 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CLIP4Caption ++: Multi-CLIP for Video Caption
Oct 14, 2021
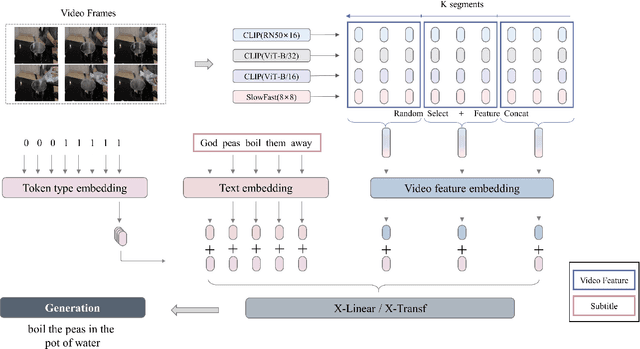
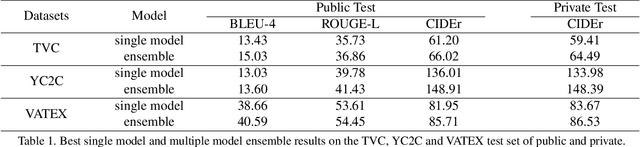

This report describes our solution to the VALUE Challenge 2021 in the captioning task. Our solution, named CLIP4Caption++, is built on X-Linear/X-Transformer, which is an advanced model with encoder-decoder architecture. We make the following improvements on the proposed CLIP4Caption++: We employ an advanced encoder-decoder model architecture X-Transformer as our main framework and make the following improvements: 1) we utilize three strong pre-trained CLIP models to extract the text-related appearance visual features. 2) we adopt the TSN sampling strategy for data enhancement. 3) we involve the video subtitle information to provide richer semantic information. 3) we introduce the subtitle information, which fuses with the visual features as guidance. 4) we design word-level and sentence-level ensemble strategies. Our proposed method achieves 86.5, 148.4, 64.5 CIDEr scores on VATEX, YC2C, and TVC datasets, respectively, which shows the superior performance of our proposed CLIP4Caption++ on all three datasets.
Using Large-scale Heterogeneous Graph Representation Learning for Code Review Recommendations
Feb 04, 2022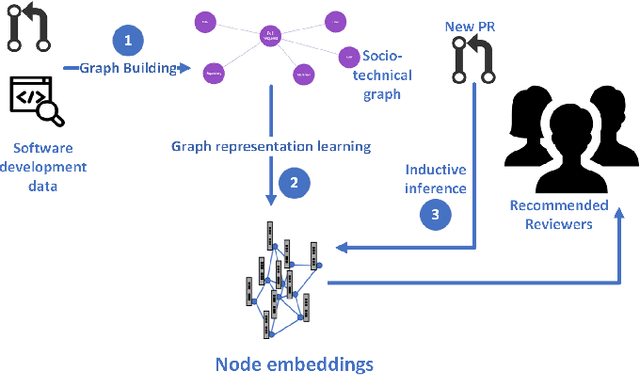
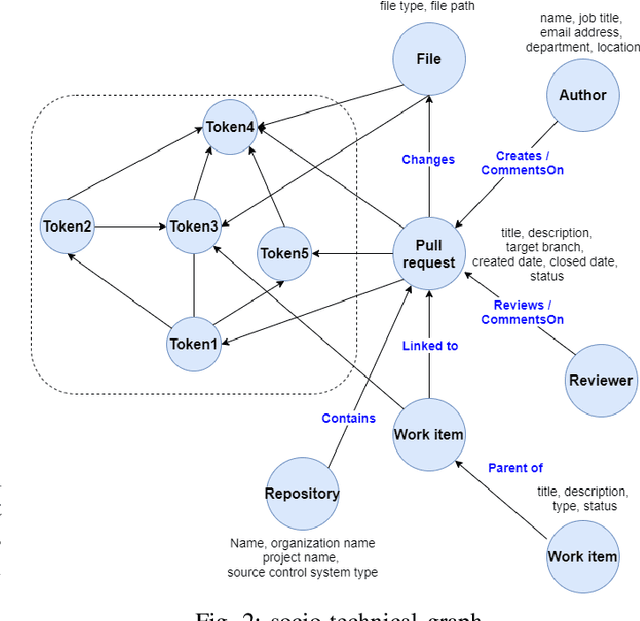
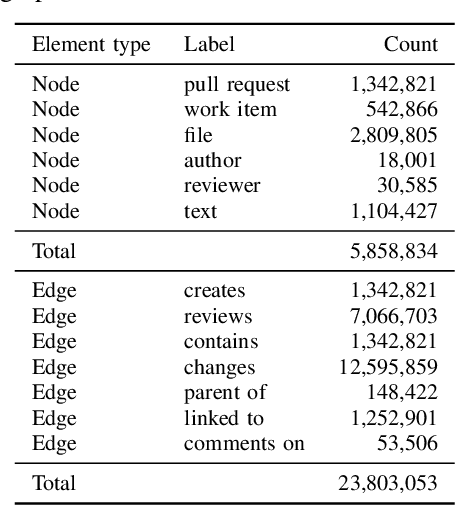

