 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeploying Semantic ID-based Generative Retrieval for Large-Scale Podcast Discovery at Spotify
Mar 18, 2026Podcast listening is often grounded in a set of favorite shows, while listener intent can evolve over time. This combination of stable preferences and changing intent motivates recommendation approaches that support both familiarity and exploration. Traditional recommender systems typically emphasize long-term interaction patterns, and are less explicitly designed to incorporate rich contextual signals or flexible, intent-aware discovery objectives. In this setting, models that can jointly reason over semantics, context, and user state offer a promising direction. Large Language Models (LLMs) provide strong semantic reasoning and contextual conditioning for discovery-oriented recommendation, but deploying them in production introduces challenges in catalog grounding, user-level personalization, and latency-critical serving. We address these challenges with GLIDE, a production-scale generative recommender for podcast discovery at Spotify. GLIDE formulates recommendation as an instruction-following task over a discretized catalog using Semantic IDs, enabling grounded generation over a large inventory. The model conditions on recent listening history and lightweight user context, while injecting long-term user embeddings as soft prompts to capture stable preferences under strict inference constraints. We evaluate GLIDE using offline retrieval metrics, human judgments, and LLM-based evaluation, and validate its impact through large-scale online A/B testing. Across experiments involving millions of users, GLIDE increases non-habitual podcast streaming on Spotify home surface by up to 5.4% and new-show discovery by up to 14.3%, while meeting production cost and latency constraints.
Evaluating Podcast Recommendations with Profile-Aware LLM-as-a-Judge
Aug 12, 2025



Evaluating personalized recommendations remains a central challenge, especially in long-form audio domains like podcasts, where traditional offline metrics suffer from exposure bias and online methods such as A/B testing are costly and operationally constrained. In this paper, we propose a novel framework that leverages Large Language Models (LLMs) as offline judges to assess the quality of podcast recommendations in a scalable and interpretable manner. Our two-stage profile-aware approach first constructs natural-language user profiles distilled from 90 days of listening history. These profiles summarize both topical interests and behavioral patterns, serving as compact, interpretable representations of user preferences. Rather than prompting the LLM with raw data, we use these profiles to provide high-level, semantically rich context-enabling the LLM to reason more effectively about alignment between a user's interests and recommended episodes. This reduces input complexity and improves interpretability. The LLM is then prompted to deliver fine-grained pointwise and pairwise judgments based on the profile-episode match. In a controlled study with 47 participants, our profile-aware judge matched human judgments with high fidelity and outperformed or matched a variant using raw listening histories. The framework enables efficient, profile-aware evaluation for iterative testing and model selection in recommender systems.
Adaptive Repetition for Mitigating Position Bias in LLM-Based Ranking
Jul 23, 2025



When using LLMs to rank items based on given criteria, or evaluate answers, the order of candidate items can influence the model's final decision. This sensitivity to item positioning in a LLM's prompt is known as position bias. Prior research shows that this bias exists even in large models, though its severity varies across models and tasks. In addition to position bias, LLMs also exhibit varying degrees of low repetition consistency, where repeating the LLM call with the same candidate ordering can lead to different rankings. To address both inconsistencies, a common approach is to prompt the model multiple times with different candidate orderings and aggregate the results via majority voting. However, this repetition strategy, significantly increases computational costs. Extending prior findings, we observe that both the direction -- favoring either the earlier or later candidate in the prompt -- and magnitude of position bias across instances vary substantially, even within a single dataset. This observation highlights the need for a per-instance mitigation strategy. To this end, we introduce a dynamic early-stopping method that adaptively determines the number of repetitions required for each instance. Evaluating our approach across three LLMs of varying sizes and on two tasks, namely re-ranking and alignment, we demonstrate that transitioning to a dynamic repetition strategy reduces the number of LLM calls by an average of 81%, while preserving the accuracy. Furthermore, we propose a confidence-based adaptation to our early-stopping method, reducing LLM calls by an average of 87% compared to static repetition, with only a slight accuracy trade-off relative to our original early-stopping method.
