 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
On the Preservation of Spatio-temporal Information in Machine Learning Applications
Jun 15, 2020
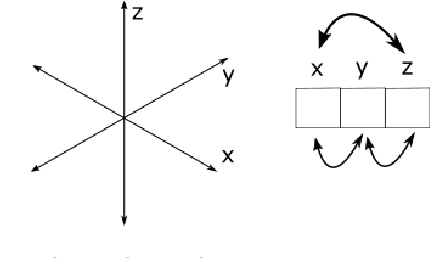
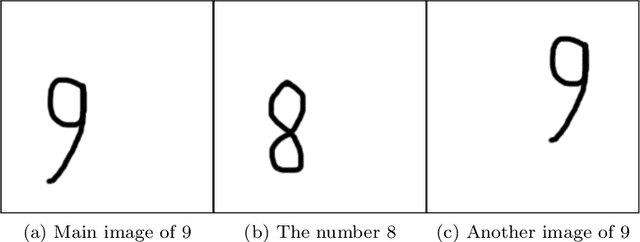
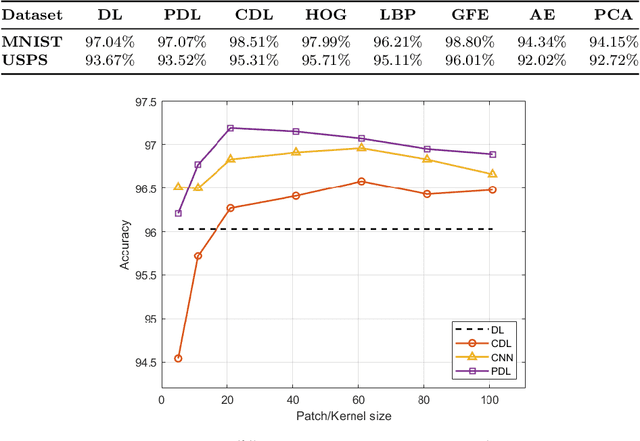
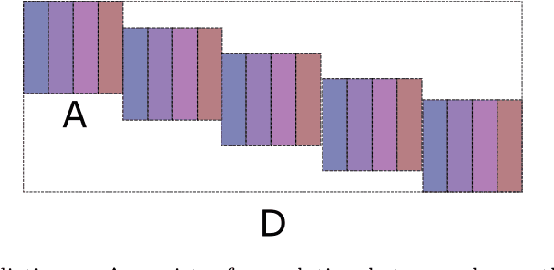
In conventional machine learning applications, each data attribute is assumed to be orthogonal to others. Namely, every pair of dimension is orthogonal to each other and thus there is no distinction of in-between relations of dimensions. However, this is certainly not the case in real world signals which naturally originate from a spatio-temporal configuration. As a result, the conventional vectorization process disrupts all of the spatio-temporal information about the order/place of data whether it be $1$D, $2$D, $3$D, or $4$D. In this paper, the problem of orthogonality is first investigated through conventional $k$-means of images, where images are to be processed as vectors. As a solution, shift-invariant $k$-means is proposed in a novel framework with the help of sparse representations. A generalization of shift-invariant $k$-means, convolutional dictionary learning, is then utilized as an unsupervised feature extraction method for classification. Experiments suggest that Gabor feature extraction as a simulation of shallow convolutional neural networks provides a little better performance compared to convolutional dictionary learning. Many alternatives of convolutional-logic are also discussed for spatio-temporal information preservation, including a spatio-temporal hypercomplex encoding scheme.