Code review is an integral part of any mature software development process, and identifying the best reviewer for a code change is a well accepted problem within the software engineering community. Selecting a reviewer who lacks expertise and understanding can slow development or result in more defects. To date, most reviewer recommendation systems rely primarily on historical file change and review information; those who changed or reviewed a file in the past are the best positioned to review in the future. We posit that while these approaches are able to identify and suggest qualified reviewers, they may be blind to reviewers who have the needed expertise and have simply never interacted with the changed files before. To address this, we present CORAL, a novel approach to reviewer recommendation that leverages a socio-technical graph built from the rich set of entities (developers, repositories, files, pull requests, work-items, etc.) and their relationships in modern source code management systems. We employ a graph convolutional neural network on this graph and train it on two and a half years of history on 332 repositories. We show that CORAL is able to model the manual history of reviewer selection remarkably well. Further, based on an extensive user study, we demonstrate that this approach identifies relevant and qualified reviewers who traditional reviewer recommenders miss, and that these developers desire to be included in the review process. Finally, we find that "classical" reviewer recommendation systems perform better on smaller (in terms of developers) software projects while CORAL excels on larger projects, suggesting that there is "no one model to rule them all."
Is Dynamic Rumor Detection on social media Viable? An Unsupervised Perspective
Nov 23, 2021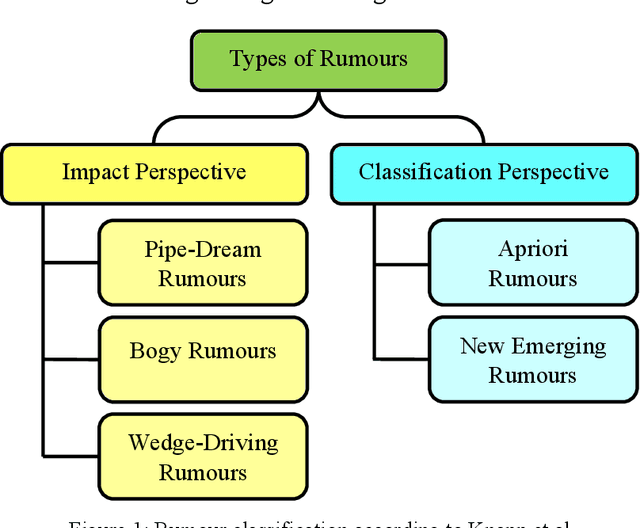
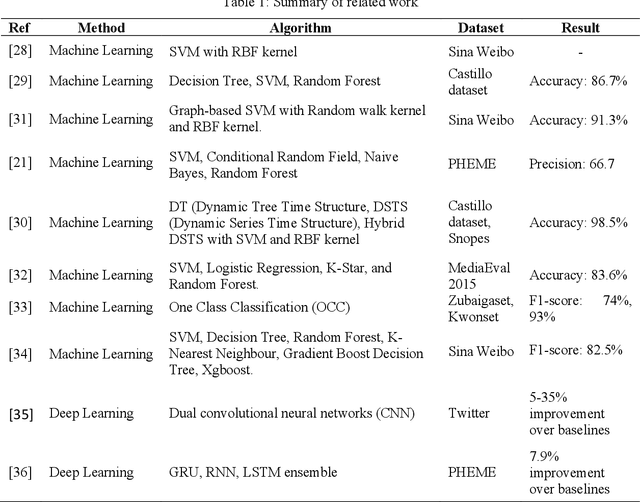
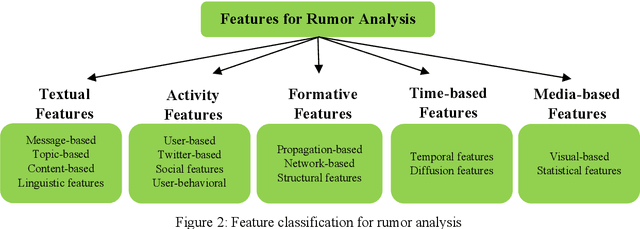
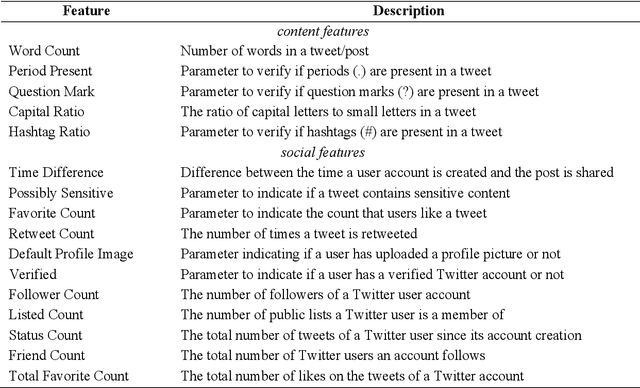
With the growing popularity and ease of access to the internet, the problem of online rumors is escalating. People are relying on social media to gain information readily but fall prey to false information. There is a lack of credibility assessment techniques for online posts to identify rumors as soon as they arrive. Existing studies have formulated several mechanisms to combat online rumors by developing machine learning and deep learning algorithms. The literature so far provides supervised frameworks for rumor classification that rely on huge training datasets. However, in the online scenario where supervised learning is exigent, dynamic rumor identification becomes difficult. Early detection of online rumors is a challenging task, and studies relating to them are relatively few. It is the need of the hour to identify rumors as soon as they appear online. This work proposes a novel framework for unsupervised rumor detection that relies on an online post's content and social features using state-of-the-art clustering techniques. The proposed architecture outperforms several existing baselines and performs better than several supervised techniques. The proposed method, being lightweight, simple, and robust, offers the suitability of being adopted as a tool for online rumor identification.
