 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
OPIEC: An Open Information Extraction Corpus
Apr 28, 2019

Open information extraction (OIE) systems extract relations and their arguments from natural language text in an unsupervised manner. The resulting extractions are a valuable resource for downstream tasks such as knowledge base construction, open question answering, or event schema induction. In this paper, we release, describe, and analyze an OIE corpus called OPIEC, which was extracted from the text of English Wikipedia. OPIEC complements the available OIE resources: It is the largest OIE corpus publicly available to date (over 340M triples) and contains valuable metadata such as provenance information, confidence scores, linguistic annotations, and semantic annotations including spatial and temporal information. We analyze the OPIEC corpus by comparing its content with knowledge bases such as DBpedia or YAGO, which are also based on Wikipedia. We found that most of the facts between entities present in OPIEC cannot be found in DBpedia and/or YAGO, that OIE facts often differ in the level of specificity compared to knowledge base facts, and that OIE open relations are generally highly polysemous. We believe that the OPIEC corpus is a valuable resource for future research on automated knowledge base construction.
* In Proceedings of the Conference of Automatic Knowledge Base Construction (AKBC) 2019
Real-time Rail Recognition Based on 3D Point Clouds
Jan 08, 2022

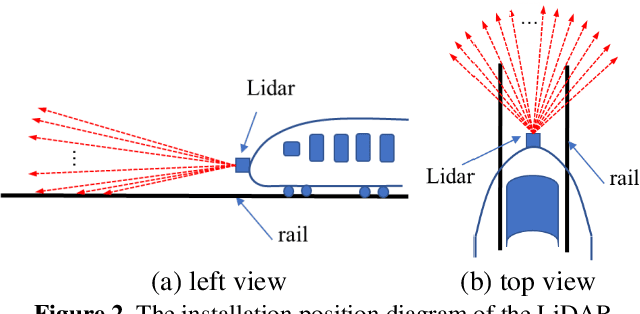
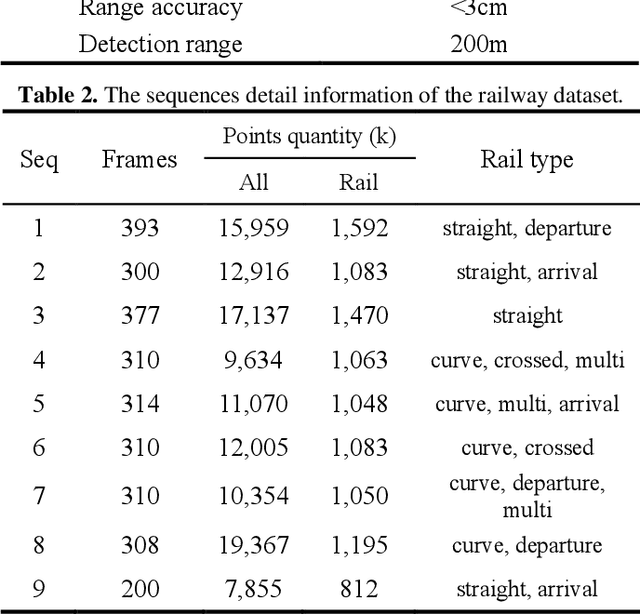
Accurate rail location is a crucial part in the railway support driving system for safety monitoring. LiDAR can obtain point clouds that carry 3D information for the railway environment, especially in darkness and terrible weather conditions. In this paper, a real-time rail recognition method based on 3D point clouds is proposed to solve the challenges, such as disorderly, uneven density and large volume of the point clouds. A voxel down-sampling method is first presented for density balanced of railway point clouds, and pyramid partition is designed to divide the 3D scanning area into the voxels with different volumes. Then, a feature encoding module is developed to find the nearest neighbor points and to aggregate their local geometric features for the center point. Finally, a multi-scale neural network is proposed to generate the prediction results of each voxel and the rail location. The experiments are conducted under 9 sequences of 3D point cloud data for the railway. The results show that the method has good performance in detecting straight, curved and other complex topologies rails.
