 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
FisrEbp: Enterprise Bankruptcy Prediction via Fusing its Intra-risk and Spillover-Risk
Feb 01, 2022
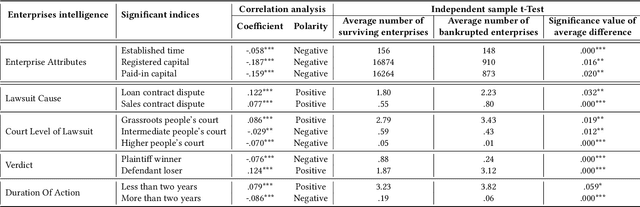
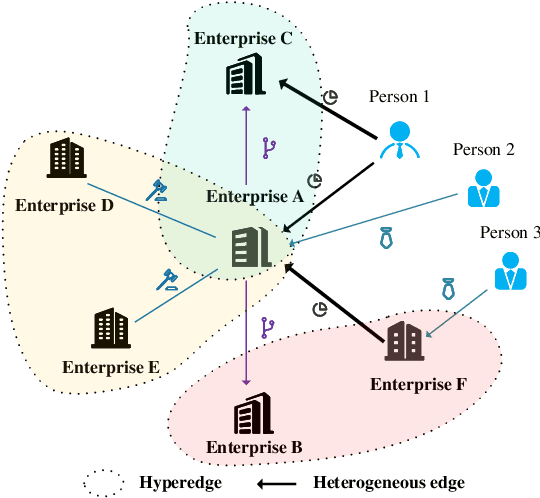
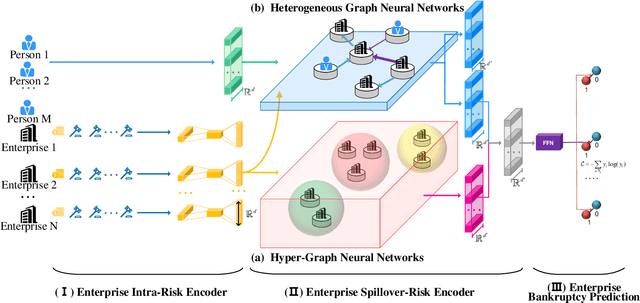
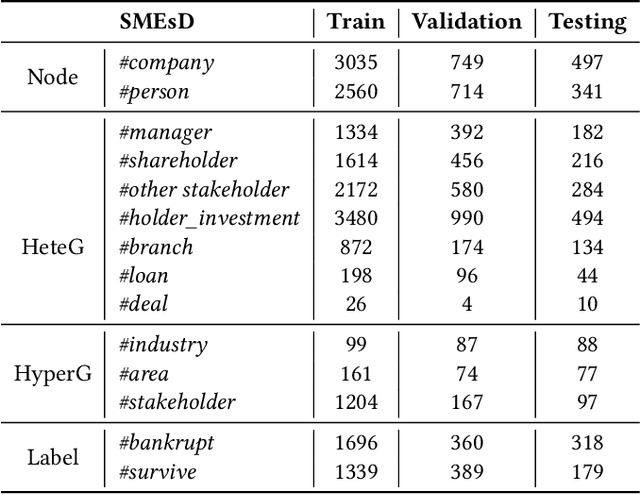
In this paper, we propose to model enterprise bankruptcy risk by fusing its intra-risk and spillover-risk. Under this framework, we propose a novel method that is equipped with an LSTM-based intra-risk encoder and GNNs-based spillover-risk encoder. Specifically, the intra-risk encoder is able to capture enterprise intra-risk using the statistic correlated indicators from the basic business information and litigation information. The spillover-risk encoder consists of hypergraph neural networks and heterogeneous graph neural networks, which aim to model spillover risk through two aspects, i.e. hyperedge and multiplex heterogeneous relations among enterprise knowledge graph, respectively. To evaluate the proposed model, we collect multi-sources SMEs data and build a new dataset SMEsD, on which the experimental results demonstrate the superiority of the proposed method. The dataset is expected to become a significant benchmark dataset for SMEs bankruptcy prediction and promote the development of financial risk study further.
