 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Improved Neural Distinguishers with (Related-key) Differentials: Applications in SIMON and SIMECK
Jan 11, 2022
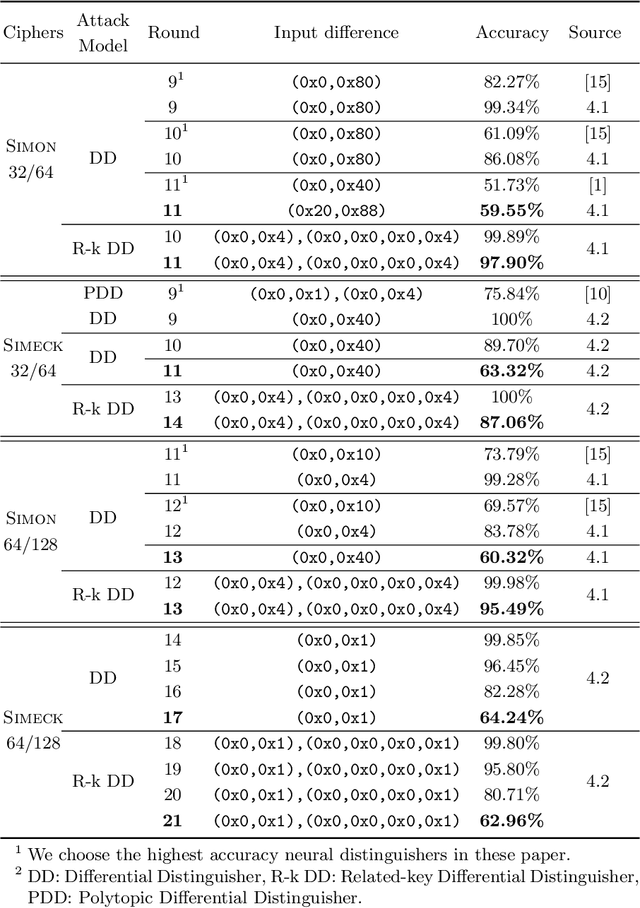
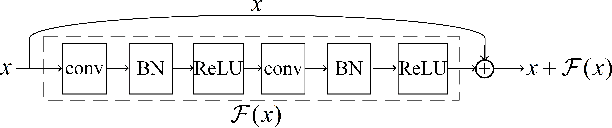

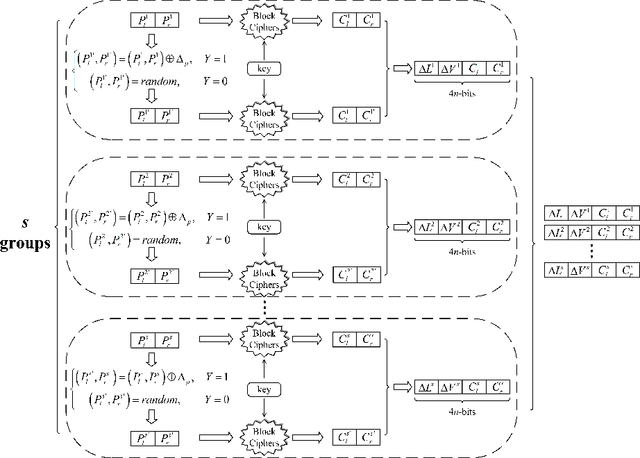
In CRYPTO 2019, Gohr made a pioneering attempt, and successfully applied deep learning to the differential cryptanalysis against NSA block cipher Speck32/64, achieving higher accuracy than the pure differential distinguishers. By its very nature, mining effective features in data plays a crucial role in data-driven deep learning. In this paper, in addition to considering the integrity of the information from the training data of the ciphertext pair, domain knowledge about the structure of differential cryptanalysis is also considered into the training process of deep learning to improve the performance. Besides, based on the SAT/SMT solvers, we find other high probability compatible differential characteristics which effectively improve the performance compared with previous work. We build neural distinguishers (NDs) and related-key neural distinguishers (RKNDs) against Simon and Simeck. The ND and RKND for Simon32/64 reach 11-, 11-round with an accuracy of 59.55% and 97.90%, respectively. For Simon64/128, the ND achieve an accuracy of 60.32% in 13-round, while it is 95.49% for the RKND. For Simeck32/64, ND and RKND of 11-, 14-round are obtained, reaching an accuracy of 63.32% and 87.06%, respectively. And we build 17-round ND and 21-round RKND for Simeck64/128 with an accuracy of 64.24% and 62.96%, respectively. Currently, these are the longest (related-key) neural distinguishers with higher accuracy for Simon32/64, Simon64/128, Simeck32/64 and Simeck64/128.