High-resolution rainfall-runoff modeling using graph neural network
Oct 21, 2021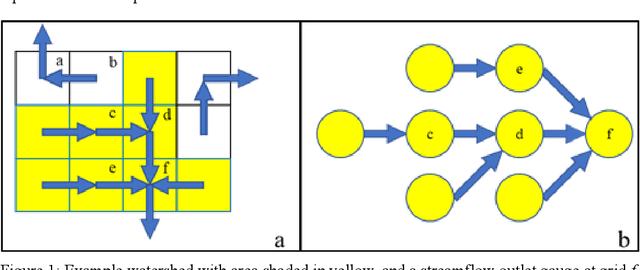
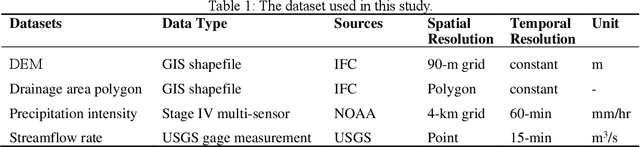
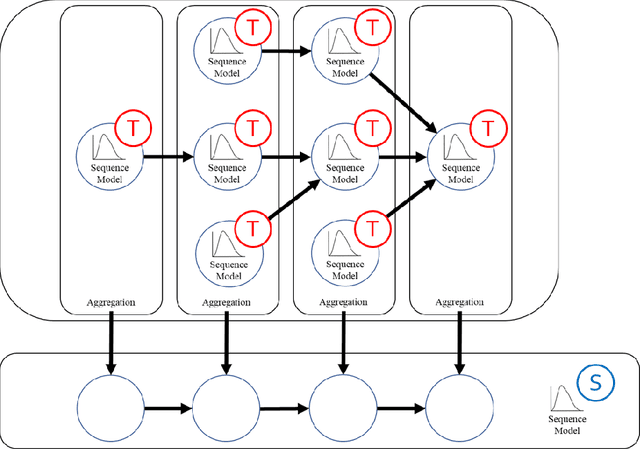
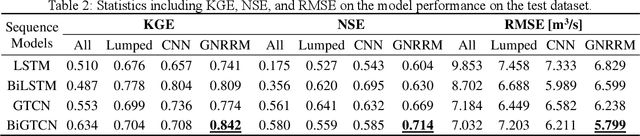
Time-series modeling has shown great promise in recent studies using the latest deep learning algorithms such as LSTM (Long Short-Term Memory). These studies primarily focused on watershed-scale rainfall-runoff modeling or streamflow forecasting, but the majority of them only considered a single watershed as a unit. Although this simplification is very effective, it does not take into account spatial information, which could result in significant errors in large watersheds. Several studies investigated the use of GNN (Graph Neural Networks) for data integration by decomposing a large watershed into multiple sub-watersheds, but each sub-watershed is still treated as a whole, and the geoinformation contained within the watershed is not fully utilized. In this paper, we propose the GNRRM (Graph Neural Rainfall-Runoff Model), a novel deep learning model that makes full use of spatial information from high-resolution precipitation data, including flow direction and geographic information. When compared to baseline models, GNRRM has less over-fitting and significantly improves model performance. Our findings support the importance of hydrological data in deep learning-based rainfall-runoff modeling, and we encourage researchers to include more domain knowledge in their models.
Improved Input Reprogramming for GAN Conditioning
Jan 07, 2022

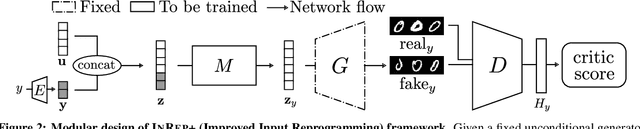
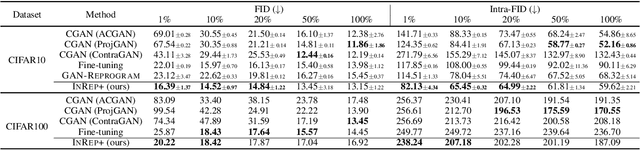
We study the GAN conditioning problem, whose goal is to convert a pretrained unconditional GAN into a conditional GAN using labeled data. We first identify and analyze three approaches to this problem -- conditional GAN training from scratch, fine-tuning, and input reprogramming. Our analysis reveals that when the amount of labeled data is small, input reprogramming performs the best. Motivated by real-world scenarios with scarce labeled data, we focus on the input reprogramming approach and carefully analyze the existing algorithm. After identifying a few critical issues of the previous input reprogramming approach, we propose a new algorithm called InRep+. Our algorithm InRep+ addresses the existing issues with the novel uses of invertible neural networks and Positive-Unlabeled (PU) learning. Via extensive experiments, we show that InRep+ outperforms all existing methods, particularly when label information is scarce, noisy, and/or imbalanced. For instance, for the task of conditioning a CIFAR10 GAN with 1% labeled data, InRep+ achieves an average Intra-FID of 82.13, whereas the second-best method achieves 114.51.