English-to-Chinese Transliteration with Phonetic Back-transliteration
Dec 20, 2021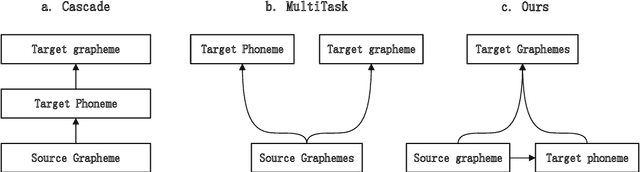
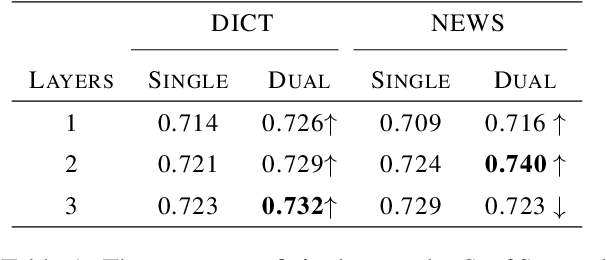
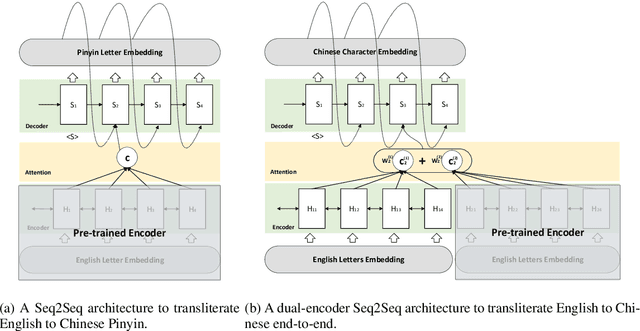
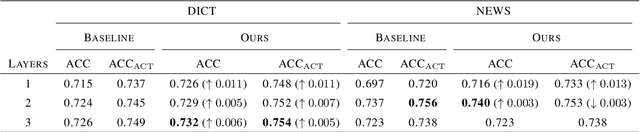
Transliteration is a task of translating named entities from a language to another, based on phonetic similarity. The task has embraced deep learning approaches in recent years, yet, most ignore the phonetic features of the involved languages. In this work, we incorporate phonetic information into neural networks in two ways: we synthesize extra data using forward and back-translation but in a phonetic manner; and we pre-train models on a phonetic task before learning transliteration. Our experiments include three language pairs and six directions, namely English to and from Chinese, Hebrew and Thai. Results indicate that our proposed approach brings benefits to the model and achieves better or similar performance when compared to state of the art.
Learning Representations and Agents for Information Retrieval
Aug 16, 2019

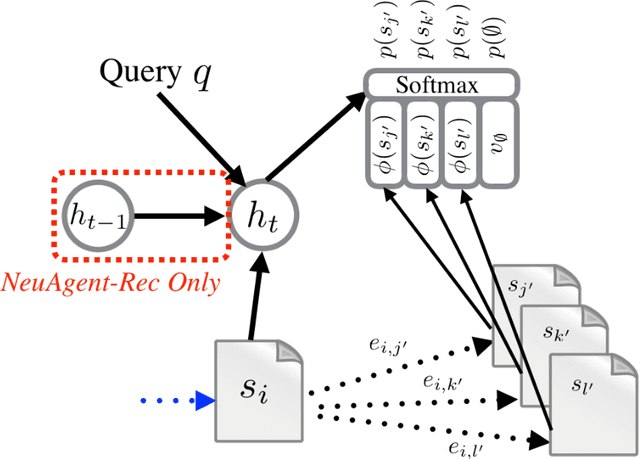

A goal shared by artificial intelligence and information retrieval is to create an oracle, that is, a machine that can answer our questions, no matter how difficult they are. A more limited, but still instrumental, version of this oracle is a question-answering system, in which an open-ended question is given to the machine, and an answer is produced based on the knowledge it has access to. Such systems already exist and are increasingly capable of answering complicated questions. This progress can be partially attributed to the recent success of machine learning and to the efficient methods for storing and retrieving information, most notably through web search engines. One can imagine that this general-purpose question-answering system can be built as a billion-parameters neural network trained end-to-end with a large number of pairs of questions and answers. We argue, however, that although this approach has been very successful for tasks such as machine translation, storing the world's knowledge as parameters of a learning machine can be very hard. A more efficient way is to train an artificial agent on how to use an external retrieval system to collect relevant information. This agent can leverage the effort that has been put into designing and running efficient storage and retrieval systems by learning how to best utilize them to accomplish a task. ...
