 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Point is a Vector: A Feature Representation in Point Analysis
May 21, 2022
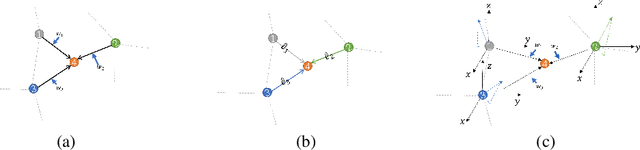
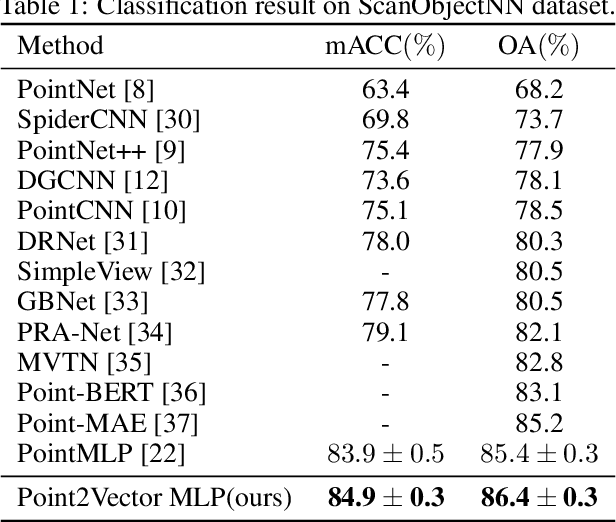
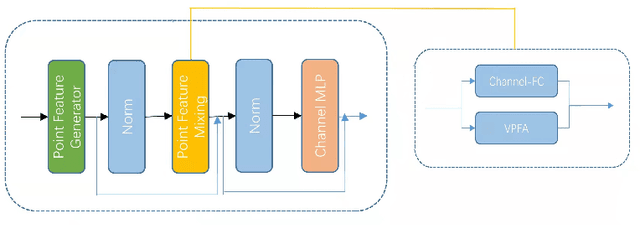

The irregularity and disorder of point clouds bring many challenges to point cloud analysis. PointMLP suggests that geometric information is not the only critical point in point cloud analysis. It achieves promising result based on a simple multi-layer perception (MLP) structure with geometric affine module. However, these MLP-like structures aggregate features only with fixed weights, while differences in the semantic information of different point features are ignored. So we propose a novel Point-Vector Representation of the point feature to improve feature aggregation by using inductive bias. The direction of the introduced vector representation can dynamically modulate the aggregation of two point features according to the semantic relationship. Based on it, we design a novel Point2Vector MLP architecture. Experiments show that it achieves state-of-the-art performance on the classification task of ScanObjectNN dataset, with 1% increase, compared with the previous best method. We hope our method can help people better understand the role of semantic information in point cloud analysis and lead to explore more and better feature representations or other ways.
Novel Class Discovery without Forgetting
Jul 21, 2022

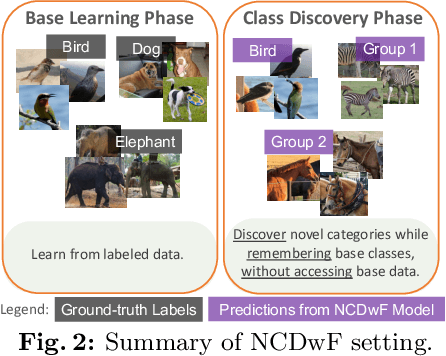
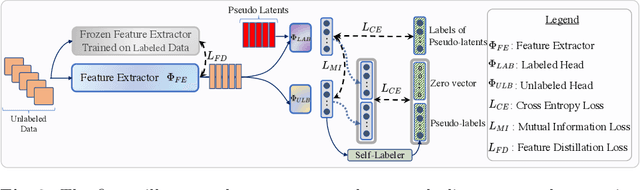
Humans possess an innate ability to identify and differentiate instances that they are not familiar with, by leveraging and adapting the knowledge that they have acquired so far. Importantly, they achieve this without deteriorating the performance on their earlier learning. Inspired by this, we identify and formulate a new, pragmatic problem setting of NCDwF: Novel Class Discovery without Forgetting, which tasks a machine learning model to incrementally discover novel categories of instances from unlabeled data, while maintaining its performance on the previously seen categories. We propose 1) a method to generate pseudo-latent representations which act as a proxy for (no longer available) labeled data, thereby alleviating forgetting, 2) a mutual-information based regularizer which enhances unsupervised discovery of novel classes, and 3) a simple Known Class Identifier which aids generalized inference when the testing data contains instances form both seen and unseen categories. We introduce experimental protocols based on CIFAR-10, CIFAR-100 and ImageNet-1000 to measure the trade-off between knowledge retention and novel class discovery. Our extensive evaluations reveal that existing models catastrophically forget previously seen categories while identifying novel categories, while our method is able to effectively balance between the competing objectives. We hope our work will attract further research into this newly identified pragmatic problem setting.