The Power of Communication in a Distributed Multi-Agent System
Dec 14, 2021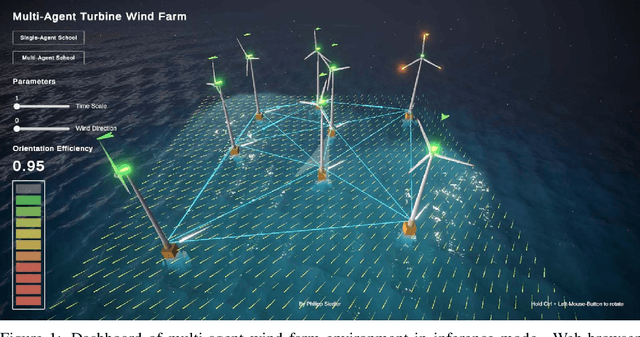
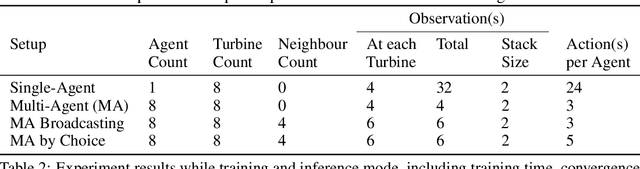


Single-Agent (SA) Reinforcement Learning systems have shown outstanding re-sults on non-stationary problems. However, Multi-Agent Reinforcement Learning(MARL) can surpass SA systems generally and when scaling. Furthermore, MAsystems can be super-powered by collaboration, which can happen through ob-serving others, or a communication system used to share information betweencollaborators. Here, we developed a distributed MA learning mechanism withthe ability to communicate based on decentralised partially observable Markovdecision processes (Dec-POMDPs) and Graph Neural Networks (GNNs). Minimis-ing the time and energy consumed by training Machine Learning models whileimproving performance can be achieved by collaborative MA mechanisms. Wedemonstrate this in a real-world scenario, an offshore wind farm, including a set ofdistributed wind turbines, where the objective is to maximise collective efficiency.Compared to a SA system, MA collaboration has shown significantly reducedtraining time and higher cumulative rewards in unseen and scaled scenarios.