Head2Toe: Utilizing Intermediate Representations for Better Transfer Learning
Jan 10, 2022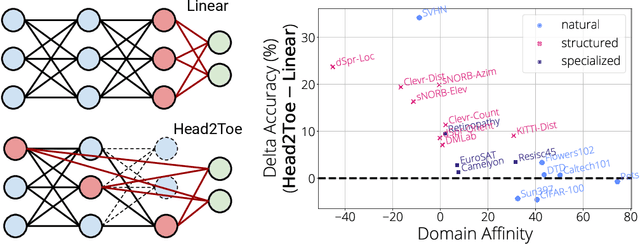
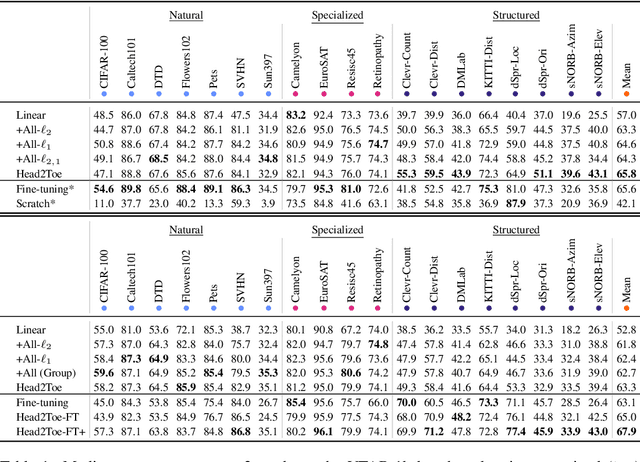
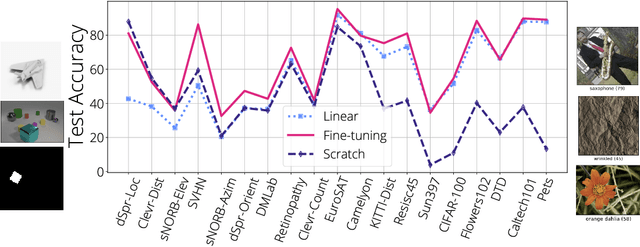
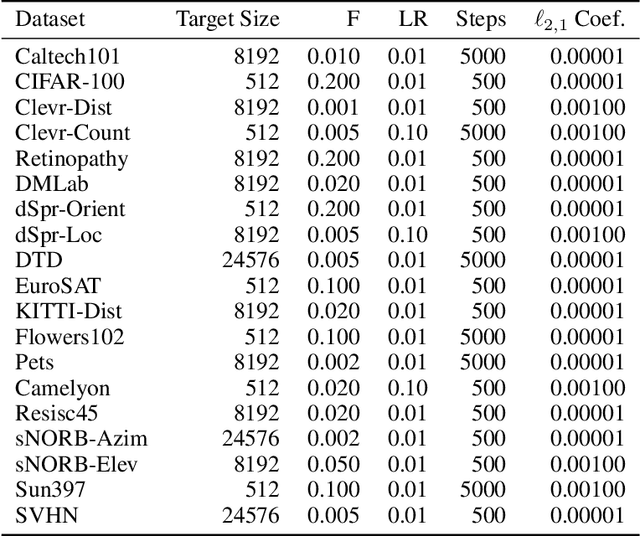
Transfer-learning methods aim to improve performance in a data-scarce target domain using a model pretrained on a data-rich source domain. A cost-efficient strategy, linear probing, involves freezing the source model and training a new classification head for the target domain. This strategy is outperformed by a more costly but state-of-the-art method -- fine-tuning all parameters of the source model to the target domain -- possibly because fine-tuning allows the model to leverage useful information from intermediate layers which is otherwise discarded by the later pretrained layers. We explore the hypothesis that these intermediate layers might be directly exploited. We propose a method, Head-to-Toe probing (Head2Toe), that selects features from all layers of the source model to train a classification head for the target-domain. In evaluations on the VTAB-1k, Head2Toe matches performance obtained with fine-tuning on average while reducing training and storage cost hundred folds or more, but critically, for out-of-distribution transfer, Head2Toe outperforms fine-tuning.