A Unified Framework for Campaign Performance Forecasting in Online Display Advertising
Feb 24, 2022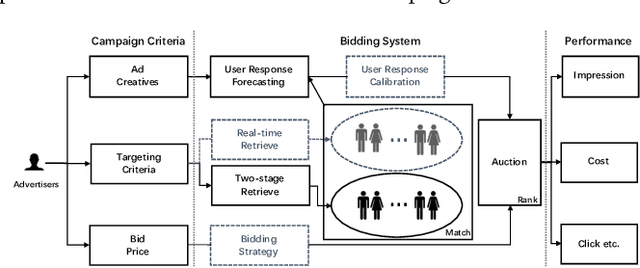

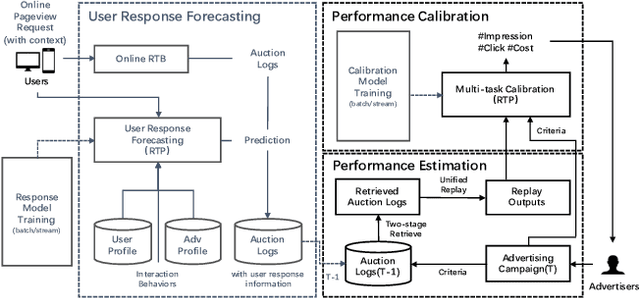

Advertisers usually enjoy the flexibility to choose criteria like target audience, geographic area and bid price when planning an campaign for online display advertising, while they lack forecast information on campaign performance to optimize delivery strategies in advance, resulting in a waste of labour and budget for feedback adjustments. In this paper, we aim to forecast key performance indicators for new campaigns given any certain criteria. Interpretable and accurate results could enable advertisers to manage and optimize their campaign criteria. There are several challenges for this very task. First, platforms usually offer advertisers various criteria when they plan an advertising campaign, it is difficult to estimate campaign performance unifiedly because of the great difference among bidding types. Furthermore, complex strategies applied in bidding system bring great fluctuation on campaign performance, making estimation accuracy an extremely tough problem. To address above challenges, we propose a novel Campaign Performance Forecasting framework, which firstly reproduces campaign performance on historical logs under various bidding types with a unified replay algorithm, in which essential auction processes like match and rank are replayed, ensuring the interpretability on forecast results. Then, we innovatively introduce a multi-task learning method to calibrate the deviation of estimation brought by hard-to-reproduce bidding strategies in replay. The method captures mixture calibration patterns among related forecast indicators to map the estimated results to the true ones, improving both accuracy and efficiency significantly. Experiment results on a dataset from Taobao.com demonstrate that the proposed framework significantly outperforms other baselines by a large margin, and an online A/B test verifies its effectiveness in the real world.
Evaluating the Robustness of Retrieval Pipelines with Query Variation Generators
Nov 25, 2021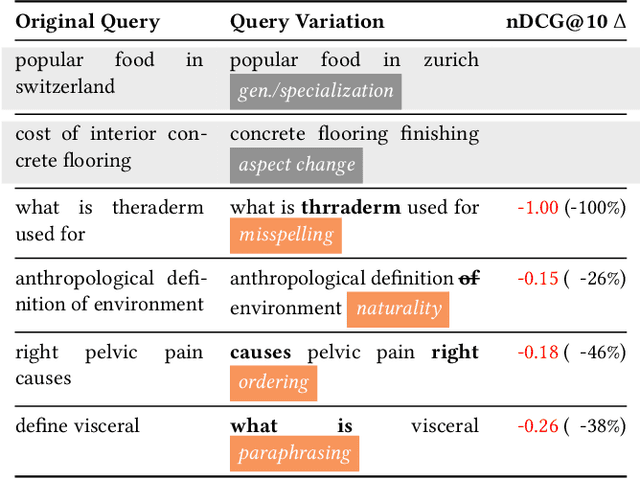
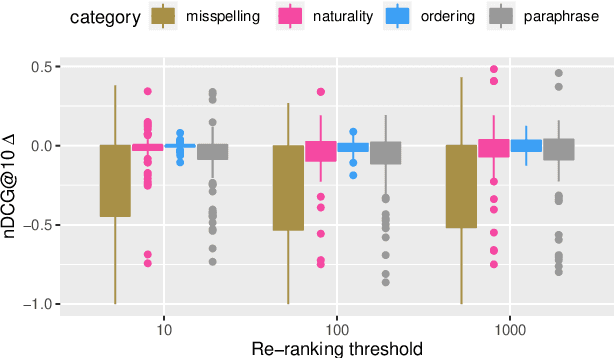
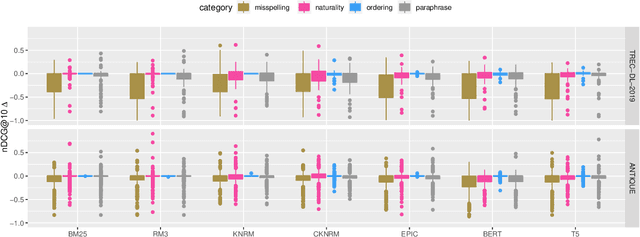
Heavily pre-trained transformers for language modelling, such as BERT, have shown to be remarkably effective for Information Retrieval (IR) tasks, typically applied to re-rank the results of a first-stage retrieval model. IR benchmarks evaluate the effectiveness of retrieval pipelines based on the premise that a single query is used to instantiate the underlying information need. However, previous research has shown that (I) queries generated by users for a fixed information need are extremely variable and, in particular, (II) neural models are brittle and often make mistakes when tested with modified inputs. Motivated by those observations we aim to answer the following question: how robust are retrieval pipelines with respect to different variations in queries that do not change the queries' semantics? In order to obtain queries that are representative of users' querying variability, we first created a taxonomy based on the manual annotation of transformations occurring in a dataset (UQV100) of user-created query variations. For each syntax-changing category of our taxonomy, we employed different automatic methods that when applied to a query generate a query variation. Our experimental results across two datasets for two IR tasks reveal that retrieval pipelines are not robust to these query variations, with effectiveness drops of $\approx20\%$ on average. The code and datasets are available at https://github.com/Guzpenha/query_variation_generators.
