 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training
Mar 23, 2022
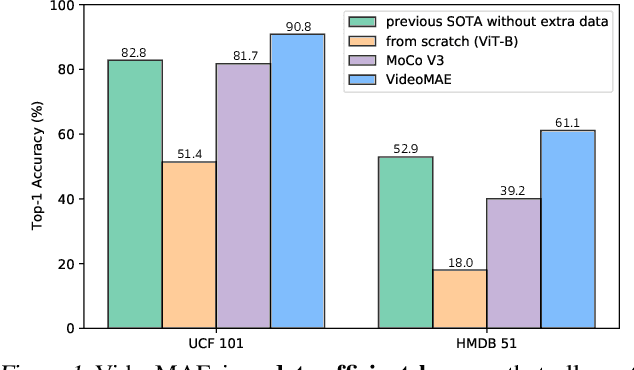
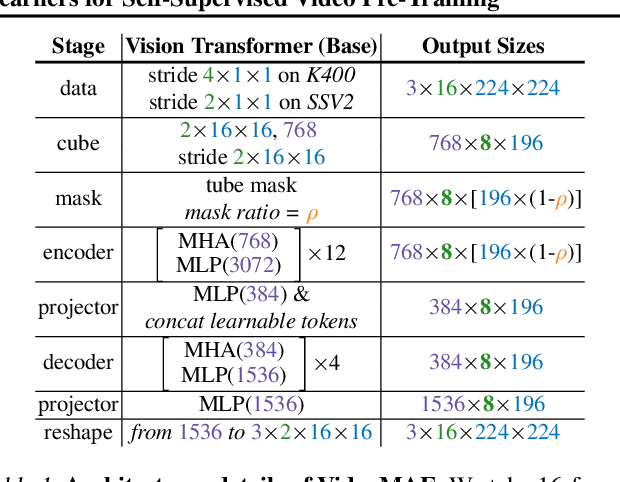
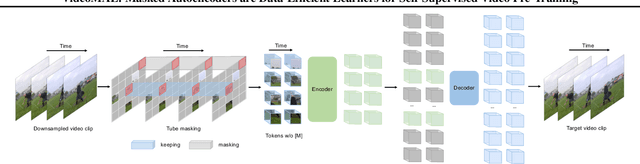
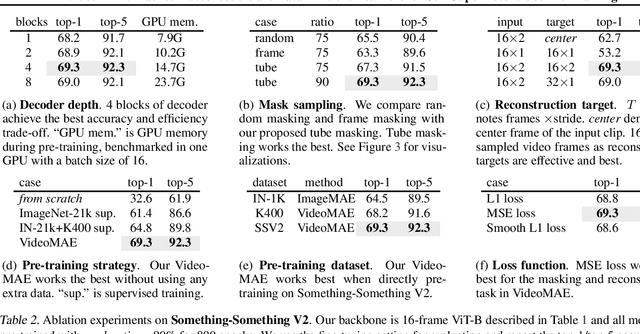
Pre-training video transformers on extra large-scale datasets is generally required to achieve premier performance on relatively small datasets. In this paper, we show that video masked autoencoders (VideoMAE) are data-efficient learners for self-supervised video pre-training (SSVP). We are inspired by the recent ImageMAE and propose customized video tube masking and reconstruction. These simple designs turn out to be effective for overcoming information leakage caused by the temporal correlation during video reconstruction. We obtain three important findings on SSVP: (1) An extremely high proportion of masking ratio (i.e., 90% to 95%) still yields favorable performance of VideoMAE. The temporally redundant video content enables higher masking ratio than that of images. (2) VideoMAE achieves impressive results on very small datasets (i.e., around 3k-4k videos) without using any extra data. This is partially ascribed to the challenging task of video reconstruction to enforce high-level structure learning. (3) VideoMAE shows that data quality is more important than data quantity for SSVP. Domain shift between pre-training and target datasets are important issues in SSVP. Notably, our VideoMAE with the vanilla ViT backbone can achieve 83.9% on Kinects-400, 75.3% on Something-Something V2, 90.8% on UCF101, and 61.1% on HMDB51 without using any extra data. Code will be released at https://github.com/MCG-NJU/VideoMAE.
