 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Image-Text Matching with Multi-View Attention
Feb 27, 2024
Existing two-stream models for image-text matching show good performance while ensuring retrieval speed and have received extensive attention from industry and academia. These methods use a single representation to encode image and text separately and get a matching score with cosine similarity or the inner product of vectors. However, the performance of the two-stream model is often sub-optimal. On the one hand, a single representation is challenging to cover complex content comprehensively. On the other hand, in this framework of lack of interaction, it is challenging to match multiple meanings which leads to information being ignored. To address the problems mentioned above and facilitate the performance of the two-stream model, we propose a multi-view attention approach for two-stream image-text matching MVAM (\textbf{M}ulti-\textbf{V}iew \textbf{A}ttention \textbf{M}odel). It first learns multiple image and text representations by diverse attention heads with different view codes. And then concatenate these representations into one for matching. A diversity objective is also used to promote diversity between attention heads. With this method, models are able to encode images and text from different views and attend to more key points. So we can get representations that contain more information. When doing retrieval tasks, the matching scores between images and texts can be calculated from different aspects, leading to better matching performance. Experiment results on MSCOCO and Flickr30K show that our proposed model brings improvements over existing models. Further case studies show that different attention heads can focus on different contents and finally obtain a more comprehensive representation.
MCF-VC: Mitigate Catastrophic Forgetting in Class-Incremental Learning for Multimodal Video Captioning
Feb 27, 2024To address the problem of catastrophic forgetting due to the invisibility of old categories in sequential input, existing work based on relatively simple categorization tasks has made some progress. In contrast, video captioning is a more complex task in multimodal scenario, which has not been explored in the field of incremental learning. After identifying this stability-plasticity problem when analyzing video with sequential input, we originally propose a method to Mitigate Catastrophic Forgetting in class-incremental learning for multimodal Video Captioning (MCF-VC). As for effectively maintaining good performance on old tasks at the macro level, we design Fine-grained Sensitivity Selection (FgSS) based on the Mask of Linear's Parameters and Fisher Sensitivity to pick useful knowledge from old tasks. Further, in order to better constrain the knowledge characteristics of old and new tasks at the specific feature level, we have created the Two-stage Knowledge Distillation (TsKD), which is able to learn the new task well while weighing the old task. Specifically, we design two distillation losses, which constrain the cross modal semantic information of semantic attention feature map and the textual information of the final outputs respectively, so that the inter-model and intra-model stylized knowledge of the old class is retained while learning the new class. In order to illustrate the ability of our model to resist forgetting, we designed a metric CIDER_t to detect the stage forgetting rate. Our experiments on the public dataset MSR-VTT show that the proposed method significantly resists the forgetting of previous tasks without replaying old samples, and performs well on the new task.
