 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Does a Face Mask Protect my Privacy?: Deep Learning to Predict Protected Attributes from Masked Face Images
Dec 15, 2021
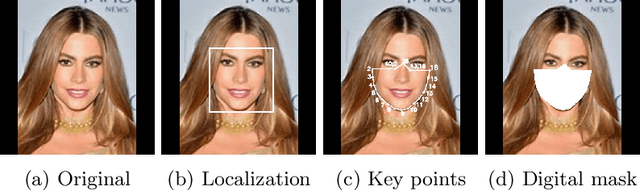
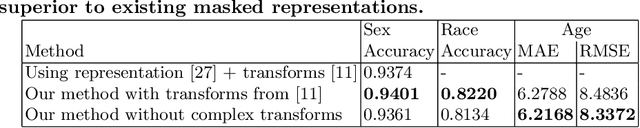
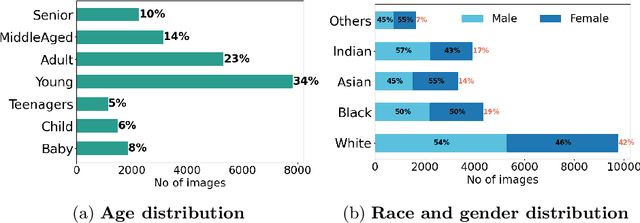
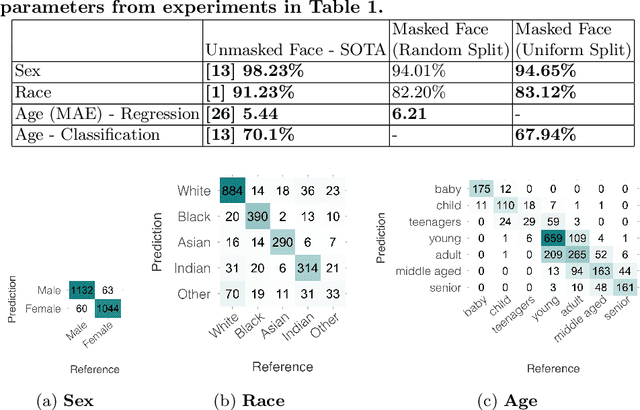
Contactless and efficient systems are implemented rapidly to advocate preventive methods in the fight against the COVID-19 pandemic. Despite the positive benefits of such systems, there is potential for exploitation by invading user privacy. In this work, we analyse the privacy invasiveness of face biometric systems by predicting privacy-sensitive soft-biometrics using masked face images. We train and apply a CNN based on the ResNet-50 architecture with 20,003 synthetic masked images and measure the privacy invasiveness. Despite the popular belief of the privacy benefits of wearing a mask among people, we show that there is no significant difference to privacy invasiveness when a mask is worn. In our experiments we were able to accurately predict sex (94.7%),race (83.1%) and age (MAE 6.21 and RMSE 8.33) from masked face images. Our proposed approach can serve as a baseline utility to evaluate the privacy-invasiveness of artificial intelligence systems that make use of privacy-sensitive information. We open-source all contributions for re-producibility and broader use by the research community.