Automatically Learning Fallback Strategies with Model-Free Reinforcement Learning in Safety-Critical Driving Scenarios
Apr 11, 2022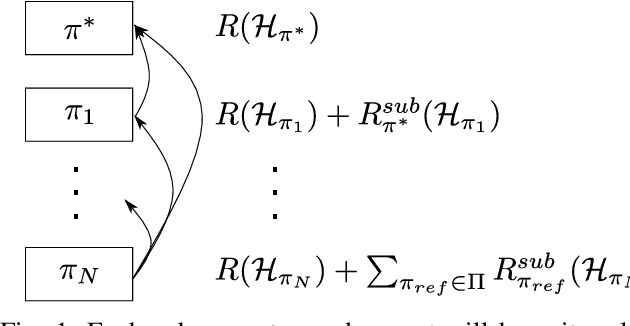
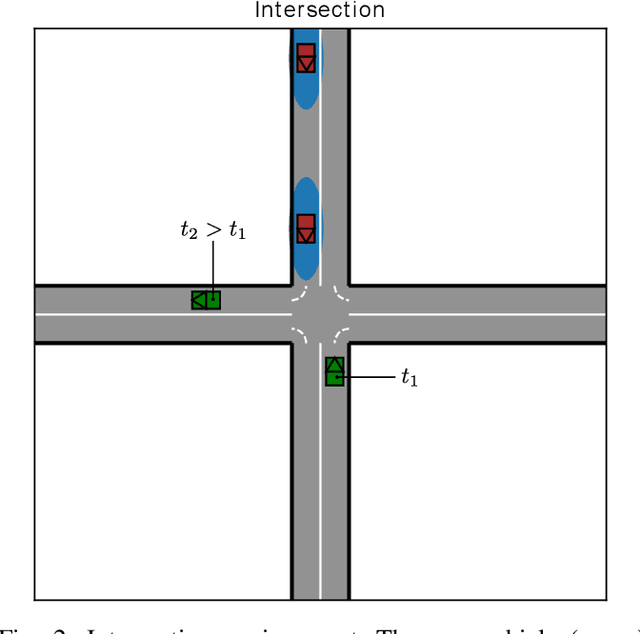
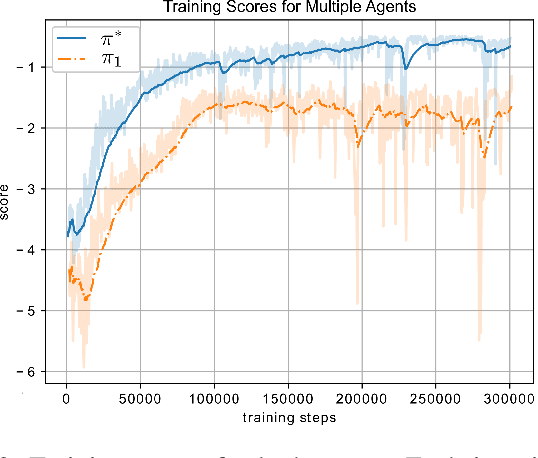
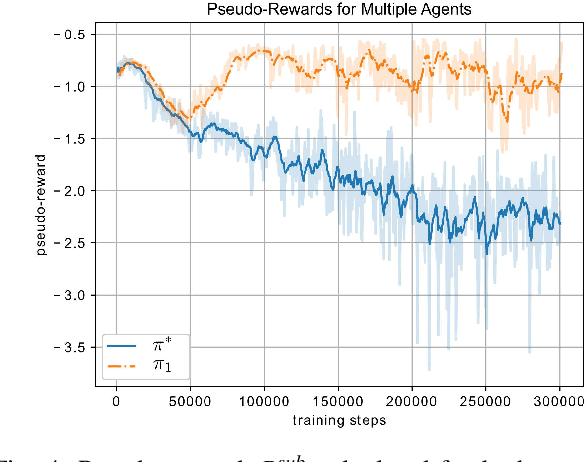
When learning to behave in a stochastic environment where safety is critical, such as driving a vehicle in traffic, it is natural for human drivers to plan fallback strategies as a backup to use if ever there is an unexpected change in the environment. Knowing to expect the unexpected, and planning for such outcomes, increases our capability for being robust to unseen scenarios and may help prevent catastrophic failures. Control of Autonomous Vehicles (AVs) has a particular interest in knowing when and how to use fallback strategies in the interest of safety. Due to imperfect information available to an AV about its environment, it is important to have alternate strategies at the ready which might not have been deduced from the original training data distribution. In this paper we present a principled approach for a model-free Reinforcement Learning (RL) agent to capture multiple modes of behaviour in an environment. We introduce an extra pseudo-reward term to the reward model, to encourage exploration to areas of state-space different from areas privileged by the optimal policy. We base this reward term on a distance metric between the trajectories of agents, in order to force policies to focus on different areas of state-space than the initial exploring agent. Throughout the paper, we refer to this particular training paradigm as learning fallback strategies. We apply this method to an autonomous driving scenario, and show that we are able to learn useful policies that would have otherwise been missed out on during training, and unavailable to use when executing the control algorithm.
