 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Human Gait Analysis using Gait Energy Image
Mar 17, 2022

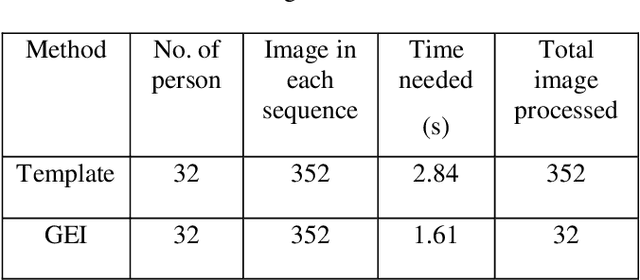

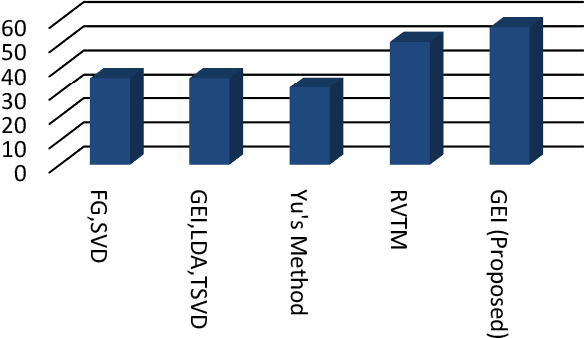
Gait recognition is one of the most recent emerging techniques of human biometric which can be used for security based purposes having unobtrusive learning method. In comparison with other bio-metrics gait analysis has some special security features. Most of the biometric technique uses sequential template based component analysis for recognition. Comparing with those methods, we proposed a developed technique for gait identification using the feature Gait Energy Image (GEI). GEI representation of gait contains all information of each image in one gait cycle and requires less storage and low processing speed. As only one image is enough to store the necessary information in GEI feature recognition process is very easier than any other feature for gait recognition. Gait recognition has some limitations in recognition process like viewing angle variation, walking speed, clothes, carrying load etc. Our proposed method in the paper compares the recognition performance with template based feature extraction which needs to process each frame in the cycle. We use GEI which gives relatively all information about all the frames in the cycle and results in better performance than other feature of gait analysis.
Exploring Diversity-based Active Learning for 3D Object Detection in Autonomous Driving
May 16, 2022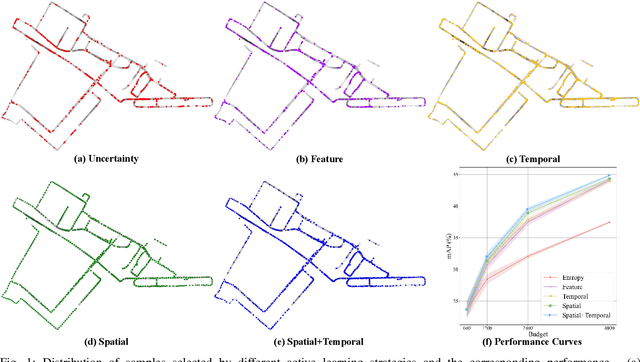
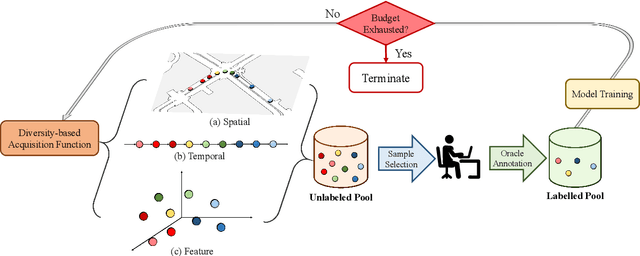
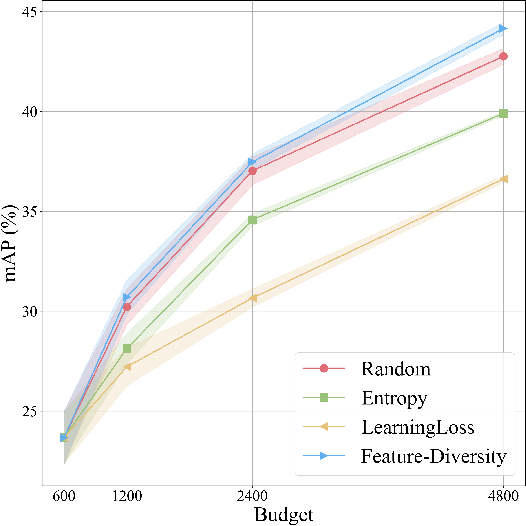
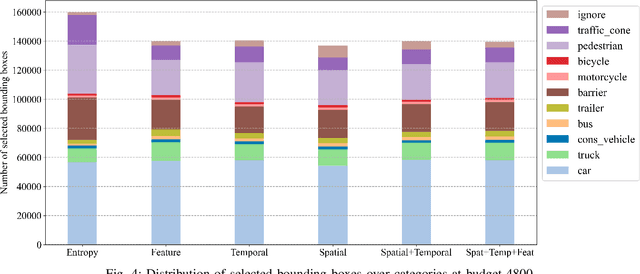
3D object detection has recently received much attention due to its great potential in autonomous vehicle (AV). The success of deep learning based object detectors relies on the availability of large-scale annotated datasets, which is time-consuming and expensive to compile, especially for 3D bounding box annotation. In this work, we investigate diversity-based active learning (AL) as a potential solution to alleviate the annotation burden. Given limited annotation budget, only the most informative frames and objects are automatically selected for human to annotate. Technically, we take the advantage of the multimodal information provided in an AV dataset, and propose a novel acquisition function that enforces spatial and temporal diversity in the selected samples. We benchmark the proposed method against other AL strategies under realistic annotation cost measurement, where the realistic costs for annotating a frame and a 3D bounding box are both taken into consideration. We demonstrate the effectiveness of the proposed method on the nuScenes dataset and show that it outperforms existing AL strategies significantly.