Contextualizing Spotify's Audiobook List Recommendations with Descriptive Shelves
Apr 18, 2025In this paper, we propose a pipeline to generate contextualized list recommendations with descriptive shelves in the domain of audiobooks. By creating several shelves for topics the user has an affinity to, e.g. Uplifting Women's Fiction, we can help them explore their recommendations according to their interests and at the same time recommend a diverse set of items. To do so, we use Large Language Models (LLMs) to enrich each item's metadata based on a taxonomy created for this domain. Then we create diverse descriptive shelves for each user. A/B tests show improvements in user engagement and audiobook discovery metrics, demonstrating benefits for users and content creators.
Text2Tracks: Prompt-based Music Recommendation via Generative Retrieval
Mar 31, 2025



In recent years, Large Language Models (LLMs) have enabled users to provide highly specific music recommendation requests using natural language prompts (e.g. "Can you recommend some old classics for slow dancing?"). In this setup, the recommended tracks are predicted by the LLM in an autoregressive way, i.e. the LLM generates the track titles one token at a time. While intuitive, this approach has several limitation. First, it is based on a general purpose tokenization that is optimized for words rather than for track titles. Second, it necessitates an additional entity resolution layer that matches the track title to the actual track identifier. Third, the number of decoding steps scales linearly with the length of the track title, slowing down inference. In this paper, we propose to address the task of prompt-based music recommendation as a generative retrieval task. Within this setting, we introduce novel, effective, and efficient representations of track identifiers that significantly outperform commonly used strategies. We introduce Text2Tracks, a generative retrieval model that learns a mapping from a user's music recommendation prompt to the relevant track IDs directly. Through an offline evaluation on a dataset of playlists with language inputs, we find that (1) the strategy to create IDs for music tracks is the most important factor for the effectiveness of Text2Tracks and semantic IDs significantly outperform commonly used strategies that rely on song titles as identifiers (2) provided with the right choice of track identifiers, Text2Tracks outperforms sparse and dense retrieval solutions trained to retrieve tracks from language prompts.
Bridging Search and Recommendation in Generative Retrieval: Does One Task Help the Other?
Oct 22, 2024



Generative retrieval for search and recommendation is a promising paradigm for retrieving items, offering an alternative to traditional methods that depend on external indexes and nearest-neighbor searches. Instead, generative models directly associate inputs with item IDs. Given the breakthroughs of Large Language Models (LLMs), these generative systems can play a crucial role in centralizing a variety of Information Retrieval (IR) tasks in a single model that performs tasks such as query understanding, retrieval, recommendation, explanation, re-ranking, and response generation. Despite the growing interest in such a unified generative approach for IR systems, the advantages of using a single, multi-task model over multiple specialized models are not well established in the literature. This paper investigates whether and when such a unified approach can outperform task-specific models in the IR tasks of search and recommendation, broadly co-existing in multiple industrial online platforms, such as Spotify, YouTube, and Netflix. Previous work shows that (1) the latent representations of items learned by generative recommenders are biased towards popularity, and (2) content-based and collaborative-filtering-based information can improve an item's representations. Motivated by this, our study is guided by two hypotheses: [H1] the joint training regularizes the estimation of each item's popularity, and [H2] the joint training regularizes the item's latent representations, where search captures content-based aspects of an item and recommendation captures collaborative-filtering aspects. Our extensive experiments with both simulated and real-world data support both [H1] and [H2] as key contributors to the effectiveness improvements observed in the unified search and recommendation generative models over the single-task approaches.