EPNet++: Cascade Bi-directional Fusion for Multi-Modal 3D Object Detection
Dec 25, 2021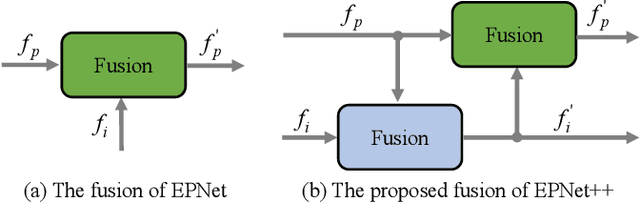
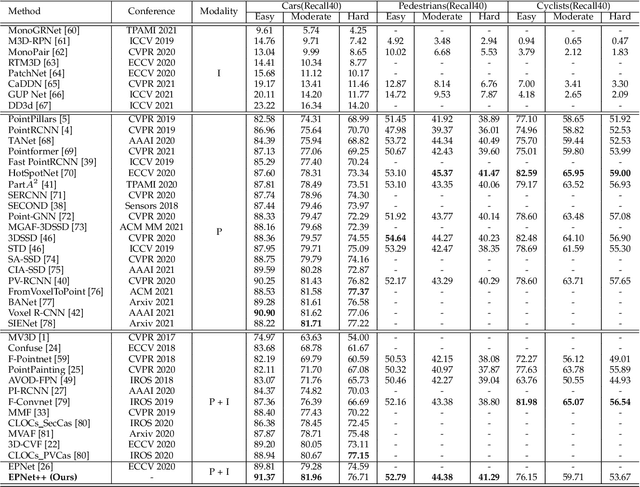
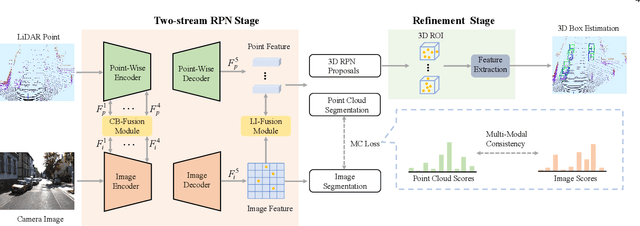
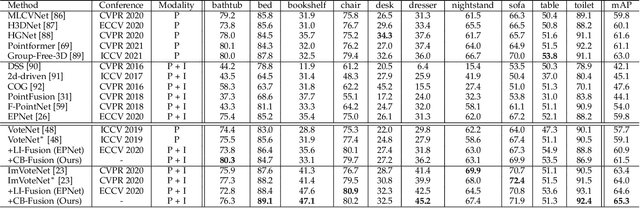
Recently, fusing the LiDAR point cloud and camera image to improve the performance and robustness of 3D object detection has received more and more attention, as these two modalities naturally possess strong complementarity. In this paper, we propose EPNet++ for multi-modal 3D object detection by introducing a novel Cascade Bi-directional Fusion~(CB-Fusion) module and a Multi-Modal Consistency~(MC) loss. More concretely, the proposed CB-Fusion module boosts the plentiful semantic information of point features with the image features in a cascade bi-directional interaction fusion manner, leading to more comprehensive and discriminative feature representations. The MC loss explicitly guarantees the consistency between predicted scores from two modalities to obtain more comprehensive and reliable confidence scores. The experiment results on the KITTI, JRDB and SUN-RGBD datasets demonstrate the superiority of EPNet++ over the state-of-the-art methods. Besides, we emphasize a critical but easily overlooked problem, which is to explore the performance and robustness of a 3D detector in a sparser scene. Extensive experiments present that EPNet++ outperforms the existing SOTA methods with remarkable margins in highly sparse point cloud cases, which might be an available direction to reduce the expensive cost of LiDAR sensors. Code will be released in the future.
Graph Theory in the Classification of Information Systems
Dec 27, 2020
Risk classification plays an important role in many regulations and standards. However, a general method that provides an optimal classification has not been proposed yet. Also, the criteria of optimality are not defined in these regulations. In this work, we will propose a mathematical model that is sufficient to describe this problem, and we also propose an algorithm that classifies graph vertices based on their risk value in polynomial time.