Observing a group to infer individual characteristics
Oct 12, 2021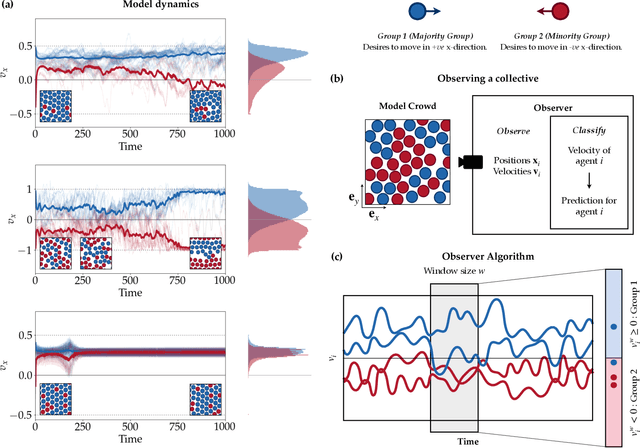
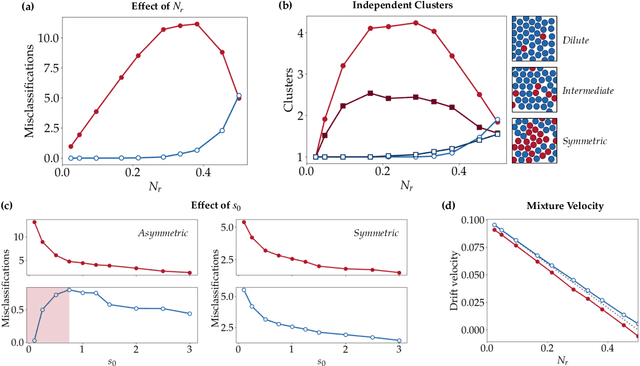
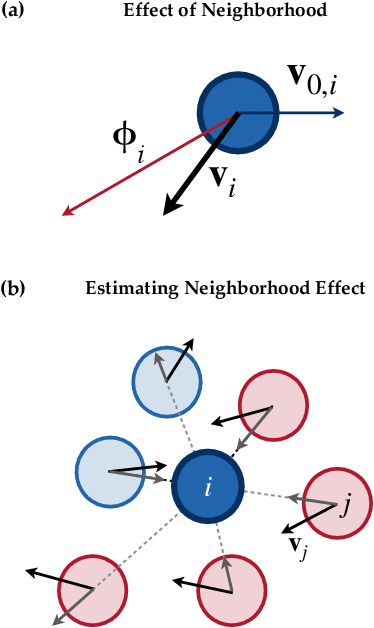
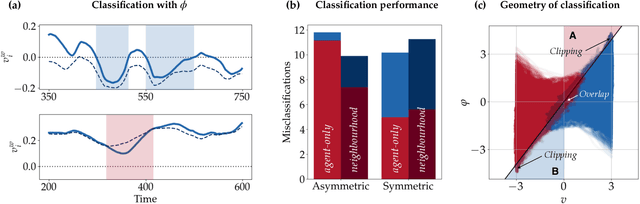
In the study of collective motion, it is common practice to collect movement information at the level of the group to infer the characteristics of the individual agents and their interactions. However, it is not clear whether one can always correctly infer individual characteristics from movement data of the collective. We investigate this question in the context of a composite crowd with two groups of agents, each with its own desired direction of motion. A simple observer attempts to classify an agent into its group based on its movement information. However, collective effects such as collisions, entrainment of agents, formation of lanes and clusters, etc. render the classification problem non-trivial, and lead to misclassifications. Based on our understanding of these effects, we propose a new observer algorithm that infers, based only on observed movement information, how the local neighborhood aids or hinders agent movement. Unlike a traditional supervised learning approach, this algorithm is based on physical insights and scaling arguments, and does not rely on training-data. This new observer improves classification performance and is able to differentiate agents belonging to different groups even when their motion is identical. Data-agnostic approaches like this have relevance to a large class of real-world problems where clean, labeled data is difficult to obtain, and is a step towards hybrid approaches that integrate both data and domain knowledge.