Natural Language Descriptions of Deep Visual Features
Jan 26, 2022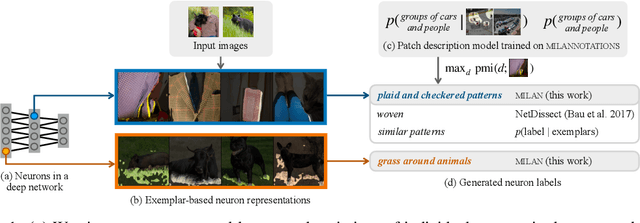
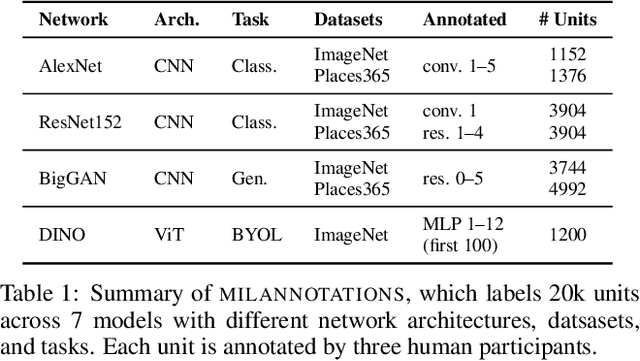
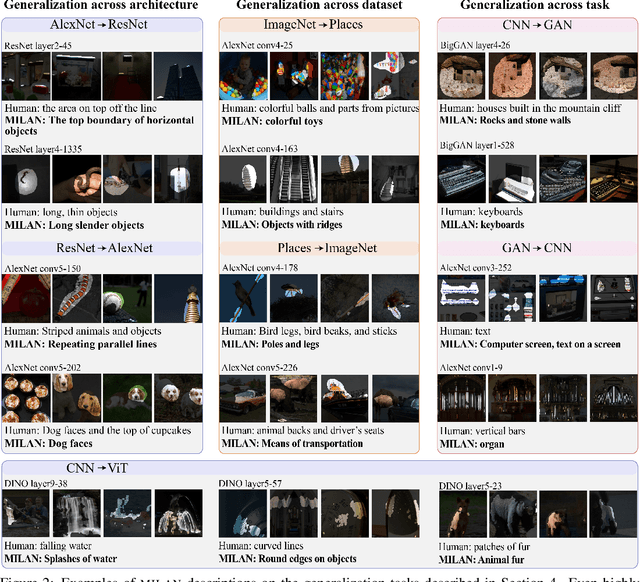
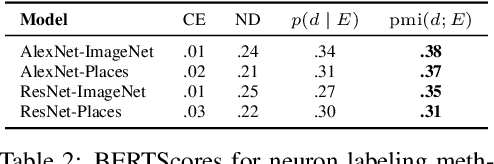
Some neurons in deep networks specialize in recognizing highly specific perceptual, structural, or semantic features of inputs. In computer vision, techniques exist for identifying neurons that respond to individual concept categories like colors, textures, and object classes. But these techniques are limited in scope, labeling only a small subset of neurons and behaviors in any network. Is a richer characterization of neuron-level computation possible? We introduce a procedure (called MILAN, for mutual-information-guided linguistic annotation of neurons) that automatically labels neurons with open-ended, compositional, natural language descriptions. Given a neuron, MILAN generates a description by searching for a natural language string that maximizes pointwise mutual information with the image regions in which the neuron is active. MILAN produces fine-grained descriptions that capture categorical, relational, and logical structure in learned features. These descriptions obtain high agreement with human-generated feature descriptions across a diverse set of model architectures and tasks, and can aid in understanding and controlling learned models. We highlight three applications of natural language neuron descriptions. First, we use MILAN for analysis, characterizing the distribution and importance of neurons selective for attribute, category, and relational information in vision models. Second, we use MILAN for auditing, surfacing neurons sensitive to protected categories like race and gender in models trained on datasets intended to obscure these features. Finally, we use MILAN for editing, improving robustness in an image classifier by deleting neurons sensitive to text features spuriously correlated with class labels.
SHGNN: Structure-Aware Heterogeneous Graph Neural Network
Dec 14, 2021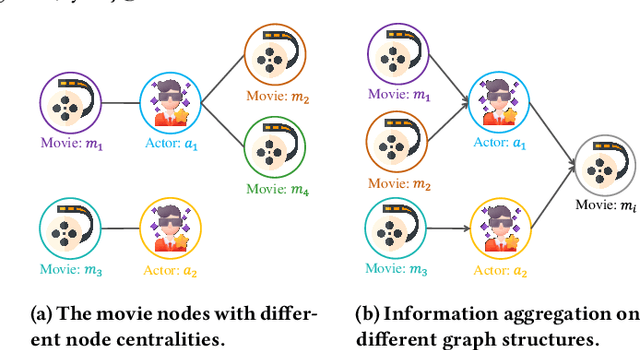
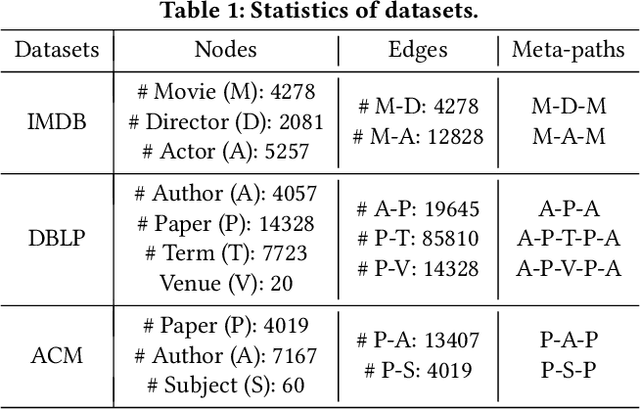
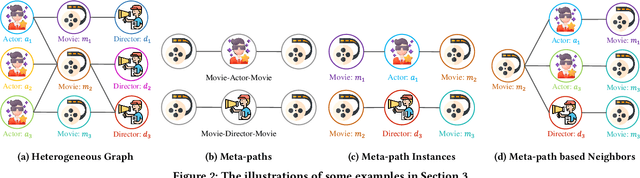
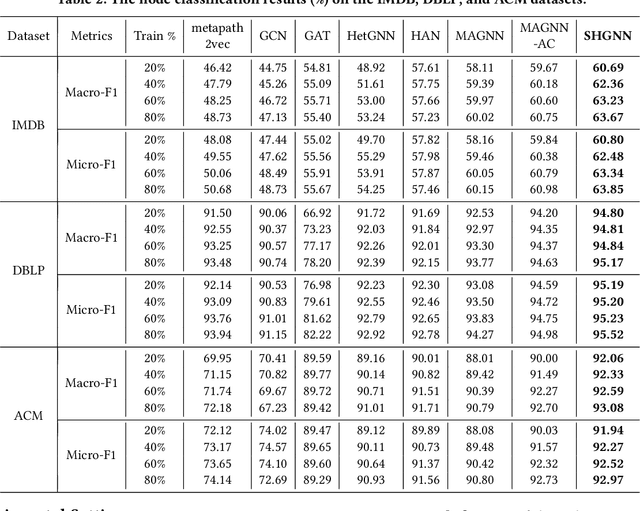