LeSICiN: A Heterogeneous Graph-based Approach for Automatic Legal Statute Identification from Indian Legal Documents
Dec 29, 2021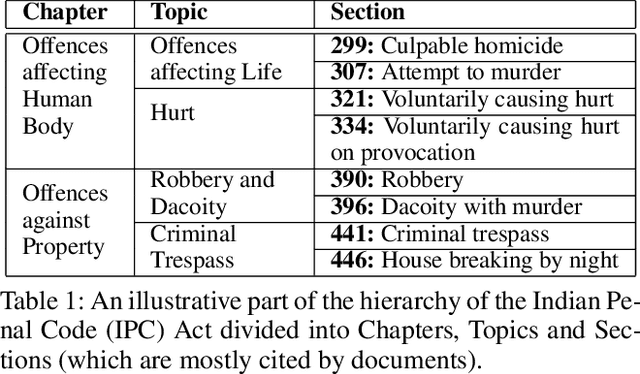
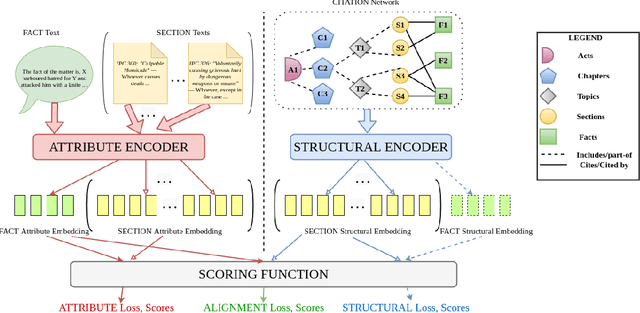
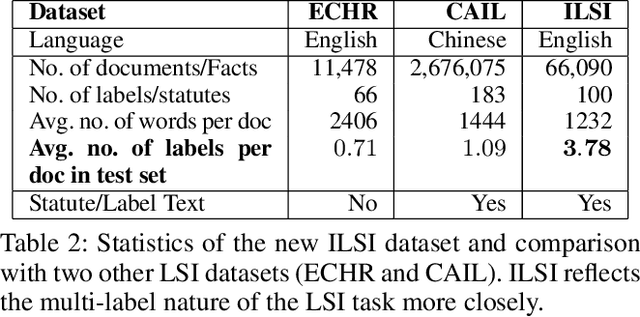
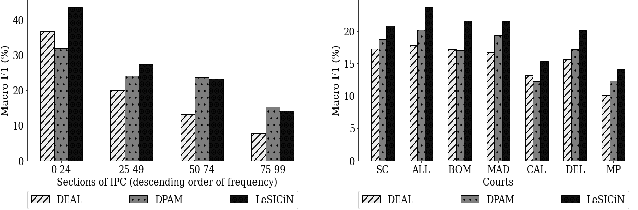
The task of Legal Statute Identification (LSI) aims to identify the legal statutes that are relevant to a given description of Facts or evidence of a legal case. Existing methods only utilize the textual content of Facts and legal articles to guide such a task. However, the citation network among case documents and legal statutes is a rich source of additional information, which is not considered by existing models. In this work, we take the first step towards utilising both the text and the legal citation network for the LSI task. We curate a large novel dataset for this task, including Facts of cases from several major Indian Courts of Law, and statutes from the Indian Penal Code (IPC). Modeling the statutes and training documents as a heterogeneous graph, our proposed model LeSICiN can learn rich textual and graphical features, and can also tune itself to correlate these features. Thereafter, the model can be used to inductively predict links between test documents (new nodes whose graphical features are not available to the model) and statutes (existing nodes). Extensive experiments on the dataset show that our model comfortably outperforms several state-of-the-art baselines, by exploiting the graphical structure along with textual features. The dataset and our codes are available at https://github.com/Law-AI/LeSICiN.
Unifying Model Explainability and Robustness for Joint Text Classification and Rationale Extraction
Dec 20, 2021
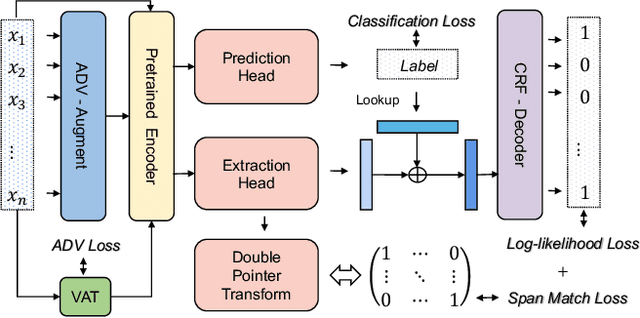
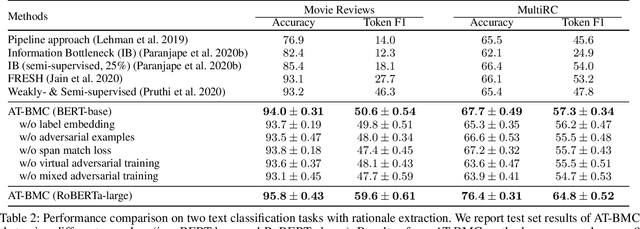
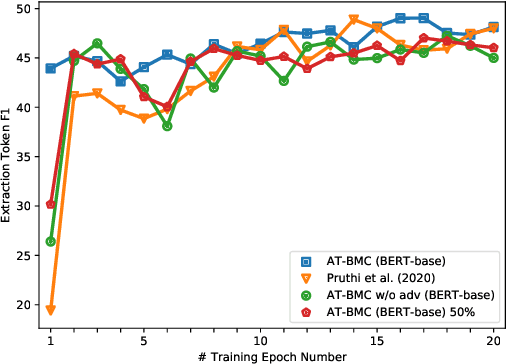
Recent works have shown explainability and robustness are two crucial ingredients of trustworthy and reliable text classification. However, previous works usually address one of two aspects: i) how to extract accurate rationales for explainability while being beneficial to prediction; ii) how to make the predictive model robust to different types of adversarial attacks. Intuitively, a model that produces helpful explanations should be more robust against adversarial attacks, because we cannot trust the model that outputs explanations but changes its prediction under small perturbations. To this end, we propose a joint classification and rationale extraction model