 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Information Newton's flow: second-order optimization method in probability space
Jan 13, 2020
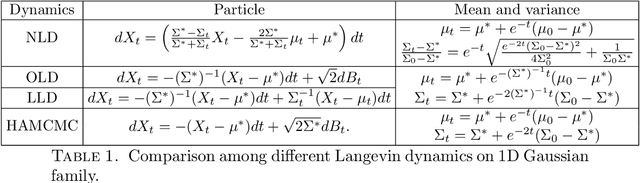
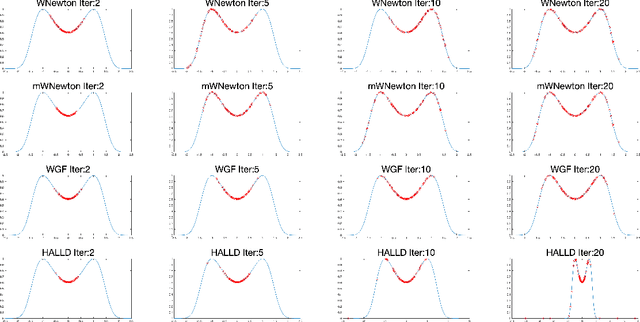

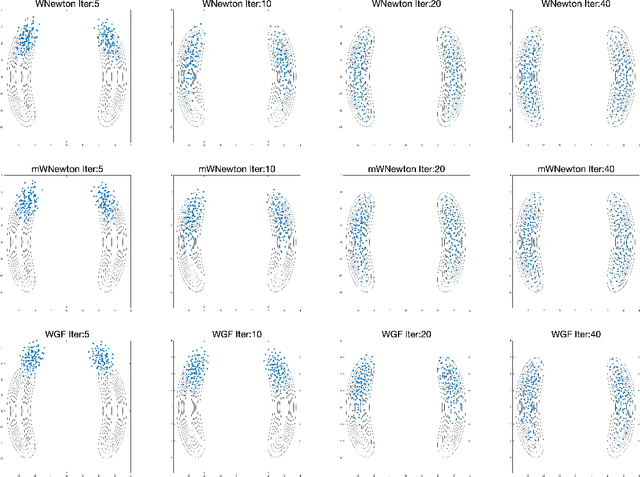
We introduce a framework for Newton's flows in probability space with information metrics, named information Newton's flows. Here two information metrics are considered, including both the Fisher-Rao metric and the Wasserstein-2 metric. Several examples of information Newton's flows for learning objective/loss functions are provided, such as Kullback-Leibler (KL) divergence, Maximum mean discrepancy (MMD), and cross entropy. The asymptotic convergence results of proposed Newton's methods are provided. A known fact is that overdamped Langevin dynamics correspond to Wasserstein gradient flows of KL divergence. Extending this fact to Wasserstein Newton's flows of KL divergence, we derive Newton's Langevin dynamics. We provide examples of Newton's Langevin dynamics in both one-dimensional space and Gaussian families. For the numerical implementation, we design sampling efficient variational methods to approximate Wasserstein Newton's directions. Several numerical examples in Gaussian families and Bayesian logistic regression are shown to demonstrate the effectiveness of the proposed method.