Many real-world graphs (networks) are heterogeneous with different types of nodes and edges. Heterogeneous graph embedding, aiming at learning the low-dimensional node representations of a heterogeneous graph, is vital for various downstream applications. Many meta-path based embedding methods have been proposed to learn the semantic information of heterogeneous graphs in recent years. However, most of the existing techniques overlook the graph structure information when learning the heterogeneous graph embeddings. This paper proposes a novel Structure-Aware Heterogeneous Graph Neural Network (SHGNN) to address the above limitations. In detail, we first utilize a feature propagation module to capture the local structure information of intermediate nodes in the meta-path. Next, we use a tree-attention aggregator to incorporate the graph structure information into the aggregation module on the meta-path. Finally, we leverage a meta-path aggregator to fuse the information aggregated from different meta-paths. We conducted experiments on node classification and clustering tasks and achieved state-of-the-art results on the benchmark datasets, which shows the effectiveness of our proposed method.
MGRR-Net: Multi-level Graph Relational Reasoning Network for Facial Action Units Detection
Apr 08, 2022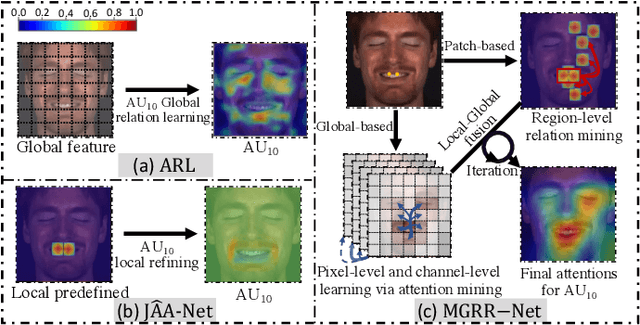
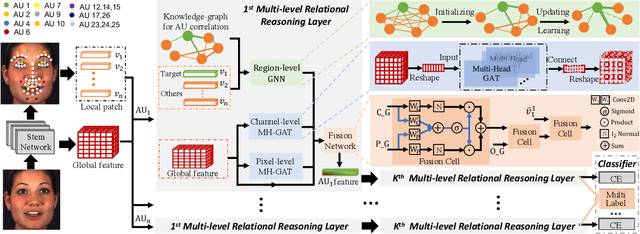
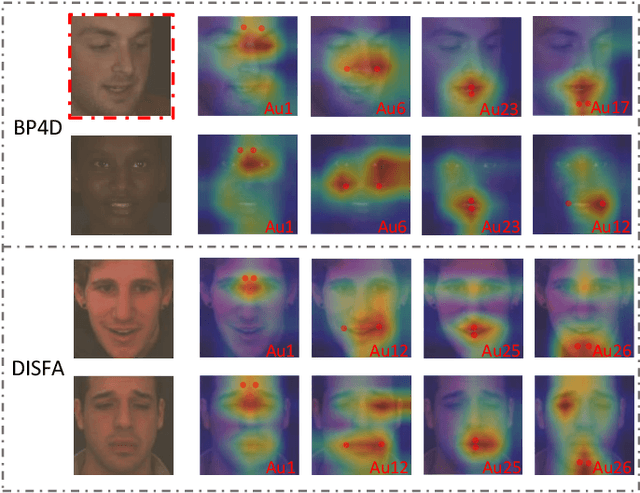
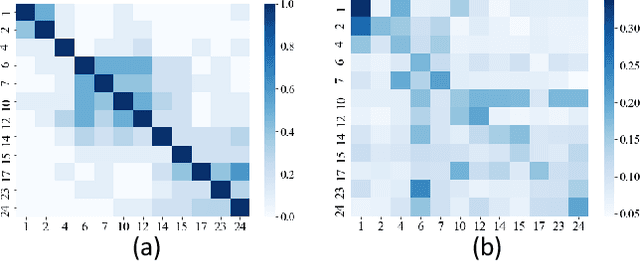
The Facial Action Coding System (FACS) encodes the action units (AUs) in facial images, which has attracted extensive research attention due to its wide use in facial expression analysis. Many methods that perform well on automatic facial action unit (AU) detection primarily focus on modeling various types of AU relations between corresponding local muscle areas, or simply mining global attention-aware facial features, however, neglect the dynamic interactions among local-global features. We argue that encoding AU features just from one perspective may not capture the rich contextual information between regional and global face features, as well as the detailed variability across AUs, because of the diversity in expression and individual characteristics. In this paper, we propose a novel Multi-level Graph Relational Reasoning Network (termed MGRR-Net) for facial AU detection. Each layer of MGRR-Net performs a multi-level (i.e., region-level, pixel-wise and channel-wise level) feature