 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Visual attention analysis of pathologists examining whole slide images of Prostate cancer
Feb 17, 2022
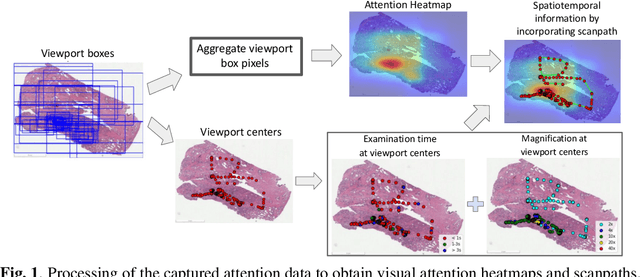
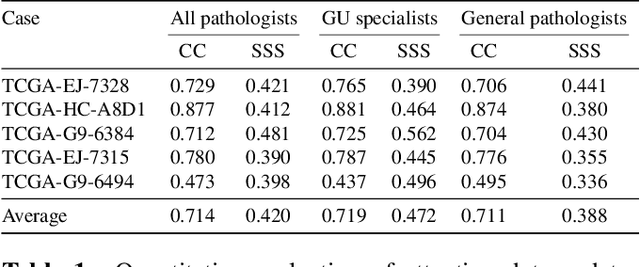
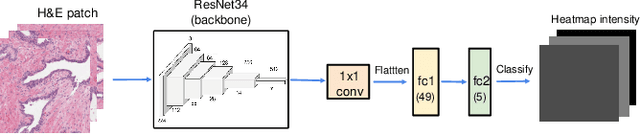
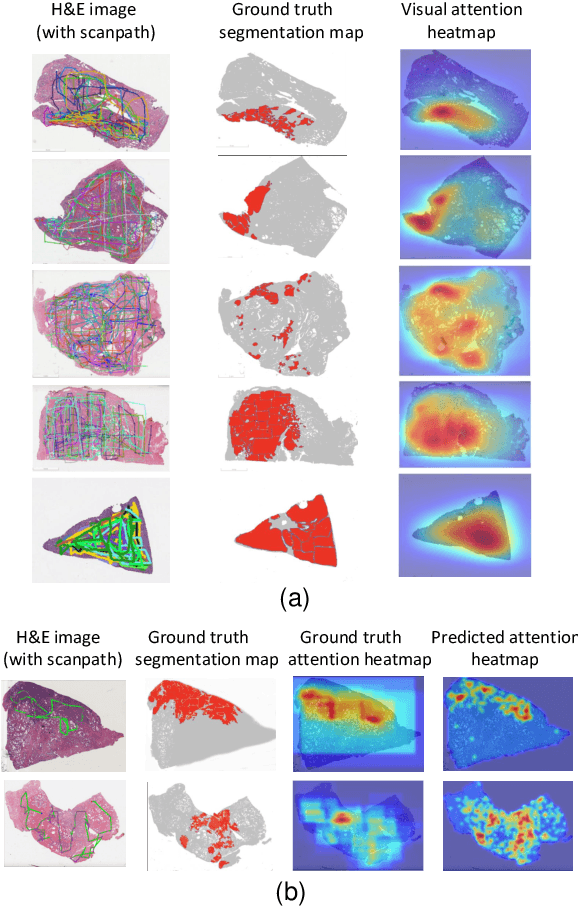
We study the attention of pathologists as they examine whole-slide images (WSIs) of prostate cancer tissue using a digital microscope. To the best of our knowledge, our study is the first to report in detail how pathologists navigate WSIs of prostate cancer as they accumulate information for their diagnoses. We collected slide navigation data (i.e., viewport location, magnification level, and time) from 13 pathologists in 2 groups (5 genitourinary (GU) specialists and 8 general pathologists) and generated visual attention heatmaps and scanpaths. Each pathologist examined five WSIs from the TCGA PRAD dataset, which were selected by a GU pathology specialist. We examined and analyzed the distributions of visual attention for each group of pathologists after each WSI was examined. To quantify the relationship between a pathologist's attention and evidence for cancer in the WSI, we obtained tumor annotations from a genitourinary specialist. We used these annotations to compute the overlap between the distribution of visual attention and annotated tumor region to identify strong correlations. Motivated by this analysis, we trained a deep learning model to predict visual attention on unseen WSIs. We find that the attention heatmaps predicted by our model correlate quite well with the ground truth attention heatmap and tumor annotations on a test set of 17 WSIs by using various spatial and temporal evaluation metrics.