The BrainScaleS-2 accelerated neuromorphic system with hybrid plasticity
Jan 26, 2022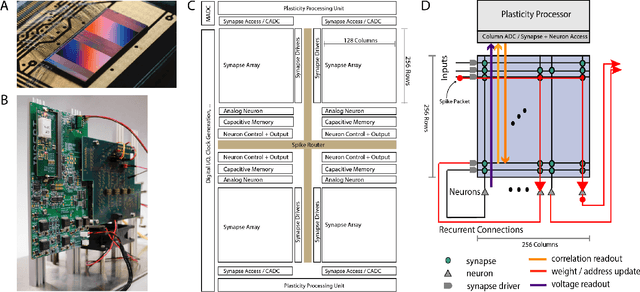
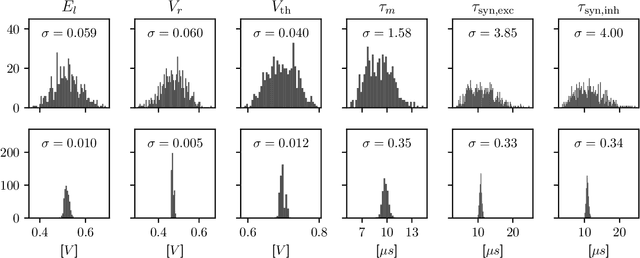
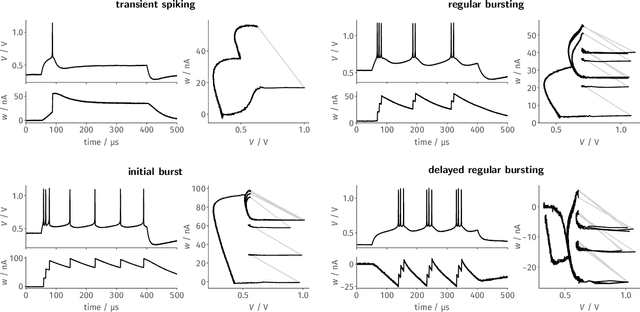
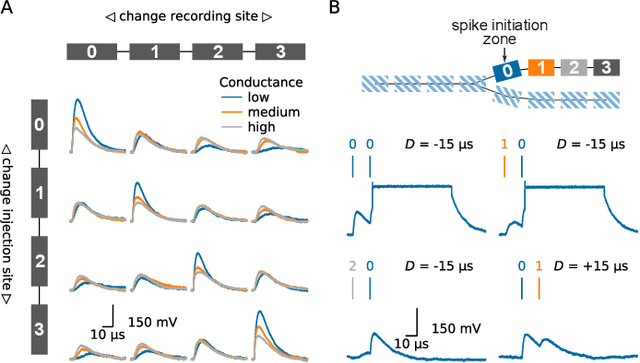
Since the beginning of information processing by electronic components, the nervous system has served as a metaphor for the organization of computational primitives. Brain-inspired computing today encompasses a class of approaches ranging from using novel nano-devices for computation to research into large-scale neuromorphic architectures, such as TrueNorth, SpiNNaker, BrainScaleS, Tianjic, and Loihi. While implementation details differ, spiking neural networks -- sometimes referred to as the third generation of neural networks -- are the common abstraction used to model computation with such systems. Here we describe the second generation of the BrainScaleS neuromorphic architecture, emphasizing applications enabled by this architecture. It combines a custom analog accelerator core supporting the accelerated physical emulation of bio-inspired spiking neural network primitives with a tightly coupled digital processor and a digital event-routing network.
Shape-consistent Generative Adversarial Networks for multi-modal Medical segmentation maps
Feb 04, 2022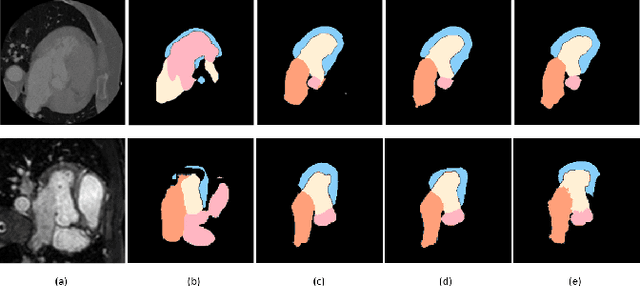
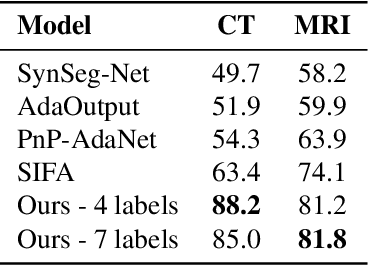


Image translation across domains for unpaired datasets has gained interest and great improvement lately. In medical imaging, there are multiple imaging modalities, with very different characteristics. Our goal is to use cross-modality adaptation between CT and MRI whole cardiac scans for semantic segmentation. We present a segmentation network using synthesised cardiac volumes for extremely limited datasets. Our solution is based on a 3D cross-modality generative adversarial network to share information between modalities and generate synthesized data using unpaired datasets. Our network utilizes semantic segmentation to improve generator shape consistency, thus creating more realistic synthesised volumes to be used when re-training the segmentation network. We show that improved segmentation can be achieved on small datasets when using spatial augmentations to improve a generative adversarial network. These augmentations improve the generator capabilities, thus enhancing the performance of the Segmentor. Using only 16 CT and 16 MRI cardiovascular volumes, improved results are shown over other segmentation methods while using the suggested architecture.