Slot Filling for Extracting Reskilling and Upskilling Options from the Web
Jul 11, 2022Disturbances in the job market such as advances in science and technology, crisis and increased competition have triggered a surge in reskilling and upskilling programs. Information on suitable continuing education options is distributed across many sites, rendering the search, comparison and selection of useful programs a cumbersome task. This paper, therefore, introduces a knowledge extraction system that integrates reskilling and upskilling options into a single knowledge graph. The system collects educational programs from 488 different providers and uses context extraction for identifying and contextualizing relevant content. Afterwards, entity recognition and entity linking methods draw upon a domain ontology to locate relevant entities such as skills, occupations and topics. Finally, slot filling integrates entities based on their context into the corresponding slots of the continuous education knowledge graph. We also introduce a German gold standard that comprises 169 documents and over 3800 annotations for benchmarking the necessary content extraction, entity linking, entity recognition and slot filling tasks, and provide an overview of the system's performance.
Identification of Threat Regions From a Dynamic Occupancy Grid Map for Situation-Aware Environment Perception
Jul 05, 2022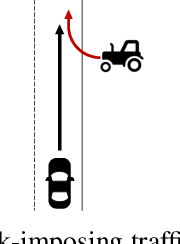
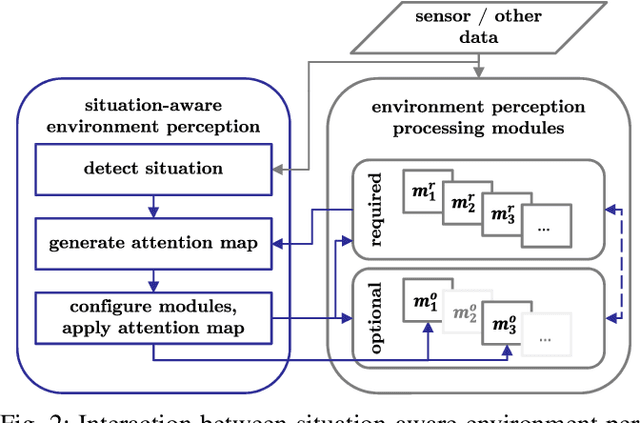
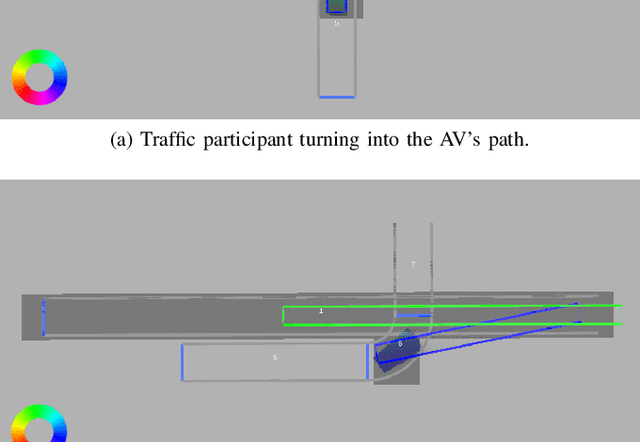
The advance towards higher levels of automation within the field of automated driving is accompanied by increasing requirements for the operational safety of vehicles. Induced by the limitation of computational resources, trade-offs between the computational complexity of algorithms and their potential to ensure safe operation of automated vehicles are often encountered. Situation-aware environment perception presents one promising example, where computational resources are distributed to regions within the perception area that are relevant for the task of the automated vehicle. While prior map knowledge is often leveraged to identify relevant regions, in this work, we present a lightweight identification of safety-relevant regions that relies solely on online information. We show that our approach enables safe vehicle operation in critical scenarios, while retaining the benefits of non-uniformly distributed resources within the environment perception.