vol2Brain: A new online Pipeline for whole Brain MRI analysis
Feb 08, 2022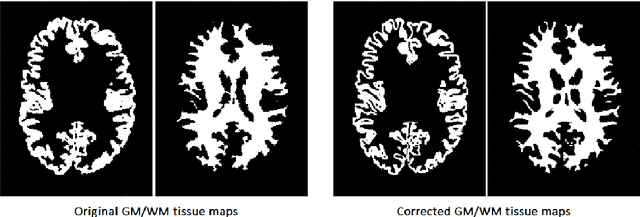
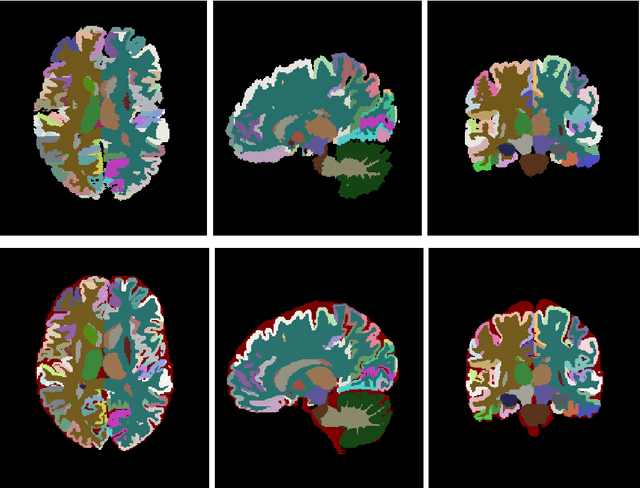
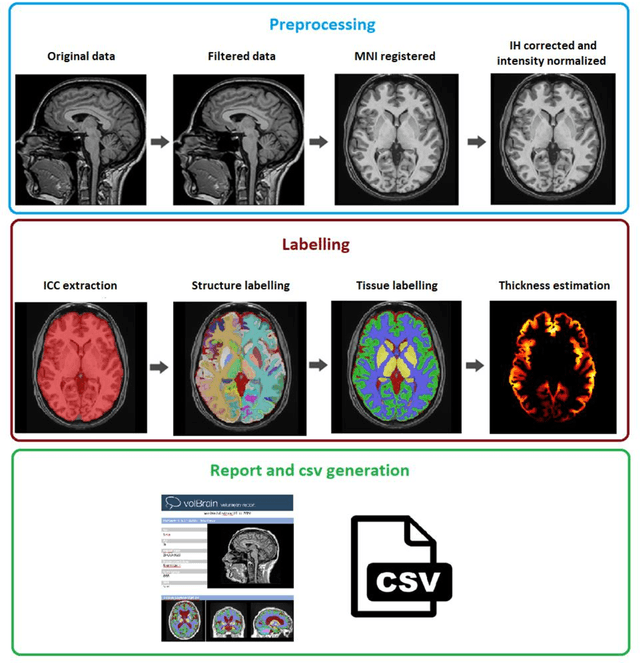
Automatic and reliable quantitative tools for MR brain image analysis are a very valuable resources for both clinical and research environments. In the last years, this field has experienced many advances with successful techniques based on label fusion and more recently deep learning. However, few of them have been specifically designed to provide a dense anatomical labelling at multiscale level and to deal with brain anatomical alterations such as white matter lesions. In this work, we present a fully automatic pipeline (vol2Brain) for whole brain segmentation and analysis which densely labels (N>100) the brain while being robust to the presence of white matter lesions. This new pipeline is an evolution of our previous volBrain pipeline that extends significantly the number of regions that can be analyzed. Our proposed method is based on a fast multiscale multi-atlas label fusion technology with systematic error correction able to provide accurate volumetric information in few minutes. We have deployed our new pipeline within our platform volBrain (www.volbrain.upv.es) which has been already demonstrated to be an efficient and effective manner to share our technology with users worldwide
QKSA: Quantum Knowledge Seeking Agent -- resource-optimized reinforcement learning using quantum process tomography
Dec 07, 2021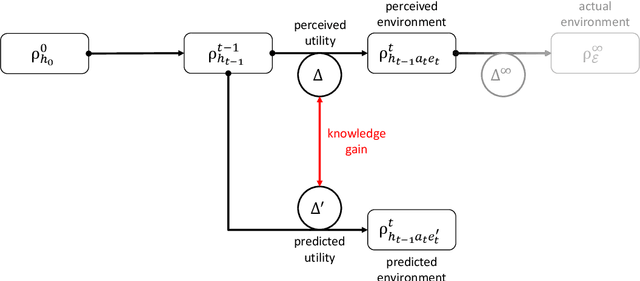
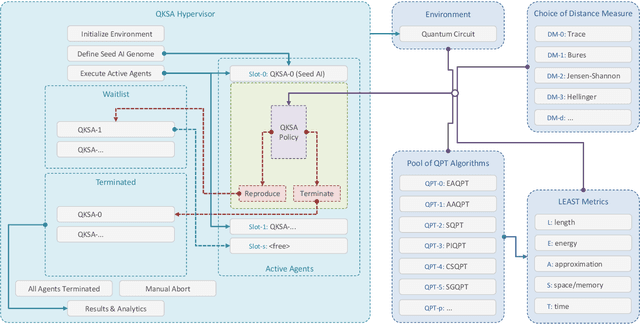
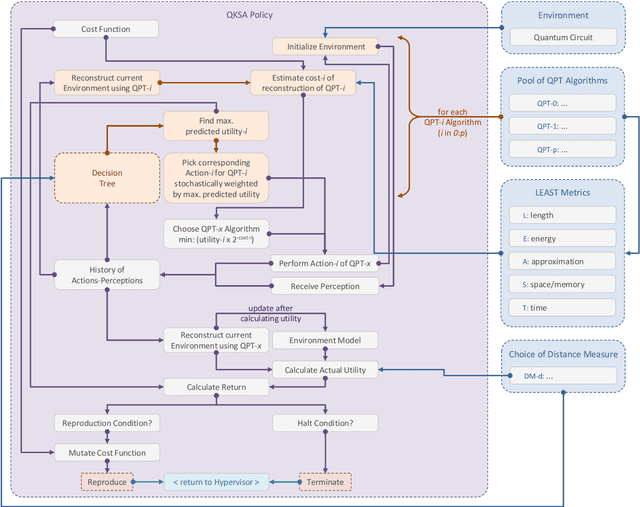
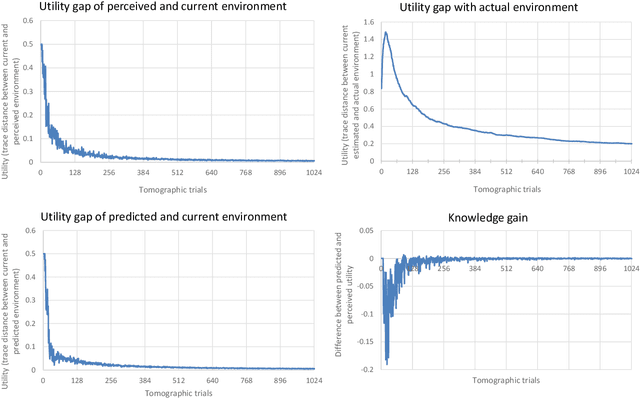
