 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval-Augmented Open-Vocabulary Object Detection
Apr 08, 2024Open-vocabulary object detection (OVD) has been studied with Vision-Language Models (VLMs) to detect novel objects beyond the pre-trained categories. Previous approaches improve the generalization ability to expand the knowledge of the detector, using 'positive' pseudo-labels with additional 'class' names, e.g., sock, iPod, and alligator. To extend the previous methods in two aspects, we propose Retrieval-Augmented Losses and visual Features (RALF). Our method retrieves related 'negative' classes and augments loss functions. Also, visual features are augmented with 'verbalized concepts' of classes, e.g., worn on the feet, handheld music player, and sharp teeth. Specifically, RALF consists of two modules: Retrieval Augmented Losses (RAL) and Retrieval-Augmented visual Features (RAF). RAL constitutes two losses reflecting the semantic similarity with negative vocabularies. In addition, RAF augments visual features with the verbalized concepts from a large language model (LLM). Our experiments demonstrate the effectiveness of RALF on COCO and LVIS benchmark datasets. We achieve improvement up to 3.4 box AP$_{50}^{\text{N}}$ on novel categories of the COCO dataset and 3.6 mask AP$_{\text{r}}$ gains on the LVIS dataset. Code is available at https://github.com/mlvlab/RALF .
Distribution-Aware Prompt Tuning for Vision-Language Models
Sep 06, 2023



Pre-trained vision-language models (VLMs) have shown impressive performance on various downstream tasks by utilizing knowledge learned from large data. In general, the performance of VLMs on target tasks can be further improved by prompt tuning, which adds context to the input image or text. By leveraging data from target tasks, various prompt-tuning methods have been studied in the literature. A key to prompt tuning is the feature space alignment between two modalities via learnable vectors with model parameters fixed. We observed that the alignment becomes more effective when embeddings of each modality are `well-arranged' in the latent space. Inspired by this observation, we proposed distribution-aware prompt tuning (DAPT) for vision-language models, which is simple yet effective. Specifically, the prompts are learned by maximizing inter-dispersion, the distance between classes, as well as minimizing the intra-dispersion measured by the distance between embeddings from the same class. Our extensive experiments on 11 benchmark datasets demonstrate that our method significantly improves generalizability. The code is available at https://github.com/mlvlab/DAPT.
CoRGi: Content-Rich Graph Neural Networks with Attention
Oct 10, 2021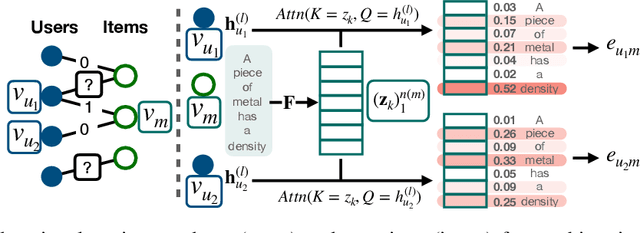

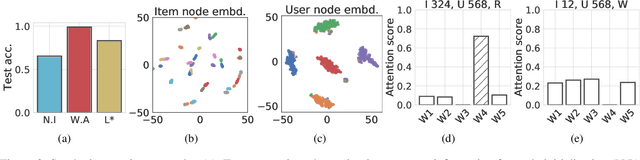
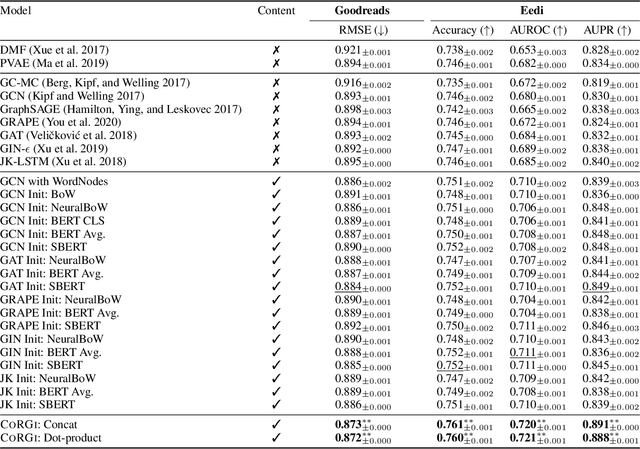
Graph representations of a target domain often project it to a set of entities (nodes) and their relations (edges). However, such projections often miss important and rich information. For example, in graph representations used in missing value imputation, items - represented as nodes - may contain rich textual information. However, when processing graphs with graph neural networks (GNN), such information is either ignored or summarized into a single vector representation used to initialize the GNN. Towards addressing this, we present CoRGi, a GNN that considers the rich data within nodes in the context of their neighbors. This is achieved by endowing CoRGi's message passing with a personalized attention mechanism over the content of each node. This way, CoRGi assigns user-item-specific attention scores with respect to the words that appear in an item's content. We evaluate CoRGi on two edge-value prediction tasks and show that CoRGi is better at making edge-value predictions over existing methods, especially on sparse regions of the graph.
