 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Collaborative Filtering with Attribution Alignment for Review-based Non-overlapped Cross Domain Recommendation
Feb 10, 2022
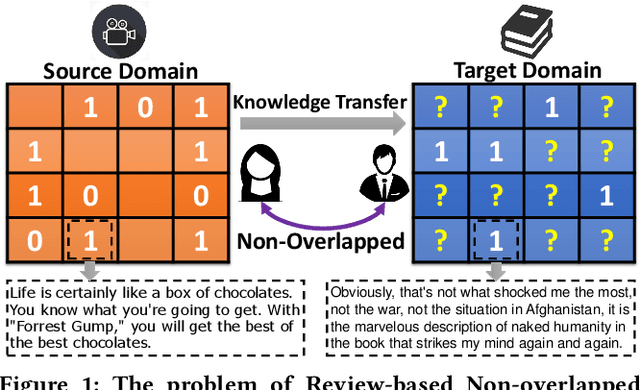
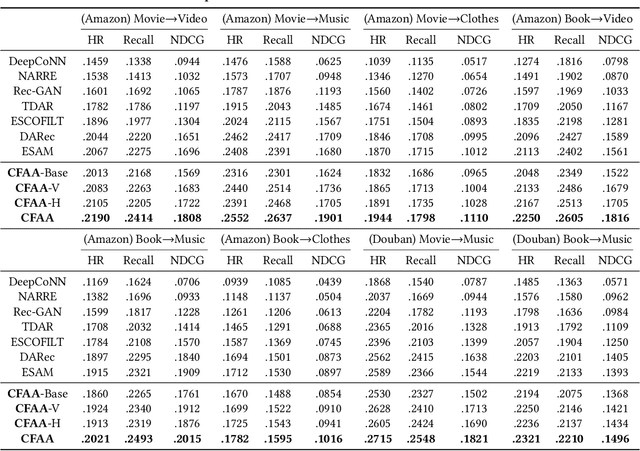
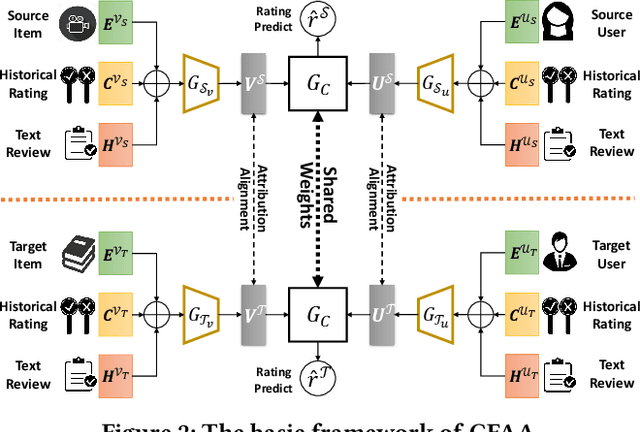
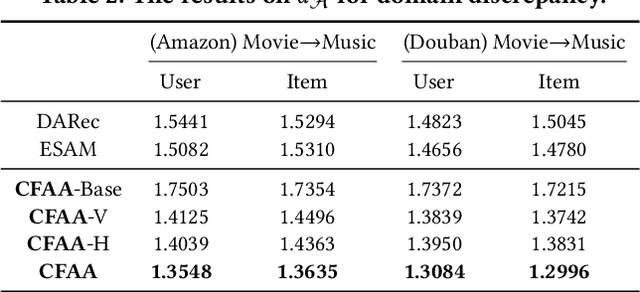
Cross-Domain Recommendation (CDR) has been popularly studied to utilize different domain knowledge to solve the data sparsity and cold-start problem in recommender systems. In this paper, we focus on the Review-based Non-overlapped Recommendation (RNCDR) problem. The problem is commonly-existed and challenging due to two main aspects, i.e, there are only positive user-item ratings on the target domain and there is no overlapped user across different domains. Most previous CDR approaches cannot solve the RNCDR problem well, since (1) they cannot effectively combine review with other information (e.g., ID or ratings) to obtain expressive user or item embedding, (2) they cannot reduce the domain discrepancy on users and items. To fill this gap, we propose Collaborative Filtering with Attribution Alignment model (CFAA), a cross-domain recommendation framework for the RNCDR problem. CFAA includes two main modules, i.e., rating prediction module and embedding attribution alignment module. The former aims to jointly mine review, one-hot ID, and multi-hot historical ratings to generate expressive user and item embeddings. The later includes vertical attribution alignment and horizontal attribution alignment, tending to reduce the discrepancy based on multiple perspectives. Our empirical study on Douban and Amazon datasets demonstrates that CFAA significantly outperforms the state-of-the-art models under the RNCDR setting.