PODTILE: Facilitating Podcast Episode Browsing with Auto-generated Chapters
Oct 21, 2024



Listeners of long-form talk-audio content, such as podcast episodes, often find it challenging to understand the overall structure and locate relevant sections. A practical solution is to divide episodes into chapters--semantically coherent segments labeled with titles and timestamps. Since most episodes on our platform at Spotify currently lack creator-provided chapters, automating the creation of chapters is essential. Scaling the chapterization of podcast episodes presents unique challenges. First, episodes tend to be less structured than written texts, featuring spontaneous discussions with nuanced transitions. Second, the transcripts are usually lengthy, averaging about 16,000 tokens, which necessitates efficient processing that can preserve context. To address these challenges, we introduce PODTILE, a fine-tuned encoder-decoder transformer to segment conversational data. The model simultaneously generates chapter transitions and titles for the input transcript. To preserve context, each input text is augmented with global context, including the episode's title, description, and previous chapter titles. In our intrinsic evaluation, PODTILE achieved an 11% improvement in ROUGE score over the strongest baseline. Additionally, we provide insights into the practical benefits of auto-generated chapters for listeners navigating episode content. Our findings indicate that auto-generated chapters serve as a useful tool for engaging with less popular podcasts. Finally, we present empirical evidence that using chapter titles can enhance effectiveness of sparse retrieval in search tasks.
Improving Content Retrievability in Search with Controllable Query Generation
Mar 21, 2023An important goal of online platforms is to enable content discovery, i.e. allow users to find a catalog entity they were not familiar with. A pre-requisite to discover an entity, e.g. a book, with a search engine is that the entity is retrievable, i.e. there are queries for which the system will surface such entity in the top results. However, machine-learned search engines have a high retrievability bias, where the majority of the queries return the same entities. This happens partly due to the predominance of narrow intent queries, where users create queries using the title of an already known entity, e.g. in book search 'harry potter'. The amount of broad queries where users want to discover new entities, e.g. in music search 'chill lyrical electronica with an atmospheric feeling to it', and have a higher tolerance to what they might find, is small in comparison. We focus here on two factors that have a negative impact on the retrievability of the entities (I) the training data used for dense retrieval models and (II) the distribution of narrow and broad intent queries issued in the system. We propose CtrlQGen, a method that generates queries for a chosen underlying intent-narrow or broad. We can use CtrlQGen to improve factor (I) by generating training data for dense retrieval models comprised of diverse synthetic queries. CtrlQGen can also be used to deal with factor (II) by suggesting queries with broader intents to users. Our results on datasets from the domains of music, podcasts, and books reveal that we can significantly decrease the retrievability bias of a dense retrieval model when using CtrlQGen. First, by using the generated queries as training data for dense models we make 9% of the entities retrievable (go from zero to non-zero retrievability). Second, by suggesting broader queries to users, we can make 12% of the entities retrievable in the best case.
