 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSlot Filling for Extracting Reskilling and Upskilling Options from the Web
Jul 11, 2022Disturbances in the job market such as advances in science and technology, crisis and increased competition have triggered a surge in reskilling and upskilling programs. Information on suitable continuing education options is distributed across many sites, rendering the search, comparison and selection of useful programs a cumbersome task. This paper, therefore, introduces a knowledge extraction system that integrates reskilling and upskilling options into a single knowledge graph. The system collects educational programs from 488 different providers and uses context extraction for identifying and contextualizing relevant content. Afterwards, entity recognition and entity linking methods draw upon a domain ontology to locate relevant entities such as skills, occupations and topics. Finally, slot filling integrates entities based on their context into the corresponding slots of the continuous education knowledge graph. We also introduce a German gold standard that comprises 169 documents and over 3800 annotations for benchmarking the necessary content extraction, entity linking, entity recognition and slot filling tasks, and provide an overview of the system's performance.
Harvest -- An Open Source Toolkit for Extracting Posts and Post Metadata from Web Forums
Feb 03, 2021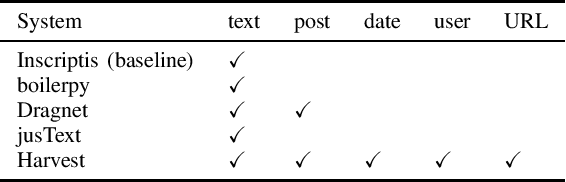
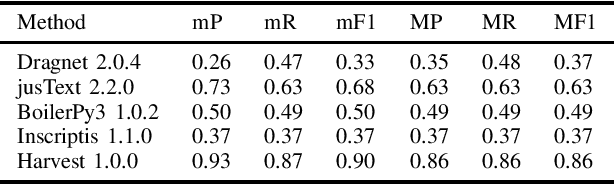
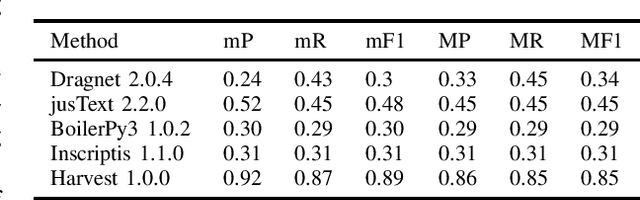
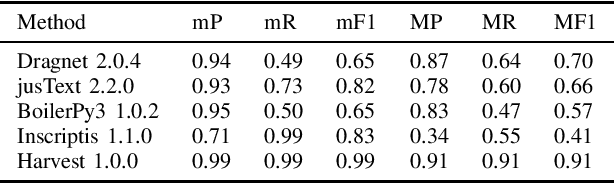
Automatic extraction of forum posts and metadata is a crucial but challenging task since forums do not expose their content in a standardized structure. Content extraction methods, therefore, often need customizations such as adaptations to page templates and improvements of their extraction code before they can be deployed to new forums. Most of the current solutions are also built for the more general case of content extraction from web pages and lack key features important for understanding forum content such as the identification of author metadata and information on the thread structure. This paper, therefore, presents a method that determines the XPath of forum posts, eliminating incorrect mergers and splits of the extracted posts that were common in systems from the previous generation. Based on the individual posts further metadata such as authors, forum URL and structure are extracted. We also introduce Harvest, a new open source toolkit that implements the presented methods and create a gold standard extracted from 52 different Web forums for evaluating our approach. A comprehensive evaluation reveals that Harvest clearly outperforms competing systems.