CEU-Net: Ensemble Semantic Segmentation of Hyperspectral Images Using Clustering
Mar 14, 2022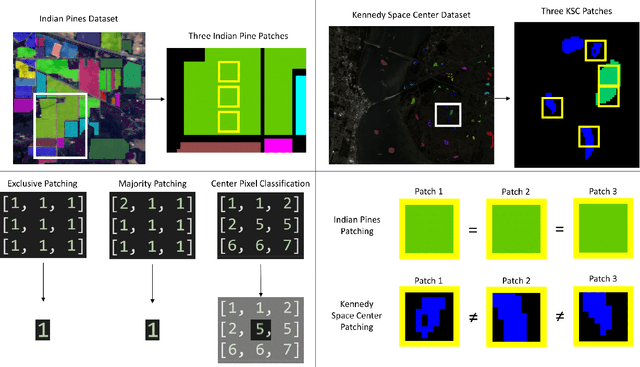

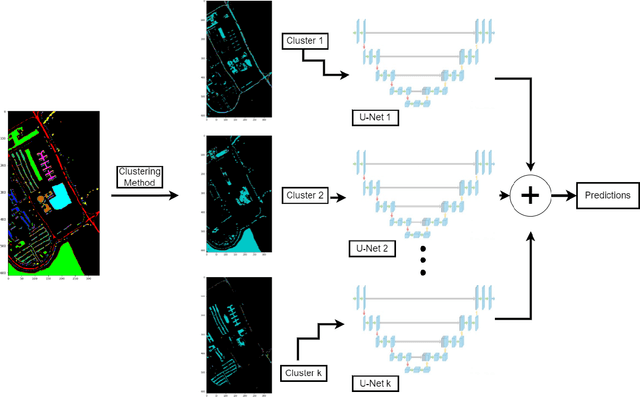

Most semantic segmentation approaches of Hyperspectral images (HSIs) use and require preprocessing steps in the form of patching to accurately classify diversified land cover in remotely sensed images. These approaches use patching to incorporate the rich neighborhood information in images and exploit the simplicity and segmentability of the most common HSI datasets. In contrast, most landmasses in the world consist of overlapping and diffused classes, making neighborhood information weaker than what is seen in common HSI datasets. To combat this issue and generalize the segmentation models to more complex and diverse HSI datasets, in this work, we propose our novel flagship model: Clustering Ensemble U-Net (CEU-Net). CEU-Net uses the ensemble method to combine spectral information extracted from convolutional neural network (CNN) training on a cluster of landscape pixels. Our CEU-Net model outperforms existing state-of-the-art HSI semantic segmentation methods and gets competitive performance with and without patching when compared to baseline models. We highlight CEU-Net's high performance across Botswana, KSC, and Salinas datasets compared to HybridSN and AeroRIT methods.