In this research, we extend the universal reinforcement learning (URL) agent models of artificial general intelligence to quantum environments. The utility function of a classical exploratory stochastic Knowledge Seeking Agent, KL-KSA, is generalized to distance measures from quantum information theory on density matrices. Quantum process tomography (QPT) algorithms form the tractable subset of programs for modeling environmental dynamics. The optimal QPT policy is selected based on a mutable cost function based on algorithmic complexity as well as computational resource complexity. Instead of Turing machines, we estimate the cost metrics on a high-level language to allow realistic experimentation. The entire agent design is encapsulated in a self-replicating quine which mutates the cost function based on the predictive value of the optimal policy choosing scheme. Thus, multiple agents with pareto-optimal QPT policies evolve using genetic programming, mimicking the development of physical theories each with different resource trade-offs. This formal framework is termed Quantum Knowledge Seeking Agent (QKSA). Despite its importance, few quantum reinforcement learning models exist in contrast to the current thrust in quantum machine learning. QKSA is the first proposal for a framework that resembles the classical URL models. Similar to how AIXI-tl is a resource-bounded active version of Solomonoff universal induction, QKSA is a resource-bounded participatory observer framework to the recently proposed algorithmic information-based reconstruction of quantum mechanics. QKSA can be applied for simulating and studying aspects of quantum information theory. Specifically, we demonstrate that it can be used to accelerate quantum variational algorithms which include tomographic reconstruction as its integral subroutine.