Local2Global: A distributed approach for scaling representation learning on graphs
Jan 12, 2022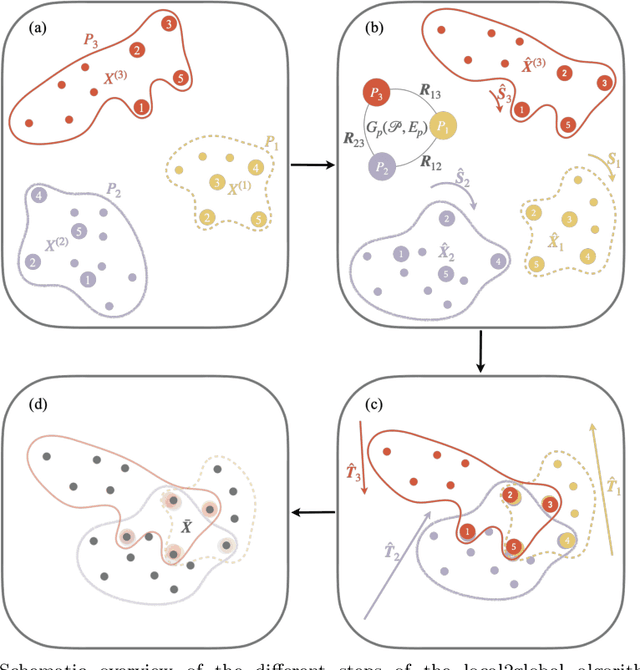

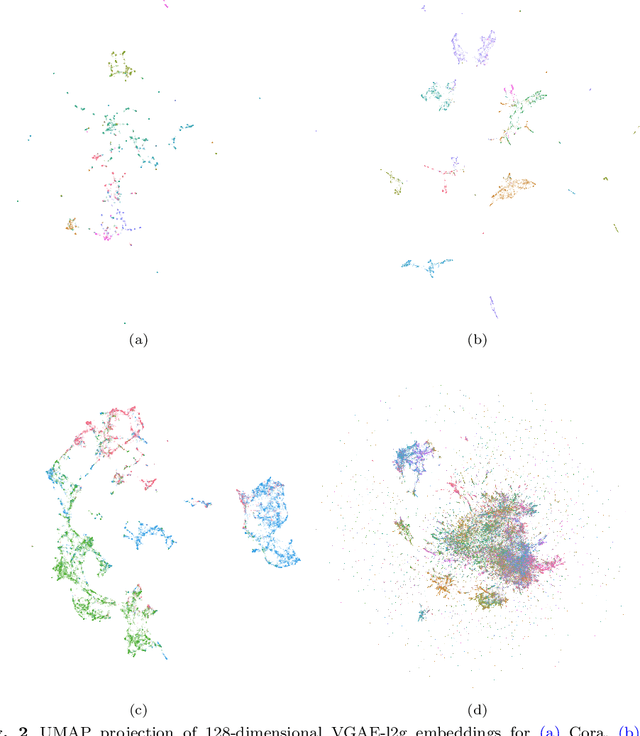
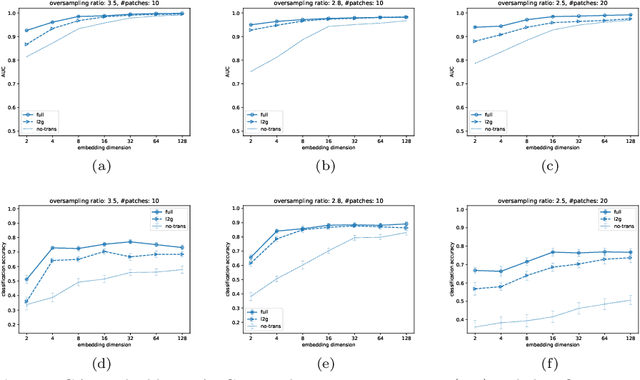
We propose a decentralised "local2global"' approach to graph representation learning, that one can a-priori use to scale any embedding technique. Our local2global approach proceeds by first dividing the input graph into overlapping subgraphs (or "patches") and training local representations for each patch independently. In a second step, we combine the local representations into a globally consistent representation by estimating the set of rigid motions that best align the local representations using information from the patch overlaps, via group synchronization. A key distinguishing feature of local2global relative to existing work is that patches are trained independently without the need for the often costly parameter synchronization during distributed training. This allows local2global to scale to large-scale industrial applications, where the input graph may not even fit into memory and may be stored in a distributed manner. We apply local2global on data sets of different sizes and show that our approach achieves a good trade-off between scale and accuracy on edge reconstruction and semi-supervised classification. We also consider the downstream task of anomaly detection and show how one can use local2global to highlight anomalies in cybersecurity networks.