Homogeneity-Based Transmissive Process to Model True and False News in Social Networks
Nov 16, 2018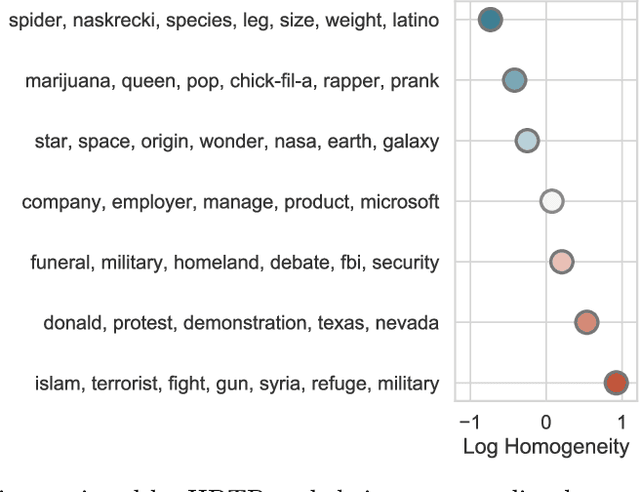
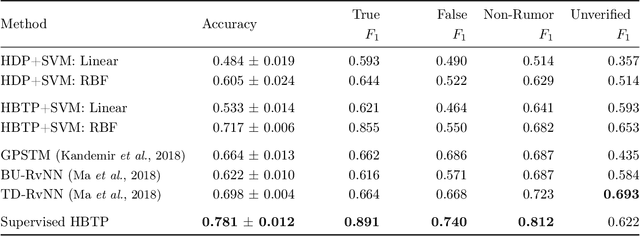
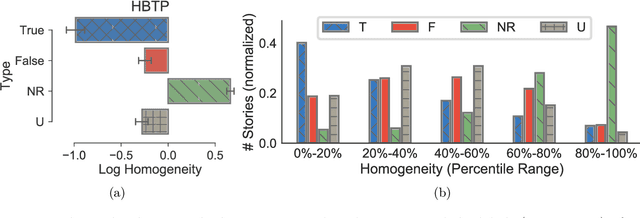
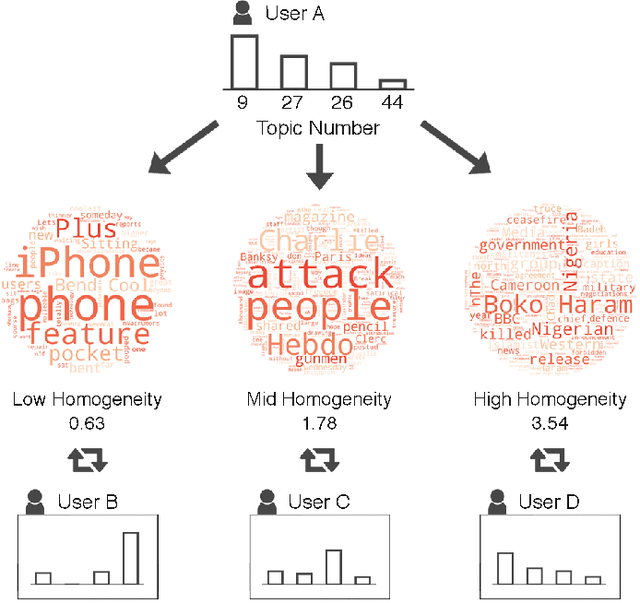
An overwhelming number of true and false news stories are posted and shared in social networks, and users diffuse the stories based on multiple factors. Diffusion of news stories from one user to another depends not only on the stories' content and the genuineness but also on the alignment of the topical interests between the users. In this paper, we propose a novel Bayesian nonparametric model that incorporates homogeneity of news stories as the key component that regulates the topical similarity between the posting and sharing users' topical interests. Our model extends hierarchical Dirichlet process to model the topics of the news stories and incorporates Bayesian Gaussian process latent variable model to discover the homogeneity values. We train our model on a real-world social network dataset and find homogeneity values of news stories that strongly relate to their labels of genuineness and their contents. Finally, we show that the supervised version of our model predicts the labels of news stories better than the state-of-the-art neural network and Bayesian models.
