 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHVR-Met: A Hypothesis-Verification-Replaning Agentic System for Extreme Weather Diagnosis
Mar 01, 2026While deep learning-based weather forecasting paradigms have made significant strides, addressing extreme weather diagnostics remains a formidable challenge. This gap exists primarily because the diagnostic process demands sophisticated multi-step logical reasoning, dynamic tool invocation, and expert-level prior judgment. Although agents possess inherent advantages in task decomposition and autonomous execution, current architectures are still hampered by critical bottlenecks: inadequate expert knowledge integration, a lack of professional-grade iterative reasoning loops, and the absence of fine-grained validation and evaluation systems for complex workflows under extreme conditions. To this end, we propose HVR-Met, a multi-agent meteorological diagnostic system characterized by the deep integration of expert knowledge. Its central innovation is the ``Hypothesis-Verification-Replanning'' closed-loop mechanism, which facilitates sophisticated iterative reasoning for anomalous meteorological signals during extreme weather events. To bridge gaps within existing evaluation frameworks, we further introduce a novel benchmark focused on atomic-level subtasks. Experimental evidence demonstrates that the system excels in complex diagnostic scenarios.
NQE: N-ary Query Embedding for Complex Query Answering over Hyper-relational Knowledge Graphs
Nov 24, 2022



Complex query answering (CQA) is an essential task for multi-hop and logical reasoning on knowledge graphs (KGs). Currently, most approaches are limited to queries among binary relational facts and pay less attention to n-ary facts (n>=2) containing more than two entities, which are more prevalent in the real world. Moreover, previous CQA methods can only make predictions for a few given types of queries and cannot be flexibly extended to more complex logical queries, which significantly limits their applications. To overcome these challenges, in this work, we propose a novel N-ary Query Embedding (NQE) model for CQA over hyper-relational knowledge graphs (HKGs), which include massive n-ary facts. The NQE utilizes a dual-heterogeneous Transformer encoder and fuzzy logic theory to satisfy all n-ary FOL queries, including existential quantifiers, conjunction, disjunction, and negation. We also propose a parallel processing algorithm that can train or predict arbitrary n-ary FOL queries in a single batch, regardless of the kind of each query, with good flexibility and extensibility. In addition, we generate a new CQA dataset WD50K-NFOL, including diverse n-ary FOL queries over WD50K. Experimental results on WD50K-NFOL and other standard CQA datasets show that NQE is the state-of-the-art CQA method over HKGs with good generalization capability. Our code and dataset are publicly available.