Homogenization of Existing Inertial-Based Datasets to Support Human Activity Recognition
Jan 17, 2022Several techniques have been proposed to address the problem of recognizing activities of daily living from signals. Deep learning techniques applied to inertial signals have proven to be effective, achieving significant classification accuracy. Recently, research in human activity recognition (HAR) models has been almost totally model-centric. It has been proven that the number of training samples and their quality are critical for obtaining deep learning models that both perform well independently of their architecture, and that are more robust to intraclass variability and interclass similarity. Unfortunately, publicly available datasets do not always contain hight quality data and a sufficiently large and diverse number of samples (e.g., number of subjects, type of activity performed, and duration of trials). Furthermore, datasets are heterogeneous among them and therefore cannot be trivially combined to obtain a larger set. The final aim of our work is the definition and implementation of a platform that integrates datasets of inertial signals in order to make available to the scientific community large datasets of homogeneous signals, enriched, when possible, with context information (e.g., characteristics of the subjects and device position). The main focus of our platform is to emphasise data quality, which is essential for training efficient models.
PatchGraph: In-hand tactile tracking with learned surface normals
Nov 15, 2021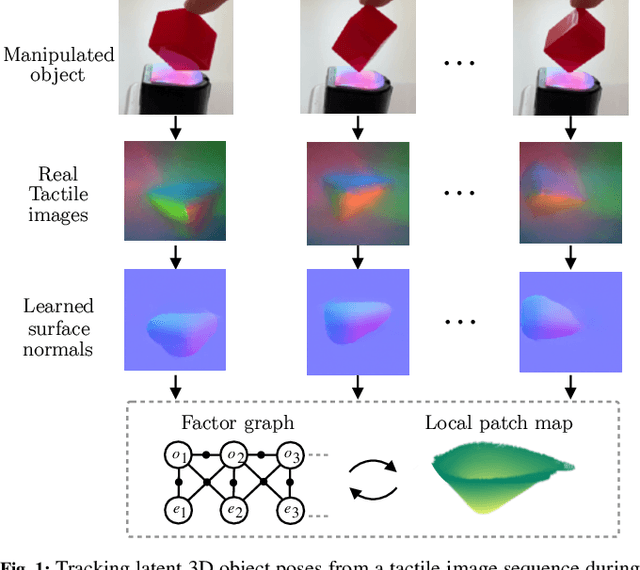
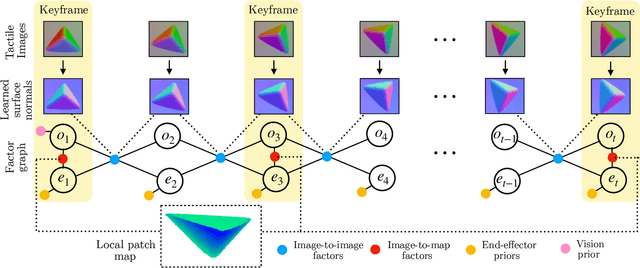
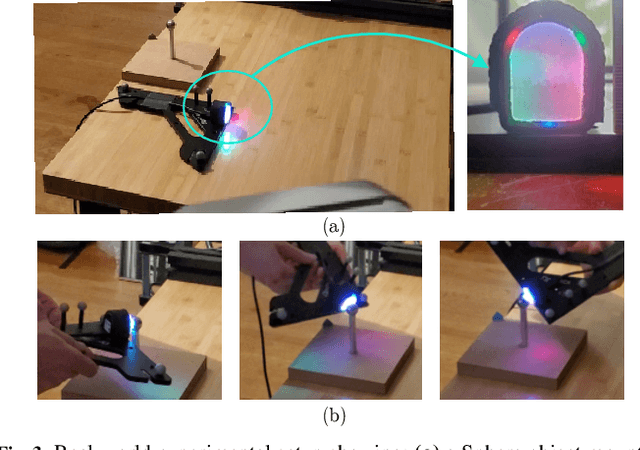
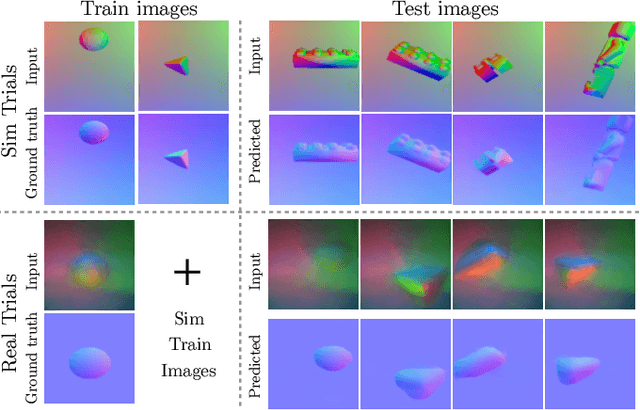
We address the problem of tracking 3D object poses from touch during in-hand manipulations. Specifically, we look at tracking small objects using vision-based tactile sensors that provide high-dimensional tactile image measurements at the point of contact. While prior work has relied on a-priori information about the object being