Time3D: End-to-End Joint Monocular 3D Object Detection and Tracking for Autonomous Driving
May 30, 2022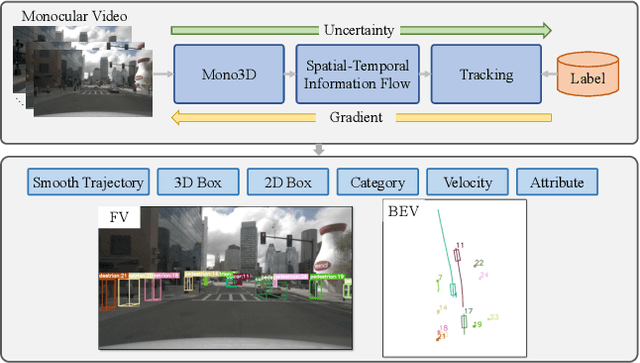
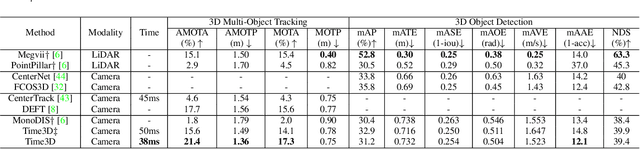
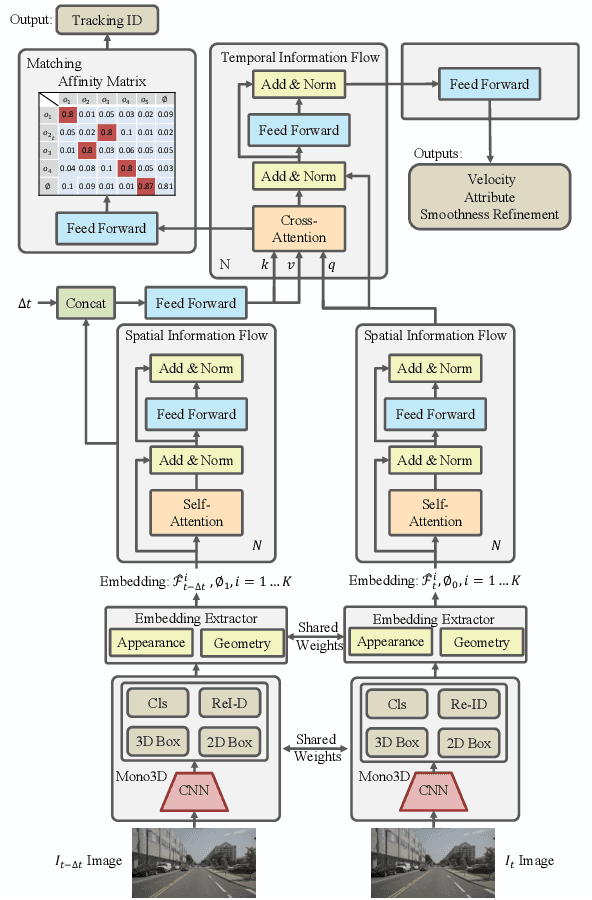
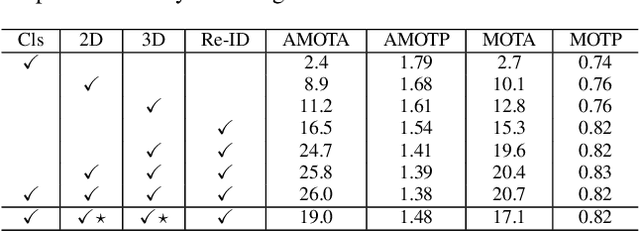
While separately leveraging monocular 3D object detection and 2D multi-object tracking can be straightforwardly applied to sequence images in a frame-by-frame fashion, stand-alone tracker cuts off the transmission of the uncertainty from the 3D detector to tracking while cannot pass tracking error differentials back to the 3D detector. In this work, we propose jointly training 3D detection and 3D tracking from only monocular videos in an end-to-end manner. The key component is a novel spatial-temporal information flow module that aggregates geometric and appearance features to predict robust similarity scores across all objects in current and past frames. Specifically, we leverage the attention mechanism of the transformer, in which self-attention aggregates the spatial information in a specific frame, and cross-attention exploits relation and affinities of all objects in the temporal domain of sequence frames. The affinities are then supervised to estimate the trajectory and guide the flow of information between corresponding 3D objects. In addition, we propose a temporal -consistency loss that explicitly involves 3D target motion modeling into the learning, making the 3D trajectory smooth in the world coordinate system. Time3D achieves 21.4\% AMOTA, 13.6\% AMOTP on the nuScenes 3D tracking benchmark, surpassing all published competitors, and running at 38 FPS, while Time3D achieves 31.2\% mAP, 39.4\% NDS on the nuScenes 3D detection benchmark.