DHGE: Dual-view Hyper-Relational Knowledge Graph Embedding for Link Prediction and Entity Typing
Jul 18, 2022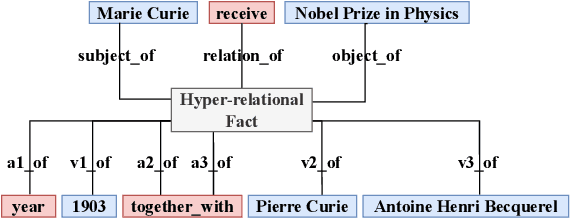
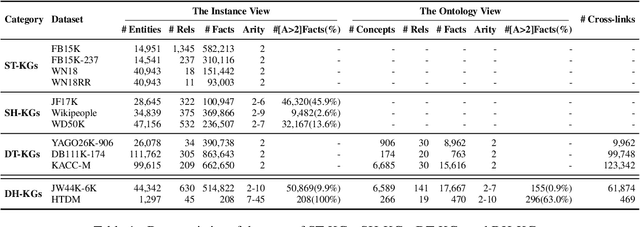
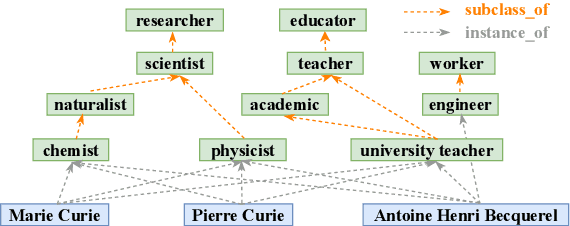
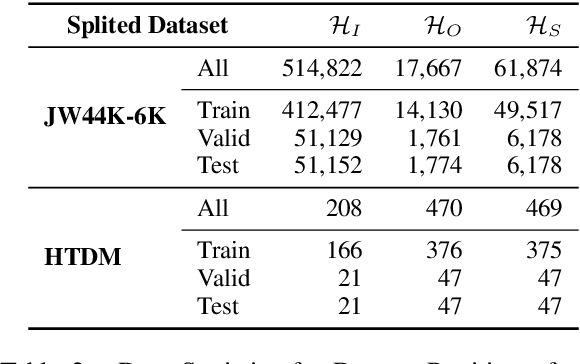
In the field of representation learning on knowledge graphs (KGs), a hyper-relational fact consists of a main triple and several auxiliary attribute value descriptions, which is considered to be more comprehensive and specific than a triple-based fact. However, the existing hyper-relational KG embedding methods in a single view are limited in application due to weakening the hierarchical structure representing the affiliation between entities. To break this limitation, we propose a dual-view hyper-relational KG (DH-KG) structure which contains a hyper-relational instance view for entities and a hyper-relational ontology view for concepts abstracted hierarchically from entities to jointly model hyper-relational and hierarchical information. In this paper, we first define link prediction and entity typing tasks on DH-KG and construct two DH-KG datasets, JW44K-6K extracted from Wikidata and HTDM based on medical data. Furthermore, We propose a DH-KG embedding model DHGE, based on GRAN encoder, HGNN, and joint learning. Experimental results show that DHGE outperforms baseline models on DH-KG. We also provide an example of the application of this technology in the field of hypertension medication. Our model and datasets are publicly available.
TFLEX: Temporal Feature-Logic Embedding Framework for Complex Reasoning over Temporal Knowledge Graph
May 28, 2022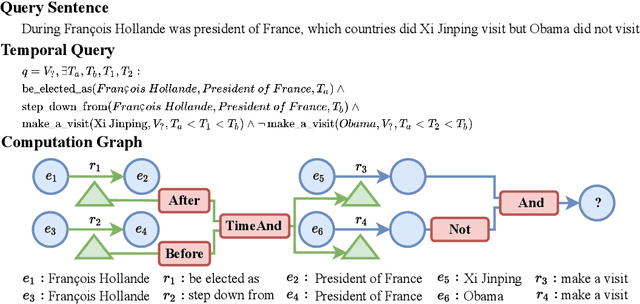

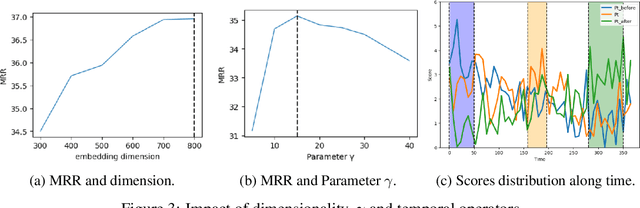
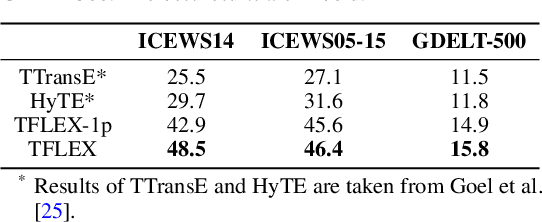
Multi-hop logical reasoning over knowledge graph (KG) plays a fundamental role in many artificial intelligence tasks. Recent complex query embedding (CQE) methods for reasoning focus on static KGs, while temporal knowledge graphs (TKGs) have not been fully explored. Reasoning over TKGs has two challenges: 1. The query should answer entities or timestamps; 2. The operators should consider both set logic on entity set and temporal logic on timestamp set. To bridge this gap, we define the multi-hop logical reasoning problem on TKGs. With generated three datasets, we propose the first temporal CQE named Temporal Feature-Logic Embedding framework (TFLEX) to answer the temporal complex queries. We utilize vector logic to compute the logic part of Temporal Feature-Logic embeddings, thus naturally modeling all First-Order Logic (FOL) operations on entity set. In addition, our framework extends vector logic on timestamp set to cope with three extra temporal operators (After, Before and Between). Experiments on numerous query patterns demonstrate the effectiveness of our method.