Fast and Scalable Human Pose Estimation using mmWave Point Cloud
Apr 29, 2022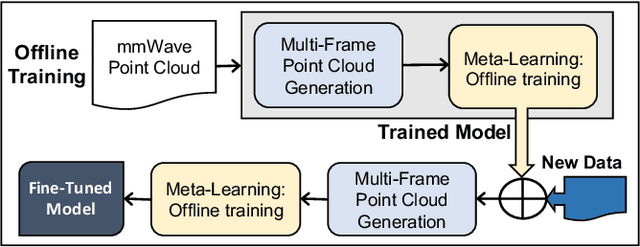
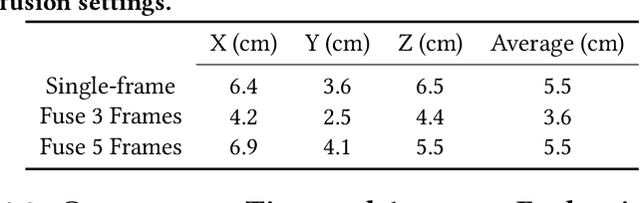
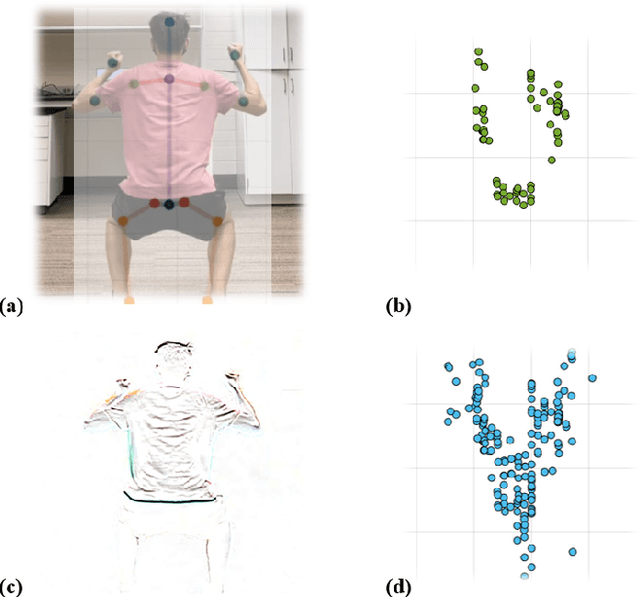
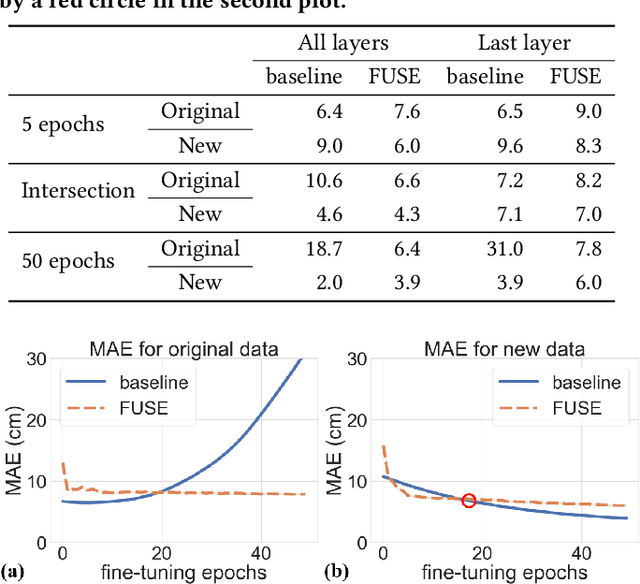
Millimeter-Wave (mmWave) radar can enable high-resolution human pose estimation with low cost and computational requirements. However, mmWave data point cloud, the primary input to processing algorithms, is highly sparse and carries significantly less information than other alternatives such as video frames. Furthermore, the scarce labeled mmWave data impedes the development of machine learning (ML) models that can generalize to unseen scenarios. We propose a fast and scalable human pose estimation (FUSE) framework that combines multi-frame representation and meta-learning to address these challenges. Experimental evaluations show that FUSE adapts to the unseen scenarios 4$\times$ faster than current supervised learning approaches and estimates human joint coordinates with about 7 cm mean absolute error.