Multi-manifold Attention for Vision Transformers
Jul 18, 2022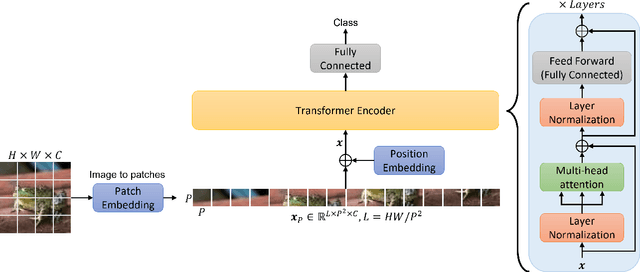
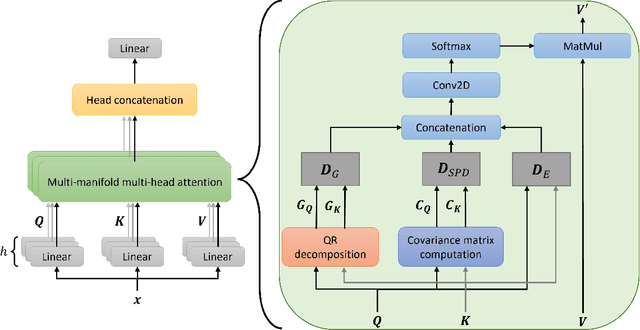
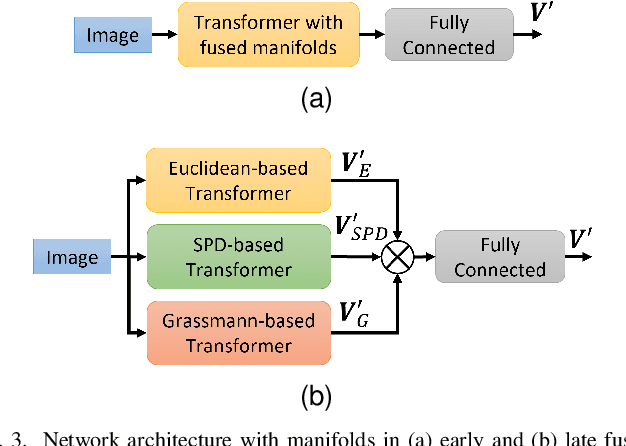

Vision Transformer are very popular nowadays due to their state-of-the-art performance in several computer vision tasks, such as image classification and action recognition. Although the performance of Vision Transformers have been greatly improved by employing Convolutional Neural Networks, hierarchical structures and compact forms, there is limited research on ways to utilize additional data representations to refine the attention map derived from the multi-head attention of a Transformer network. This work proposes a novel attention mechanism, called multi-manifold attention, that can substitute any standard attention mechanism in a Transformer-based network. The proposed attention models the input space in three distinct manifolds, namely Euclidean, Symmetric Positive Definite and Grassmann, with different statistical and geometrical properties, guiding the network to take into consideration a rich set of information that describe the appearance, color and texture of an image, for the computation of a highly descriptive attention map. In this way, a Vision Transformer with the proposed attention is guided to become more attentive towards discriminative features, leading to improved classification results, as shown by the experimental results on several well-known image classification datasets.