FLEX: Feature-Logic Embedding Framework for CompleX Knowledge Graph Reasoning
May 23, 2022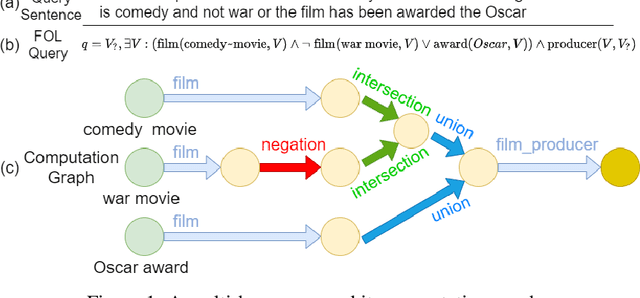
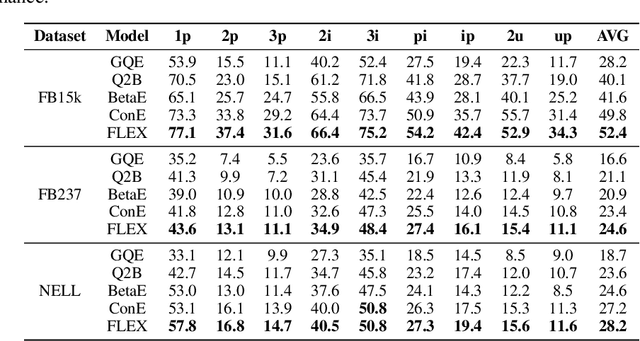
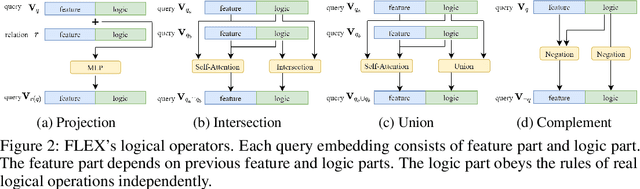
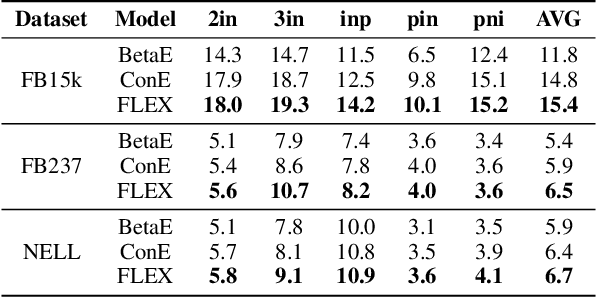
Current best performing models for knowledge graph reasoning (KGR) are based on complex distribution or geometry objects to embed entities and first-order logical (FOL) queries in low-dimensional spaces. They can be summarized as a center-size framework (point/box/cone, Beta/Gaussian distribution, etc.) whose logical reasoning ability is limited by the expressiveness of the relevant mathematical concepts. Because too deeply the center and the size depend on each other, it is difficult to integrate the logical reasoning ability with other models. To address these challenges, we instead propose a novel KGR framework named Feature-Logic Embedding framework, FLEX, which is the first KGR framework that can not only TRULY handle all FOL operations including conjunction, disjunction, negation and so on, but also support various feature spaces. Specifically, the logic part of feature-logic framework is based on vector logic, which naturally models all FOL operations. Experiments demonstrate that FLEX significantly outperforms existing state-of-the-art methods on benchmark datasets.