named AT-BMC. It includes two key mechanisms: mixed Adversarial Training (AT) is designed to use various perturbations in discrete and embedding space to improve the model's robustness, and Boundary Match Constraint (BMC) helps to locate rationales more precisely with the guidance of boundary information. Performances on benchmark datasets demonstrate that the proposed AT-BMC outperforms baselines on both classification and rationale extraction by a large margin. Robustness analysis shows that the proposed AT-BMC decreases the attack success rate effectively by up to 69%. The empirical results indicate that there are connections between robust models and better explanations.
Overabundant Information and Learning Traps
Jun 19, 2018We develop a model of social learning from overabundant information: Short-lived agents sequentially choose from a large set of (flexibly correlated) information sources for prediction of an unknown state. Signal realizations are public. We demonstrate two starkly different long-run outcomes: (1) efficient information aggregation, where the community eventually learns as fast as possible; (2) "learning traps," where the community gets stuck observing suboptimal sources and learns inefficiently. Our main results identify a simple property of the signal correlation structure that separates these outcomes. In both regimes, we characterize which sources are observed in the long run and how often.
Equal Bits: Enforcing Equally Distributed Binary Network Weights
Dec 02, 2021
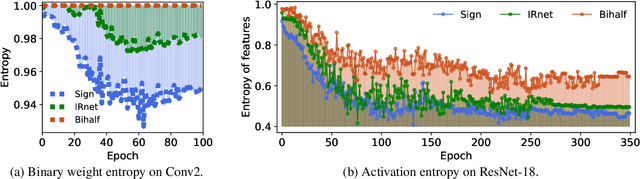
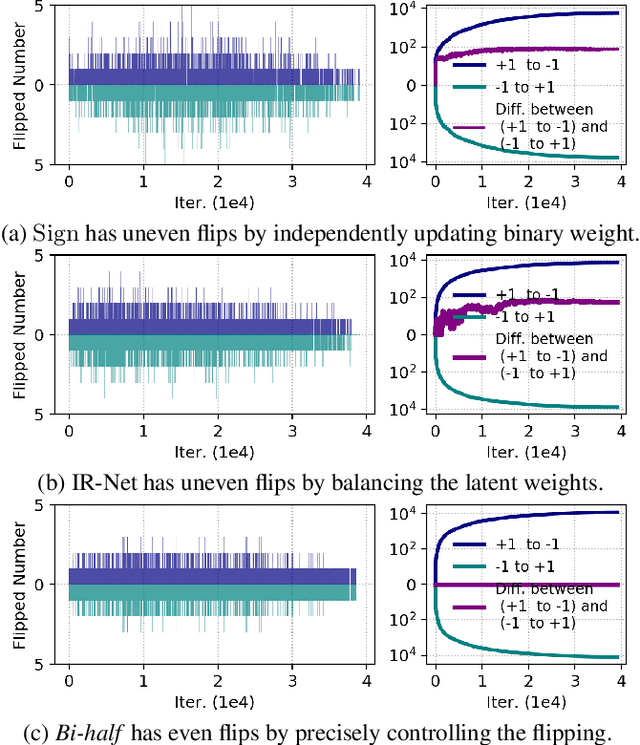
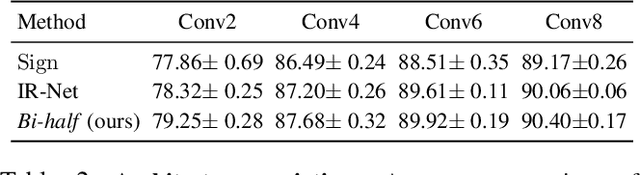
Binary networks are extremely efficient as they use only two symbols to define the network: $\{+1,-1\}$. One can make the prior distribution of these symbols a design choice. The recent IR-Net of Qin et al. argues that imposing a Bernoulli distribution with equal priors (equal bit ratios) over the binary weights leads to maximum entropy and thus minimizes information loss. However, prior work cannot precisely control the binary weight distribution during training, and therefore cannot guarantee maximum entropy. Here, we show that quantizing using optimal transport can guarantee any bit ratio, including equal ratios. We investigate experimentally that equal bit ratios are indeed preferable and show that our method leads to optimization benefits. We show that our quantization method is effective when compared to state-of-the-art binarization methods, even when using binary weight pruning.