Empirical Risk Minimization with Relative Entropy Regularization: Optimality and Sensitivity Analysis
Feb 09, 2022The optimality and sensitivity of the empirical risk minimization problem with relative entropy regularization (ERM-RER) are investigated for the case in which the reference is a sigma-finite measure instead of a probability measure. This generalization allows for a larger degree of flexibility in the incorporation of prior knowledge over the set of models. In this setting, the interplay of the regularization parameter, the reference measure, the risk function, and the empirical risk induced by the solution of the ERM-RER problem is characterized. This characterization yields necessary and sufficient conditions for the existence of a regularization parameter that achieves an arbitrarily small empirical risk with arbitrarily high probability. The sensitivity of the expected empirical risk to deviations from the solution of the ERM-RER problem is studied. The sensitivity is then used to provide upper and lower bounds on the expected empirical risk. Moreover, it is shown that the expectation of the sensitivity is upper bounded, up to a constant factor, by the square root of the lautum information between the models and the datasets.
Shaping Visual Representations with Attributes for Few-Shot Learning
Dec 13, 2021
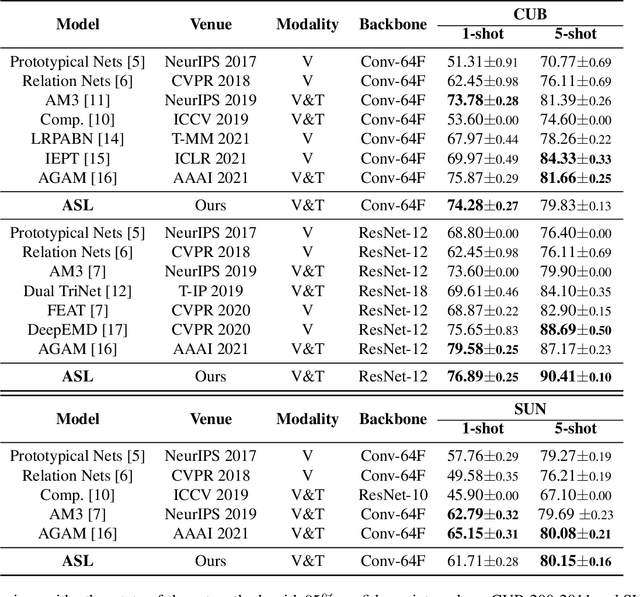
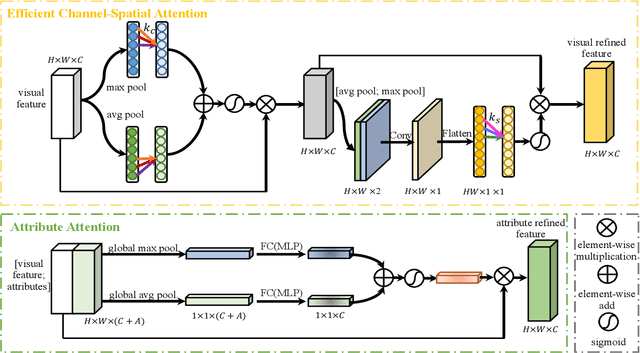
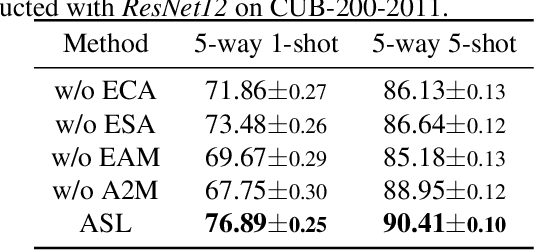
Few-shot recognition aims to recognize novel categories under low-data regimes. Due to the scarcity of images, machines cannot obtain enough effective information, and the generalization ability of the model is extremely weak. By using auxiliary semantic modalities, recent metric-learning based few-shot learning methods have achieved promising performances. However, these methods only augment the representations of support classes, while query images have no semantic modalities information to enhance representations. Instead, we propose attribute-shaped learning (ASL), which can normalize visual representations to predict attributes for query images. And we further devise an attribute-visual attention module (AVAM), which utilizes attributes to generate more discriminative features. Our method enables visual representations to focus on important regions with attributes guidance. Experiments demonstrate that our method can achieve competitive results on CUB and SUN benchmarks. Our code is available at {https://github.com/chenhaoxing/ASL}.