Differential Private Knowledge Transfer for Privacy-Preserving Cross-Domain Recommendation
Feb 10, 2022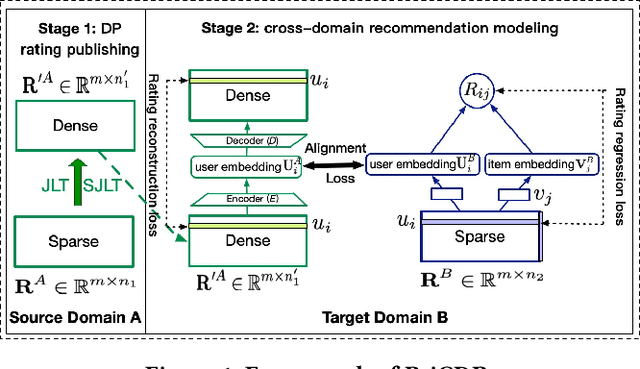
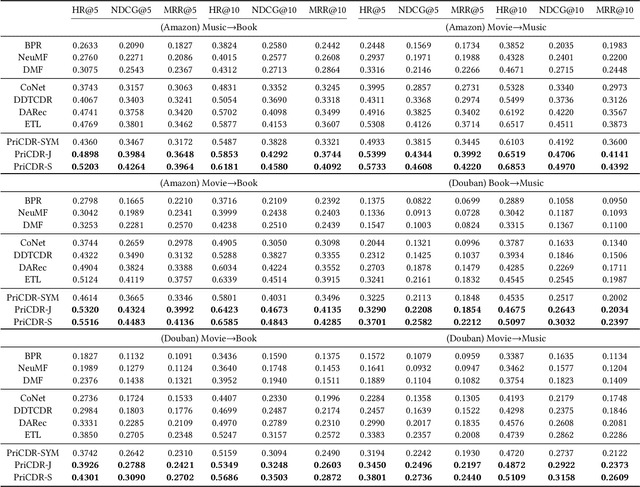
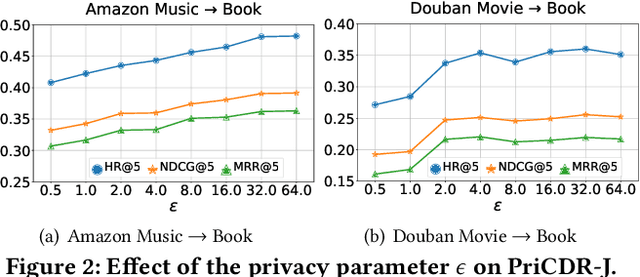

Cross Domain Recommendation (CDR) has been popularly studied to alleviate the cold-start and data sparsity problem commonly existed in recommender systems. CDR models can improve the recommendation performance of a target domain by leveraging the data of other source domains. However, most existing CDR models assume information can directly 'transfer across the bridge', ignoring the privacy issues. To solve the privacy concern in CDR, in this paper, we propose a novel two stage based privacy-preserving CDR framework (PriCDR). In the first stage, we propose two methods, i.e., Johnson-Lindenstrauss Transform (JLT) based and Sparse-awareJLT (SJLT) based, to publish the rating matrix of the source domain using differential privacy. We theoretically analyze the privacy and utility of our proposed differential privacy based rating publishing methods. In the second stage, we propose a novel heterogeneous CDR model (HeteroCDR), which uses deep auto-encoder and deep neural network to model the published source rating matrix and target rating matrix respectively. To this end, PriCDR can not only protect the data privacy of the source domain, but also alleviate the data sparsity of the source domain. We conduct experiments on two benchmark datasets and the results demonstrate the effectiveness of our proposed PriCDR and HeteroCDR.