Object Counting: You Only Need to Look at One
Dec 11, 2021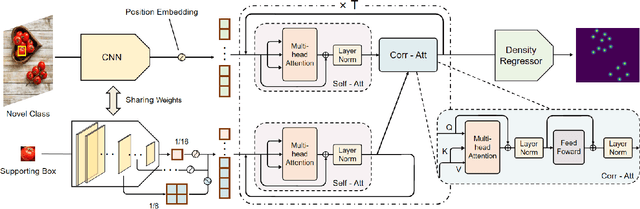
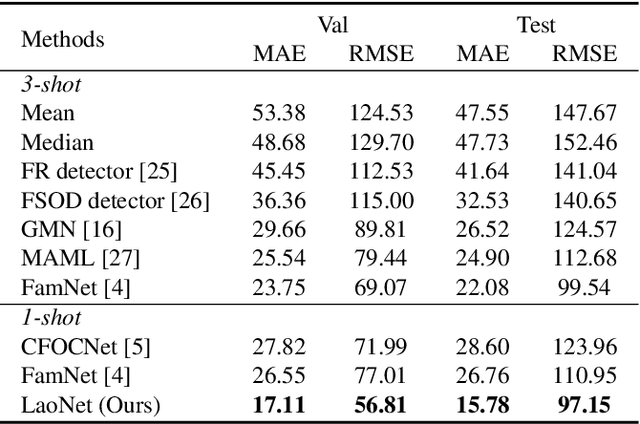


This paper aims to tackle the challenging task of one-shot object counting. Given an image containing novel, previously unseen category objects, the goal of the task is to count all instances in the desired category with only one supporting bounding box example. To this end, we propose a counting model by which you only need to Look At One instance (LaoNet). First, a feature correlation module combines the Self-Attention and Correlative-Attention modules to learn both inner-relations and inter-relations. It enables the network to be robust to the inconsistency of rotations and sizes among different instances. Second, a Scale Aggregation mechanism is designed to help extract features with different scale information. Compared with existing few-shot counting methods, LaoNet achieves state-of-the-art results while learning with a high convergence speed. The code will be available soon.
Long-range medical image registration through generalized mutual information (GMI): toward a fully automatic volumetric alignment
Nov 30, 2020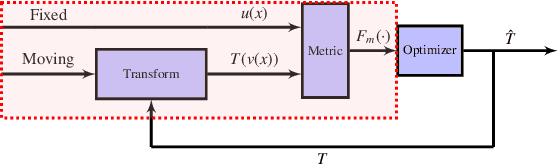
Image registration is a key operation in medical image processing, allowing a plethora of applications. Mutual information (MI) is consolidated as a robust similarity metric often used for medical image registration. Although MI provides a robust medical image registration, it usually fails when the needed image transform is too big due to MI local maxima traps. In this paper, we propose and evaluate a generalized parametric MI as an affine registration cost function. We assessed the generalized MI (GMI) functions for separable affine transforms and exhaustively evaluated the GMI mathematical image seeking the maximum registration range through a gradient descent simulation. We also employed Monte Carlo simulation essays for testing translation registering of randomized T1 versus T2 