Hyperdimensional computing encoding for feature selection on the use case of epileptic seizure detection
May 16, 2022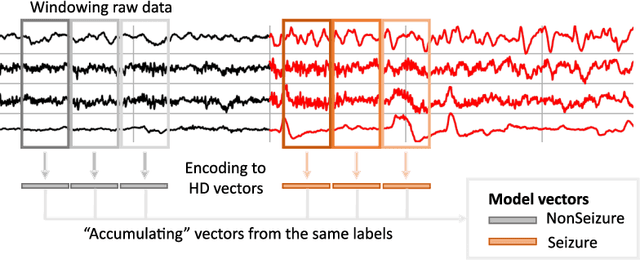
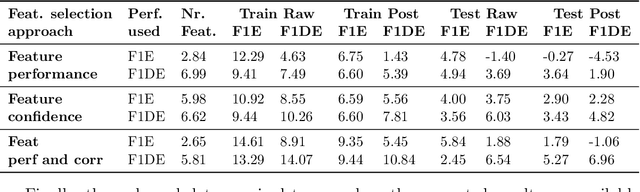
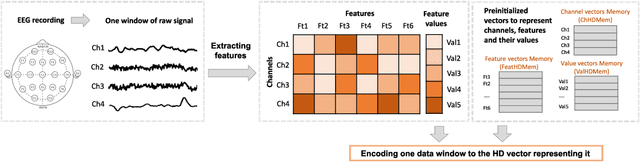
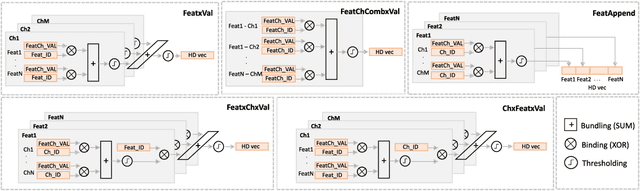
The healthcare landscape is moving from the reactive interventions focused on symptoms treatment to a more proactive prevention, from one-size-fits-all to personalized medicine, and from centralized to distributed paradigms. Wearable IoT devices and novel algorithms for continuous monitoring are essential components of this transition. Hyperdimensional (HD) computing is an emerging ML paradigm inspired by neuroscience research with various aspects interesting for IoT devices and biomedical applications. Here we explore the not yet addressed topic of optimal encoding of spatio-temporal data, such as electroencephalogram (EEG) signals, and all information it entails to the HD vectors. Further, we demonstrate how the HD computing framework can be used to perform feature selection by choosing an adequate encoding. To the best of our knowledge, this is the first approach to performing feature selection using HD computing in the literature. As a result, we believe it can support the ML community to further foster the research in multiple directions related to feature and channel selection, as well as model interpretability.
A Meeting Transcription System for an Ad-Hoc Acoustic Sensor Network
May 02, 2022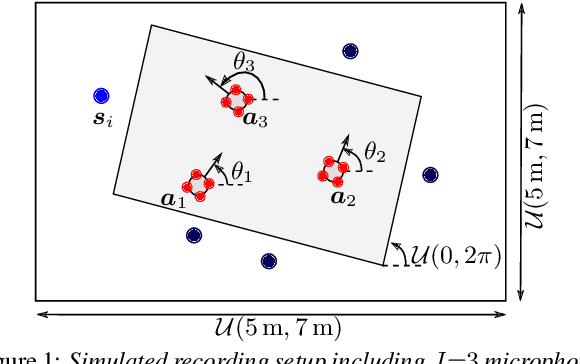
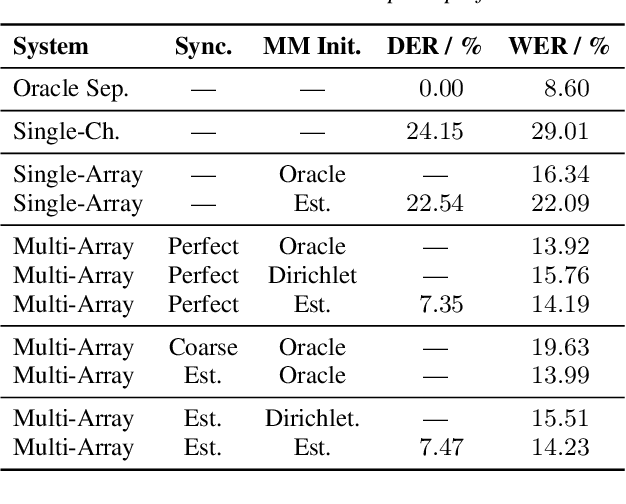
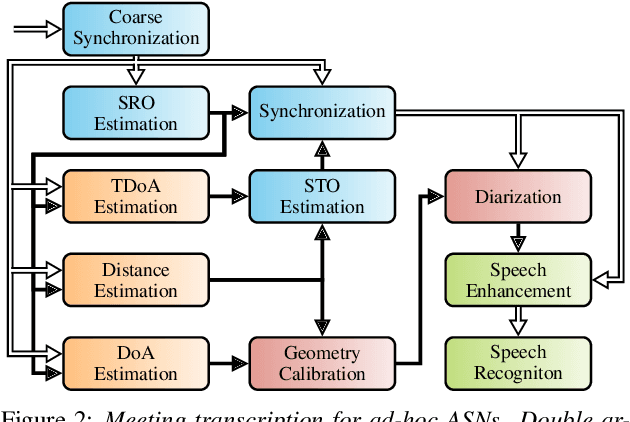
We propose a system that transcribes the conversation of a typical meeting scenario that is captured by a set of initially unsynchronized microphone arrays at unknown positions. It consists of subsystems for signal synchronization, including both sampling rate and sampling time offset estimation, diarization based on speaker and microphone array position estimation, multi-channel speech enhancement, and automatic speech recognition. With the estimated diarization information, a spatial mixture model is initialized that is used to estimate beamformer coefficients for source separation. Simulations show that the speech recognition accuracy can be improved by synchronizing and combining multiple distributed microphone arrays compared to a single compact microphone array. Furthermore, the proposed informed initialization of the spatial mixture model delivers a clear performance advantage over random initialization.