Coordinate-Aligned Multi-Camera Collaboration for Active Multi-Object Tracking
Feb 22, 2022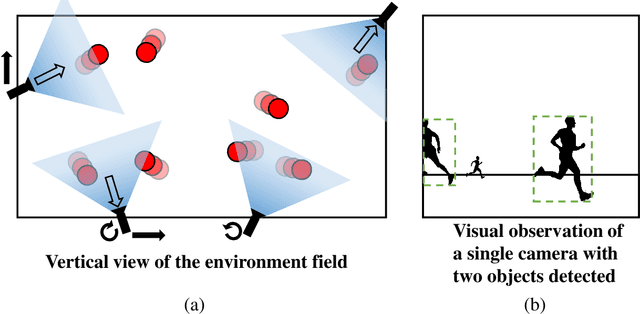
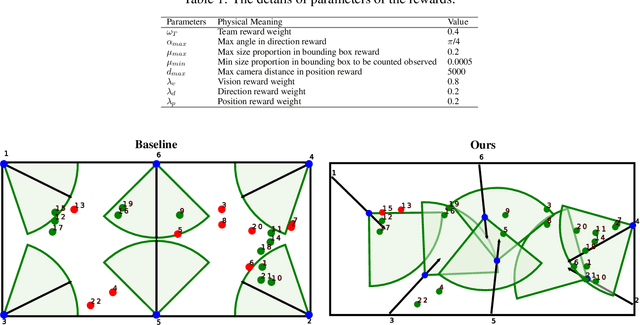
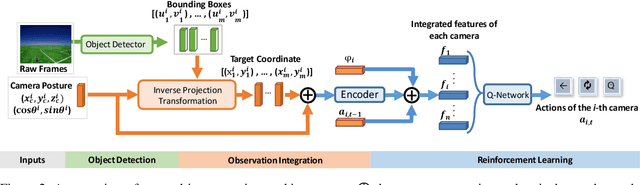

Active Multi-Object Tracking (AMOT) is a task where cameras are controlled by a centralized system to adjust their poses automatically and collaboratively so as to maximize the coverage of targets in their shared visual field. In AMOT, each camera only receives partial information from its observation, which may mislead cameras to take locally optimal action. Besides, the global goal, i.e., maximum coverage of objects, is hard to be directly optimized. To address the above issues, we propose a coordinate-aligned multi-camera collaboration system for AMOT. In our approach, we regard each camera as an agent and address AMOT with a multi-agent reinforcement learning solution. To represent the observation of each agent, we first identify the targets in the camera view with an image detector, and then align the coordinates of the targets in 3D environment. We define the reward of each agent based on both global coverage as well as four individual reward terms. The action policy of the agents is derived with a value-based Q-network. To the best of our knowledge, we are the first to study the AMOT task. To train and evaluate the efficacy of our system, we build a virtual yet credible 3D environment, named "Soccer Court", to mimic the real-world AMOT scenario. The experimental results show that our system achieves a coverage of 71.88%, outperforming the baseline method by 8.9%.
Finite-time enclosing control for multiple moving targets: a continuous estimator approach
Feb 01, 2022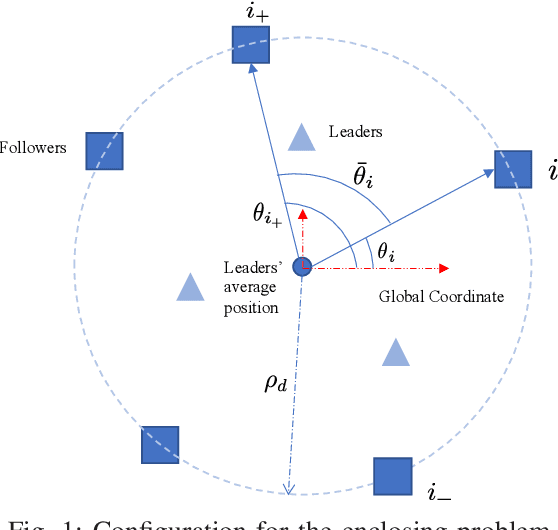
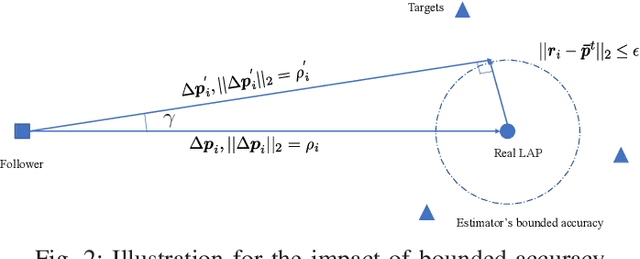
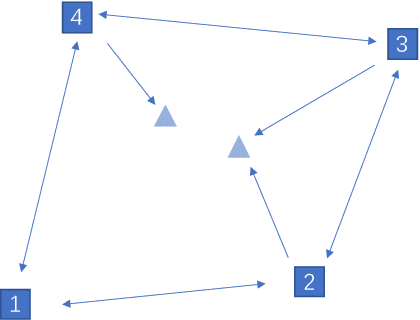
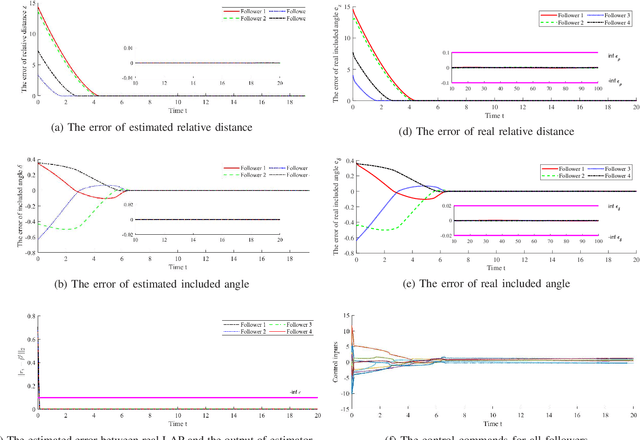
