 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Economic and Language Models for Enhanced Sentiment Analysis of the Oil Market
Oct 16, 2024Crude oil, a critical component of the global economy, has its prices influenced by various factors such as economic trends, political events, and natural disasters. Traditional prediction methods based on historical data have their limits in forecasting, but recent advancements in natural language processing bring new possibilities for event-based analysis. In particular, Language Models (LM) and their advancement, the Generative Pre-trained Transformer (GPT), have shown potential in classifying vast amounts of natural language. However, these LMs often have difficulty with domain-specific terminology, limiting their effectiveness in the crude oil sector. Addressing this gap, we introduce CrudeBERT, a fine-tuned LM specifically for the crude oil market. The results indicate that CrudeBERT's sentiment scores align more closely with the WTI Futures curve and significantly enhance price predictions, underscoring the crucial role of integrating economic principles into LMs.
CrudeBERT: Applying Economic Theory towards fine-tuning Transformer-based Sentiment Analysis Models to the Crude Oil Market
May 10, 2023Predicting market movements based on the sentiment of news media has a long tradition in data analysis. With advances in natural language processing, transformer architectures have emerged that enable contextually aware sentiment classification. Nevertheless, current methods built for the general financial market such as FinBERT cannot distinguish asset-specific value-driving factors. This paper addresses this shortcoming by presenting a method that identifies and classifies events that impact supply and demand in the crude oil markets within a large corpus of relevant news headlines. We then introduce CrudeBERT, a new sentiment analysis model that draws upon these events to contextualize and fine-tune FinBERT, thereby yielding improved sentiment classifications for headlines related to the crude oil futures market. An extensive evaluation demonstrates that CrudeBERT outperforms proprietary and open-source solutions in the domain of crude oil.
Slot Filling for Extracting Reskilling and Upskilling Options from the Web
Jul 11, 2022Disturbances in the job market such as advances in science and technology, crisis and increased competition have triggered a surge in reskilling and upskilling programs. Information on suitable continuing education options is distributed across many sites, rendering the search, comparison and selection of useful programs a cumbersome task. This paper, therefore, introduces a knowledge extraction system that integrates reskilling and upskilling options into a single knowledge graph. The system collects educational programs from 488 different providers and uses context extraction for identifying and contextualizing relevant content. Afterwards, entity recognition and entity linking methods draw upon a domain ontology to locate relevant entities such as skills, occupations and topics. Finally, slot filling integrates entities based on their context into the corresponding slots of the continuous education knowledge graph. We also introduce a German gold standard that comprises 169 documents and over 3800 annotations for benchmarking the necessary content extraction, entity linking, entity recognition and slot filling tasks, and provide an overview of the system's performance.
Inscriptis -- A Python-based HTML to text conversion library optimized for knowledge extraction from the Web
Jul 12, 2021

Inscriptis provides a library, command line client and Web service for converting HTML to plain text. Its development has been triggered by the need to obtain accurate text representations for knowledge extraction tasks that preserve the spatial alignment of text without drawing upon heavyweight, browser-based solutions such as Selenium. In contrast to existing software packages such as HTML2text, jusText and Lynx, Inscriptis (i) provides a layout-aware conversion of HTML that more closely resembles the rendering obtained from standard Web browsers and, therefore, better preserves the spatial arrangement of text elements. Inscriptis excels in terms of conversion quality, since it correctly converts complex HTML constructs such as nested tables and also interprets a subset of HTML attributes that determine the text alignment. In addition, it (ii) supports annotation rules, i.e., user-provided mappings that allow for annotating the extracted text based on structural and semantic information encoded in HTML tags and attributes used for controlling structure and layout in the original HTML document. These unique features ensure that downstream knowledge extraction components can operate on accurate text representations, and may even use information on the semantics and structure of the original HTML document, if annotation support has been enabled.
Harvest -- An Open Source Toolkit for Extracting Posts and Post Metadata from Web Forums
Feb 03, 2021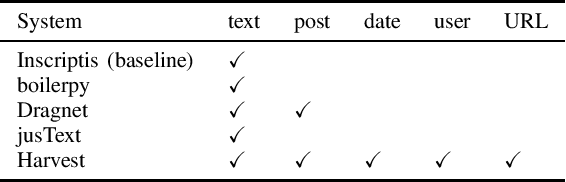
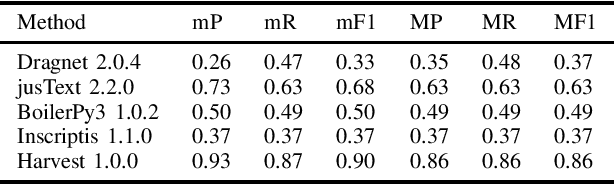
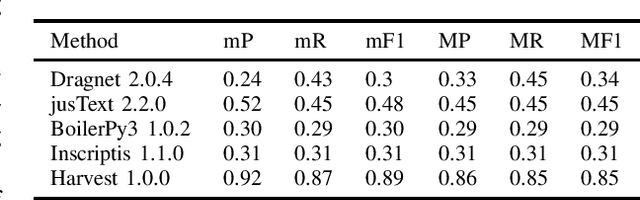
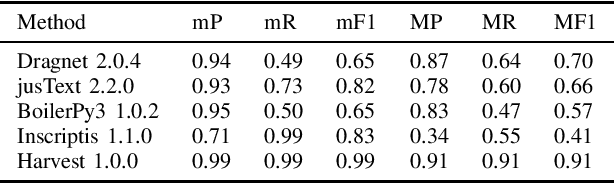
Automatic extraction of forum posts and metadata is a crucial but challenging task since forums do not expose their content in a standardized structure. Content extraction methods, therefore, often need customizations such as adaptations to page templates and improvements of their extraction code before they can be deployed to new forums. Most of the current solutions are also built for the more general case of content extraction from web pages and lack key features important for understanding forum content such as the identification of author metadata and information on the thread structure. This paper, therefore, presents a method that determines the XPath of forum posts, eliminating incorrect mergers and splits of the extracted posts that were common in systems from the previous generation. Based on the individual posts further metadata such as authors, forum URL and structure are extracted. We also introduce Harvest, a new open source toolkit that implements the presented methods and create a gold standard extracted from 52 different Web forums for evaluating our approach. A comprehensive evaluation reveals that Harvest clearly outperforms competing systems.
Automatic Expansion of Domain-Specific Affective Models for Web Intelligence Applications
Feb 01, 2021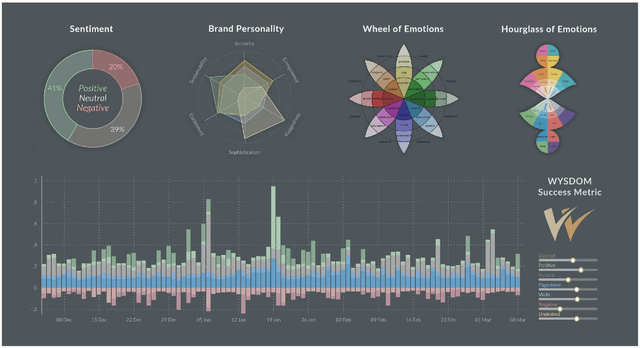