Vision-and-Language or Vision-for-Language? On Cross-Modal Influence in Multimodal Transformers
Sep 09, 2021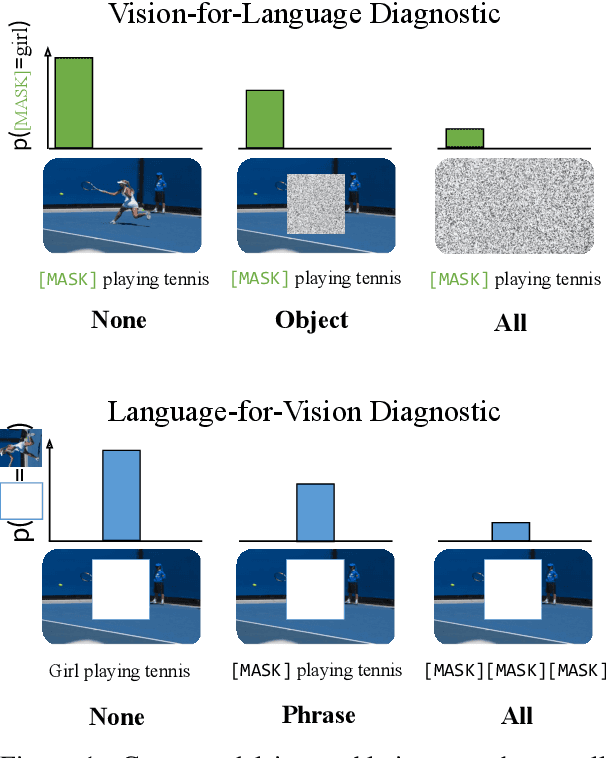
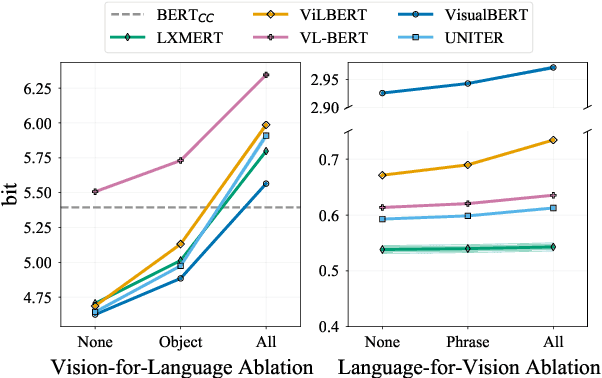
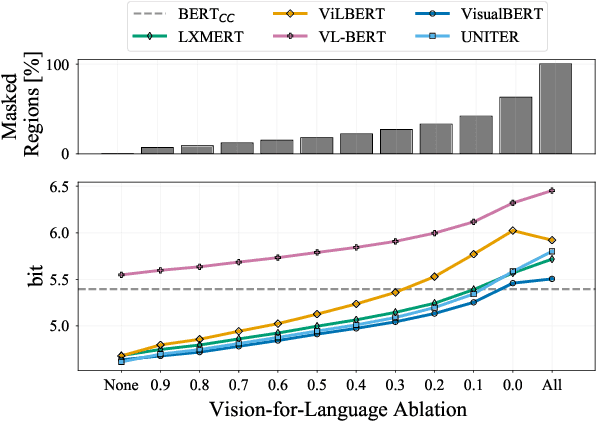
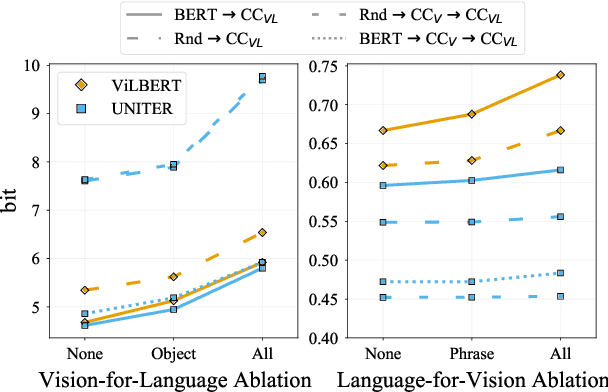
Pretrained vision-and-language BERTs aim to learn representations that combine information from both modalities. We propose a diagnostic method based on cross-modal input ablation to assess the extent to which these models actually integrate cross-modal information. This method involves ablating inputs from one modality, either entirely or selectively based on cross-modal grounding alignments, and evaluating the model prediction performance on the other modality. Model performance is measured by modality-specific tasks that mirror the model pretraining objectives (e.g. masked language modelling for text). Models that have learned to construct cross-modal representations using both modalities are expected to perform worse when inputs are missing from a modality. We find that recently proposed models have much greater relative difficulty predicting text when visual information is ablated, compared to predicting visual object categories when text is ablated, indicating that these models are not symmetrically cross-modal.