RerrFact: Reduced Evidence Retrieval Representations for Scientific Claim Verification
Feb 05, 2022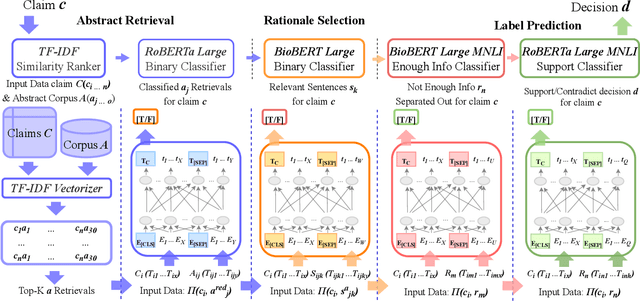



Exponential growth in digital information outlets and the race to publish has made scientific misinformation more prevalent than ever. However, the task to fact-verify a given scientific claim is not straightforward even for researchers. Scientific claim verification requires in-depth knowledge and great labor from domain experts to substantiate supporting and refuting evidence from credible scientific sources. The SciFact dataset and corresponding task provide a benchmarking leaderboard to the community to develop automatic scientific claim verification systems via extracting and assimilating relevant evidence rationales from source abstracts. In this work, we propose a modular approach that sequentially carries out binary classification for every prediction subtask as in the SciFact leaderboard. Our simple classifier-based approach uses reduced abstract representations to retrieve relevant abstracts. These are further used to train the relevant rationale-selection model. Finally, we carry out two-step stance predictions that first differentiate non-relevant rationales and then identify supporting or refuting rationales for a given claim. Experimentally, our system RerrFact with no fine-tuning, simple design, and a fraction of model parameters fairs competitively on the leaderboard against large-scale, modular, and joint modeling approaches. We make our codebase available at https://github.com/ashishrana160796/RerrFact.
Single-stage Rotate Object Detector via Two Points with Solar Corona Heatmap
Feb 14, 2022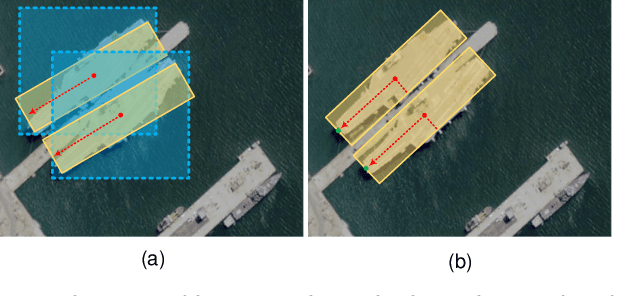

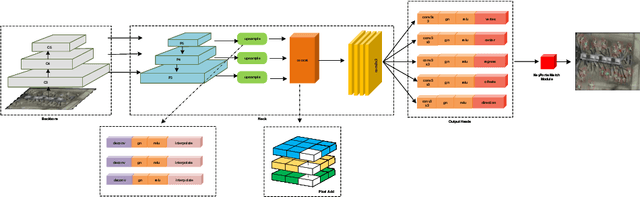
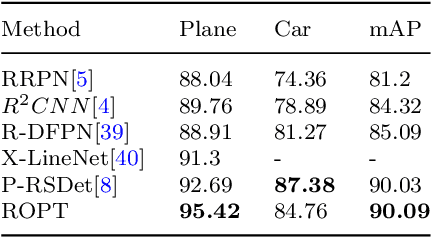
Oriented object detection is a crucial task in computer vision. Current top-down oriented detection methods usually directly detect entire objects, and not only neglecting the authentic direction of targets, but also do not fully utilise the key semantic information, which causes a decrease in detection accuracy. In this study, we developed a single-stage rotating object detector via two points with a solar corona heatmap (ROTP) to detect oriented objects. The ROTP predicts parts of the object and then aggregates them to form a whole image. Herein, we meticulously represent an object in a random direction using the vertex, centre point with width, and height. Specifically, we regress two heatmaps that characterise the relative location of each object, which enhances the accuracy of locating objects and avoids deviations caused by angle predictions. To rectify the central misjudgement of the Gaussian heatmap on high-aspect ratio targets, we designed a solar corona heatmap generation method to improve the perception difference between the central and non-central samples. Additionally, we predicted the vertex relative to the direction of the centre point to connect two key points that belong to the same goal. Experiments on the HRSC 2016, UCASAOD, and DOTA datasets show that our ROTP achieves the most advanced performance with a simpler modelling and less manual intervention.
