 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNotes2Skills: From Lab Notebooks to Certainty-Aware Scientific Agent Skills
Jun 10, 2026Scientific discovery workflows usually contain and rely heavily on lab notes, where researchers record observations, interpret uncertain results, and plan follow-up experiments. Such informative lab notes preserve evolving scientific reasoning and author uncertainty, rather than polished final results exhibited in publications, providing a valuable opportunity for AI to engage in scientific exploration at a more comprehensive and deeper level. However, most prior work on scientific text focuses on papers, protocols, or structured databases, leaving informal laboratory notes underexplored as inputs to AI agents for science. This gap matters because lab notes often intermingle validated observations, tentative judgments, and possible experimental next steps within the same passage. If these signals are conflated, an AI agent may mistake uncertain scientific judgments for confirmed conclusions or executable actions. To this end, we present Notes2Skills, a two-stage framework for turning lab notebooks into verifiable skills for scientific AI agents while preserving the author's certainty. Across seven conditions and three wet-lab sessions, Notes2Skills is the only configuration that neither mistakes uncertain notes for firm instructions nor discards firm ones. We show that certainty preservation is the missing piece between lab notebooks and reliable agent skills, opening a path toward safer AI co-scientist systems.
Robust LLM Unlearning Against Relearning Attacks: The Minor Components in Representations Matter
May 12, 2026Large language model (LLM) unlearning aims to remove specific data influences from pre-trained model without costly retraining, addressing privacy, copyright, and safety concerns. However, recent studies reveal a critical vulnerability: unlearned models rapidly recover "forgotten" knowledge through relearning attacks. This fragility raises serious security concerns, especially for open-weight models. In this work, we investigate the fundamental mechanism underlying this fragility from a representation geometry perspective. We discover that existing unlearning methods predominantly optimize along dominant components, leaving minor components largely unchanged. Critically, during relearning attacks, the modifications in these dominant components are easily reversed, enabling rapid knowledge recovery, whereas minor components exhibit stronger resistance to such reversal. We further provide a theoretical analysis that explains both observations from the spectral structure of representations. Building on this insight, we propose Minor Component Unlearning (MCU), a novel unlearning approach that explicitly targets minor components in representations. By concentrating unlearning effects in these inherently robust directions, our method achieves substantially improved resistance to relearning attacks. Extensive experiments on three datasets validate our approach, demonstrating significant improvements over state-of-the-art methods including sharpness-aware minimization.
A Novel Framework with Information Fusion and Neighborhood Enhancement for User Identity Linkage
Mar 16, 2020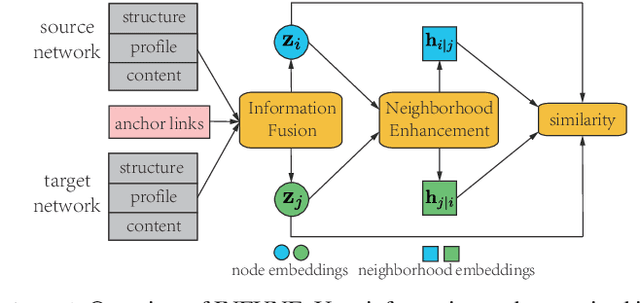
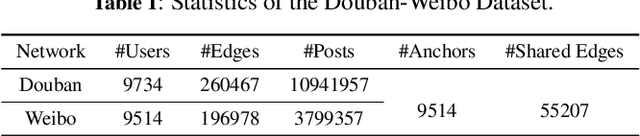
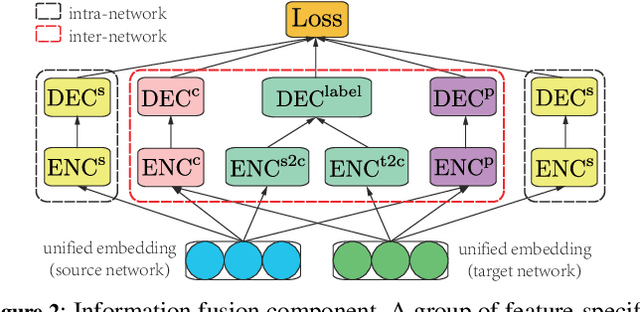

User identity linkage across social networks is an essential problem for cross-network data mining. Since network structure, profile and content information describe different aspects of users, it is critical to learn effective user representations that integrate heterogeneous information. This paper proposes a novel framework with INformation FUsion and Neighborhood Enhancement (INFUNE) for user identity linkage. The information fusion component adopts a group of encoders and decoders to fuse heterogeneous information and generate discriminative node embeddings for preliminary matching. Then, these embeddings are fed to the neighborhood enhancement component, a novel graph neural network, to produce adaptive neighborhood embeddings that reflect the overlapping degree of neighborhoods of varying candidate user pairs. The importance of node embeddings and neighborhood embeddings are weighted for final prediction. The proposed method is evaluated on real-world social network data. The experimental results show that INFUNE significantly outperforms existing state-of-the-art methods.