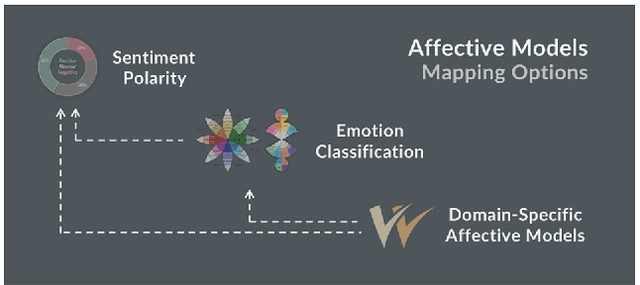

Sentic computing relies on well-defined affective models of different complexity - polarity to distinguish positive and negative sentiment, for example, or more nuanced models to capture expressions of human emotions. When used to measure communication success, even the most granular affective model combined with sophisticated machine learning approaches may not fully capture an organisation's strategic positioning goals. Such goals often deviate from the assumptions of standardised affective models. While certain emotions such as Joy and Trust typically represent desirable brand associations, specific communication goals formulated by marketing professionals often go beyond such standard dimensions. For instance, the brand manager of a television show may consider fear or sadness to be desired emotions for its audience. This article introduces expansion techniques for affective models, combining common and commonsense knowledge available in knowledge graphs with language models and affective reasoning, improving coverage and consistency as well as supporting domain-specific interpretations of emotions. An extensive evaluation compares the performance of different expansion techniques: (i) a quantitative evaluation based on the revisited Hourglass of Emotions model to assess performance on complex models that cover multiple affective categories, using manually compiled gold standard data, and (ii) a qualitative evaluation of a domain-specific affective model for television programme brands. The results of these evaluations demonstrate that the introduced techniques support a variety of embeddings and pre-trained models. The paper concludes with a discussion on applying this approach to other scenarios where affective model resources are scarce.
* see also https://link.springer.com/article/10.1007/s12559-021-09839-4
Improving Company Valuations with Automated Knowledge Discovery, Extraction and Fusion
Oct 19, 2020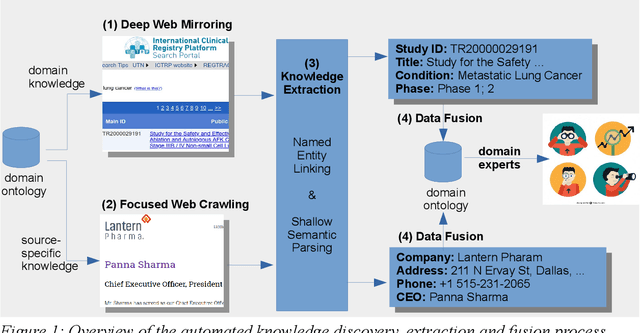
Performing company valuations within the domain of biotechnology, pharmacy and medical technology is a challenging task, especially when considering the unique set of risks biotech start-ups face when entering new markets. Companies specialized in global valuation services, therefore, combine valuation models and past experience with heterogeneous metrics and indicators that provide insights into a company's performance. This paper illustrates how automated knowledge discovery, extraction and data fusion can be used to (i) obtain additional indicators that provide insights into the success of a company's product development efforts, and (ii) support labor-intensive data curation processes. We apply deep web knowledge acquisition methods to identify and harvest data on clinical trials that is hidden behind proprietary search interfaces and integrate the extracted data into the industry partner's company valuation ontology. In addition, focused Web crawls and shallow semantic parsing yield information on the company's key personnel and respective contact data, notifying domain experts of relevant changes that get then incorporated into the industry partner's company data.