Extending compositional data analysis from a graph signal processing perspective
Jan 25, 2022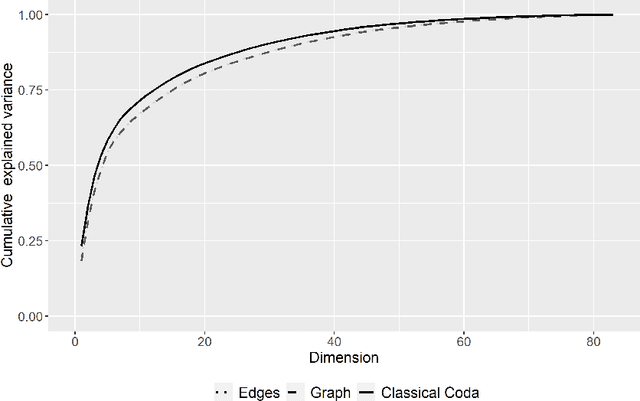
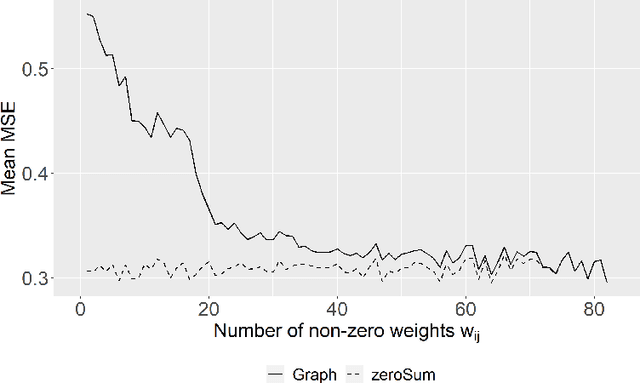
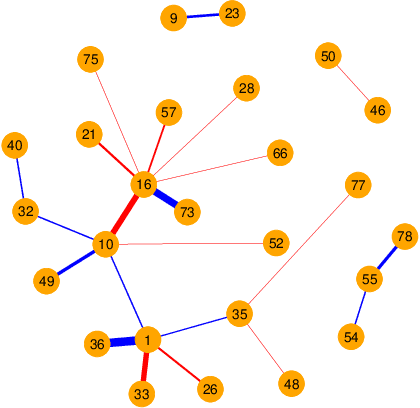
Traditional methods for the analysis of compositional data consider the log-ratios between all different pairs of variables with equal weight, typically in the form of aggregated contributions. This is not meaningful in contexts where it is known that a relationship only exists between very specific variables (e.g.~for metabolomic pathways), while for other pairs a relationship does not exist. Modeling absence or presence of relationships is done in graph theory, where the vertices represent the variables, and the connections refer to relations. This paper links compositional data analysis with graph signal processing, and it extends the Aitchison geometry to a setting where only selected log-ratios can be considered. The presented framework retains the desirable properties of scale invariance and compositional coherence. An additional extension to include absolute information is readily made. Examples from bioinformatics and geochemistry underline the usefulness of thisapproach in comparison to standard methods for compositional data analysis.