FairGNN: Eliminating the Discrimination in Graph Neural Networks with Limited Sensitive Attribute Information
Sep 03, 2020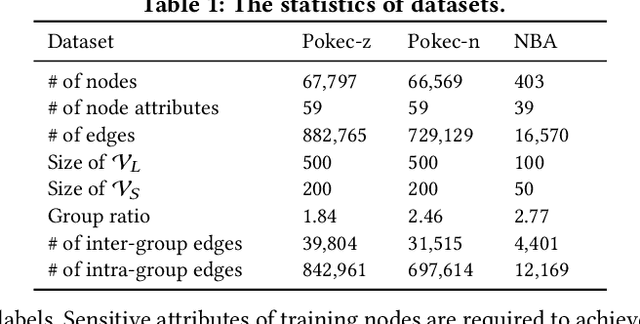
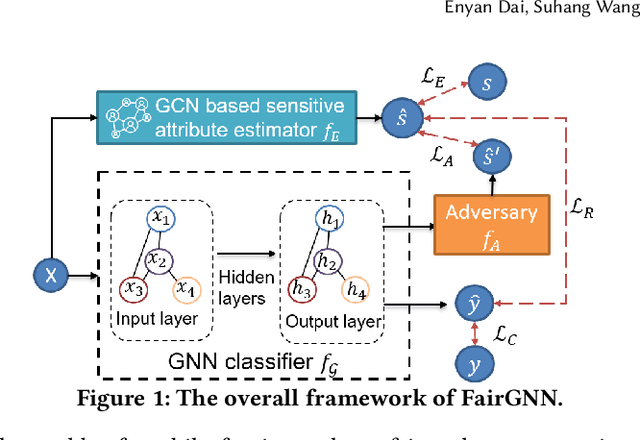
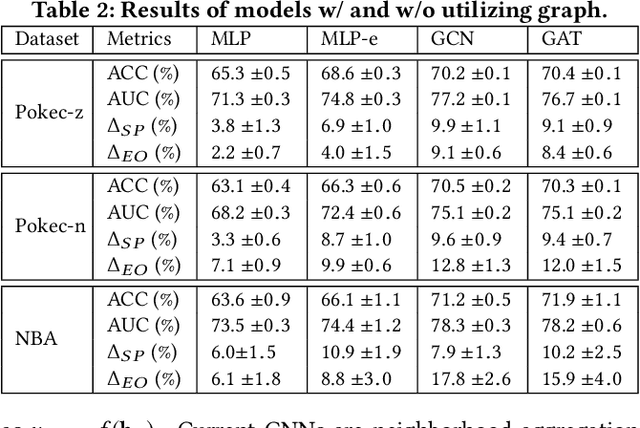
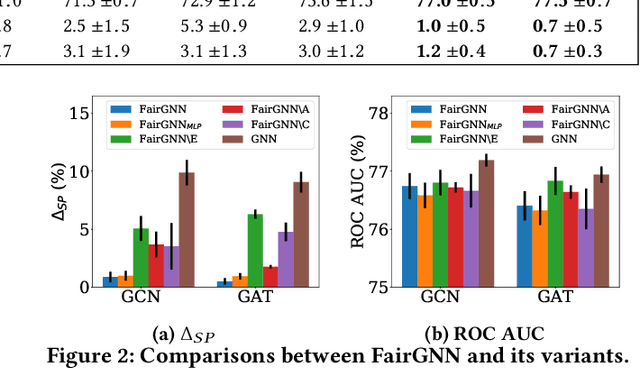
Graph neural networks (GNNs) have shown great power in modeling graph structured data. However, similar to other machine learning models, GNNs may make predictions biased on protected sensitive attributes, e.g., skin color, gender, and nationality. Because machine learning algorithms including GNNs are trained to faithfully reflect the distribution of the training data which often contains historical bias towards sensitive attributes. In addition, the discrimination in GNNs can be magnified by graph structures and the message-passing mechanism. As a result, the applications of GNNs in sensitive domains such as crime rate prediction would be largely limited. Though extensive studies of fair classification have been conducted on i.i.d data, methods to address the problem of discrimination on non-i.i.d data are rather limited. Furthermore, the practical scenario of sparse annotations in sensitive attributes is rarely considered in existing works. Therefore, we study the novel and important problem of learning fair GNNs with limited sensitive attribute information. FairGNN is proposed to eliminate the bias of GNNs whilst maintaining high node classification accuracy by leveraging graph structures and limited sensitive information. Our theoretical analysis shows that FairGNN can ensure the fairness of GNNs under mild conditions given limited nodes with known sensitive attributes. Extensive experiments on real-world datasets also demonstrate the effectiveness of FairGNN in debiasing and keeping high accuracy.