Gradual (In)Compatibility of Fairness Criteria
Sep 09, 2021
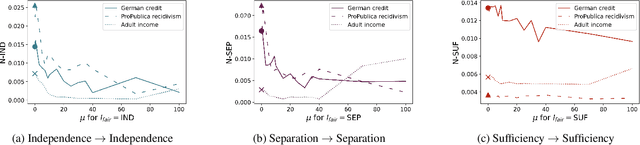
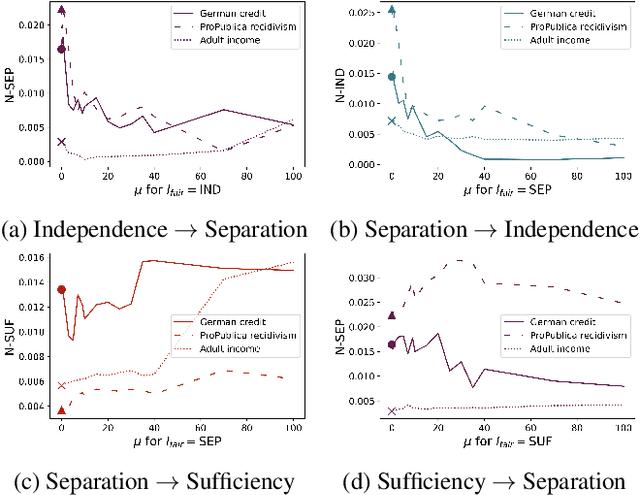
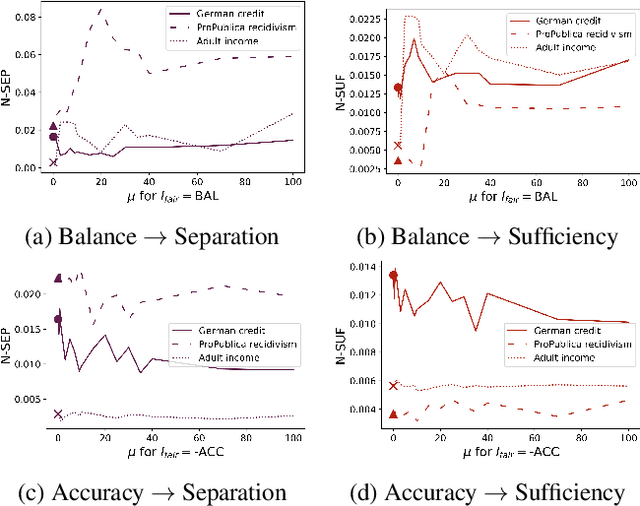
Impossibility results show that important fairness measures (independence, separation, sufficiency) cannot be satisfied at the same time under reasonable assumptions. This paper explores whether we can satisfy and/or improve these fairness measures simultaneously to a certain degree. We introduce information-theoretic formulations of the fairness measures and define degrees of fairness based on these formulations. The information-theoretic formulations suggest unexplored theoretical relations between the three fairness measures. In the experimental part, we use the information-theoretic expressions as regularizers to obtain fairness-regularized predictors for three standard datasets. Our experiments show that a) fairness regularization directly increases fairness measures, in line with existing work, and b) some fairness regularizations indirectly increase other fairness measures, as suggested by our theoretical findings. This establishes that it is possible to increase the degree to which some fairness measures are satisfied at the same time -- some fairness measures are gradually compatible.