Learning Functions on Multiple Sets using Multi-Set Transformers
Jun 30, 2022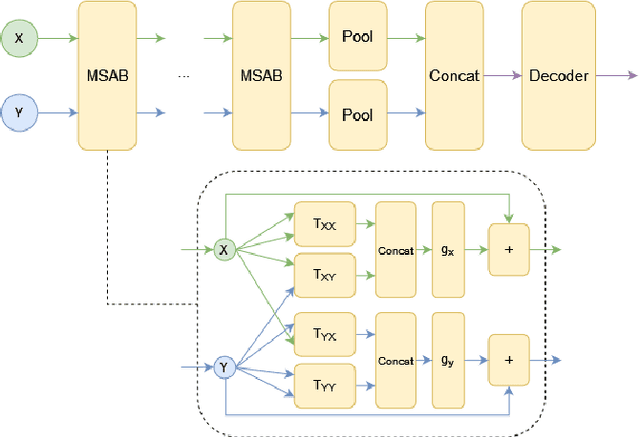
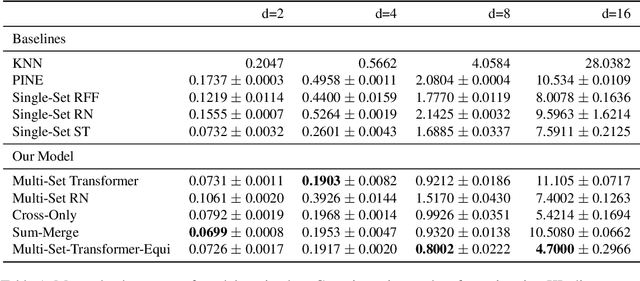
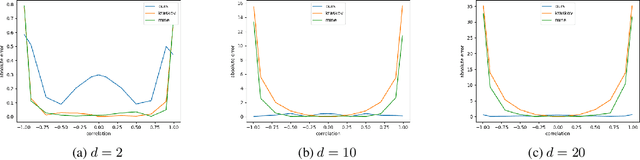
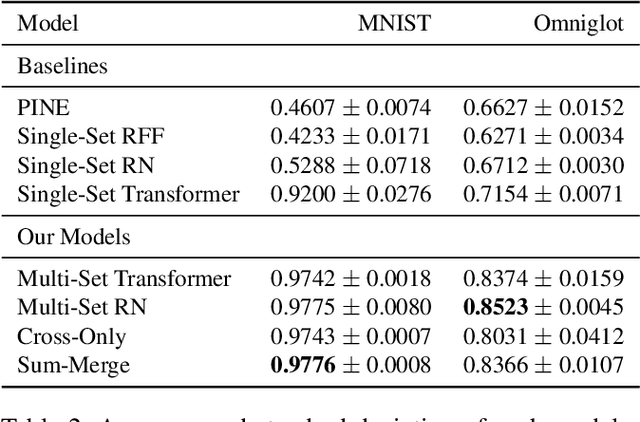
We propose a general deep architecture for learning functions on multiple permutation-invariant sets. We also show how to generalize this architecture to sets of elements of any dimension by dimension equivariance. We demonstrate that our architecture is a universal approximator of these functions, and show superior results to existing methods on a variety of tasks including counting tasks, alignment tasks, distinguishability tasks and statistical distance measurements. This last task is quite important in Machine Learning. Although our approach is quite general, we demonstrate that it can generate approximate estimates of KL divergence and mutual information that are more accurate than previous techniques that are specifically designed to approximate those statistical distances.