Deep ViT Features as Dense Visual Descriptors
Dec 10, 2021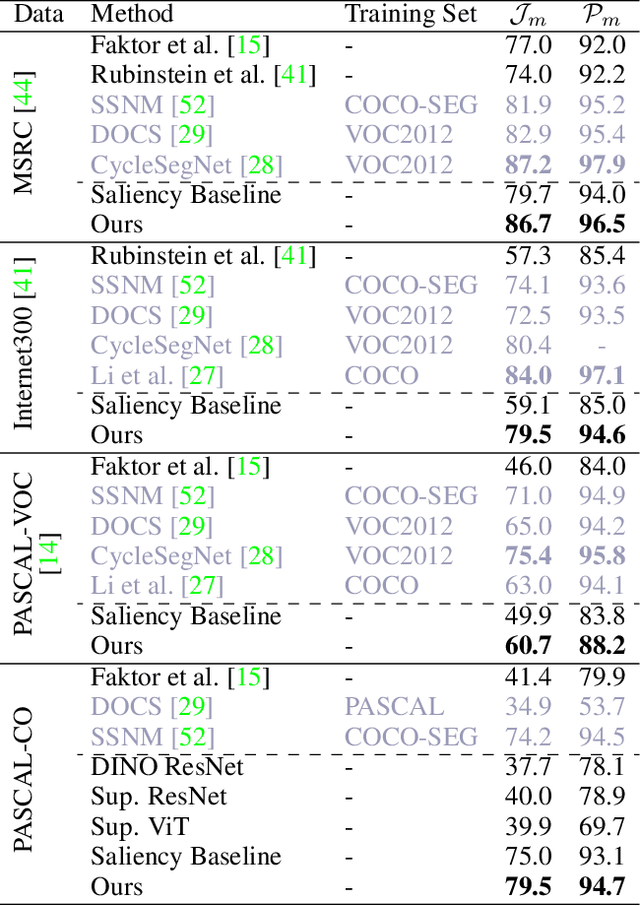
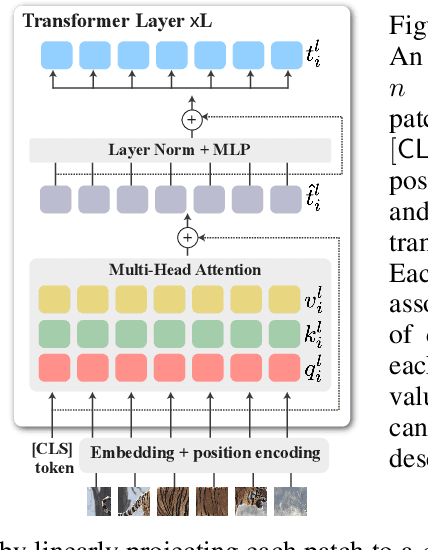
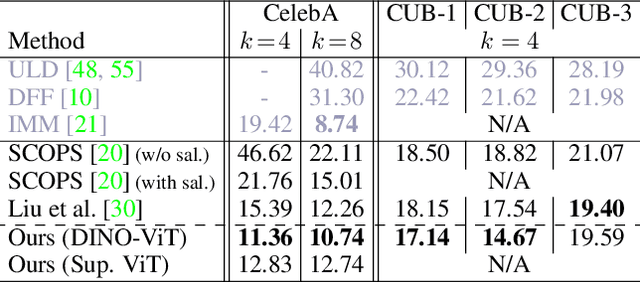
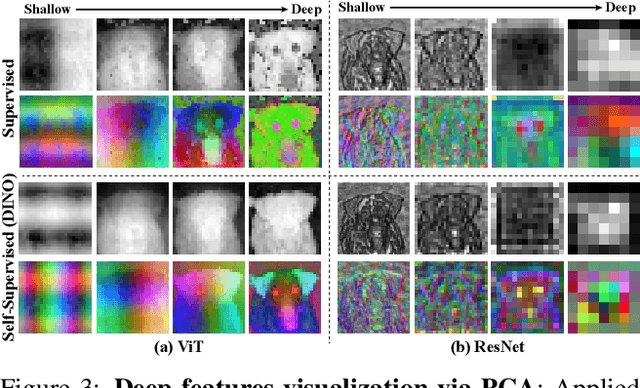
We leverage deep features extracted from a pre-trained Vision Transformer (ViT) as dense visual descriptors. We demonstrate that such features, when extracted from a self-supervised ViT model (DINO-ViT), exhibit several striking properties: (i) the features encode powerful high level information at high spatial resolution -- i.e., capture semantic object parts at fine spatial granularity, and (ii) the encoded semantic information is shared across related, yet different object categories (i.e. super-categories). These properties allow us to design powerful dense ViT descriptors that facilitate a variety of applications, including co-segmentation, part co-segmentation and correspondences -- all achieved by applying lightweight methodologies to deep ViT features (e.g., binning / clustering). We take these applications further to the realm of inter-class tasks -- demonstrating how objects from related categories can be commonly segmented into semantic parts, under significant pose and appearance changes. Our methods, extensively evaluated qualitatively and quantitatively, achieve state-of-the-art part co-segmentation results, and competitive results with recent supervised methods trained specifically for co-segmentation and correspondences.