DSGN++: Exploiting Visual-Spatial Relation for Stereo-based 3D Detectors
Apr 09, 2022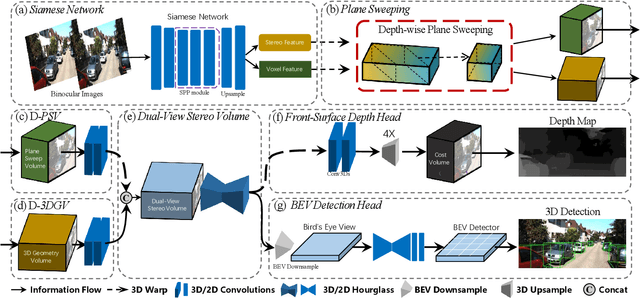
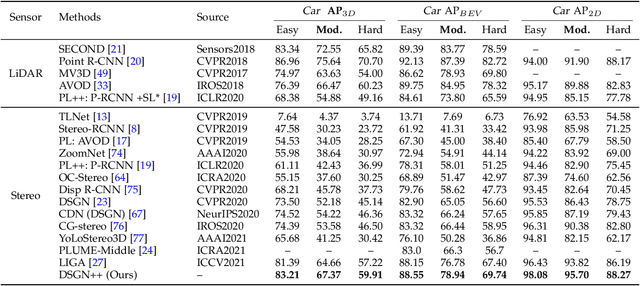
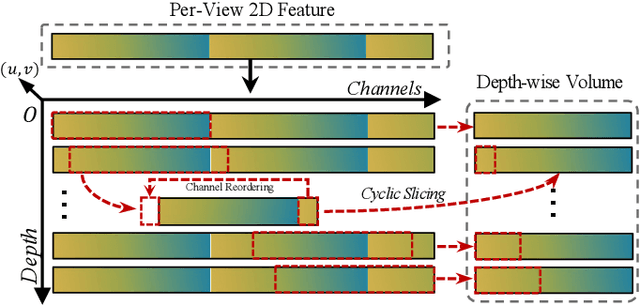
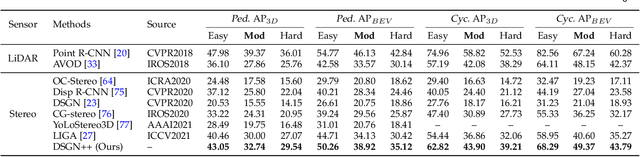
Camera-based 3D object detectors are welcome due to their wider deployment and lower price than LiDAR sensors. We revisit the prior stereo modeling DSGN about the stereo volume constructions for representing both 3D geometry and semantics. We polish the stereo modeling and propose our approach, DSGN++, aiming for improving information flow throughout the 2D-to-3D pipeline in the following three main aspects. First, to effectively lift the 2D information to stereo volume, we propose depth-wise plane sweeping (DPS) that allows denser connections and extracts depth-guided features. Second, for better grasping differently spaced features, we present a novel stereo volume -- Dual-view Stereo Volume (DSV) that integrates front-view and top-view features and reconstructs sub-voxel depth in the camera frustum. Third, as the foreground region becomes less dominant in 3D space, we firstly propose a multi-modal data editing strategy -- Stereo-LiDAR Copy-Paste, which ensures cross-modal alignment and improves data efficiency. Without bells and whistles, extensive experiments in various modality setups on the popular KITTI benchmark show that our method consistently outperforms other camera-based 3D detectors for all categories. Code will be released at https://github.com/chenyilun95/DSGN2.