localized, we remove this requirement. Our key insight is that an object is composed of several local surface patches, each informative enough to achieve reliable object tracking. Moreover, we can recover the geometry of this local patch online by extracting local surface normal information embedded in each tactile image. We propose a novel two-stage approach. First, we learn a mapping from tactile images to surface normals using an image translation network. Second, we use these surface normals within a factor graph to both reconstruct a local patch map and use it to infer 3D object poses. We demonstrate reliable object tracking for over 100 contact sequences across unique shapes with four objects in simulation and two objects in the real-world. Supplementary video: https://youtu.be/JwNTC9_nh8M
CoRGi: Content-Rich Graph Neural Networks with Attention
Oct 10, 2021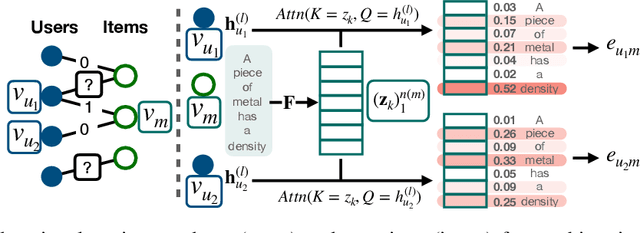

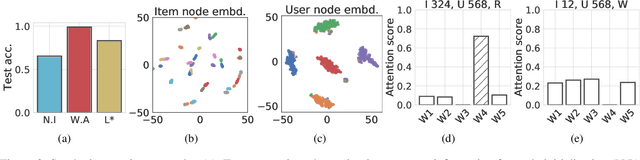
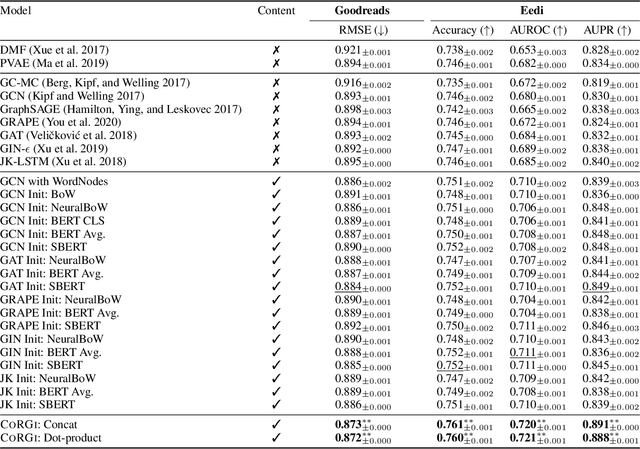
Graph representations of a target domain often project it to a set of entities (nodes) and their relations (edges). However, such projections often miss important and rich information. For example, in graph representations used in missing value imputation, items - represented as nodes - may contain rich textual information. However, when processing graphs with graph neural networks (GNN), such information is either ignored or summarized into a single vector representation used to initialize the GNN. Towards addressing this, we present CoRGi, a GNN that considers the rich data within nodes in the context of their neighbors. This is achieved by endowing CoRGi's message passing with a personalized attention mechanism over the content of each node. This way, CoRGi assigns user-item-specific attention scores with respect to the words that appear in an item's content. We evaluate CoRGi on two edge-value prediction tasks and show that CoRGi is better at making edge-value predictions over existing methods, especially on sparse regions of the graph.