Insta-VAX: A Multimodal Benchmark for Anti-Vaccine and Misinformation Posts Detection on Social Media
Dec 15, 2021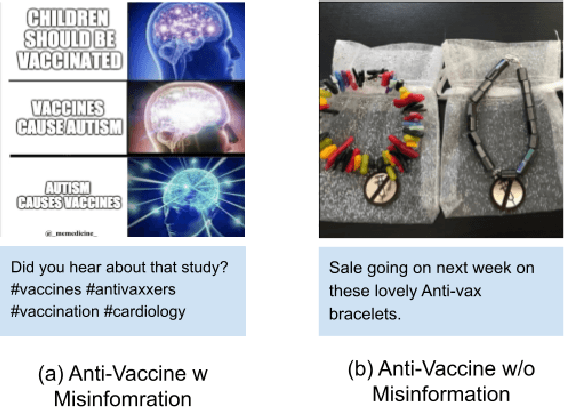
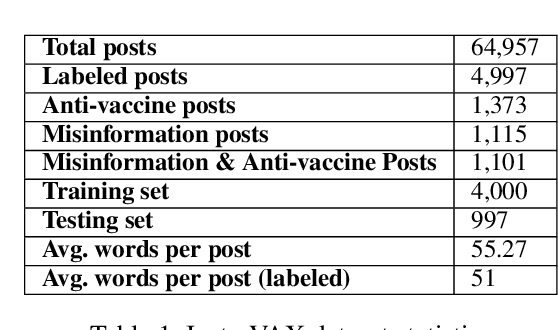
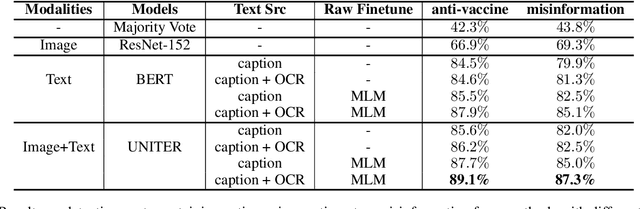

Sharing of anti-vaccine posts on social media, including misinformation posts, has been shown to create confusion and reduce the publics confidence in vaccines, leading to vaccine hesitancy and resistance. Recent years have witnessed the fast rise of such anti-vaccine posts in a variety of linguistic and visual forms in online networks, posing a great challenge for effective content moderation and tracking. Extending previous work on leveraging textual information to understand vaccine information, this paper presents Insta-VAX, a new multi-modal dataset consisting of a sample of 64,957 Instagram posts related to human vaccines. We applied a crowdsourced annotation procedure verified by two trained expert judges to this dataset. We then bench-marked several state-of-the-art NLP and computer vision classifiers to detect whether the posts show anti-vaccine attitude and whether they contain misinformation. Extensive experiments and analyses demonstrate the multimodal models can classify the posts more accurately than the uni-modal models, but still need improvement especially on visual context understanding and external knowledge cooperation. The dataset and classifiers contribute to monitoring and tracking of vaccine discussions for social scientific and public health efforts in combating the problem of vaccine misinformation.
Optimal Clustering with Bandit Feedback