Neural Architecture Searching for Facial Attributes-based Depression Recognition
Jan 24, 2022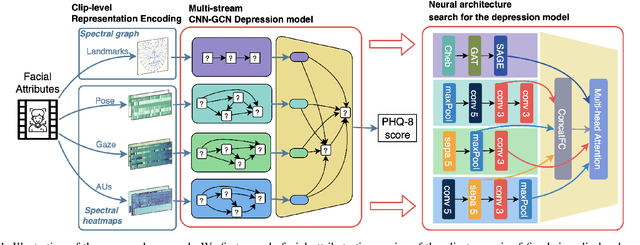
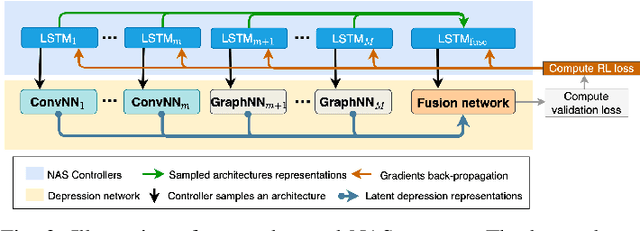
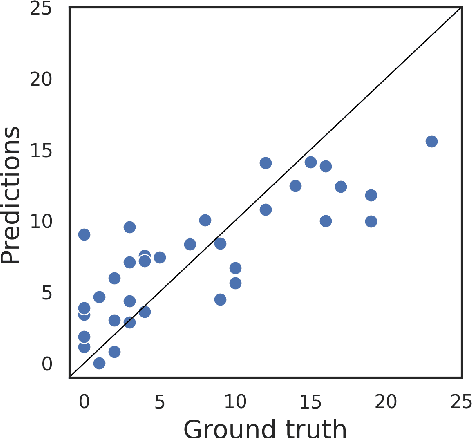
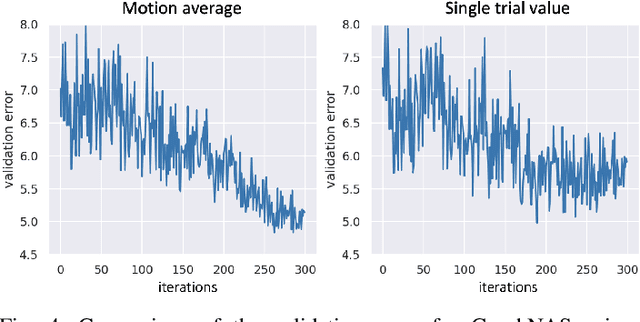
Recent studies show that depression can be partially reflected from human facial attributes. Since facial attributes have various data structure and carry different information, existing approaches fail to specifically consider the optimal way to extract depression-related features from each of them, as well as investigates the best fusion strategy. In this paper, we propose to extend Neural Architecture Search (NAS) technique for designing an optimal model for multiple facial attributes-based depression recognition, which can be efficiently and robustly implemented in a small dataset. Our approach first conducts a warmer up step to the feature extractor of each facial attribute, aiming to largely reduce the search space and providing customized architecture, where each feature extractor can be either a Convolution Neural Networks (CNN) or Graph Neural Networks (GNN). Then, we conduct an end-to-end architecture search for all feature extractors and the fusion network, allowing the complementary depression cues to be optimally combined with less redundancy. The experimental results on AVEC 2016 dataset show that the model explored by our approach achieves breakthrough performance with 27\% and 30\% RMSE and MAE improvements over the existing state-of-the-art. In light of these findings, this paper provides solid evidences and a strong baseline for applying NAS to time-series data-based mental health analysis.