A Novel Framework with Information Fusion and Neighborhood Enhancement for User Identity Linkage
Mar 16, 2020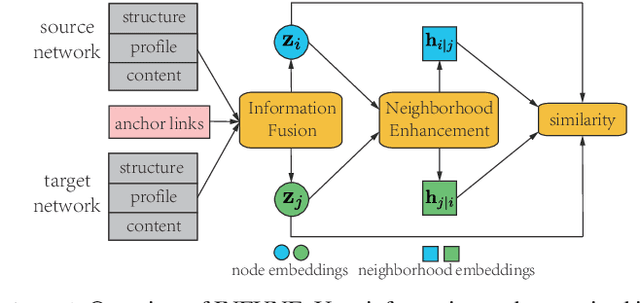
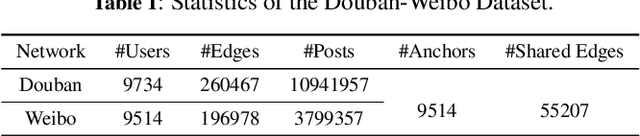
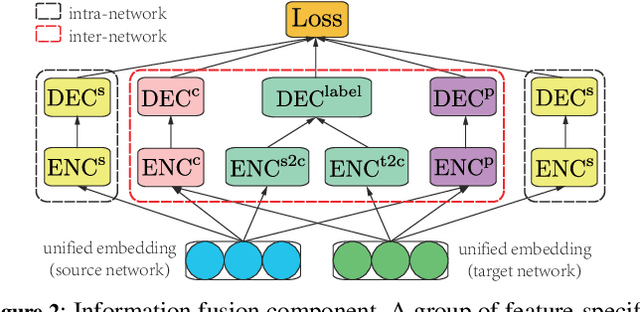

User identity linkage across social networks is an essential problem for cross-network data mining. Since network structure, profile and content information describe different aspects of users, it is critical to learn effective user representations that integrate heterogeneous information. This paper proposes a novel framework with INformation FUsion and Neighborhood Enhancement (INFUNE) for user identity linkage. The information fusion component adopts a group of encoders and decoders to fuse heterogeneous information and generate discriminative node embeddings for preliminary matching. Then, these embeddings are fed to the neighborhood enhancement component, a novel graph neural network, to produce adaptive neighborhood embeddings that reflect the overlapping degree of neighborhoods of varying candidate user pairs. The importance of node embeddings and neighborhood embeddings are weighted for final prediction. The proposed method is evaluated on real-world social network data. The experimental results show that INFUNE significantly outperforms existing state-of-the-art methods.
Unsupervised Time-Series Representation Learning with Iterative Bilinear Temporal-Spectral Fusion
Feb 08, 2022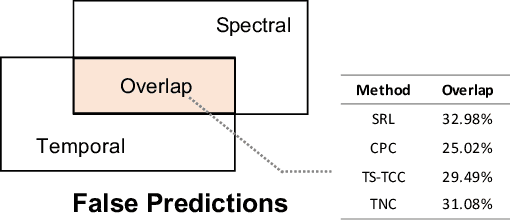
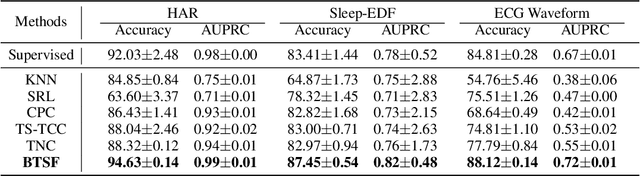
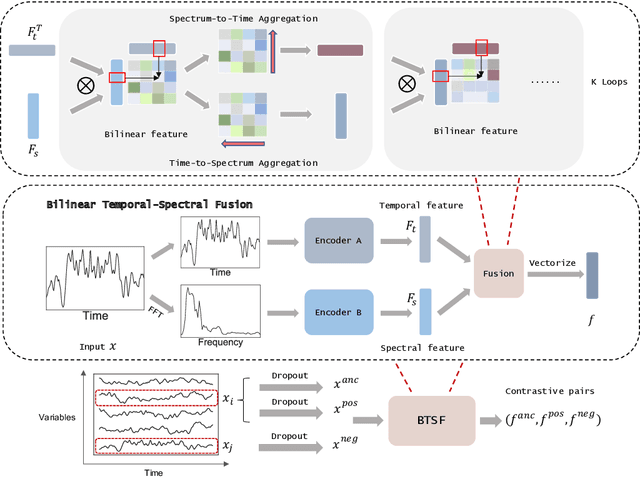
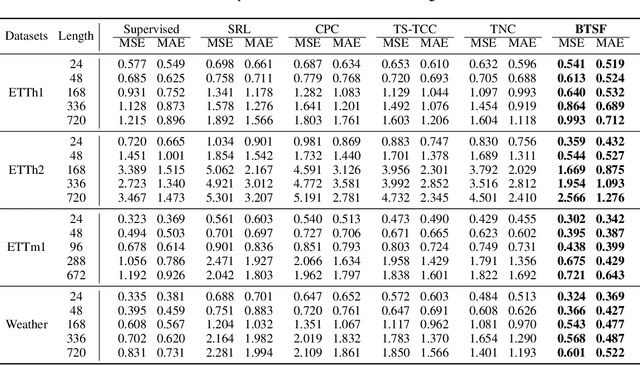
Unsupervised/self-supervised time series representation learning is a challenging problem because of its complex dynamics and sparse annotations. Existing works mainly adopt the framework of contrastive learning with the time-based augmentation techniques to sample positives and negatives for contrastive training. Nevertheless, they mostly use segment-level augmentation derived from time slicing, which may bring about sampling bias and incorrect optimization with false negatives due to the loss of global context. Besides, they