Feb 09, 2022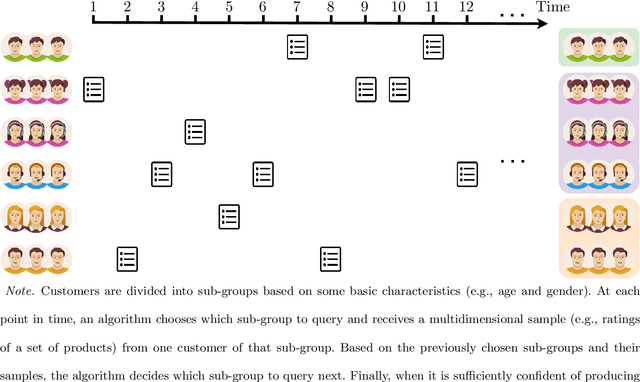
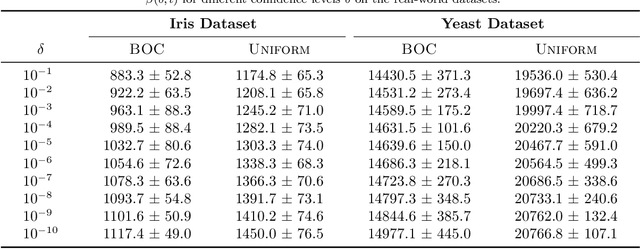
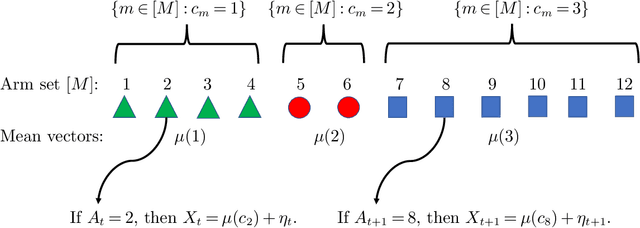
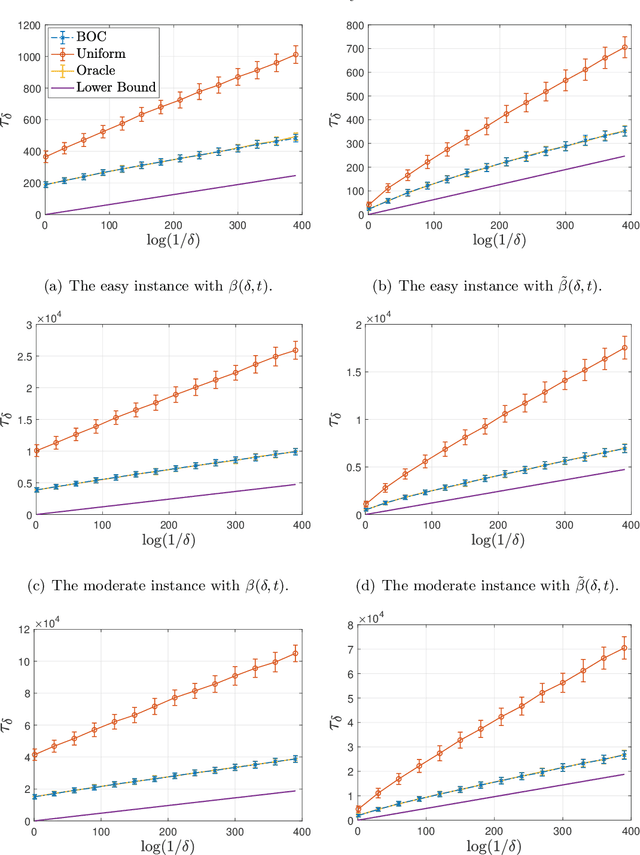
This paper considers the problem of online clustering with bandit feedback. A set of arms (or items) can be partitioned into various groups that are unknown. Within each group, the observations associated to each of the arms follow the same distribution with the same mean vector. At each time step, the agent queries or pulls an arm and obtains an independent observation from the distribution it is associated to. Subsequent pulls depend on previous ones as well as the previously obtained samples. The agent's task is to uncover the underlying partition of the arms with the least number of arm pulls and with a probability of error not exceeding a prescribed constant $\delta$. The problem proposed finds numerous applications from clustering of variants of viruses to online market segmentation. We present an instance-dependent information-theoretic lower bound on the expected sample complexity for this task, and design a computationally efficient and asymptotically optimal algorithm, namely Bandit Online Clustering (BOC). The algorithm includes a novel stopping rule for adaptive sequential testing that circumvents the need to exactly solve any NP-hard weighted clustering problem as its subroutines. We show through extensive simulations on synthetic and real-world datasets that BOC's performance matches the lower bound asymptotically, and significantly outperforms a non-adaptive baseline algorithm.