CrowdMLP: Weakly-Supervised Crowd Counting via Multi-Granularity MLP
Mar 15, 2022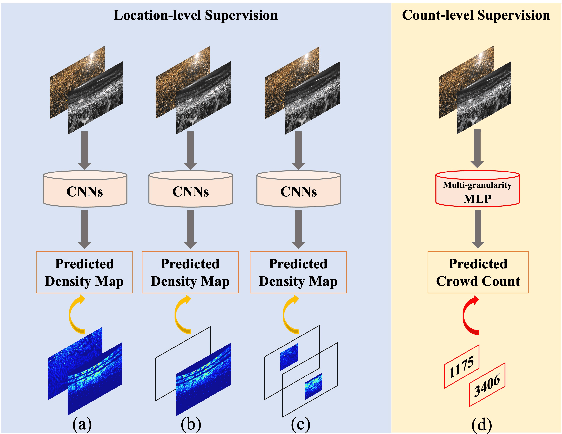
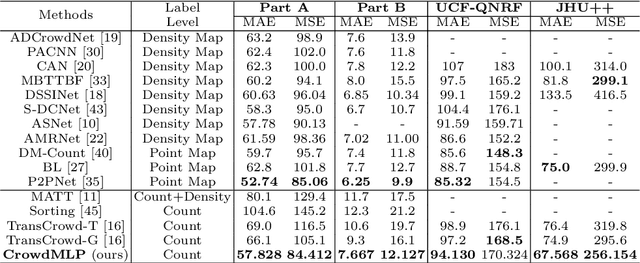
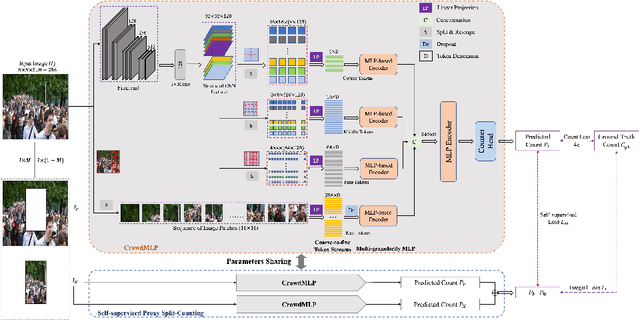
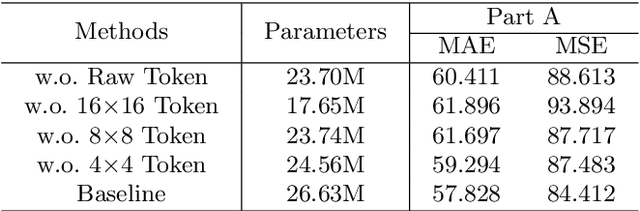
Existing state-of-the-art crowd counting algorithms rely excessively on location-level annotations, which are burdensome to acquire. When only count-level (weak) supervisory signals are available, it is arduous and error-prone to regress total counts due to the lack of explicit spatial constraints. To address this issue, a novel and efficient counter (referred to as CrowdMLP) is presented, which probes into modelling global dependencies of embeddings and regressing total counts by devising a multi-granularity MLP regressor. In specific, a locally-focused pre-trained frontend is cascaded to extract crude feature maps with intrinsic spatial cues, which prevent the model from collapsing into trivial outcomes. The crude embeddings, along with raw crowd scenes, are tokenized at different granularity levels. The multi-granularity MLP then proceeds to mix tokens at the dimensions of cardinality, channel, and spatial for mining global information. An effective proxy task, namely Split-Counting, is also proposed to evade the barrier of limited samples and the shortage of spatial hints in a self-supervised manner. Extensive experiments demonstrate that CrowdMLP significantly outperforms existing weakly-supervised counting algorithms and performs on par with state-of-the-art location-level supervised approaches.