Leveraging the Crowd to Detect and Reduce the Spread of Fake News and Misinformation
Nov 27, 2017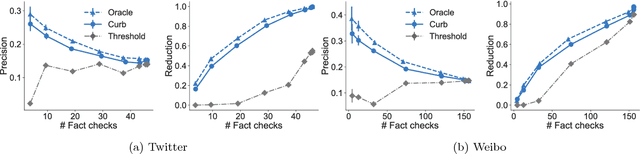
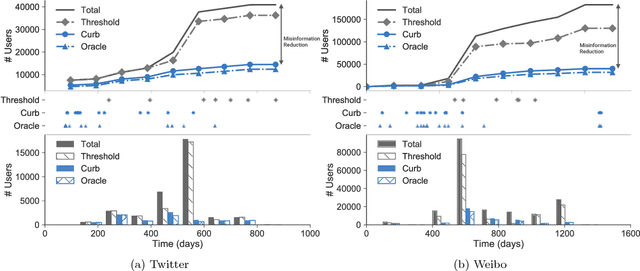
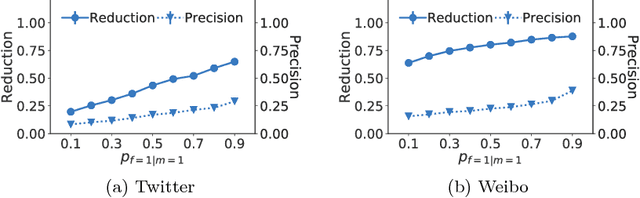
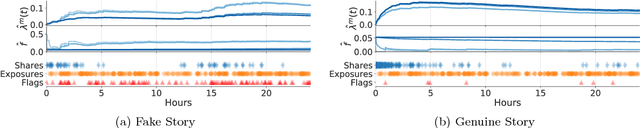
Online social networking sites are experimenting with the following crowd-powered procedure to reduce the spread of fake news and misinformation: whenever a user is exposed to a story through her feed, she can flag the story as misinformation and, if the story receives enough flags, it is sent to a trusted third party for fact checking. If this party identifies the story as misinformation, it is marked as disputed. However, given the uncertain number of exposures, the high cost of fact checking, and the trade-off between flags and exposures, the above mentioned procedure requires careful reasoning and smart algorithms which, to the best of our knowledge, do not exist to date. In this paper, we first introduce a flexible representation of the above procedure using the framework of marked temporal point processes. Then, we develop a scalable online algorithm, Curb, to select which stories to send for fact checking and when to do so to efficiently reduce the spread of misinformation with provable guarantees. In doing so, we need to solve a novel stochastic optimal control problem for stochastic differential equations with jumps, which is of independent interest. Experiments on two real-world datasets gathered from Twitter and Weibo show that our algorithm may be able to effectively reduce the spread of fake news and misinformation.
Joint Modeling of Topics, Citations, and Topical Authority in Academic Corpora
Jun 02, 2017Much of scientific progress stems from previously published findings, but searching through the vast sea of scientific publications is difficult. We often rely on metrics of scholarly authority to find the prominent authors but these authority indices do not differentiate authority based on research topics. We present Latent Topical-Authority Indexing (LTAI) for jointly modeling the topics, citations, and topical authority in a corpus of academic papers. Compared to previous models, LTAI differs in two main aspects. First, it explicitly models the generative process of the citations, rather than treating the citations as given. Second, it models each author's influence on citations of a paper based on the topics of the cited papers, as well as the citing papers. We fit LTAI to four academic corpora: CORA, Arxiv Physics, PNAS, and Citeseer. We compare the performance of LTAI against various baselines, starting with the latent Dirichlet allocation, to the more advanced models including author-link topic model and dynamic author citation topic model. The results show that LTAI achieves improved accuracy over other similar models when predicting words, citations and authors of publications.