Adaptive Kernel Graph Neural Network
Dec 08, 2021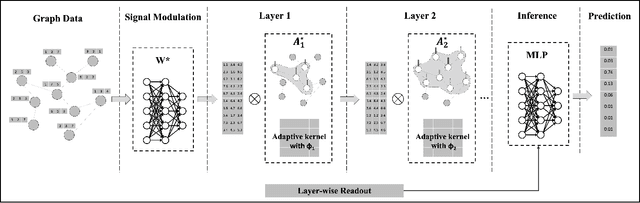
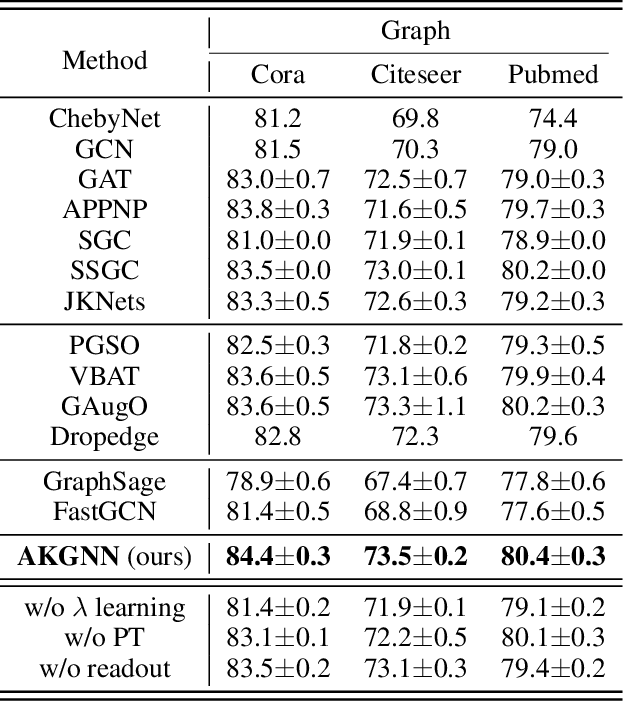
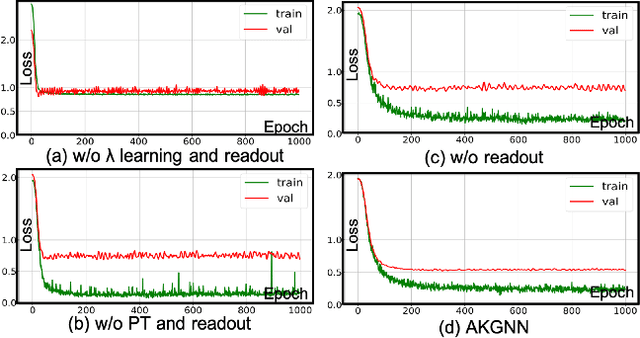
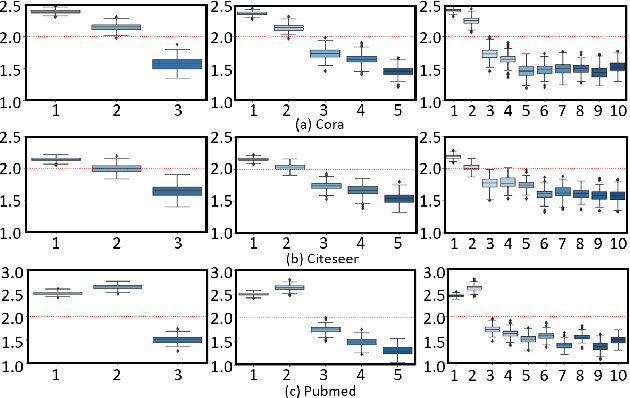
Graph neural networks (GNNs) have demonstrated great success in representation learning for graph-structured data. The layer-wise graph convolution in GNNs is shown to be powerful at capturing graph topology. During this process, GNNs are usually guided by pre-defined kernels such as Laplacian matrix, adjacency matrix, or their variants. However, the adoptions of pre-defined kernels may restrain the generalities to different graphs: mismatch between graph and kernel would entail sub-optimal performance. For example, GNNs that focus on low-frequency information may not achieve satisfactory performance when high-frequency information is significant for the graphs, and vice versa. To solve this problem, in this paper, we propose a novel framework - i.e., namely Adaptive Kernel Graph Neural Network (AKGNN) - which learns to adapt to the optimal graph kernel in a unified manner at the first attempt. In the proposed AKGNN, we first design a data-driven graph kernel learning mechanism, which adaptively modulates the balance between all-pass and low-pass filters by modifying the maximal eigenvalue of the graph Laplacian. Through this process, AKGNN learns the optimal threshold between high and low frequency signals to relieve the generality problem. Later, we further reduce the number of parameters by a parameterization trick and enhance the expressive power by a global readout function. Extensive experiments are conducted on acknowledged benchmark datasets and promising results demonstrate the outstanding performance of our proposed AKGNN by comparison with state-of-the-art GNNs. The source code is publicly available at: https://github.com/jumxglhf/AKGNN.