Learning Causal Features for Incremental Object Detection
Mar 01, 2024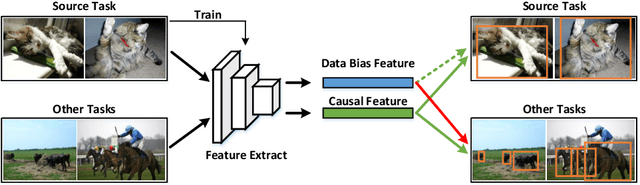
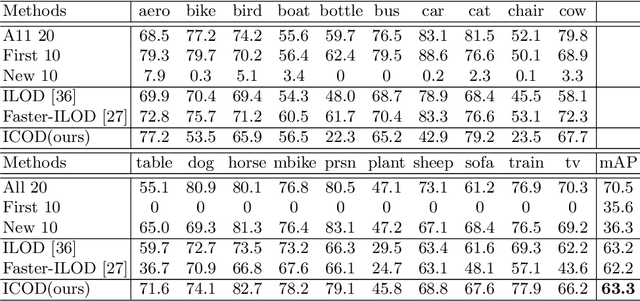
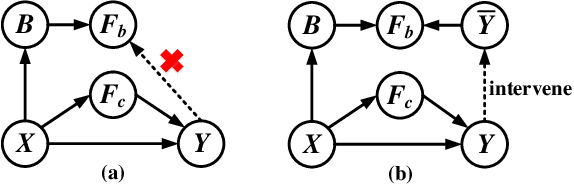
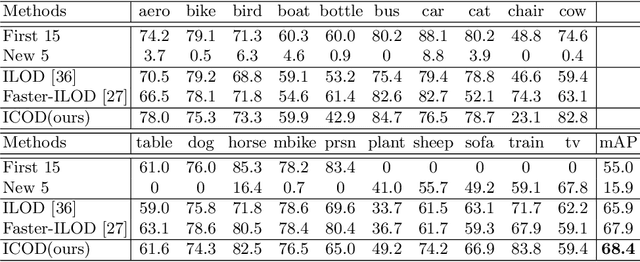
Object detection limits its recognizable categories during the training phase, in which it can not cover all objects of interest for users. To satisfy the practical necessity, the incremental learning ability of the detector becomes a critical factor for real-world applications. Unfortunately, neural networks unavoidably meet catastrophic forgetting problem when it is implemented on a new task. To this end, many incremental object detection models preserve the knowledge of previous tasks by replaying samples or distillation from previous models. However, they ignore an important factor that the performance of the model mostly depends on its feature. These models try to rouse the memory of the neural network with previous samples but not to prevent forgetting. To this end, in this paper, we propose an incremental causal object detection (ICOD) model by learning causal features, which can adapt to more tasks. Traditional object detection models, unavoidably depend on the data-bias or data-specific features to get the detection results, which can not adapt to the new task. When the model meets the requirements of incremental learning, the data-bias information is not beneficial to the new task, and the incremental learning may eliminate these features and lead to forgetting. To this end, our ICOD is introduced to learn the causal features, rather than the data-bias features when training the detector. Thus, when the model is implemented to a new task, the causal features of the old task can aid the incremental learning process to alleviate the catastrophic forgetting problem. We conduct our model on several experiments, which shows a causal feature without data-bias can make the model adapt to new tasks better. \keywords{Object detection, incremental learning, causal feature.
Complex-Valued Neural Network based Federated Learning for Multi-user Indoor Positioning Performance Optimization
Mar 01, 2024
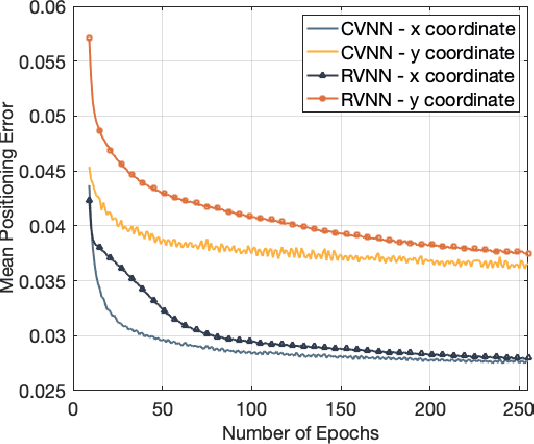
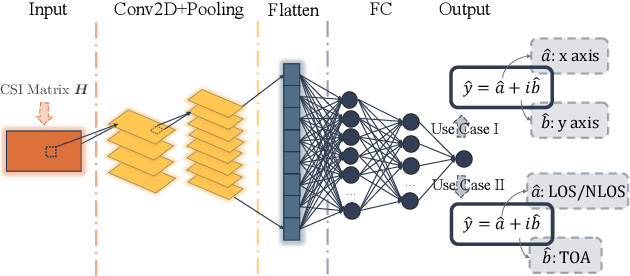
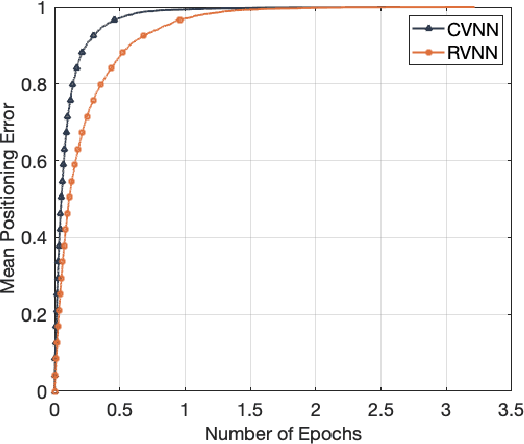
In this article, the use of channel state information (CSI) for indoor positioning is studied. In the considered model, a server equipped with several antennas sends pilot signals to users, while each user uses the received pilot signals to estimate channel states for user positioning. To this end, we formulate the positioning problem as an optimization problem aiming to minimize the gap between the estimated positions and the ground truth positions of users. To solve this problem, we design a complex-valued neural network (CVNN) model based federated learning (FL) algorithm. Compared to standard real-valued centralized machine learning (ML) methods, our proposed algorithm has two main advantages. First, our proposed algorithm can directly process complex-valued CSI data without data transformation. Second, our proposed algorithm is a distributed ML method that does not require users to send their CSI data to the server. Since the output of our proposed algorithm is complex-valued which