ReconFormer: Accelerated MRI Reconstruction Using Recurrent Transformer
Jan 23, 2022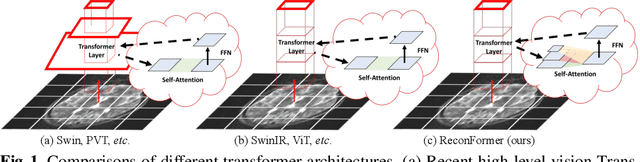
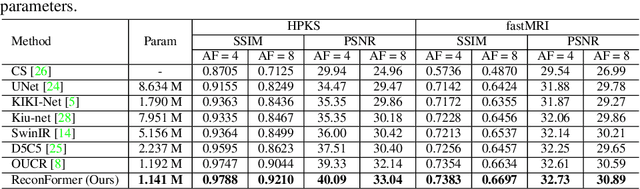
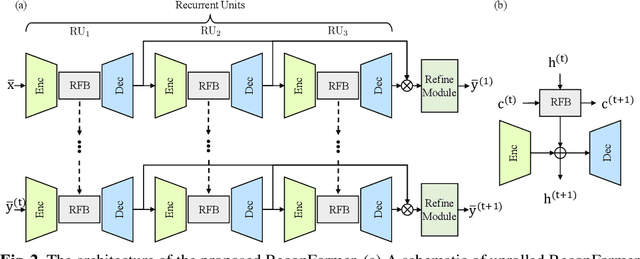
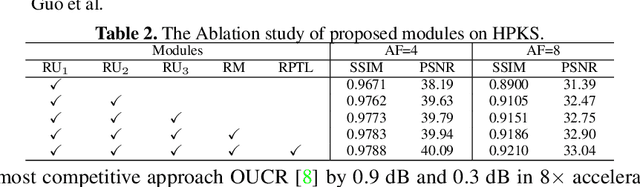
Accelerating magnetic resonance image (MRI) reconstruction process is a challenging ill-posed inverse problem due to the excessive under-sampling operation in k-space. In this paper, we propose a recurrent transformer model, namely \textbf{ReconFormer}, for MRI reconstruction which can iteratively reconstruct high fertility magnetic resonance images from highly under-sampled k-space data. In particular, the proposed architecture is built upon Recurrent Pyramid Transformer Layers (RPTL), which jointly exploits intrinsic multi-scale information at every architecture unit as well as the dependencies of the deep feature correlation through recurrent states. Moreover, the proposed ReconFormer is lightweight since it employs the recurrent structure for its parameter efficiency. We validate the effectiveness of ReconFormer on multiple datasets with different magnetic resonance sequences and show that it achieves significant improvements over the state-of-the-art methods with better parameter efficiency. Implementation code will be available in https://github.com/guopengf/ReconFormer.