ROMA: Cross-Domain Region Similarity Matching for Unpaired Nighttime Infrared to Daytime Visible Video Translation
Apr 26, 2022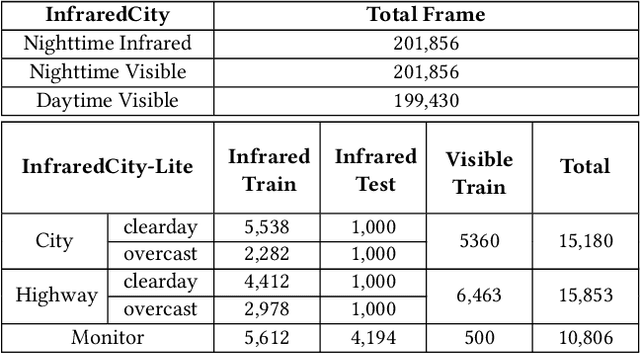
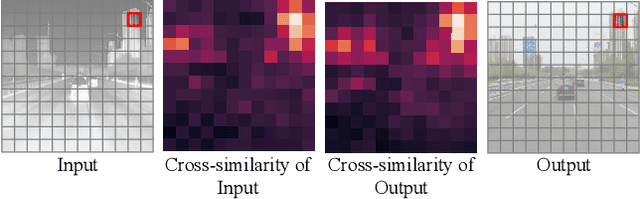
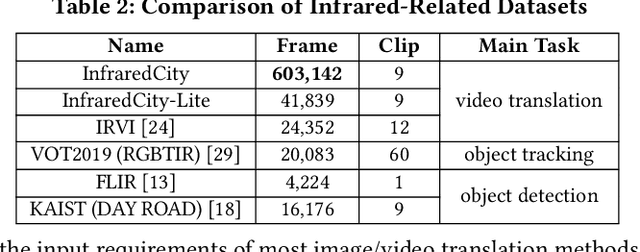
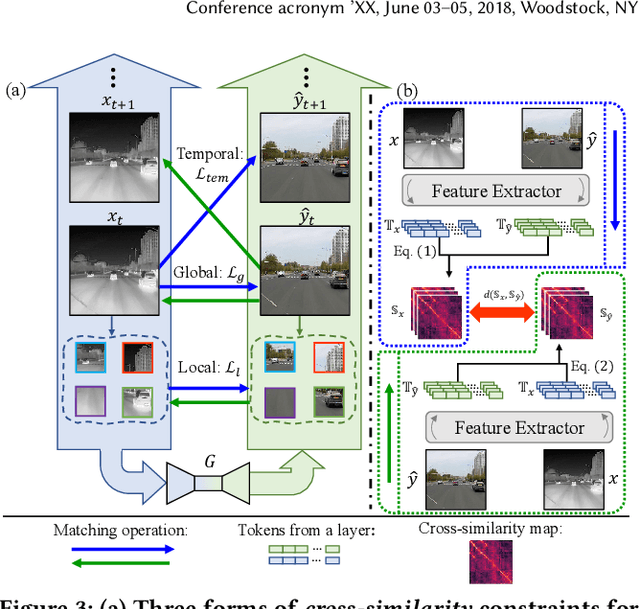
Infrared cameras are often utilized to enhance the night vision since the visible light cameras exhibit inferior efficacy without sufficient illumination. However, infrared data possesses inadequate color contrast and representation ability attributed to its intrinsic heat-related imaging principle. This makes it arduous to capture and analyze information for human beings, meanwhile hindering its application. Although, the domain gaps between unpaired nighttime infrared and daytime visible videos are even huger than paired ones that captured at the same time, establishing an effective translation mapping will greatly contribute to various fields. In this case, the structural knowledge within nighttime infrared videos and semantic information contained in the translated daytime visible pairs could be utilized simultaneously. To this end, we propose a tailored framework ROMA that couples with our introduced cRoss-domain regiOn siMilarity mAtching technique for bridging the huge gaps. To be specific, ROMA could efficiently translate the unpaired nighttime infrared videos into fine-grained daytime visible ones, meanwhile maintain the spatiotemporal consistency via matching the cross-domain region similarity. Furthermore, we design a multiscale region-wise discriminator to distinguish the details from synthesized visible results and real references. Extensive experiments and evaluations for specific applications indicate ROMA outperforms the state-of-the-art methods. Moreover, we provide a new and challenging dataset encouraging further research for unpaired nighttime infrared and daytime visible video translation, named InfraredCity. In particular, it consists of 9 long video clips including City, Highway and Monitor scenarios. All clips could be split into 603,142 frames in total, which are 20 times larger than the recently released daytime infrared-to-visible dataset IRVI.