This work addresses the finite-time enclosing control problem where a set of followers are deployed to encircle and rotate around multiple moving targets with a predefined spacing pattern in finite time. A novel distributed and continuous estimator is firstly proposed to track the geometric center of targets in finite time using only local information for every follower. Then a pair of decentralized control laws for both the relative distance and included angle, respectively, are designed to achieve the desired spacing pattern in finite time based on the output of the proposed estimator. Through both theoretical analysis and simulation validation, we show that the proposed estimator is continuous and therefore can avoid dithering control output while still inheriting the merit of finite-time convergence. The steady errors of the estimator and the enclosing controller are guaranteed to converge to some bounded and adjustable regions around zero.
The CUHK-TENCENT speaker diarization system for the ICASSP 2022 multi-channel multi-party meeting transcription challenge
Feb 04, 2022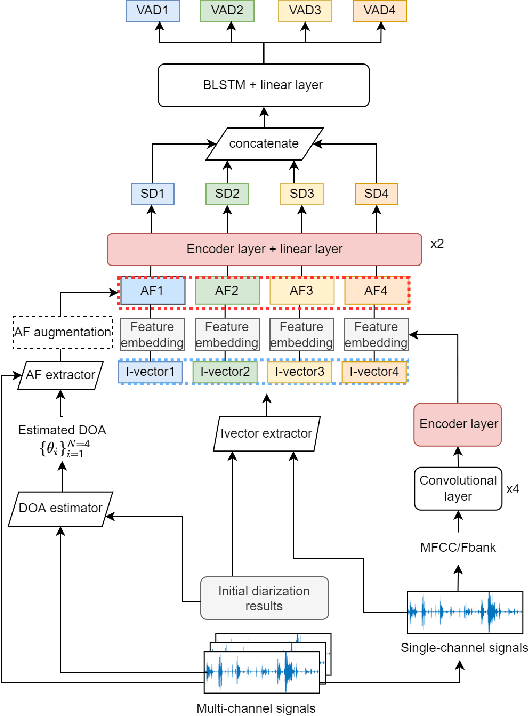
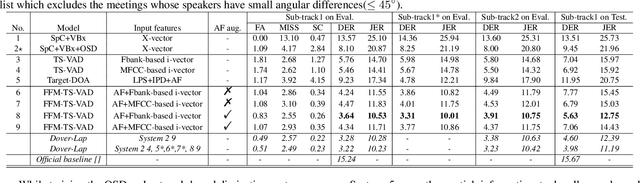
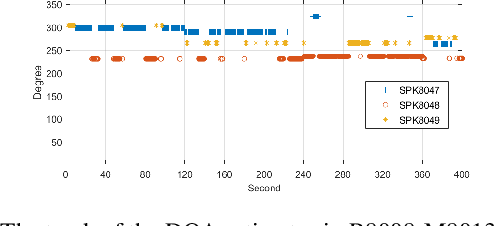
This paper describes our speaker diarization system submitted to the Multi-channel Multi-party Meeting Transcription (M2MeT) challenge, where Mandarin meeting data were recorded in multi-channel format for diarization and automatic speech recognition (ASR) tasks. In these meeting scenarios, the uncertainty of the speaker number and the high ratio of overlapped speech present great challenges for diarization. Based on the assumption that there is valuable complementary information between acoustic features, spatial-related and speaker-related features, we propose a multi-level feature fusion mechanism based target-speaker voice activity detection (FFM-TS-VAD) system to improve the performance of the conventional TS-VAD system. Furthermore, we propose a data augmentation method during training to improve the system robustness when the angular difference between two speakers is relatively small. We provide comparisons for different sub-systems we used in M2MeT challenge. Our submission is a fusion of several sub-systems and ranks second in the diarization task.