all pay no attention to incorporate the spectral information in feature representation. In this paper, we propose a unified framework, namely Bilinear Temporal-Spectral Fusion (BTSF). Specifically, we firstly utilize the instance-level augmentation with a simple dropout on the entire time series for maximally capturing long-term dependencies. We devise a novel iterative bilinear temporal-spectral fusion to explicitly encode the affinities of abundant time-frequency pairs, and iteratively refines representations in a fusion-and-squeeze manner with Spectrum-to-Time (S2T) and Time-to-Spectrum (T2S) Aggregation modules. We firstly conducts downstream evaluations on three major tasks for time series including classification, forecasting and anomaly detection. Experimental results shows that our BTSF consistently significantly outperforms the state-of-the-art methods.
Learnable Wavelet Packet Transform for Data-Adapted Spectrograms
Jan 26, 2022
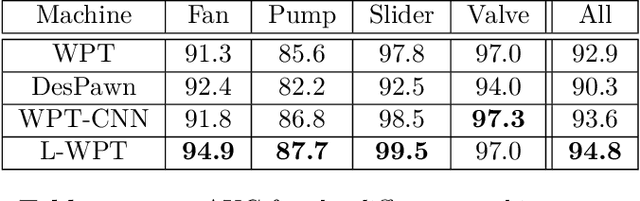
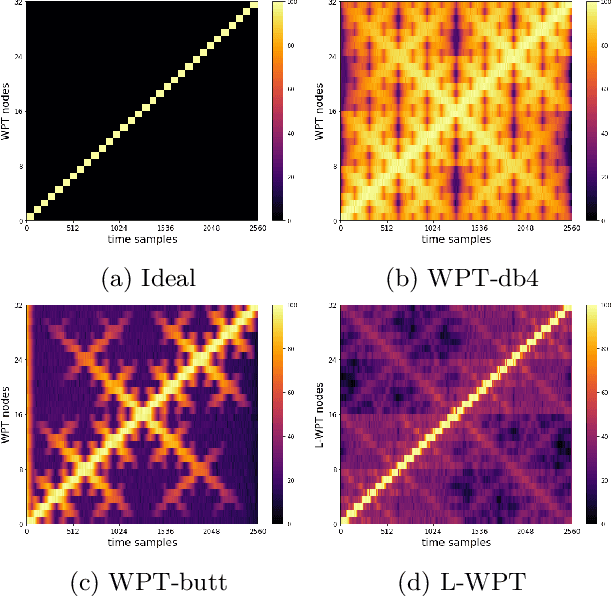
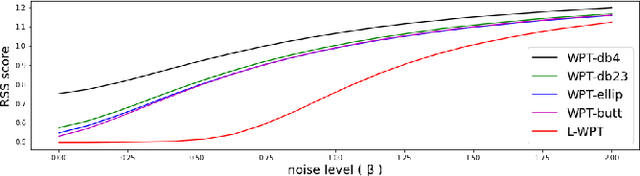
Capturing high-frequency data concerning the condition of complex systems, e.g. by acoustic monitoring, has become increasingly prevalent. Such high-frequency signals typically contain time dependencies ranging over different time scales and different types of cyclic behaviors. Processing such signals requires careful feature engineering, particularly the extraction of meaningful time-frequency features. This can be time-consuming and the performance is often dependent on the choice of parameters. To address these limitations, we propose a deep learning framework for learnable wavelet packet transforms, enabling to learn features automatically from data and optimise them with respect to the defined objective function. The learned features can be represented as a spectrogram, containing the important time-frequency information of the dataset. We evaluate the properties and performance of the proposed approach by evaluating its improved spectral leakage and by applying it to an anomaly detection task for acoustic monitoring.