E-Mail Assistant -- Automation of E-Mail Handling and Management using Robotic Process Automation
May 12, 2022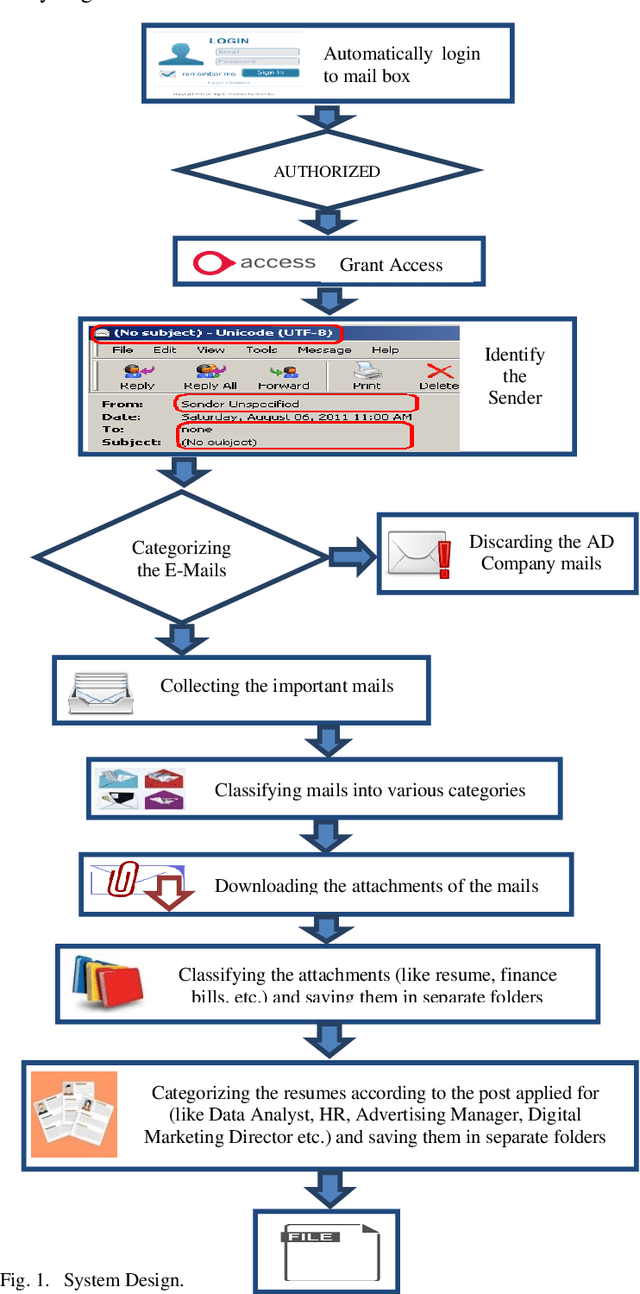
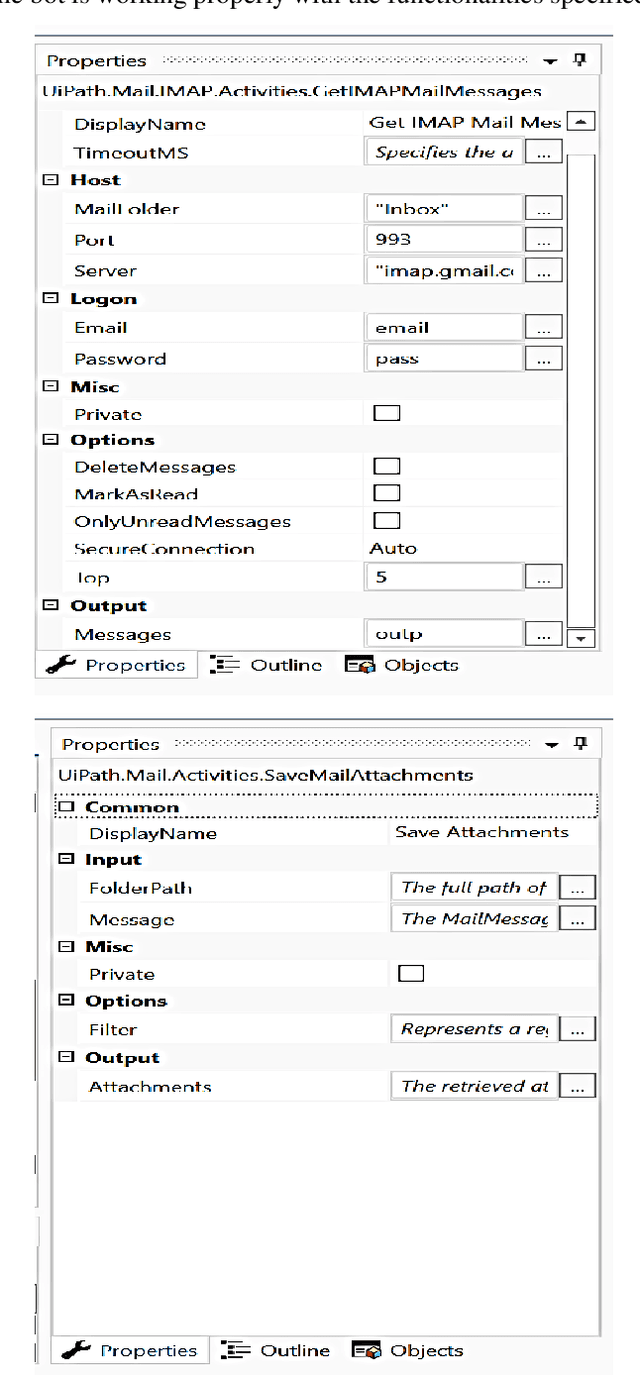
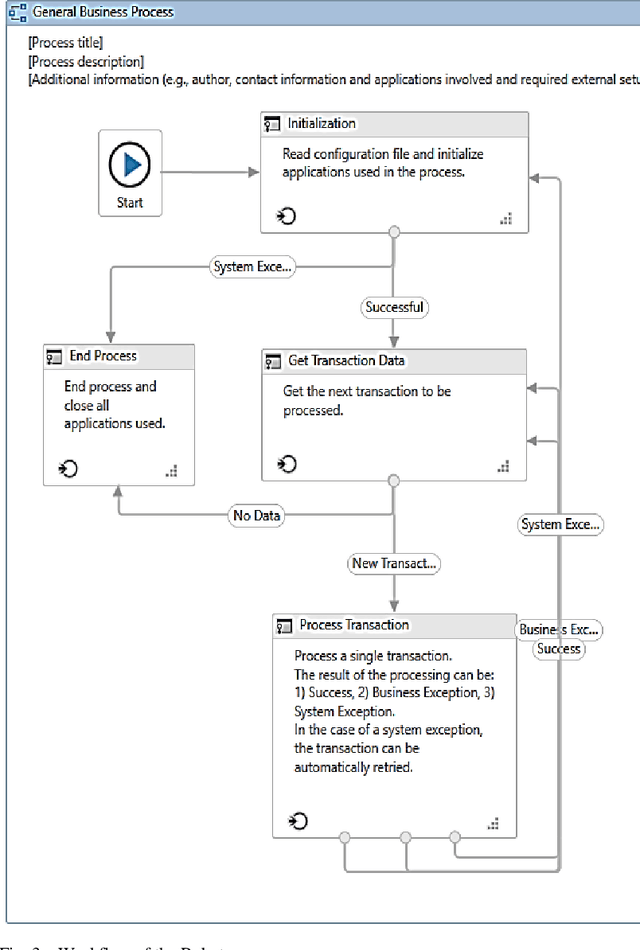

In this paper, a workflow for designing a bot using Robotic Process Automation (RPA), associated with Artificial Intelligence (AI) that is used for information extraction, classification, etc., is proposed. The bot is equipped with many features that make email handling a stress-free job. It automatically login into the mailbox through secured channels, distinguishes between the useful and not useful emails, classifies the emails into different labels, downloads the attached files, creates different directories, and stores the downloaded files into relevant directories. It moves the not useful emails into the trash. Further, the bot can also be trained to rename the attached files with the names of the sender/applicant in case of a job application