Refine-Net: Normal Refinement Neural Network for Noisy Point Clouds
Mar 23, 2022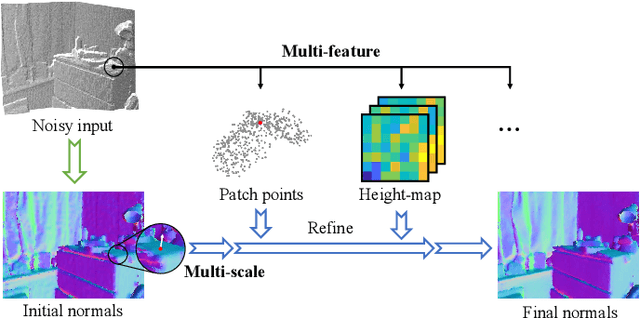
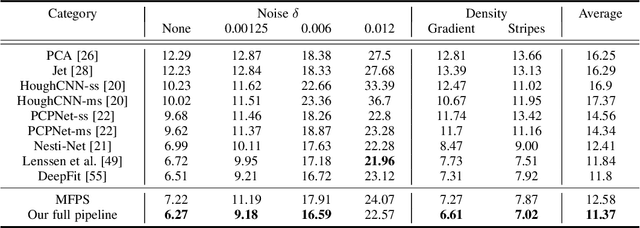

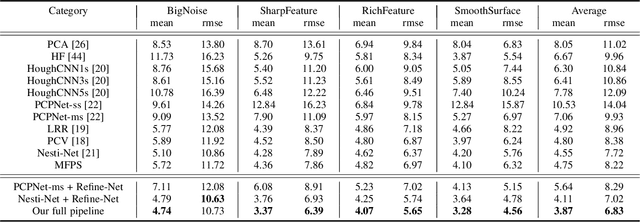
Point normal, as an intrinsic geometric property of 3D objects, not only serves conventional geometric tasks such as surface consolidation and reconstruction, but also facilitates cutting-edge learning-based techniques for shape analysis and generation. In this paper, we propose a normal refinement network, called Refine-Net, to predict accurate normals for noisy point clouds. Traditional normal estimation wisdom heavily depends on priors such as surface shapes or noise distributions, while learning-based solutions settle for single types of hand-crafted features. Differently, our network is designed to refine the initial normal of each point by extracting additional information from multiple feature representations. To this end, several feature modules are developed and incorporated into Refine-Net by a novel connection module. Besides the overall network architecture of Refine-Net, we propose a new multi-scale fitting patch selection scheme for the initial normal estimation, by absorbing geometry domain knowledge. Also, Refine-Net is a generic normal estimation framework: 1) point normals obtained from other methods can be further refined, and 2) any feature module related to the surface geometric structures can be potentially integrated into the framework. Qualitative and quantitative evaluations demonstrate the clear superiority of Refine-Net over the state-of-the-arts on both synthetic and real-scanned datasets. Our code is available at https://github.com/hrzhou2/refinenet.