DHGE: Dual-view Hyper-Relational Knowledge Graph Embedding for Link Prediction and Entity Typing
Jul 18, 2022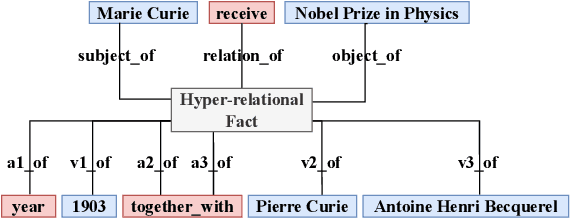
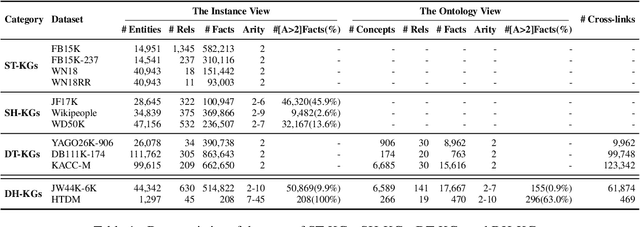
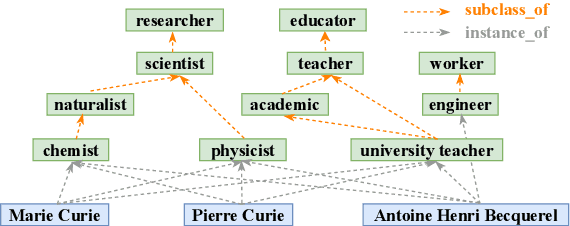
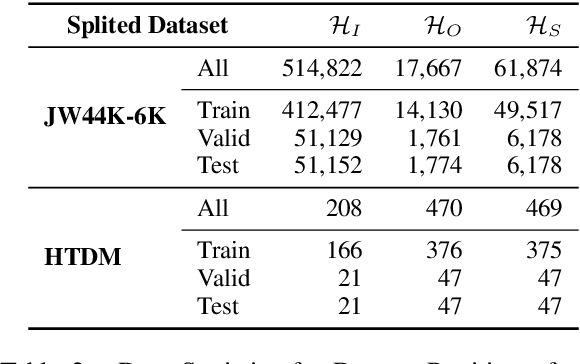
In the field of representation learning on knowledge graphs (KGs), a hyper-relational fact consists of a main triple and several auxiliary attribute value descriptions, which is considered to be more comprehensive and specific than a triple-based fact. However, the existing hyper-relational KG embedding methods in a single view are limited in application due to weakening the hierarchical structure representing the affiliation between entities. To break this limitation, we propose a dual-view hyper-relational KG (DH-KG) structure which contains a hyper-relational instance view for entities and a hyper-relational ontology view for concepts abstracted hierarchically from entities to jointly model hyper-relational and hierarchical information. In this paper, we first define link prediction and entity typing tasks on DH-KG and construct two DH-KG datasets, JW44K-6K extracted from Wikidata and HTDM based on medical data. Furthermore, We propose a DH-KG embedding model DHGE, based on GRAN encoder, HGNN, and joint learning. Experimental results show that DHGE outperforms baseline models on DH-KG. We also provide an example of the application of this technology in the field of hypertension medication. Our model and datasets are publicly available.