Retrieval-Augmented Reinforcement Learning
Feb 17, 2022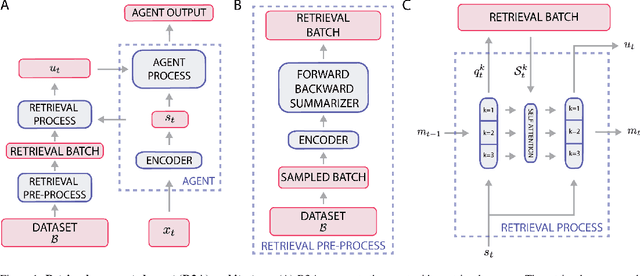

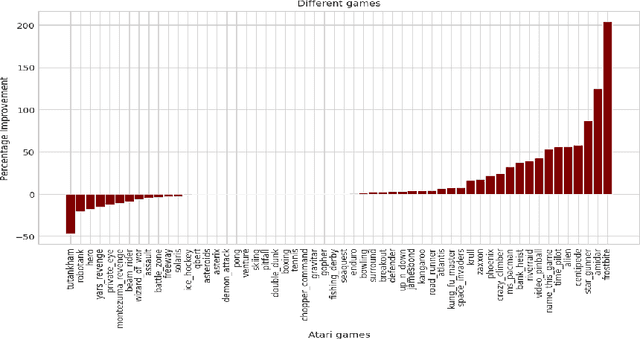
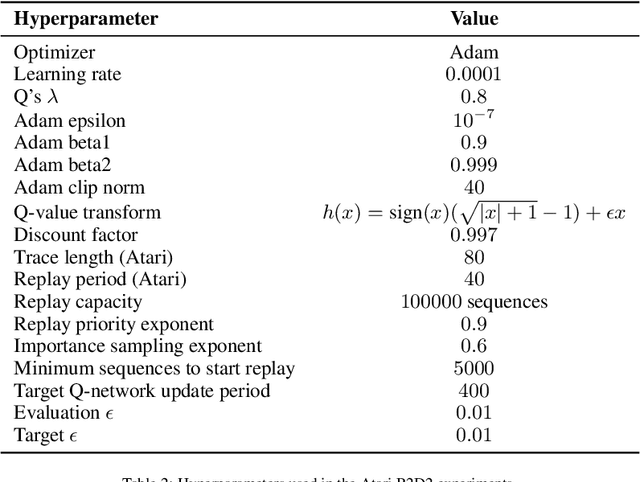
Most deep reinforcement learning (RL) algorithms distill experience into parametric behavior policies or value functions via gradient updates. While effective, this approach has several disadvantages: (1) it is computationally expensive, (2) it can take many updates to integrate experiences into the parametric model, (3) experiences that are not fully integrated do not appropriately influence the agent's behavior, and (4) behavior is limited by the capacity of the model. In this paper we explore an alternative paradigm in which we train a network to map a dataset of past experiences to optimal behavior. Specifically, we augment an RL agent with a retrieval process (parameterized as a neural network) that has direct access to a dataset of experiences. This dataset can come from the agent's past experiences, expert demonstrations, or any other relevant source. The retrieval process is trained to retrieve information from the dataset that may be useful in the current context, to help the agent achieve its goal faster and more efficiently. We integrate our method into two different RL agents: an offline DQN agent and an online R2D2 agent. In offline multi-task problems, we show that the retrieval-augmented DQN agent avoids task interference and learns faster than the baseline DQN agent. On Atari, we show that retrieval-augmented R2D2 learns significantly faster than the baseline R2D2 agent and achieves higher scores. We run extensive ablations to measure the contributions of the components of our proposed method.
Direct Training via Backpropagation for Ultra-low Latency Spiking Neural Networks with Multi-threshold
Nov 25, 2021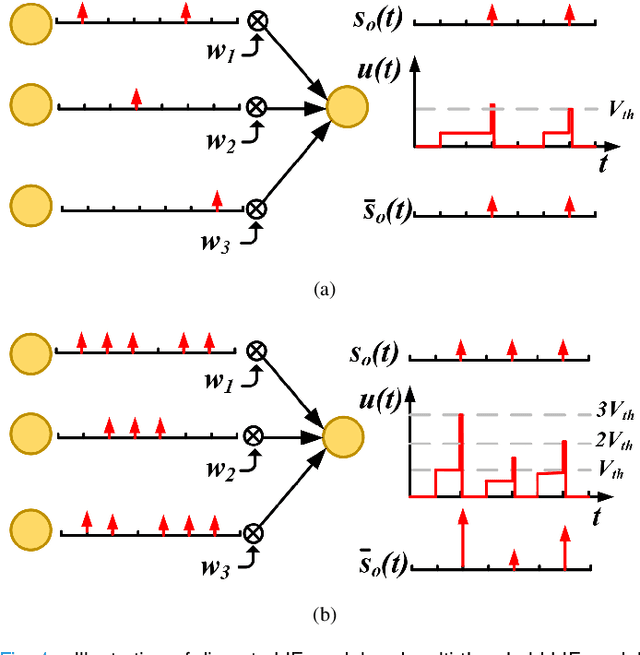
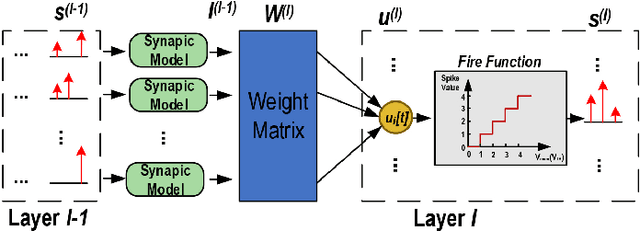
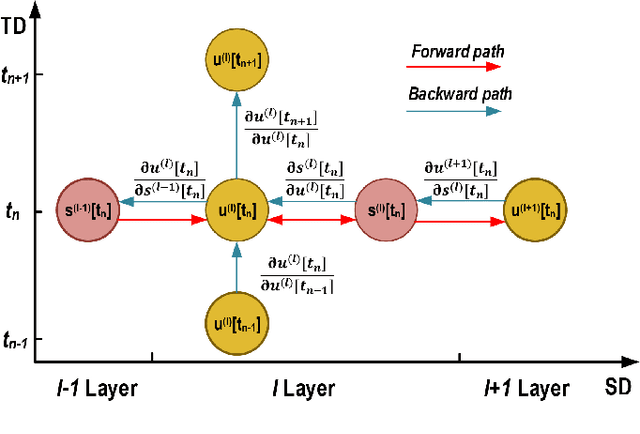
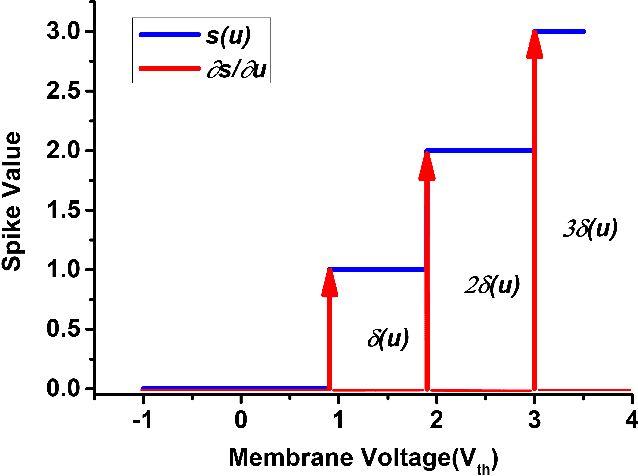