SWIS: Self-Supervised Representation Learning For Writer Independent Offline Signature Verification
Feb 26, 2022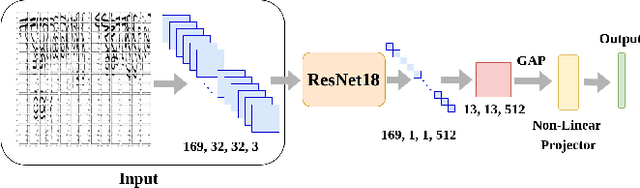

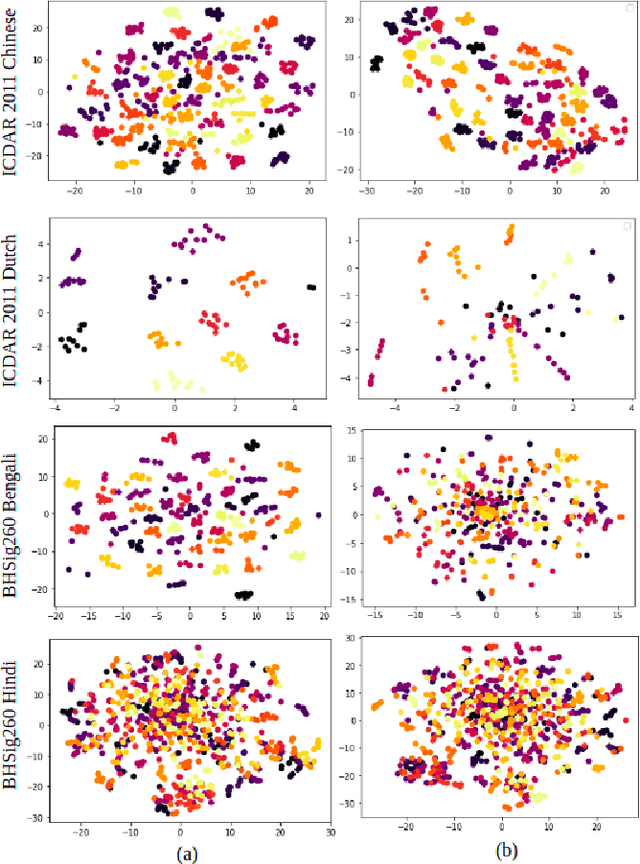
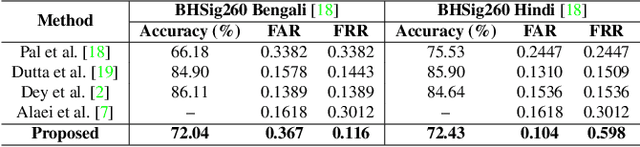
Writer independent offline signature verification is one of the most challenging tasks in pattern recognition as there is often a scarcity of training data. To handle such data scarcity problem, in this paper, we propose a novel self-supervised learning (SSL) framework for writer independent offline signature verification. To our knowledge, this is the first attempt to utilize self-supervised setting for the signature verification task. The objective of self-supervised representation learning from the signature images is achieved by minimizing the cross-covariance between two random variables belonging to different feature directions and ensuring a positive cross-covariance between the random variables denoting the same feature direction. This ensures that the features are decorrelated linearly and the redundant information is discarded. Through experimental results on different data sets, we obtained encouraging results.
Towards Rich, Portable, and Large-Scale Pedestrian Data Collection
Mar 03, 2022


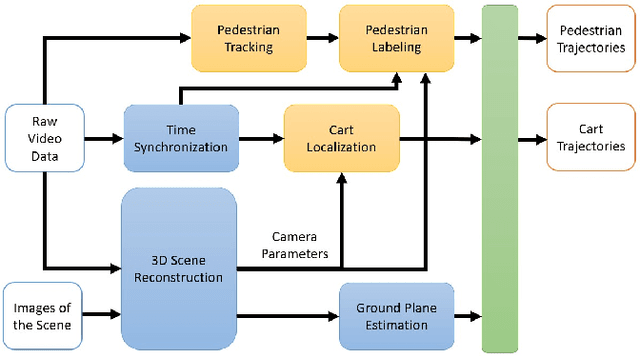
Recently, pedestrian behavior research has shifted towards machine learning based methods and converged on the topic of modeling pedestrian interactions. For this, a large-scale dataset that contains rich information is needed. We propose a data collection system that is portable, which facilitates accessible large-scale data collection in diverse environments. We also couple the system with a semi-autonomous labeling pipeline for fast trajectory label production. We demonstrate the effectiveness of our system by further introducing a dataset we have collected -- the TBD pedestrian dataset. Compared with existing pedestrian datasets, our dataset contains three components: human verified labels grounded in the metric space, a combination of top-down and perspective views, and naturalistic human behavior in the presence of a socially appropriate "robot". In addition, the TBD pedestrian dataset is larger in quantity compared to similar existing datasets and contains unique pedestrian behavior.