Active Learning of Quantum System Hamiltonians yields Query Advantage
Dec 29, 2021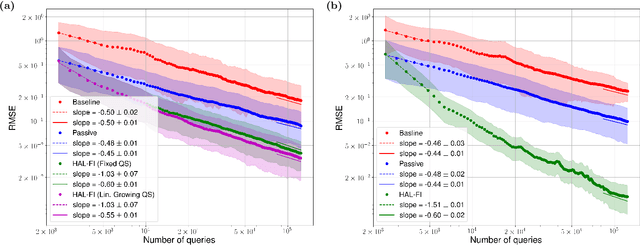
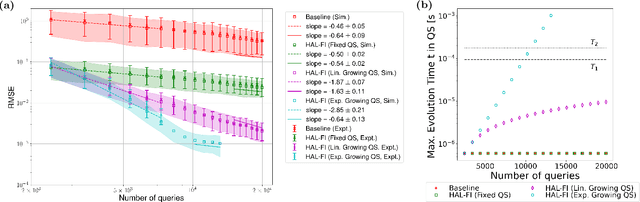
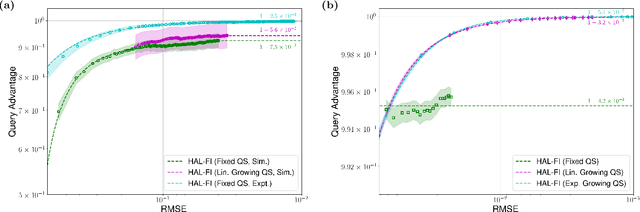
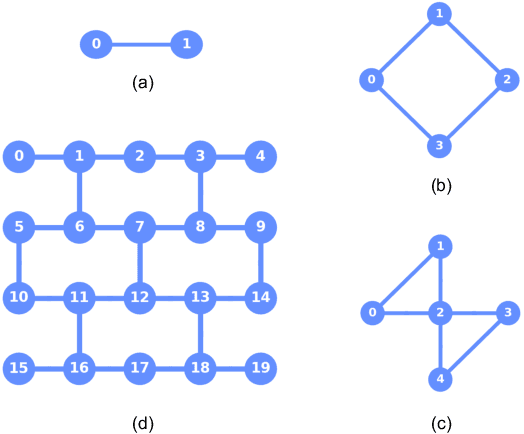
Hamiltonian learning is an important procedure in quantum system identification, calibration, and successful operation of quantum computers. Through queries to the quantum system, this procedure seeks to obtain the parameters of a given Hamiltonian model and description of noise sources. Standard techniques for Hamiltonian learning require careful design of queries and $O(\epsilon^{-2})$ queries in achieving learning error $\epsilon$ due to the standard quantum limit. With the goal of efficiently and accurately estimating the Hamiltonian parameters within learning error $\epsilon$ through minimal queries, we introduce an active learner that is given an initial set of training examples and the ability to interactively query the quantum system to generate new training data. We formally specify and experimentally assess the performance of this Hamiltonian active learning (HAL) algorithm for learning the six parameters of a two-qubit cross-resonance Hamiltonian on four different superconducting IBM Quantum devices. Compared with standard techniques for the same problem and a specified learning error, HAL achieves up to a $99.8\%$ reduction in queries required, and a $99.1\%$ reduction over the comparable non-adaptive learning algorithm. Moreover, with access to prior information on a subset of Hamiltonian parameters and given the ability to select queries with linearly (or exponentially) longer system interaction times during learning, HAL can exceed the standard quantum limit and achieve Heisenberg (or super-Heisenberg) limited convergence rates during learning.