 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSlot Filling for Extracting Reskilling and Upskilling Options from the Web
Jul 11, 2022Disturbances in the job market such as advances in science and technology, crisis and increased competition have triggered a surge in reskilling and upskilling programs. Information on suitable continuing education options is distributed across many sites, rendering the search, comparison and selection of useful programs a cumbersome task. This paper, therefore, introduces a knowledge extraction system that integrates reskilling and upskilling options into a single knowledge graph. The system collects educational programs from 488 different providers and uses context extraction for identifying and contextualizing relevant content. Afterwards, entity recognition and entity linking methods draw upon a domain ontology to locate relevant entities such as skills, occupations and topics. Finally, slot filling integrates entities based on their context into the corresponding slots of the continuous education knowledge graph. We also introduce a German gold standard that comprises 169 documents and over 3800 annotations for benchmarking the necessary content extraction, entity linking, entity recognition and slot filling tasks, and provide an overview of the system's performance.
Improving Company Valuations with Automated Knowledge Discovery, Extraction and Fusion
Oct 19, 2020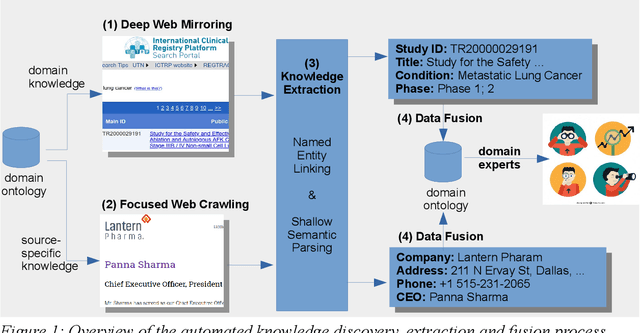
Performing company valuations within the domain of biotechnology, pharmacy and medical technology is a challenging task, especially when considering the unique set of risks biotech start-ups face when entering new markets. Companies specialized in global valuation services, therefore, combine valuation models and past experience with heterogeneous metrics and indicators that provide insights into a company's performance. This paper illustrates how automated knowledge discovery, extraction and data fusion can be used to (i) obtain additional indicators that provide insights into the success of a company's product development efforts, and (ii) support labor-intensive data curation processes. We apply deep web knowledge acquisition methods to identify and harvest data on clinical trials that is hidden behind proprietary search interfaces and integrate the extracted data into the industry partner's company valuation ontology. In addition, focused Web crawls and shallow semantic parsing yield information on the company's key personnel and respective contact data, notifying domain experts of relevant changes that get then incorporated into the industry partner's company data.