Do the Findings of Document and Passage Retrieval Generalize to the Retrieval of Responses for Dialogues?
Jan 13, 2023



A number of learned sparse and dense retrieval approaches have recently been proposed and proven effective in tasks such as passage retrieval and document retrieval. In this paper we analyze with a replicability study if the lessons learned generalize to the retrieval of responses for dialogues, an important task for the increasingly popular field of conversational search. Unlike passage and document retrieval where documents are usually longer than queries, in response ranking for dialogues the queries (dialogue contexts) are often longer than the documents (responses). Additionally, dialogues have a particular structure, i.e. multiple utterances by different users. With these differences in mind, we here evaluate how generalizable the following major findings from previous works are: (F1) query expansion outperforms a no-expansion baseline; (F2) document expansion outperforms a no-expansion baseline; (F3) zero-shot dense retrieval underperforms sparse baselines; (F4) dense retrieval outperforms sparse baselines; (F5) hard negative sampling is better than random sampling for training dense models. Our experiments -- based on three different information-seeking dialogue datasets -- reveal that four out of five findings (F2-F5) generalize to our domain
Sparse and Dense Approaches for the Full-rank Retrieval of Responses for Dialogues
Apr 22, 2022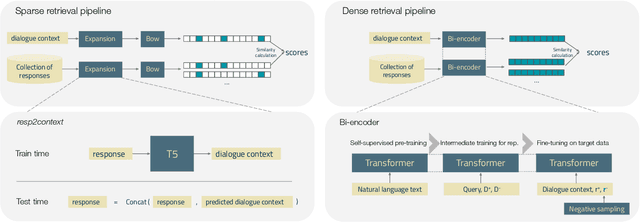
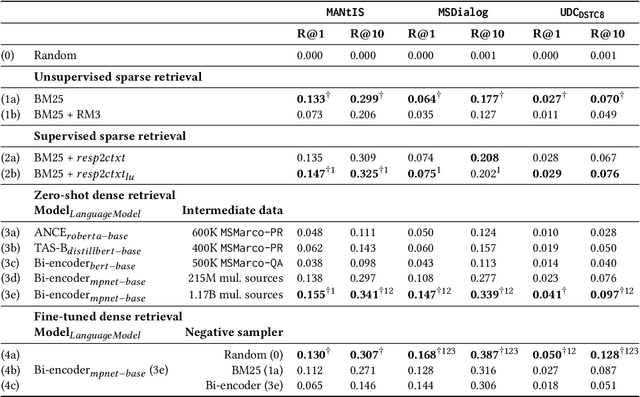
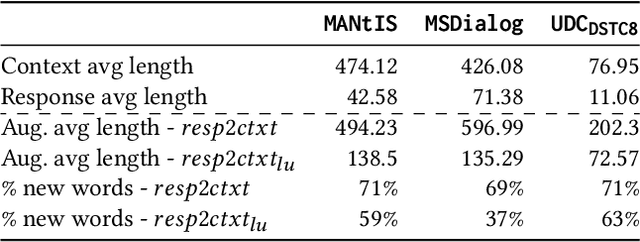
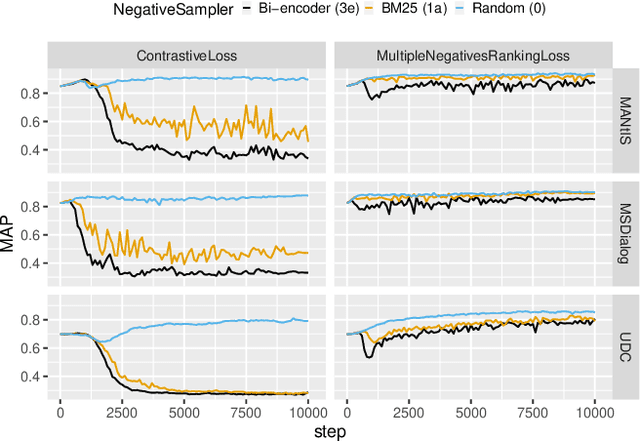
Ranking responses for a given dialogue context is a popular benchmark in which the setup is to re-rank the ground-truth response over a limited set of $n$ responses, where $n$ is typically 10. The predominance of this setup in conversation response ranking has lead to a great deal of attention to building neural re-rankers, while the first-stage retrieval step has been overlooked. Since the correct answer is always available in the candidate list of $n$ responses, this artificial evaluation setup assumes that there is a first-stage retrieval step which is always able to rank the correct response in its top-$n$ list. In this paper we focus on the more realistic task of full-rank retrieval of responses, where $n$ can be up to millions of responses. We investigate both dialogue context and response expansion techniques for sparse retrieval, as well as zero-shot and fine-tuned dense retrieval approaches. Our findings based on three different information-seeking dialogue datasets reveal that a learned response expansion technique is a solid baseline for sparse retrieval. We find the best performing method overall to be dense retrieval with intermediate training, i.e. a step after the language model pre-training where sentence representations are learned, followed by fine-tuning on the target conversational data. We also investigate the intriguing phenomena that harder negatives sampling techniques lead to worse results for the fine-tuned dense retrieval models. The code and datasets are available at https://github.com/Guzpenha/transformer_rankers/tree/full_rank_retrieval_dialogues.