images. GMI functions showed to have smooth isosurfaces driving the algorithm to the global maxima. Results show significantly prolonged registration ranges, avoiding the traps of local maxima. We evaluated a range of [-150mm,150mm] for translations, [-180{\deg},180{\deg}] for rotations, [0.5,2] for scales, and [-1,1] for skew with a success rate of 99.99%, 97.58%, 99.99%, and 99.99% respectively for the transforms in the simulated gradient descent. We also obtained 99.75% success in Monte Carlo simulation from 2,000 randomized translations trials with 1,113 subjects T1 and T2 MRI images. The findings point towards the reliability of GMI for long-range registration with enhanced speed performance
Comprehensive Movie Recommendation System
Dec 23, 2021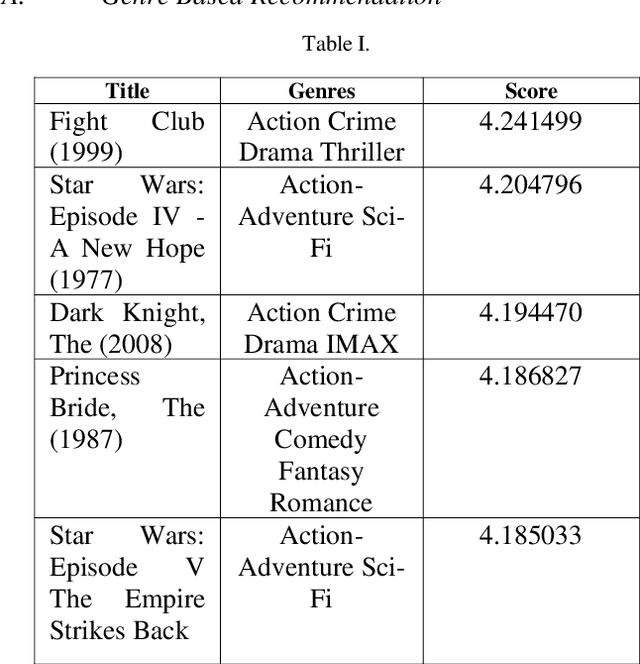
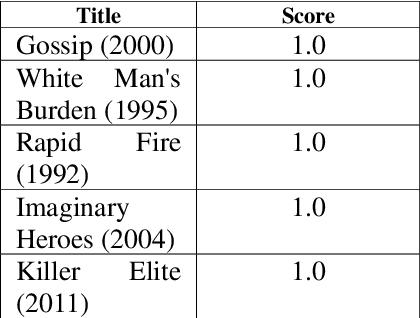
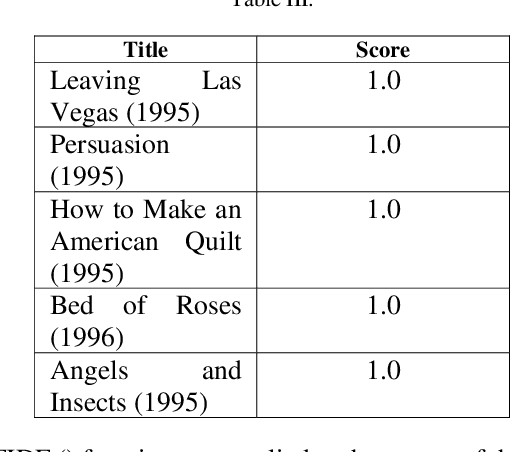
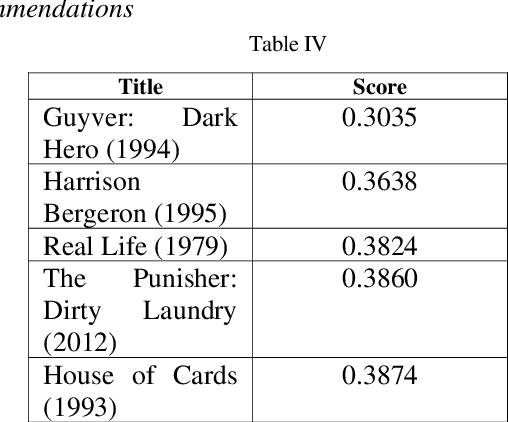
A recommender system, also known as a recommendation system, is a type of information filtering system that attempts to forecast a user's rating or preference for an item. This article designs and implements a complete movie recommendation system prototype based on the Genre, Pearson Correlation Coefficient, Cosine Similarity, KNN-Based, Content-Based Filtering using TFIDF and SVD, Collaborative Filtering using TFIDF and SVD, Surprise Library based recommendation system technology. Apart from that in this paper, we present a novel idea that applies machine learning techniques to construct a cluster for the movie based on genres and then observes the inertia value number of clusters were defined. The constraints of the approaches discussed in this work have been described, as well as how one strategy overcomes the disadvantages of another. The whole work has been done on the dataset Movie Lens present at the group lens website which contains 100836 ratings and 3683 tag applications across 9742 movies. These data were created by 610 users between March 29, 1996, and September 24, 2018.