for the sake of convenience. The bot is designed and tested using the UiPath tool to improve the performance of the system. The paper also discusses the further possible functionalities that can be added on to the bot.
Mutual Information in Community Detection with Covariate Information and Correlated Networks
Dec 11, 2019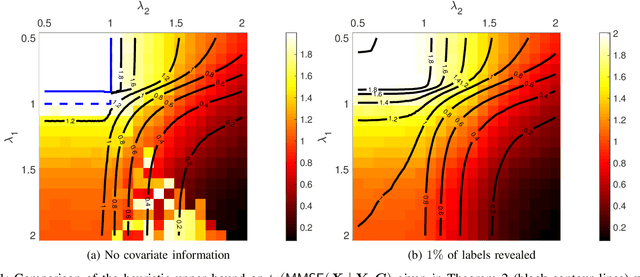
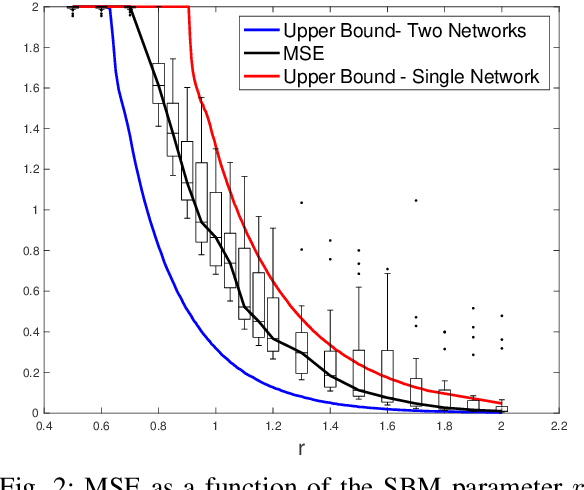
We study the problem of community detection when there is covariate information about the node labels and one observes multiple correlated networks. We provide an asymptotic upper bound on the per-node mutual information as well as a heuristic analysis of a multivariate performance measure called the MMSE matrix. These results show that the combined effects of seemingly very different types of information can be characterized explicitly in terms of formulas involving low-dimensional estimation problems in additive Gaussian noise. Our analysis is supported by numerical simulations.