ARTEMIS: Attention-based Retrieval with Text-Explicit Matching and Implicit Similarity
Mar 15, 2022
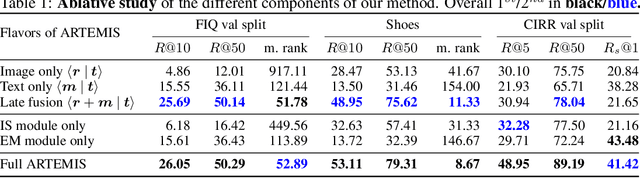
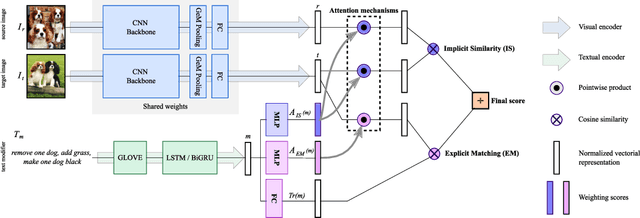
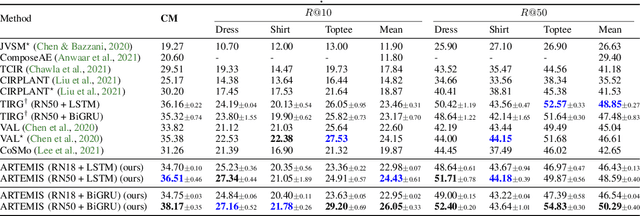
An intuitive way to search for images is to use queries composed of an example image and a complementary text. While the first provides rich and implicit context for the search, the latter explicitly calls for new traits, or specifies how some elements of the example image should be changed to retrieve the desired target image. Current approaches typically combine the features of each of the two elements of the query into a single representation, which can then be compared to the ones of the potential target images. Our work aims at shedding new light on the task by looking at it through the prism of two familiar and related frameworks: text-to-image and image-to-image retrieval. Taking inspiration from them, we exploit the specific relation of each query element with the targeted image and derive light-weight attention mechanisms which enable to mediate between the two complementary modalities. We validate our approach on several retrieval benchmarks, querying with images and their associated free-form text modifiers. Our method obtains state-of-the-art results without resorting to side information, multi-level features, heavy pre-training nor large architectures as in previous works.
Web of Scholars: A Scholar Knowledge Graph
Feb 23, 2022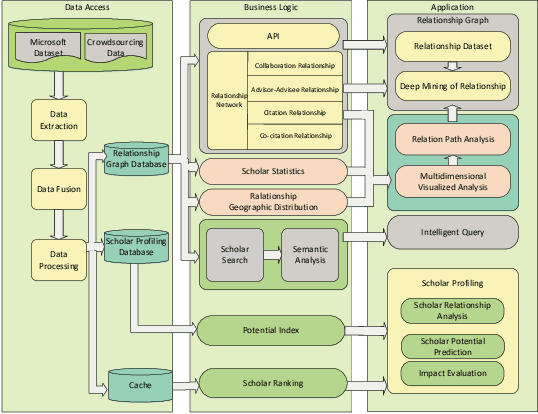
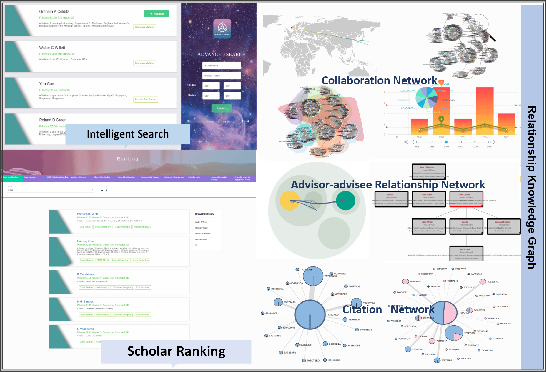
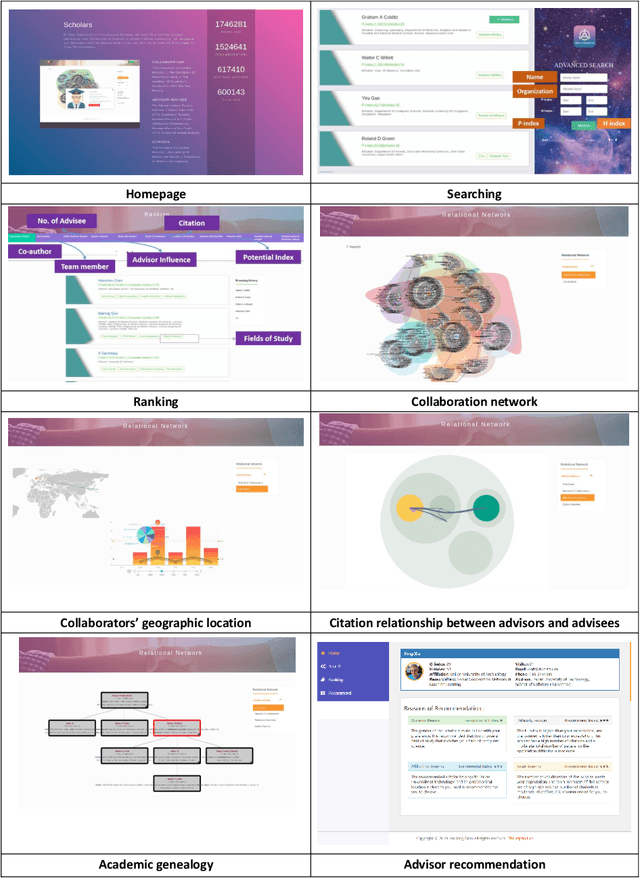