consists of the real and imaginary parts, we study the use of the CVNN to implement two learning tasks. First, the proposed algorithm directly outputs the estimated positions of a user. Here, the real and imaginary parts of an output neuron represent the 2D coordinates of the user. Second, the proposed method can output two CSI features (i.e., line-of-sight/non-line-of-sight transmission link classification and time of arrival (TOA) prediction) which can be used in traditional positioning algorithms. Simulation results demonstrate that our designed CVNN based FL can reduce the mean positioning error between the estimated position and the actual position by up to 36\%, compared to a RVNN based FL which requires to transform CSI data into real-valued data.
Against Filter Bubbles: Diversified Music Recommendation via Weighted Hypergraph Embedding Learning
Feb 26, 2024Recommender systems serve a dual purpose for users: sifting out inappropriate or mismatched information while accurately identifying items that align with their preferences. Numerous recommendation algorithms are designed to provide users with a personalized array of information tailored to their preferences. Nevertheless, excessive personalization can confine users within a "filter bubble". Consequently, achieving the right balance between accuracy and diversity in recommendations is a pressing concern. To address this challenge, exemplified by music recommendation, we introduce the Diversified Weighted Hypergraph music Recommendation algorithm (DWHRec). In the DWHRec algorithm, the initial connections between users and listened tracks are represented by a weighted hypergraph. Simultaneously, associations between artists, albums and tags with tracks are also appended to the hypergraph. To explore users' latent preferences, a hypergraph-based random walk embedding method is applied to the constructed hypergraph. In our investigation, accuracy is gauged by the alignment between the user and the track, whereas the array of recommended track types measures diversity. We rigorously compared DWHRec against seven state-of-the-art recommendation algorithms using two real-world music datasets. The experimental results validate DWHRec as a solution that adeptly harmonizes accuracy and diversity, delivering a more enriched musical experience. Beyond music recommendation, DWHRec can be extended to cater to other scenarios with similar data structures.
Robot Body Schema Learning from Full-body Extero/Proprioception Sensors
Feb 28, 2024For a robot, its body structure is an a-prior knowledge when it is designed. However, when such information is not available, can a robot recognize it by itself? In this paper, we aim to grant a robot such ability to learn its body structure from exteroception and proprioception data collected from on-body sensors. By a novel machine learning method, the robot can learn a binary Heterogeneous Dependency Matrix from its sensor readings. We showed such matrix is equivalent to a Heterogeneous out-tree structure which can uniquely represent the robot body topology. We explored the properties of such matrix and the out-tree, and proposed a remedy to fix them when they are contaminated by partial observability or data noise. We ran our algorithm on 6 different robots with different body structures in simulation and 1 real robot. Our algorithm correctly recognized their body structures with only on-body sensor readings but no topology prior knowledge.