learning. While the region-level feature learning from local face patches features via graph neural network can encode the correlation across different AUs, the pixel-wise and channel-wise feature learning via graph attention network can enhance the discrimination ability of AU features from global face features. The fused features from the three levels lead to improved AU discriminative ability. Extensive experiments on DISFA and BP4D AU datasets show that the proposed approach achieves superior performance than the state-of-the-art methods.
On Distinctive Image Captioning via Comparing and Reweighting
Apr 08, 2022
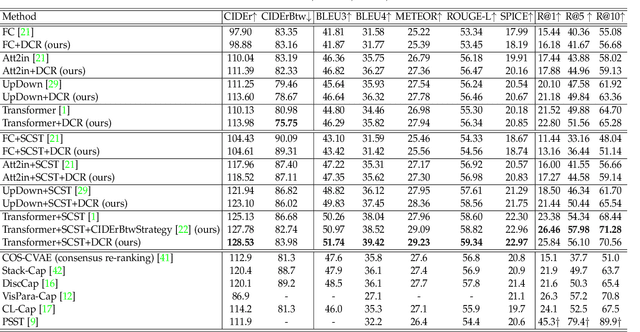
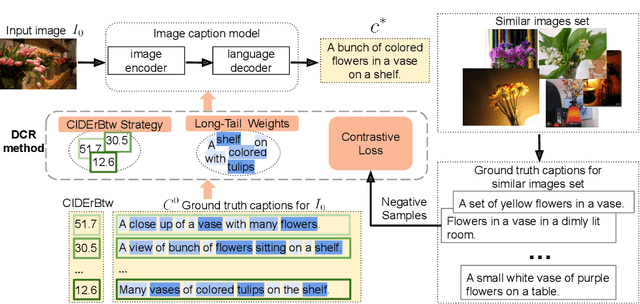
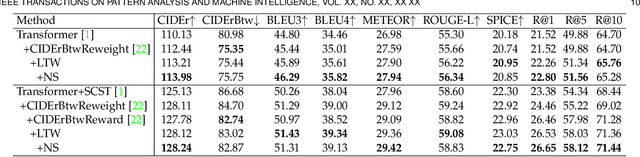
Recent image captioning models are achieving impressive results based on popular metrics, i.e., BLEU, CIDEr, and SPICE. However, focusing on the most popular metrics that only consider the overlap between the generated captions and human annotation could result in using common words and phrases, which lacks distinctiveness, i.e., many similar images have the same caption. In this paper, we aim to improve the distinctiveness of image captions via comparing and reweighting with a set of similar images. First, we propose a distinctiveness metric -- between-set CIDEr (CIDErBtw) to evaluate the distinctiveness of a caption with respect to those of similar images. Our metric reveals that the human annotations of each image in the MSCOCO dataset are not equivalent based on distinctiveness; however, previous works normally treat the human annotations equally during training, which could be a reason for generating less distinctive captions. In contrast, we reweight each ground-truth caption according to its distinctiveness during training. We further integrate a long-tailed weight strategy to highlight the rare words that contain more information, and captions from the similar image set are sampled as negative examples to encourage the generated sentence to be unique. Finally, extensive experiments are conducted, showing that our proposed approach significantly improves both distinctiveness (as measured by CIDErBtw and retrieval metrics) and accuracy (e.g., as measured by CIDEr) for a wide variety of image captioning baselines. These results are further confirmed through a user study.