Data-Efficient Learning of High-Quality Controls for Kinodynamic Planning used in Vehicular Navigation
Jan 06, 2022
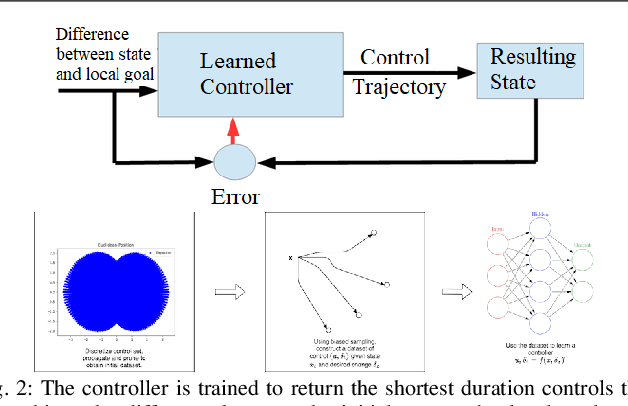
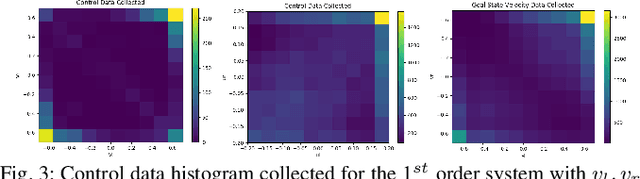
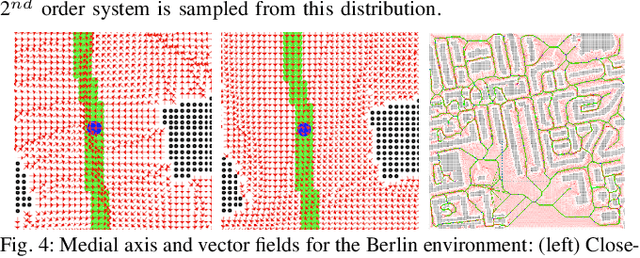
This paper aims to improve the path quality and computational efficiency of kinodynamic planners used for vehicular systems. It proposes a learning framework for identifying promising controls during the expansion process of sampling-based motion planners for systems with dynamics. Offline, the learning process is trained to return the highest-quality control that reaches a local goal state (i.e., a waypoint) in the absence of obstacles from an input difference vector between its current state and a local goal state. The data generation scheme provides bounds on the target dispersion and uses state space pruning to ensure high-quality controls. By focusing on the system's dynamics, this process is data efficient and takes place once for a dynamical system, so that it can be used for different environments with modular expansion functions. This work integrates the proposed learning process with a) an exploratory expansion function that generates waypoints with biased coverage over the reachable space, and b) proposes an exploitative expansion function for mobile robots, which generates waypoints using medial axis information. This paper evaluates the learning process and the corresponding planners for a first and second-order differential drive systems. The results show that the proposed integration of learning and planning can produce better quality paths than kinodynamic planning with random controls in fewer iterations and computation time.