In this work, we demonstrate a novel system, namely Web of Scholars, which integrates state-of-the-art mining techniques to search, mine, and visualize complex networks behind scholars in the field of Computer Science. Relying on the knowledge graph, it provides services for fast, accurate, and intelligent semantic querying as well as powerful recommendations. In addition, in order to realize information sharing, it provides an open API to be served as the underlying architecture for advanced functions. Web of Scholars takes advantage of knowledge graph, which means that it will be able to access more knowledge if more search exist. It can be served as a useful and interoperable tool for scholars to conduct in-depth analysis within Science of Science.
Multi-Robot Collaborative Perception with Graph Neural Networks
Jan 23, 2022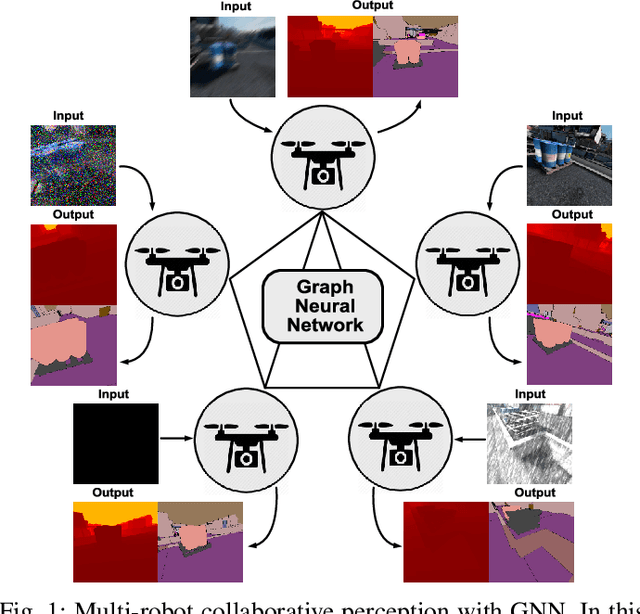

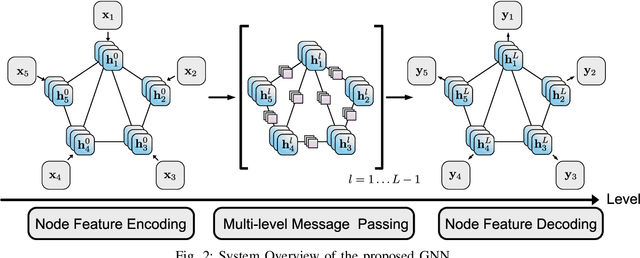
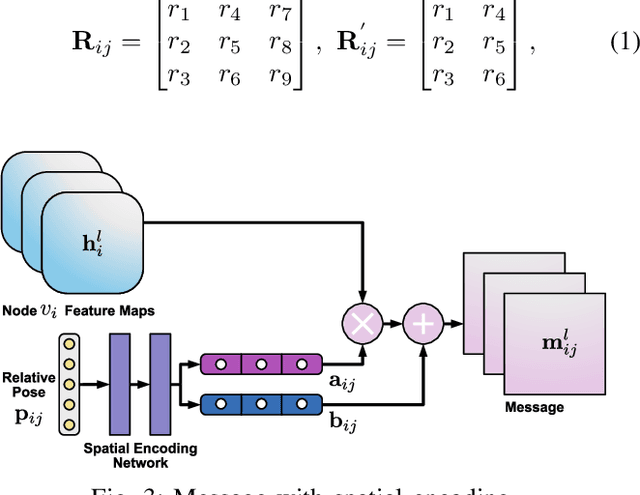
Multi-robot systems such as swarms of aerial robots are naturally suited to offer additional flexibility, resilience, and robustness in several tasks compared to a single robot by enabling cooperation among the agents. To enhance the autonomous robot decision-making process and situational awareness, multi-robot systems have to coordinate their perception capabilities to collect, share, and fuse environment information among the agents in an efficient and meaningful way such to accurately obtain context-appropriate information or gain resilience to sensor noise or failures. In this paper, we propose a general-purpose Graph Neural Network (GNN) with the main goal to increase, in multi-robot perception tasks, single robots' inference perception accuracy as well as resilience to sensor failures and disturbances. We show that the proposed framework can address multi-view visual perception problems such as monocular depth estimation