* 20 pages. arXiv admin note: substantial text overlap with arXiv:2007.06877
A Discourse Aware Sequence Learning Approach for Emotion Recognition in Conversations
Apr 01, 2022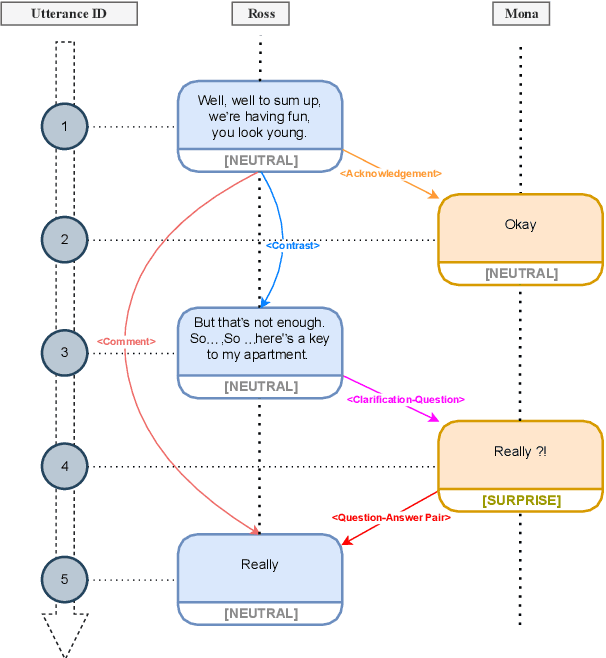
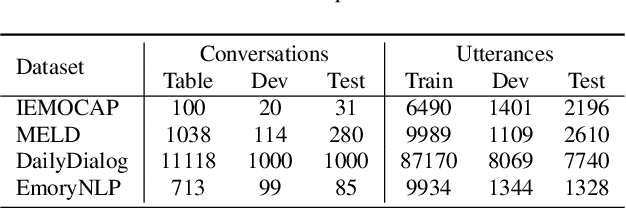
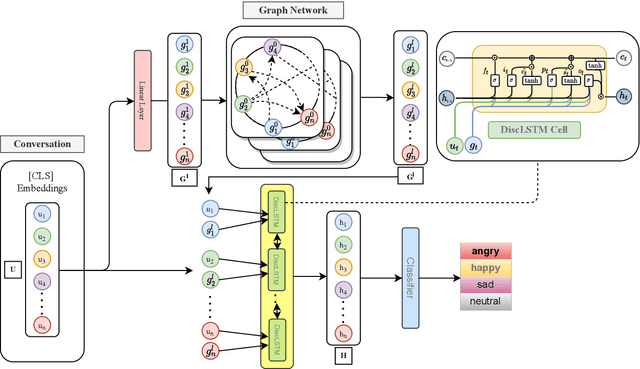
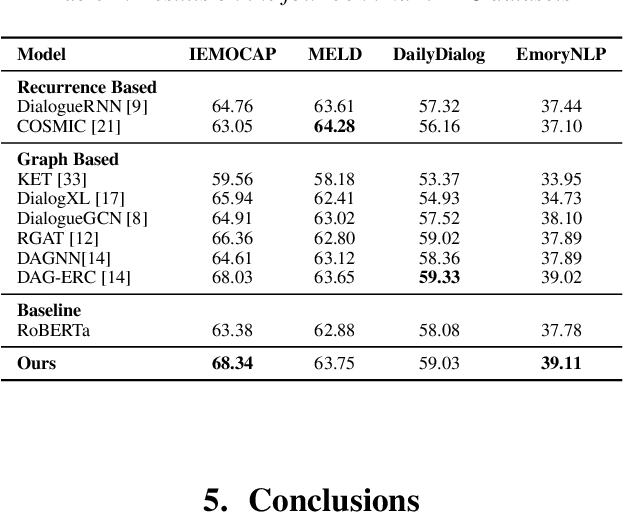
The expression of emotions is a crucial part of daily human communication. Modeling the conversational and sequential context has seen much success and plays a vital role in Emotion Recognition in Conversations (ERC). However, existing approaches either model only one of the two or employ naive late-fusion methodologies to obtain final utterance representations. This paper proposes a novel idea to incorporate both these contexts and better model the intrinsic structure within a conversation. More precisely, we propose a novel architecture boosted by a modified LSTM cell, which we call DiscLSTM, that better captures the interaction between conversational and sequential context. DiscLSTM brings together the best of both worlds and provides a more intuitive and efficient way to model the information flow between individual utterances by better capturing long-distance conversational background through discourse relations and sequential context through recurrence. We conduct experiments on four benchmark datasets for ERC and show that our model achieves performance competitive to state-of-the-art and at times performs better than other graph-based approaches in literature, with a conversational graph that is both sparse and avoids complicated edge relations like much of previous work. We make all our codes publicly available on GitHub.