Multi-relation Message Passing for Multi-label Text Classification
Feb 10, 2022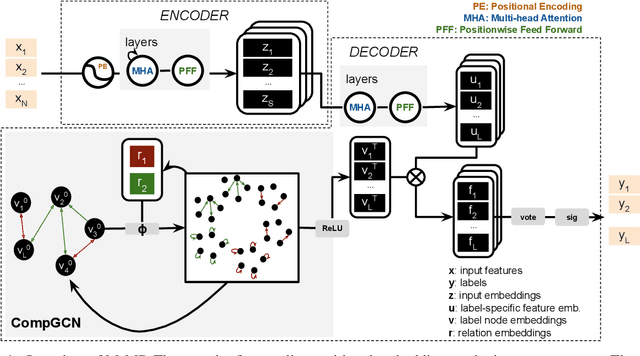

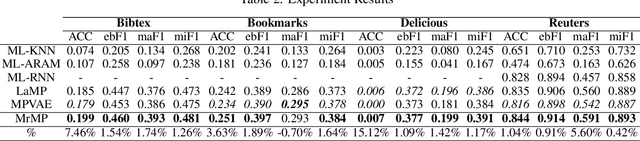
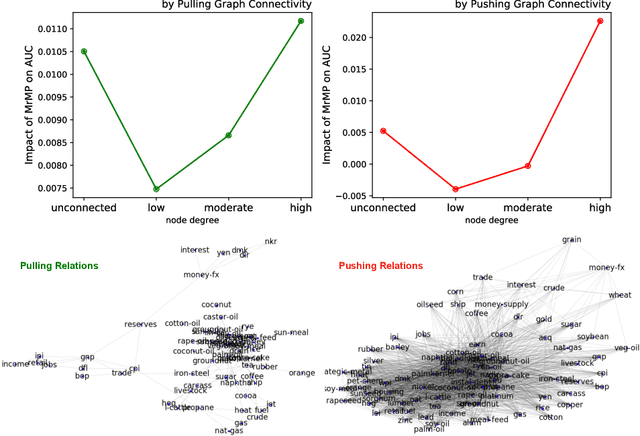
A well-known challenge associated with the multi-label classification problem is modelling dependencies between labels. Most attempts at modelling label dependencies focus on co-occurrences, ignoring the valuable information that can be extracted by detecting label subsets that rarely occur together. For example, consider customer product reviews; a product probably would not simultaneously be tagged by both "recommended" (i.e., reviewer is happy and recommends the product) and "urgent" (i.e., the review suggests immediate action to remedy an unsatisfactory experience). Aside from the consideration of positive and negative dependencies, the direction of a relationship should also be considered. For a multi-label image classification problem, the "ship" and "sea" labels have an obvious dependency, but the presence of the former implies the latter much more strongly than the other way around. These examples motivate the modelling of multiple types of bi-directional relationships between labels. In this paper, we propose a novel method, entitled Multi-relation Message Passing (MrMP), for the multi-label classification problem. Experiments on benchmark multi-label text classification datasets show that the MrMP module yields similar or superior performance compared to state-of-the-art methods. The approach imposes only minor additional computational and memory overheads.
Submodularity In Machine Learning and Artificial Intelligence
Jan 31, 2022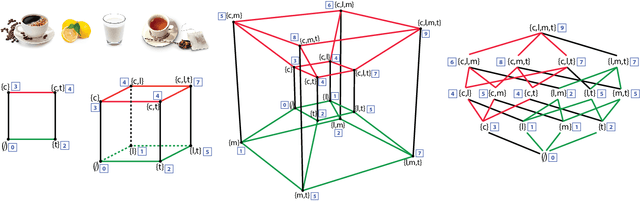

In this manuscript, we offer a gentle review of submodularity and supermodularity and their properties. We offer a plethora of submodular definitions; a full description of a number of example submodular functions and their generalizations; example discrete constraints; a discussion of basic algorithms for maximization, minimization, and other operations; a brief overview of continuous submodular extensions; and some historical applications. We then turn to how submodularity is useful in machine learning and artificial intelligence. This includes summarization, and we offer a complete account of the differences between and commonalities amongst sketching, coresets, extractive and abstractive summarization in NLP, data distillation and condensation, and data subset selection and feature selection. We discuss a variety of ways to produce a submodular function useful for machine learning, including heuristic hand-crafting, learning or approximately learning a submodular function or aspects thereof, and some advantages of the use of a submodular function as a coreset producer. We discuss submodular combinatorial information functions, and how submodularity is useful for clustering, data partitioning, parallel machine learning, active and semi-supervised learning, probabilistic modeling, and structured norms and loss functions.