Learning When and What to Ask: a Hierarchical Reinforcement Learning Framework
Oct 14, 2021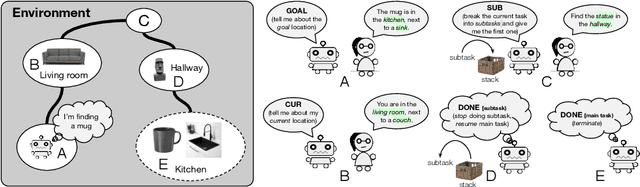
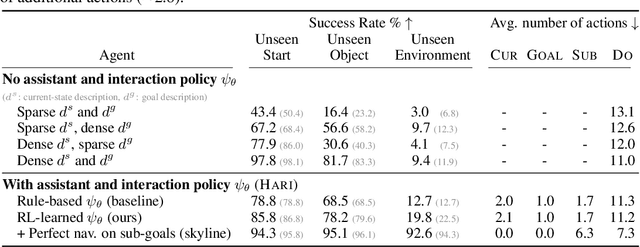

Reliable AI agents should be mindful of the limits of their knowledge and consult humans when sensing that they do not have sufficient knowledge to make sound decisions. We formulate a hierarchical reinforcement learning framework for learning to decide when to request additional information from humans and what type of information would be helpful to request. Our framework extends partially-observed Markov decision processes (POMDPs) by allowing an agent to interact with an assistant to leverage their knowledge in accomplishing tasks. Results on a simulated human-assisted navigation problem demonstrate the effectiveness of our framework: aided with an interaction policy learned by our method, a navigation policy achieves up to a 7x improvement in task success rate compared to performing tasks only by itself. The interaction policy is also efficient: on average, only a quarter of all actions taken during a task execution are requests for information. We analyze benefits and challenges of learning with a hierarchical policy structure and suggest directions for future work.
Pre-Trained Neural Language Models for Automatic Mobile App User Feedback Answer Generation
Feb 04, 2022Studies show that developers' answers to the mobile app users' feedbacks on app stores can increase the apps' star rating. To help app developers generate answers that are related to the users' issues, recent studies develop models to generate the answers automatically. Aims: The app response generation models use deep neural networks and require training data. Pre-Trained neural language Models (PTM) used in Natural Language Processing (NLP) take advantage of the information they learned from a large corpora in an unsupervised manner, and can reduce the amount of required training data. In this paper, we evaluate PTMs to generate replies to the mobile app user feedbacks. Method: We train a Transformer model from scratch and fine-tune two PTMs to evaluate the generated responses, which are compared to RRGEN, a current app response model. We