Evaluating Deep Vs. Wide & Deep Learners As Contextual Bandits For Personalized Email Promo Recommendations
Jan 31, 2022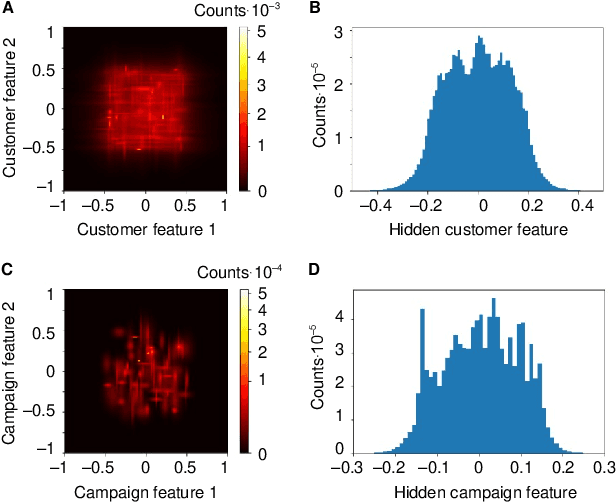

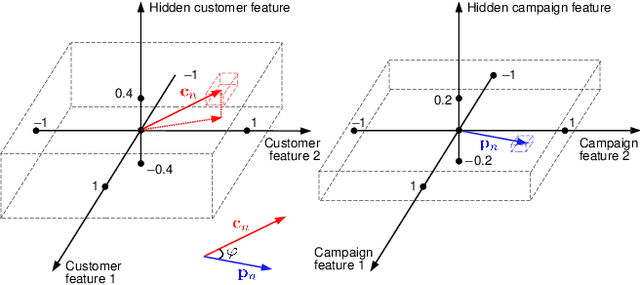

Personalization enables businesses to learn customer preferences from past interactions and thus to target individual customers with more relevant content. We consider the problem of predicting the optimal promotional offer for a given customer out of several options as a contextual bandit problem. Identifying information for the customer and/or the campaign can be used to deduce unknown customer/campaign features that improve optimal offer prediction. Using a generated synthetic email promo dataset, we demonstrate similar prediction accuracies for (a) a wide and deep network that takes identifying information (or other categorical features) as input to the wide part and (b) a deep-only neural network that includes embeddings of categorical features in the input. Improvements in accuracy from including categorical features depends on the variability of the unknown numerical features for each category. We also show that selecting options using upper confidence bound or Thompson sampling, approximated via Monte Carlo dropout layers in the wide and deep models, slightly improves model performance.
SegTransVAE: Hybrid CNN -- Transformer with Regularization for medical image segmentation
Jan 21, 2022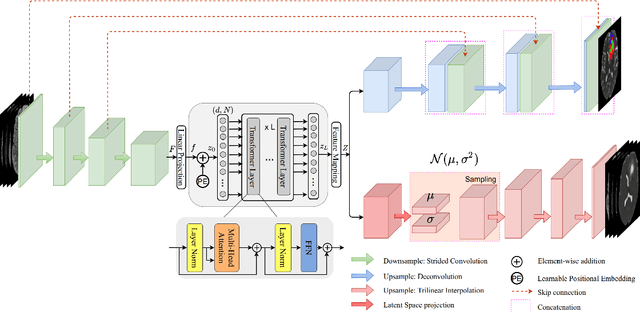
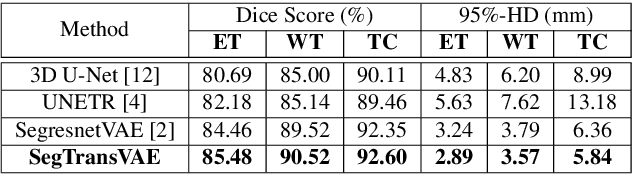
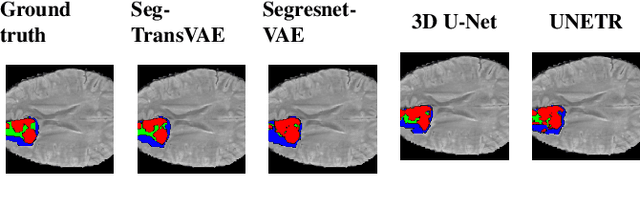
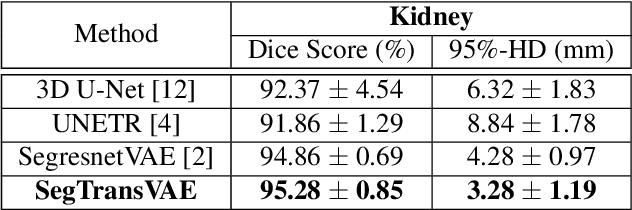
Current research on deep learning for medical image segmentation exposes their limitations in learning either global semantic information or local contextual information. To tackle these issues, a novel network named SegTransVAE is proposed in this paper. SegTransVAE is built upon encoder-decoder architecture, exploiting transformer with the variational autoencoder (VAE) branch to the network to reconstruct the input images jointly with segmentation. To the best of our knowledge, this is the first method combining the success of CNN, transformer, and VAE. Evaluation on various recently introduced datasets shows that SegTransVAE outperforms previous methods in Dice Score and $95\%$-Haudorff Distance while having comparable inference time to a simple CNN-based architecture network. The source code is available at: https://github.com/itruonghai/SegTransVAE.