Visual Object Tracking on Multi-modal RGB-D Videos: A Review
Jan 23, 2022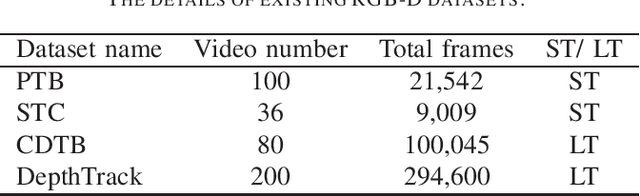
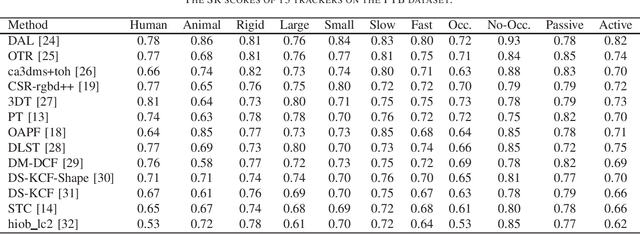
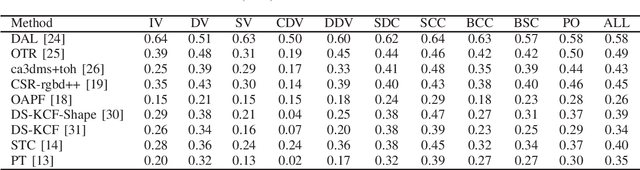

The development of visual object tracking has continued for decades. Recent years, as the wide accessibility of the low-cost RGBD sensors, the task of visual object tracking on RGB-D videos has drawn much attention. Compared to conventional RGB-only tracking, the RGB-D videos can provide more information that facilitates objecting tracking in some complicated scenarios. The goal of this review is to summarize the relative knowledge of the research filed of RGB-D tracking. To be specific, we will generalize the related RGB-D tracking benchmarking datasets as well as the corresponding performance measurements. Besides, the existing RGB-D tracking methods are summarized in the paper. Moreover, we discuss the possible future direction in the field of RGB-D tracking.
Span Based Open Information Extraction
Jan 30, 2019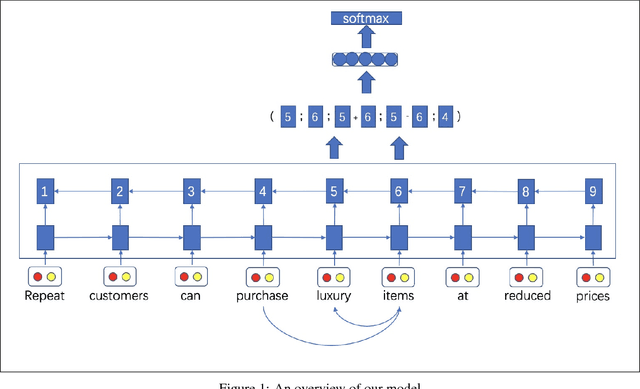
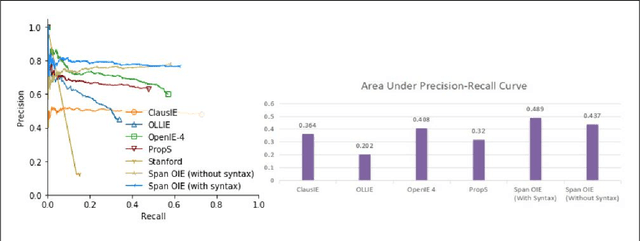
In this paper, we propose a span based model combined with syntactic information for n-ary open information extraction. The advantage of span model is that it can leverage span level features, which is difficult in token based BIO tagging methods. We also improve the previous bootstrap method to construct training corpus. Experiments show that our model outperforms previous open information extraction systems. Our code and data are publicly available at https://github.com/zhanjunlang/Span_OIE