Cellular Network Radio Propagation Modeling with Deep Convolutional Neural Networks
Oct 05, 2021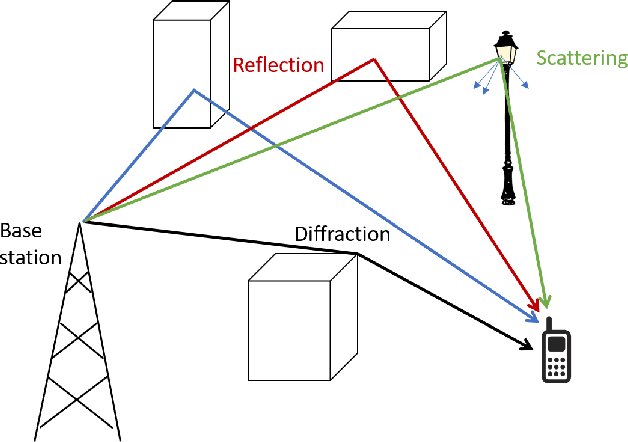
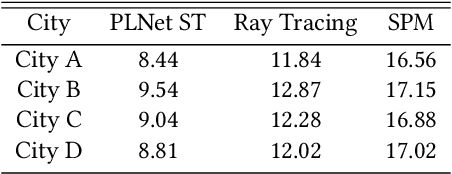
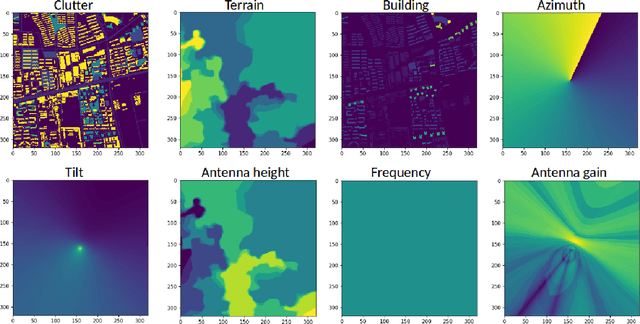
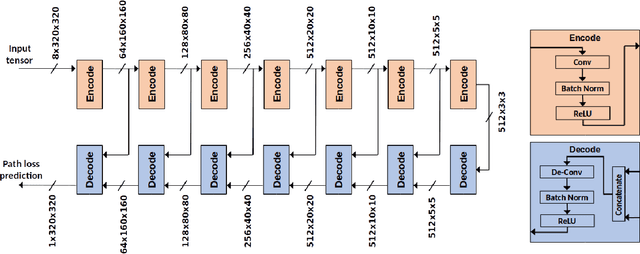
Radio propagation modeling and prediction is fundamental for modern cellular network planning and optimization. Conventional radio propagation models fall into two categories. Empirical models, based on coarse statistics, are simple and computationally efficient, but are inaccurate due to oversimplification. Deterministic models, such as ray tracing based on physical laws of wave propagation, are more accurate and site specific. But they have higher computational complexity and are inflexible to utilize site information other than traditional global information system (GIS) maps. In this article we present a novel method to model radio propagation using deep convolutional neural networks and report significantly improved performance compared to conventional models. We also lay down the framework for data-driven modeling of radio propagation and enable future research to utilize rich and unconventional information of the site, e.g. satellite photos, to provide more accurate and flexible models.