Towards Coherent and Consistent Use of Entities in Narrative Generation
Feb 03, 2022
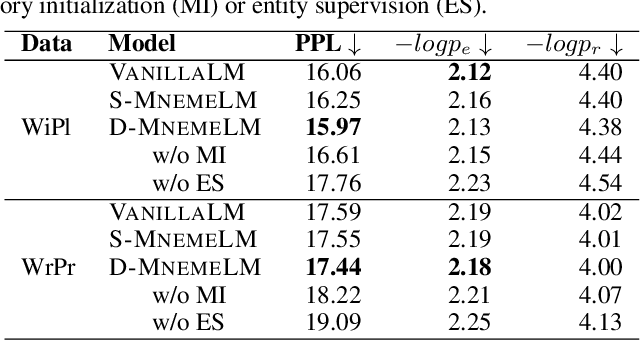
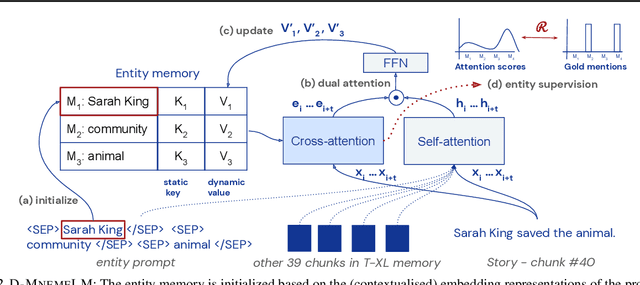
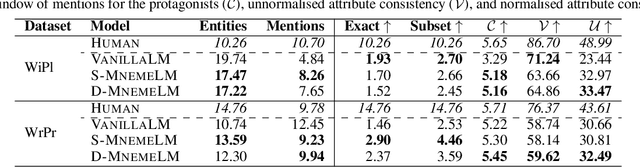
Large pre-trained language models (LMs) have demonstrated impressive capabilities in generating long, fluent text; however, there is little to no analysis on their ability to maintain entity coherence and consistency. In this work, we focus on the end task of narrative generation and systematically analyse the long-range entity coherence and consistency in generated stories. First, we propose a set of automatic metrics for measuring model performance in terms of entity usage. Given these metrics, we quantify the limitations of current LMs. Next, we propose augmenting a pre-trained LM with a dynamic entity memory in an end-to-end manner by using an auxiliary entity-related loss for guiding the reads and writes to the memory. We demonstrate that the dynamic entity memory increases entity coherence according to both automatic and human judgment and helps preserving entity-related information especially in settings with a limited context window. Finally, we also validate that our automatic metrics are correlated with human ratings and serve as a good indicator of the quality of generated stories.