and semantic segmentation. Several experiments both using photo-realistic and real data gathered from multiple aerial robots' viewpoints show the effectiveness of the proposed approach in challenging inference conditions including images corrupted by heavy noise and camera occlusions or failures.
Categorical Representation Learning and RG flow operators for algorithmic classifiers
Mar 15, 2022
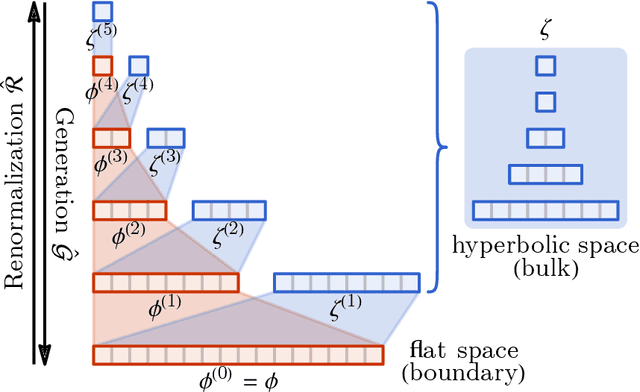

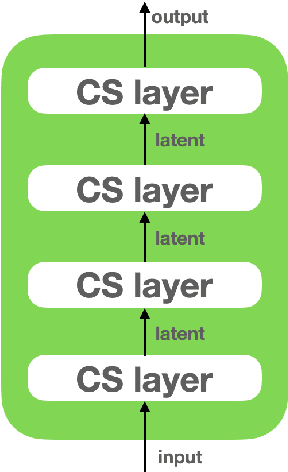
Following the earlier formalism of the categorical representation learning (arXiv:2103.14770) by the first two authors, we discuss the construction of the "RG-flow based categorifier". Borrowing ideas from theory of renormalization group flows (RG) in quantum field theory, holographic duality, and hyperbolic geometry, and mixing them with neural ODE's, we construct a new algorithmic natural language processing (NLP) architecture, called the RG-flow categorifier or for short the RG categorifier, which is capable of data classification and generation in all layers. We apply our algorithmic platform to biomedical data sets and show its performance in the field of sequence-to-function mapping. In particular we apply the RG categorifier to particular genomic sequences of flu viruses and show how our technology is capable of extracting the information from given genomic sequences, find their hidden symmetries and dominant features, classify them and use the trained data to make stochastic prediction of new plausible generated sequences associated with new set of viruses which could avoid the human immune system. The content of the current article is part of the recent US patent application submitted by first two authors (U.S. Patent Application No.: 63/313.504).