Knowledge-Infused LLM-Powered Conversational Health Agent: A Case Study for Diabetes Patients
Feb 28, 2024Effective diabetes management is crucial for maintaining health in diabetic patients. Large Language Models (LLMs) have opened new avenues for diabetes management, facilitating their efficacy. However, current LLM-based approaches are limited by their dependence on general sources and lack of integration with domain-specific knowledge, leading to inaccurate responses. In this paper, we propose a knowledge-infused LLM-powered conversational health agent (CHA) for diabetic patients. We customize and leverage the open-source openCHA framework, enhancing our CHA with external knowledge and analytical capabilities. This integration involves two key components: 1) incorporating the American Diabetes Association dietary guidelines and the Nutritionix information and 2) deploying analytical tools that enable nutritional intake calculation and comparison with the guidelines. We compare the proposed CHA with GPT4. Our evaluation includes 100 diabetes-related questions on daily meal choices and assessing the potential risks associated with the suggested diet. Our findings show that the proposed agent demonstrates superior performance in generating responses to manage essential nutrients.
VerifiNER: Verification-augmented NER via Knowledge-grounded Reasoning with Large Language Models
Feb 28, 2024Recent approaches in domain-specific named entity recognition (NER), such as biomedical NER, have shown remarkable advances. However, they still lack of faithfulness, producing erroneous predictions. We assume that knowledge of entities can be useful in verifying the correctness of the predictions. Despite the usefulness of knowledge, resolving such errors with knowledge is nontrivial, since the knowledge itself does not directly indicate the ground-truth label. To this end, we propose VerifiNER, a post-hoc verification framework that identifies errors from existing NER methods using knowledge and revises them into more faithful predictions. Our framework leverages the reasoning abilities of large language models to adequately ground on knowledge and the contextual information in the verification process. We validate effectiveness of VerifiNER through extensive experiments on biomedical datasets. The results suggest that VerifiNER can successfully verify errors from existing models as a model-agnostic approach. Further analyses on out-of-domain and low-resource settings show the usefulness of VerifiNER on real-world applications.
HOP to the Next Tasks and Domains for Continual Learning in NLP
Feb 28, 2024Continual Learning (CL) aims to learn a sequence of problems (i.e., tasks and domains) by transferring knowledge acquired on previous problems, whilst avoiding forgetting of past ones. Different from previous approaches which focused on CL for one NLP task or domain in a specific use-case, in this paper, we address a more general CL setting to learn from a sequence of problems in a unique framework. Our method, HOP, permits to hop across tasks and domains by addressing the CL problem along three directions: (i) we employ a set of adapters to generalize a large pre-trained model to unseen problems, (ii) we compute high-order moments over the distribution of embedded representations to distinguish independent and correlated statistics across different tasks and domains, (iii) we process this enriched information with auxiliary heads specialized for each end problem. Extensive experimental campaign on 4 NLP applications, 5 benchmarks and 2 CL setups demonstrates the effectiveness of our HOP.
Reflection Removal Using Recurrent Polarization-to-Polarization Network
Feb 28, 2024This paper addresses reflection removal, which is the task of separating reflection components from a captured image and deriving the image with only transmission components. Considering that the existence of the reflection changes the polarization state of a scene, some existing methods have exploited polarized images for reflection removal. While these methods apply polarized images as the inputs, they predict the reflection and the transmission directly as non-polarized intensity images. In contrast, we propose a polarization-to-polarization approach that applies polarized images as the inputs and predicts "polarized" reflection and transmission images using two sequential networks to facilitate the separation task by utilizing the interrelated polarization information between the reflection and the transmission. We further adopt a recurrent framework, where the predicted reflection and transmission images are used to iteratively refine each other. Experimental results on a public dataset demonstrate that our method outperforms other state-of-the-art methods.