Pattern Recognition and Event Detection on IoT Data-streams
Mar 02, 2022
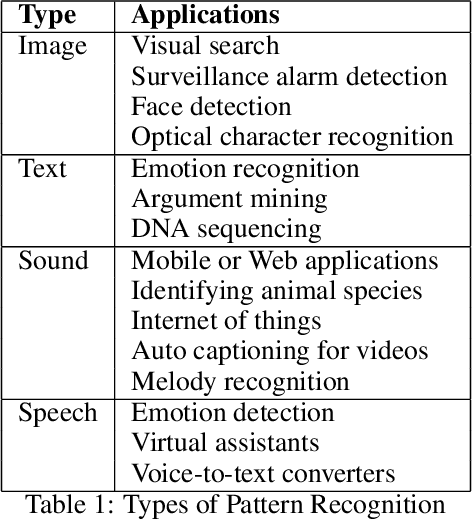

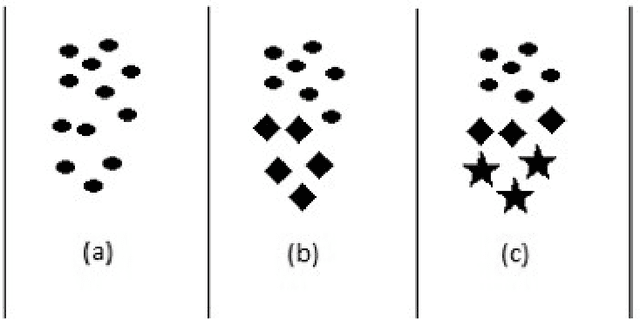
Big data streams are possibly one of the most essential underlying notions. However, data streams are often challenging to handle owing to their rapid pace and limited information lifetime. It is difficult to collect and communicate stream samples while storing, transmitting and computing a function across the whole stream or even a large segment of it. In answer to this research issue, many streaming-specific solutions were developed. Stream techniques imply a limited capacity of one or more resources such as computing power and memory, as well as time or accuracy limits. Reservoir sampling algorithms choose and store results that are probabilistically significant. A weighted random sampling approach using a generalised sampling algorithmic framework to detect unique events is the key research goal of this work. Briefly, a gradually developed estimate of the joint stream distribution across all feasible components keeps k stream elements judged representative for the full stream. Once estimate confidence is high, k samples are chosen evenly. The complexity is O(min(k,n-k)), where n is the number of items inspected. Due to the fact that events are usually considered outliers, it is sufficient to extract element patterns and push them to an alternate version of k-means as proposed here. The suggested technique calculates the sum of squared errors (SSE) for each cluster, and this is utilised not only as a measure of convergence, but also as a quantification and an indirect assessment of the element distribution's approximation accuracy. This clustering enables for the detection of outliers in the stream based on their distance from the usual event centroids. The findings reveal that weighted sampling and res-means outperform typical approaches for stream event identification. Detected events are shown as knowledge graphs, along with typical clusters of events.
Predictive Beamforming for Integrated Sensing and Communication in Vehicular Networks: A Deep Learning Approach
Feb 08, 2022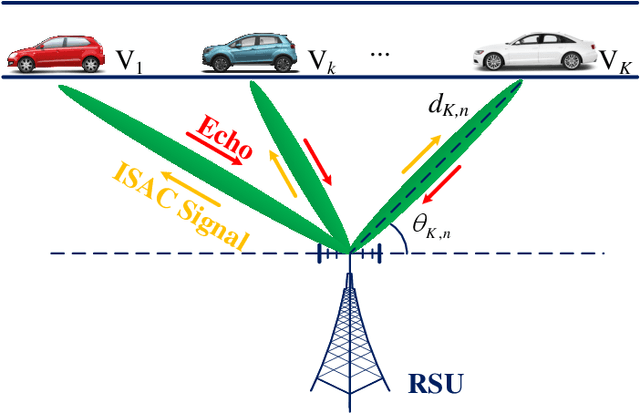
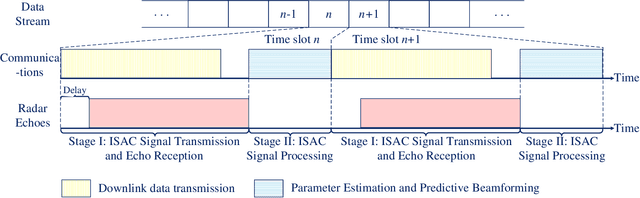
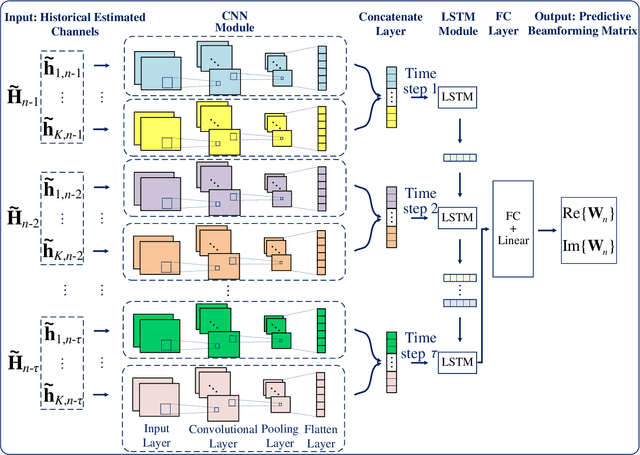
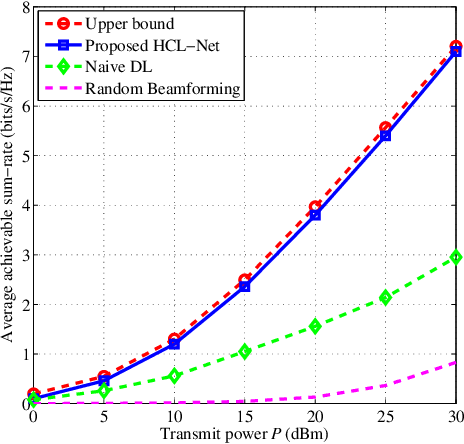