* Presented at the Machine Learning for Motion Planning (MLMP) Workshop at ICRA 2021, Xi'an, China
Homoscatter: Towards efficient connectivity for ZigBee backscatter system
Nov 03, 2021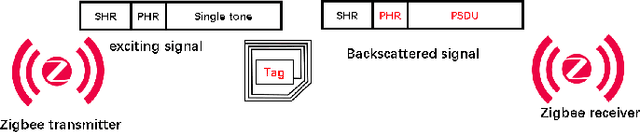
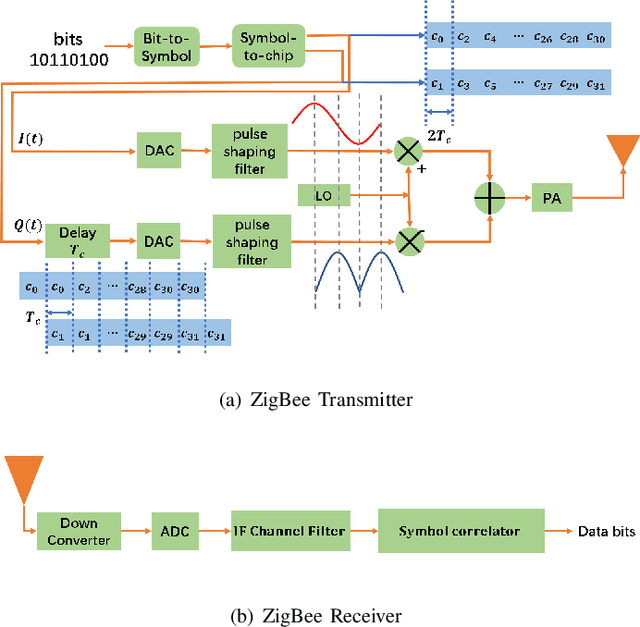
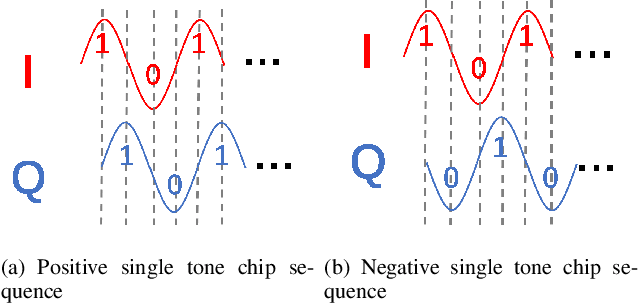
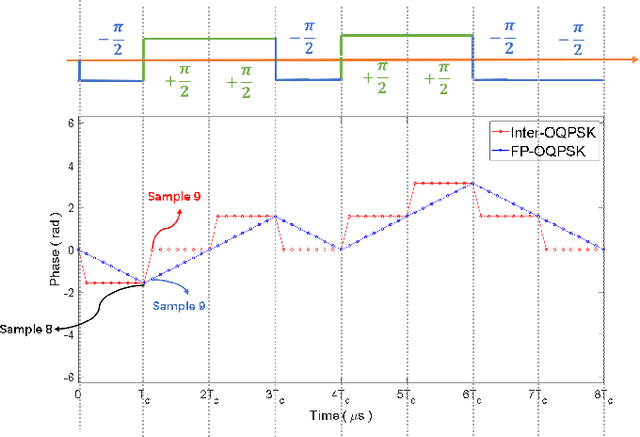
Recent advances in backscatter open a promising direction for ultra-low power communication. However, the state-of-art ZigBee backscatter system, Interscatter, has several drawbacks to deploy. Its backscatter tag and exciting source, Bluetooth, can hardly decode packets from other ZigBee nodes, which left Interscatter one-way communication. Besides, it adopts instantaneous phase change to modulate information, producing obvious sidelobes and interfering devices working on neighboring channels severely. To address the problems mentioned above, we introduce Homoscatter, a novel ZigBee backscatter system that adopts specific ZigBee devices to generate a single tone and leverages continuous phase change to modulate information, which eliminates spectral leakage. It also does codeword translation on the packet header of exciting packets, improving the utilization of ambient signal. The prototype of Homoscatter consists of a microchip radio, a backscatter tag, and a commodity receiver. The evaluations show that the occupied bandwidth of Homoscatter achieves 3x smaller than Interscatter. When the channel capacity is 17.5 kbps, the continuous phase change modulation achieves 13 kbps with the codeword translation on the excitation header. Based on the widely spread IoT devices, Homoscatter is a practical way to build an efficient connection between IoT devices.