also evaluate the models with different portions of the training data. Results: The results on a large dataset evaluated by automatic metrics show that PTMs obtain lower scores than the baselines. However, our human evaluation confirms that PTMs can generate more relevant and meaningful responses to the posted feedbacks. Moreover, the performance of PTMs has less drop compared to other models when the amount of training data is reduced to 1/3. Conclusion: PTMs are useful in generating responses to app reviews and are more robust models to the amount of training data provided. However, the prediction time is 19X than RRGEN. This study can provide new avenues for research in adapting the PTMs for analyzing mobile app user feedbacks. Index Terms-mobile app user feedback analysis, neural pre-trained language models, automatic answer generation
Single-Modal Entropy based Active Learning for Visual Question Answering
Nov 18, 2021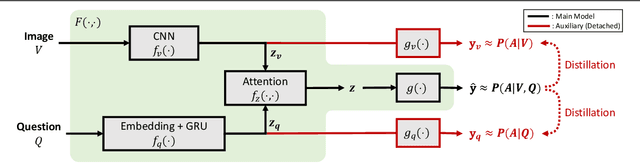
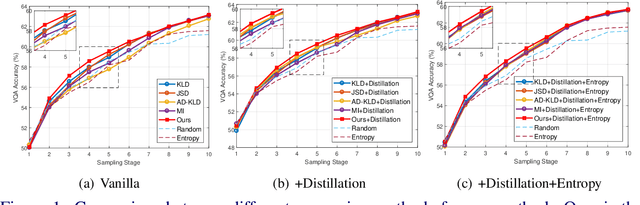
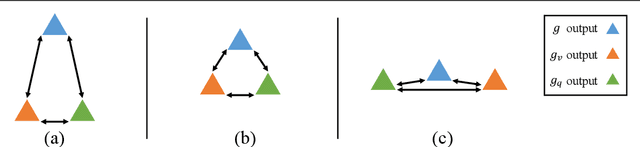
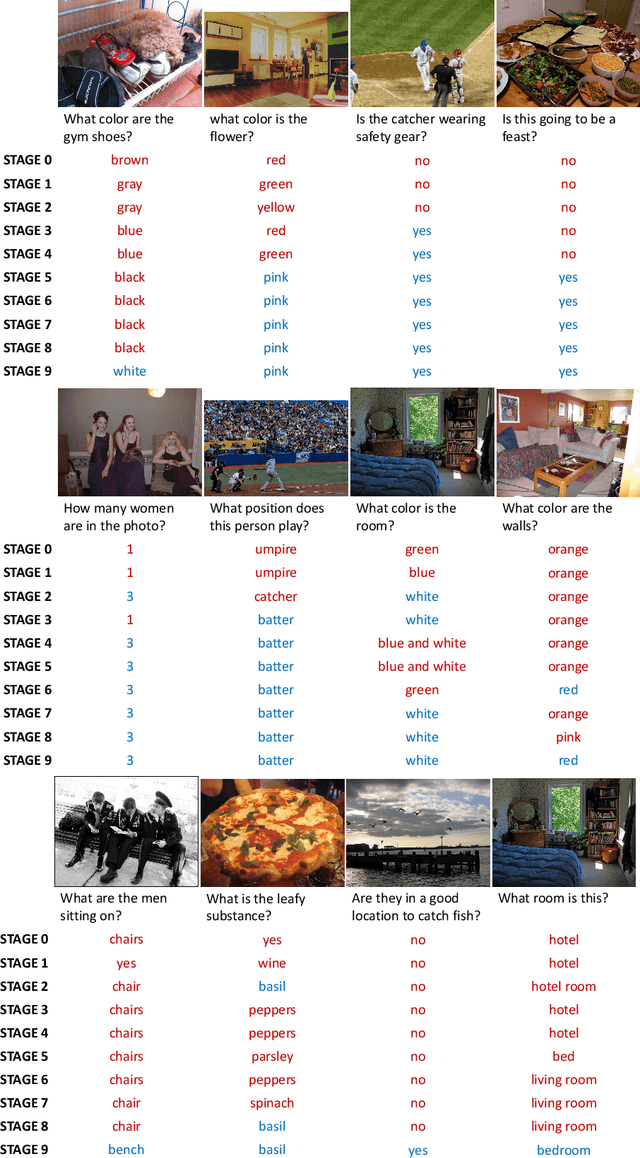
Constructing a large-scale labeled dataset in the real world, especially for high-level tasks (eg, Visual Question Answering), can be expensive and time-consuming. In addition, with the ever-growing amounts of data and architecture complexity, Active Learning has become an important aspect of computer vision research. In this work, we address Active Learning in the multi-modal setting of Visual Question Answering (VQA). In light of the multi-modal inputs, image and question, we propose a novel method for effective sample acquisition through the use of ad hoc single-modal branches for each input to leverage its information. Our mutual information based sample acquisition strategy Single-Modal Entropic Measure (SMEM) in addition to our self-distillation technique enables the sample acquisitor to exploit all present modalities and find the most informative samples. Our novel idea is simple to implement, cost-efficient, and readily adaptable to other multi-modal tasks. We confirm our findings on various VQA datasets through state-of-the-art performance by comparing to existing Active Learning baselines.