The implementation of integrated sensing and communication (ISAC) highly depends on the effective beamforming design exploiting accurate instantaneous channel state information (ICSI). However, channel tracking in ISAC requires large amount of training overhead and prohibitively large computational complexity. To address this problem, in this paper, we focus on ISAC-assisted vehicular networks and exploit a deep learning approach to implicitly learn the features of historical channels and directly predict the beamforming matrix for the next time slot to maximize the average achievable sum-rate of system, thus bypassing the need of explicit channel tracking for reducing the system signaling overhead. To this end, a general sum-rate maximization problem with Cramer-Rao lower bounds-based sensing constraints is first formulated for the considered ISAC system. Then, a historical channels-based convolutional long short-term memory network is designed for predictive beamforming that can exploit the spatial and temporal dependencies of communication channels to further improve the learning performance. Finally, simulation results show that the proposed method can satisfy the requirement of sensing performance, while its achievable sum-rate can approach the upper bound obtained by a genie-aided scheme with perfect ICSI available.
ContourletNet: A Generalized Rain Removal Architecture Using Multi-Direction Hierarchical Representation
Nov 25, 2021


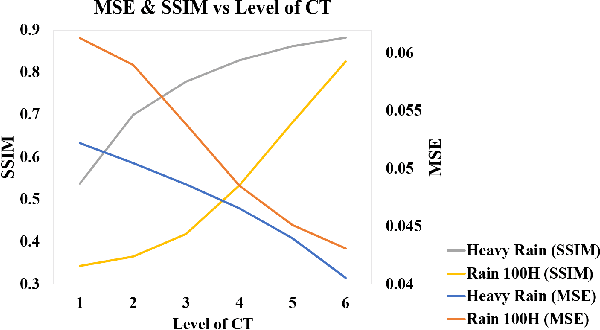
Images acquired from rainy scenes usually suffer from bad visibility which may damage the performance of computer vision applications. The rainy scenarios can be categorized into two classes: moderate rain and heavy rain scenes. Moderate rain scene mainly consists of rain streaks while heavy rain scene contains both rain streaks and the veiling effect (similar to haze). Although existing methods have achieved excellent performance on these two cases individually, it still lacks a general architecture to address both heavy rain and moderate rain scenarios effectively. In this paper, we construct a hierarchical multi-direction representation network by using the contourlet transform (CT) to address both moderate rain and heavy rain scenarios. The CT divides the image into the multi-direction subbands (MS) and the semantic subband (SS). First, the rain streak information is retrieved to the MS based on the multi-orientation property of the CT. Second, a hierarchical architecture is proposed to reconstruct the background information including damaged semantic information and the veiling effect in the SS. Last, the multi-level subband discriminator with the feedback error map is proposed. By this module, all subbands can be well optimized. This is the first architecture that can address both of the two scenarios effectively. The code is available in https://github.com/cctakaet/ContourletNet-BMVC2021.