Spiking neural networks (SNNs) can utilize spatio-temporal information and have a nature of energy efficiency which is a good alternative to deep neural networks(DNNs). The event-driven information processing makes SNNs can reduce the expensive computation of DNNs and save a lot of energy consumption. However, high training and inference latency is a limitation of the development of deeper SNNs. SNNs usually need tens or even hundreds of time steps during the training and inference process which causes not only the increase of latency but also the waste of energy consumption. To overcome this problem, we proposed a novel training method based on backpropagation (BP) for ultra-low latency(1-2 time steps) SNN with multi-threshold. In order to increase the information capacity of each spike, we introduce the multi-threshold Leaky Integrate and Fired (LIF) model. In our proposed training method, we proposed three approximated derivative for spike activity to solve the problem of the non-differentiable issue which cause difficulties for direct training SNNs based on BP. The experimental results show that our proposed method achieves an average accuracy of 99.56%, 93.08%, and 87.90% on MNIST, FashionMNIST, and CIFAR10, respectively with only 2 time steps. For the CIFAR10 dataset, our proposed method achieve 1.12% accuracy improvement over the previously reported direct trained SNNs with fewer time steps.
Ten Conceptual Dimensions of Context
Nov 04, 2021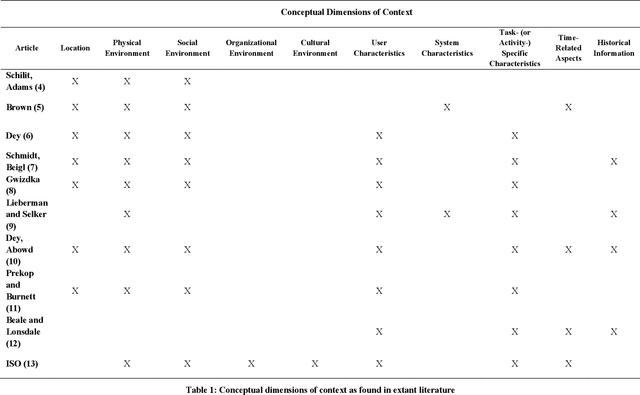
This paper attempts to synthesize various conceptualizations of the term "context" as found in computing literature. Ten conceptual dimensions of context thus emerge -- location; user, task, and system characteristics; physical, social, organizational, and cultural environments; time-related aspects, and historical information. Together, the ten dimensions of context provide a comprehensive view of the notion of context, and allow for a more systematic examination of the influence of context and contextual information on human-system or human-AI interactions.