Resurrecting Trust in Facial Recognition: Mitigating Backdoor Attacks in Face Recognition to Prevent Potential Privacy Breaches
Feb 18, 2022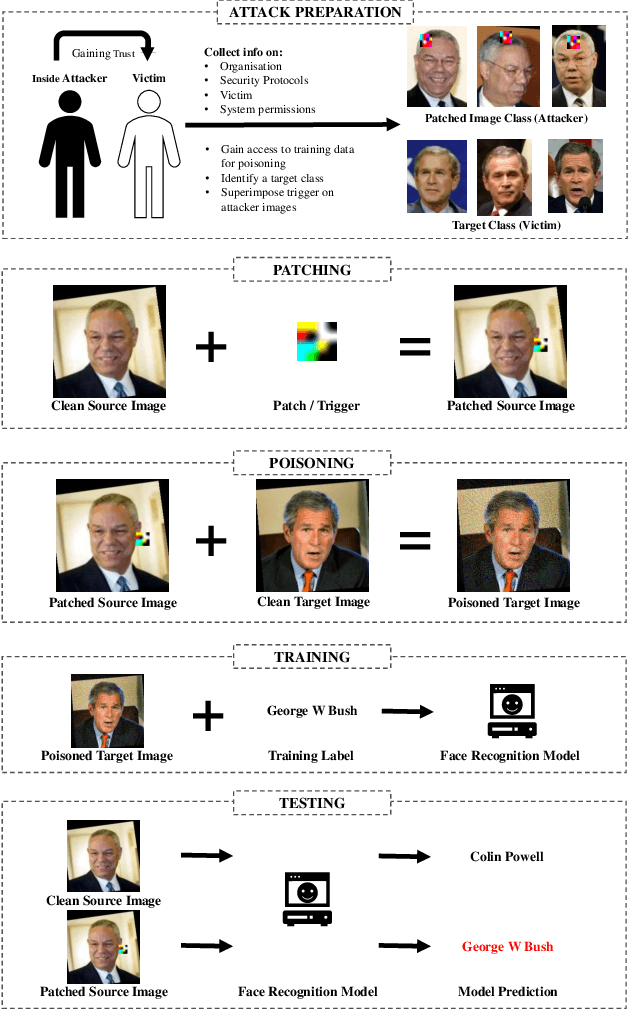
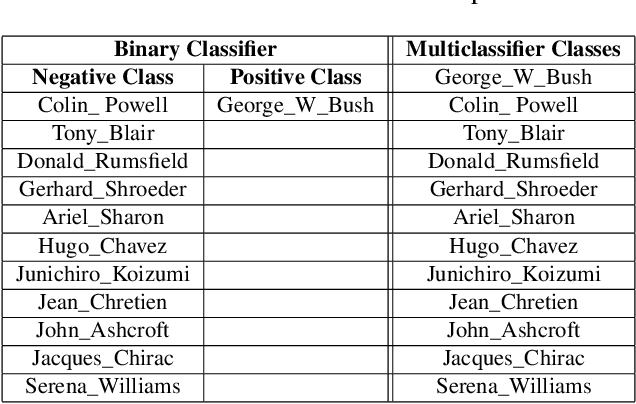
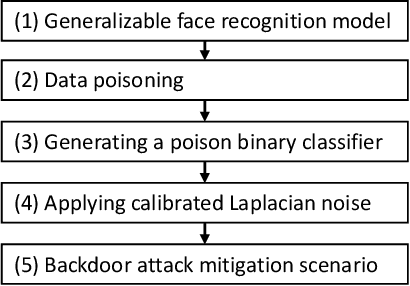
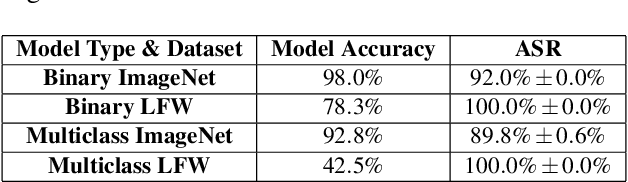
Biometric data, such as face images, are often associated with sensitive information (e.g medical, financial, personal government records). Hence, a data breach in a system storing such information can have devastating consequences. Deep learning is widely utilized for face recognition (FR); however, such models are vulnerable to backdoor attacks executed by malicious parties. Backdoor attacks cause a model to misclassify a particular class as a target class during recognition. This vulnerability can allow adversaries to gain access to highly sensitive data protected by biometric authentication measures or allow the malicious party to masquerade as an individual with higher system permissions. Such breaches pose a serious privacy threat. Previous methods integrate noise addition mechanisms into face recognition models to mitigate this issue and improve the robustness of classification against backdoor attacks. However, this can drastically affect model accuracy. We propose a novel and generalizable approach (named BA-BAM: Biometric Authentication - Backdoor Attack Mitigation), that aims to prevent backdoor attacks on face authentication deep learning models through transfer learning and selective image perturbation. The empirical evidence shows that BA-BAM is highly robust and incurs a maximal accuracy drop of 2.4%, while reducing the attack success rate to a maximum of 20%. Comparisons with existing approaches show that BA-BAM provides a more practical backdoor mitigation approach for face recognition.