Improving Knowledge Graph Representation Learning by Structure Contextual Pre-training
Dec 08, 2021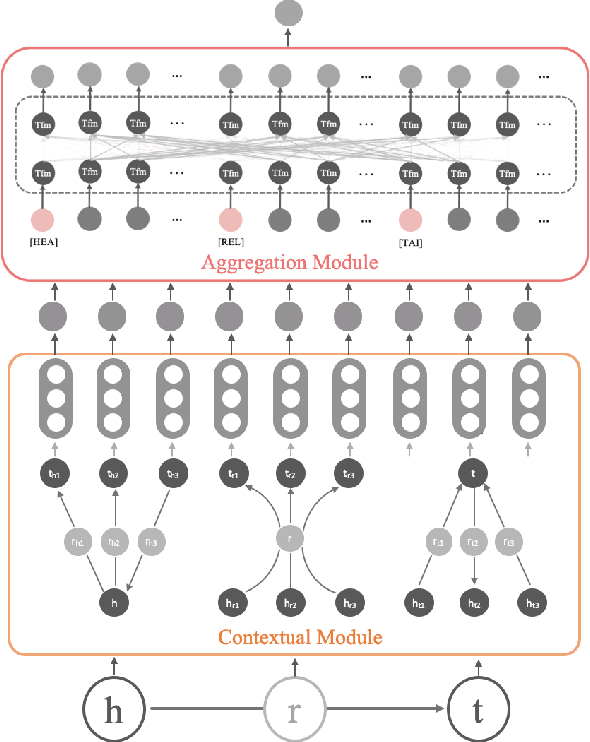
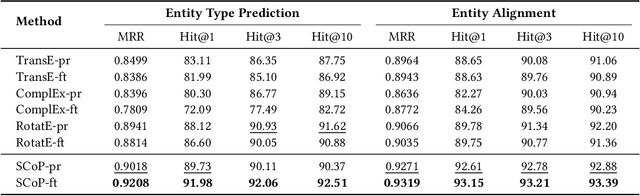
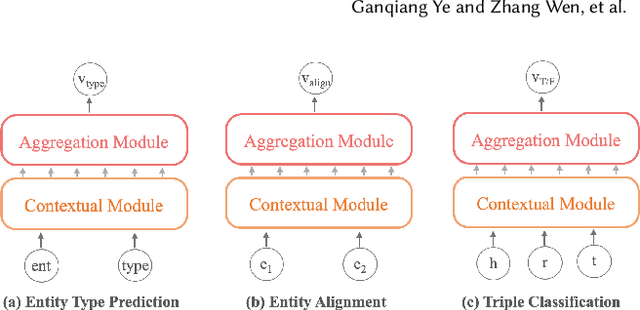
Representation learning models for Knowledge Graphs (KG) have proven to be effective in encoding structural information and performing reasoning over KGs. In this paper, we propose a novel pre-training-then-fine-tuning framework for knowledge graph representation learning, in which a KG model is firstly pre-trained with triple classification task, followed by discriminative fine-tuning on specific downstream tasks such as entity type prediction and entity alignment. Drawing on the general ideas of learning deep contextualized word representations in typical pre-trained language models, we propose SCoP to learn pre-trained KG representations with structural and contextual triples of the target triple encoded. Experimental results demonstrate that fine-tuning SCoP not only outperforms results of baselines on a portfolio of downstream tasks but also avoids tedious task-specific model design and parameter training.
Boosted GAN with Semantically Interpretable Information for Image Inpainting
Aug 13, 2019
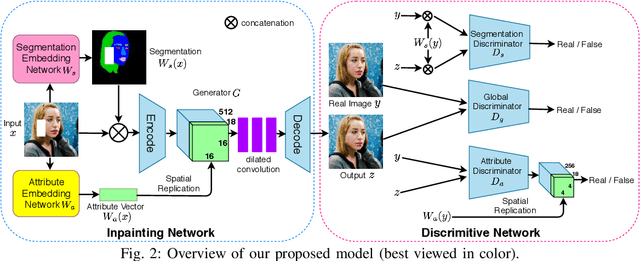


Image inpainting aims at restoring missing region of corrupted images, which has many applications such as image restoration and object removal. However, current GAN-based inpainting models fail to explicitly consider the semantic consistency between restored images and original images. Forexample, given a male image with image region of one eye missing, current models may restore it with a female eye. This is due to the ambiguity of GAN-based inpainting models: these models can generate many possible restorations given a missing region. To address this limitation, our key insight is that semantically interpretable information (such as attribute and segmentation information) of input images (with missing regions) can provide essential guidance for the inpainting process. Based on this insight, we propose a boosted GAN with semantically interpretable information for image inpainting that consists of an inpainting network and a discriminative network. The inpainting network utilizes two auxiliary pretrained networks to discover the attribute and segmentation information of input images and incorporates them into the inpainting process to provide explicit semantic-level guidance. The discriminative network adopts a multi-level design that can enforce regularizations not only on overall realness but also on attribute and segmentation consistency with the original images. Experimental results show that our proposed model can preserve consistency on both attribute and segmentation level, and significantly outperforms the state-of-the-art models.