Neural Network Learning of Chemical Bond Representations in Spectral Indices and Features
Jul 21, 2022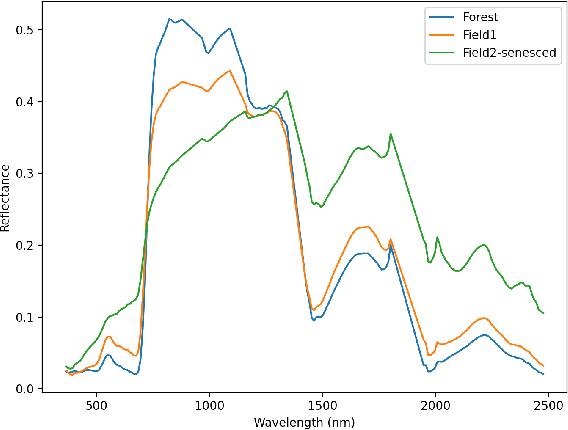


In this paper we investigate neural networks for classification in hyperspectral imaging with a focus on connecting the architecture of the network with the physics of the sensing and materials present. Spectroscopy is the process of measuring light reflected or emitted by a material as a function wavelength. Molecular bonds present in the material have vibrational frequencies which affect the amount of light measured at each wavelength. Thus the measured spectrum contains information about the particular chemical constituents and types of bonds. For example, chlorophyll reflects more light in the near-IR rage (800-900nm) than in the red (625-675nm) range, and this difference can be measured using a normalized vegetation difference index (NDVI), which is commonly used to detect vegetation presence, health, and type in imagery collected at these wavelengths. In this paper we show that the weights in a Neural Network trained on different vegetation classes learn to measure this difference in reflectance. We then show that a Neural Network trained on a more complex set of ten different polymer materials will learn spectral 'features' evident in the weights for the network, and these features can be used to reliably distinguish between the different types of polymers. Examination of the weights provides a human-interpretable understanding of the network.
MQRetNN: Multi-Horizon Time Series Forecasting with Retrieval Augmentation
Jul 21, 2022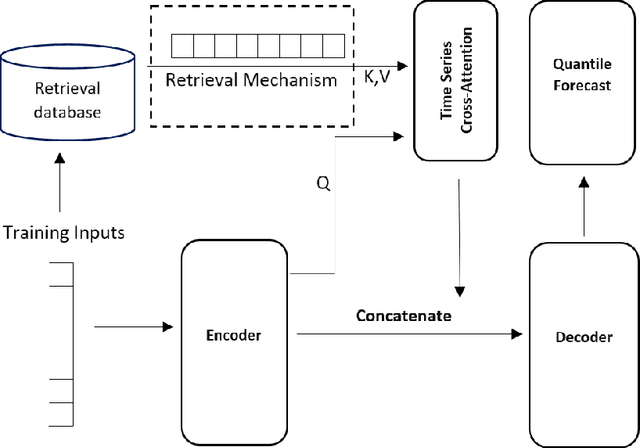
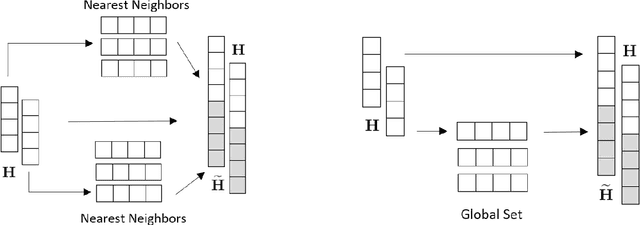
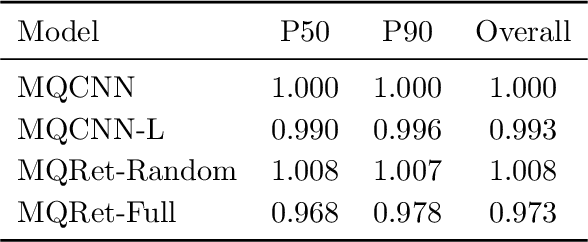
Multi-horizon probabilistic time series forecasting has wide applicability to real-world tasks such as demand forecasting. Recent work in neural time-series forecasting mainly focus on the use of Seq2Seq architectures. For example, MQTransformer - an improvement of MQCNN - has shown the state-of-the-art performance in probabilistic demand forecasting. In this paper, we consider incorporating cross-entity information to enhance model performance by adding a cross-entity attention mechanism along with a retrieval mechanism to select which entities to attend over. We demonstrate how our new neural architecture, MQRetNN, leverages the encoded contexts from a pretrained baseline model on the entire population to improve forecasting accuracy. Using MQCNN as the baseline model (due to computational constraints, we do not use MQTransformer), we first show on a small demand forecasting dataset that it is possible to achieve ~3% improvement in test loss by adding a cross-entity attention mechanism where each entity attends to all others in the population. We then evaluate the model with our proposed retrieval methods - as a means of approximating an attention over a large population - on a large-scale demand forecasting application with over 2 million products and observe ~1% performance gain over the MQCNN baseline.