GAIL-PT: A Generic Intelligent Penetration Testing Framework with Generative Adversarial Imitation Learning
Apr 05, 2022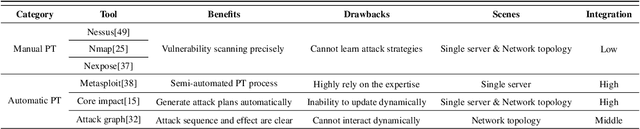
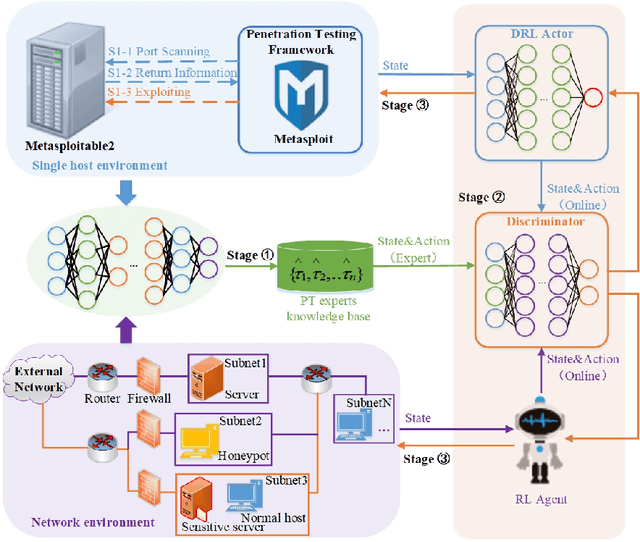

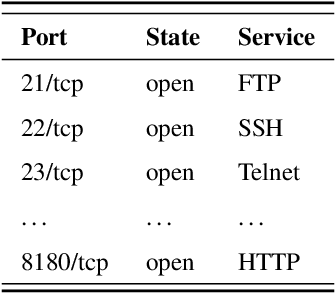
Penetration testing (PT) is an efficient network testing and vulnerability mining tool by simulating a hacker's attack for valuable information applied in some areas. Compared with manual PT, intelligent PT has become a dominating mainstream due to less time-consuming and lower labor costs. Unfortunately, RL-based PT is still challenged in real exploitation scenarios because the agent's action space is usually high-dimensional discrete, thus leading to algorithm convergence difficulty. Besides, most PT methods still rely on the decisions of security experts. Addressing the challenges, for the first time, we introduce expert knowledge to guide the agent to make better decisions in RL-based PT and propose a Generative Adversarial Imitation Learning-based generic intelligent Penetration testing framework, denoted as GAIL-PT, to solve the problems of higher labor costs due to the involvement of security experts and high-dimensional discrete action space. Specifically, first, we manually collect the state-action pairs to construct an expert knowledge base when the pre-trained RL / DRL model executes successful penetration testings. Second, we input the expert knowledge and the state-action pairs generated online by the different RL / DRL models into the discriminator of GAIL for training. At last, we apply the output reward of the discriminator to guide the agent to perform the action with a higher penetration success rate to improve PT's performance. Extensive experiments conducted on the real target host and simulated network scenarios show that GAIL-PT achieves the SOTA penetration performance against DeepExploit in exploiting actual target Metasploitable2 and Q-learning in optimizing penetration path, not only in small-scale with or without honey-pot network environments but also in the large-scale virtual network environment.