Team Yao at Factify 2022: Utilizing Pre-trained Models and Co-attention Networks for Multi-Modal Fact Verification
Jan 26, 2022

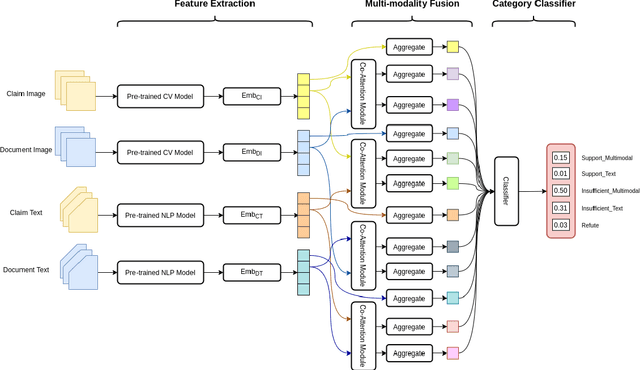

In recent years, social media has enabled users to get exposed to a myriad of misinformation and disinformation; thus, misinformation has attracted a great deal of attention in research fields and as a social issue. To address the problem, we propose a framework, Pre-CoFact, composed of two pre-trained models for extracting features from text and images, and multiple co-attention networks for fusing the same modality but different sources and different modalities. Besides, we adopt the ensemble method by using different pre-trained models in Pre-CoFact to achieve better performance. We further illustrate the effectiveness from the ablation study and examine different pre-trained models for comparison. Our team, Yao, won the fifth prize (F1-score: 74.585\%) in the Factify challenge hosted by De-Factify @ AAAI 2022, which demonstrates that our model achieved competitive performance without using auxiliary tasks or extra information. The source code of our work is publicly available at https://github.com/wywyWang/Multi-Modal-Fact-Verification-2021
DMGCRN: Dynamic Multi-Graph Convolution Recurrent Network for Traffic Forecasting
Dec 04, 2021
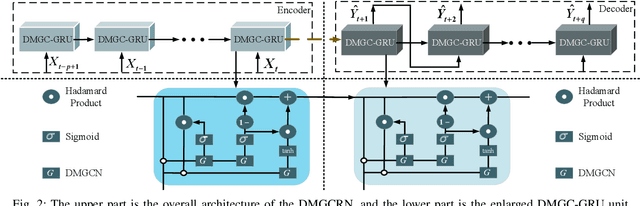
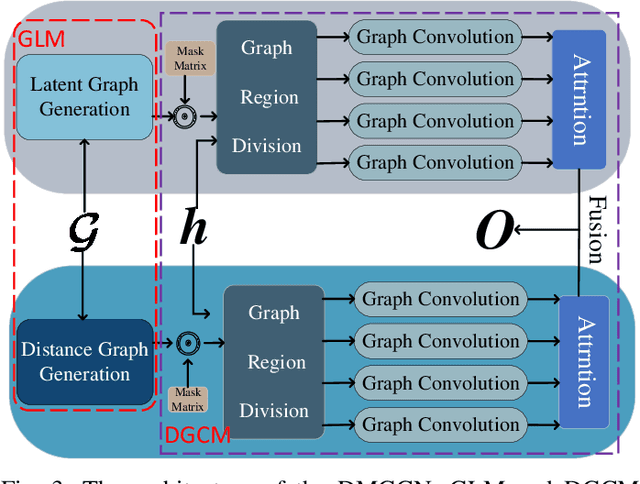
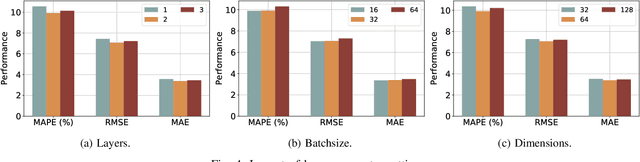
Traffic forecasting is a problem of intelligent transportation systems (ITS) and crucial for individuals and public agencies. Therefore, researches pay great attention to deal with the complex spatio-temporal dependencies of traffic system for accurate forecasting. However, there are two challenges: 1) Most traffic forecasting studies mainly focus on modeling correlations of neighboring sensors and ignore correlations of remote sensors, e.g., business districts with similar spatio-temporal patterns; 2) Prior methods which use static adjacency matrix in graph convolutional networks (GCNs) are not enough to reflect the dynamic spatial dependence in traffic system. Moreover, fine-grained methods which use self-attention to model dynamic correlations of all sensors ignore hierarchical information in road networks and have quadratic computational complexity. In this paper, we propose a novel dynamic multi-graph convolution recurrent network (DMGCRN) to tackle above issues, which can model the spatial correlations of distance, the spatial correlations of structure, and the temporal correlations simultaneously. We not only use the distance-based graph to capture spatial information from nodes are close in distance but also construct a novel latent graph which encoded the structure correlations among roads to capture spatial information from nodes are similar in structure. Furthermore, we divide the neighbors of each sensor into coarse-grained regions, and dynamically assign different weights to each region at different times. Meanwhile, we integrate the dynamic multi-graph convolution network into the gated recurrent unit (GRU) to capture temporal dependence. Extensive experiments on three real-world traffic datasets demonstrate that our proposed algorithm outperforms state-of-the-art baselines.