 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Sequential Manipulation Planning on Scene Graph
Jul 17, 2022
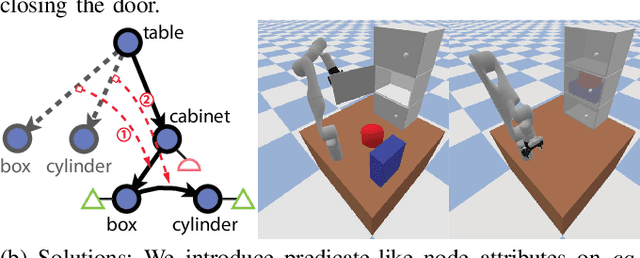
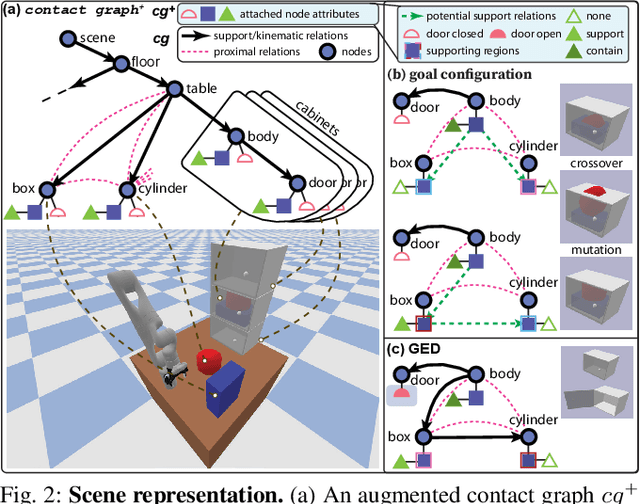
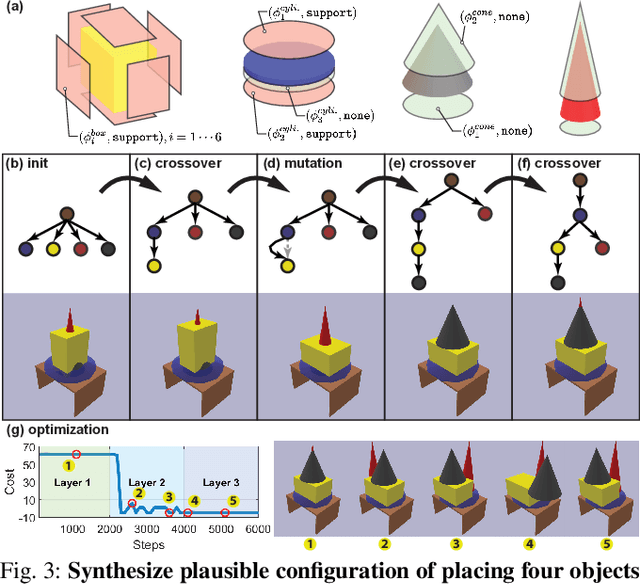
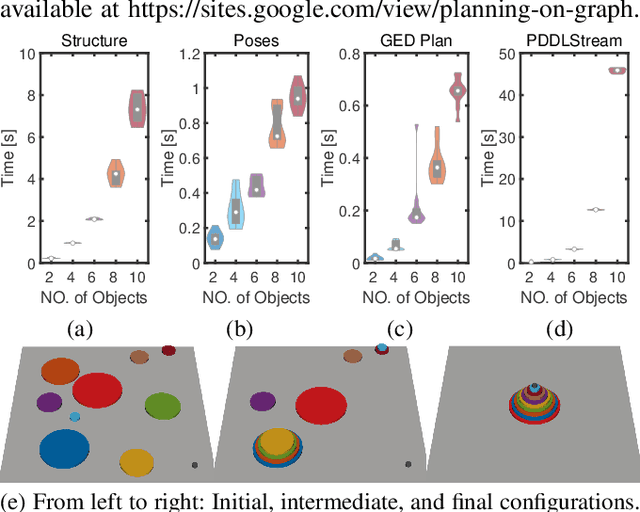
We devise a 3D scene graph representation, contact graph+ (cg+), for efficient sequential task planning. Augmented with predicate-like attributes, this contact graph-based representation abstracts scene layouts with succinct geometric information and valid robot-scene interactions. Goal configurations, naturally specified on contact graphs, can be produced by a genetic algorithm with a stochastic optimization method. A task plan is then initialized by computing the Graph Editing Distance (GED) between the initial contact graphs and the goal configurations, which generates graph edit operations corresponding to possible robot actions. We finalize the task plan by imposing constraints to regulate the temporal feasibility of graph edit operations, ensuring valid task and motion correspondences. In a series of simulations and experiments, robots successfully complete complex sequential object rearrangement tasks that are difficult to specify using conventional planning language like Planning Domain Definition Language (PDDL), demonstrating the high feasibility and potential of robot sequential task planning on contact graph.
Dynamic Structure Estimation from Bandit Feedback
Jun 02, 2022
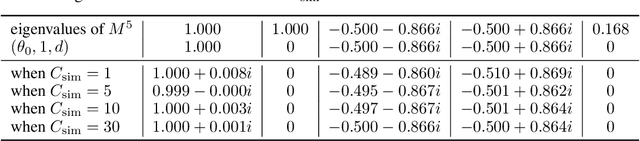
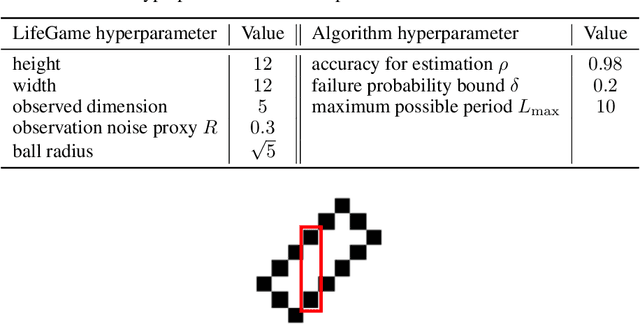
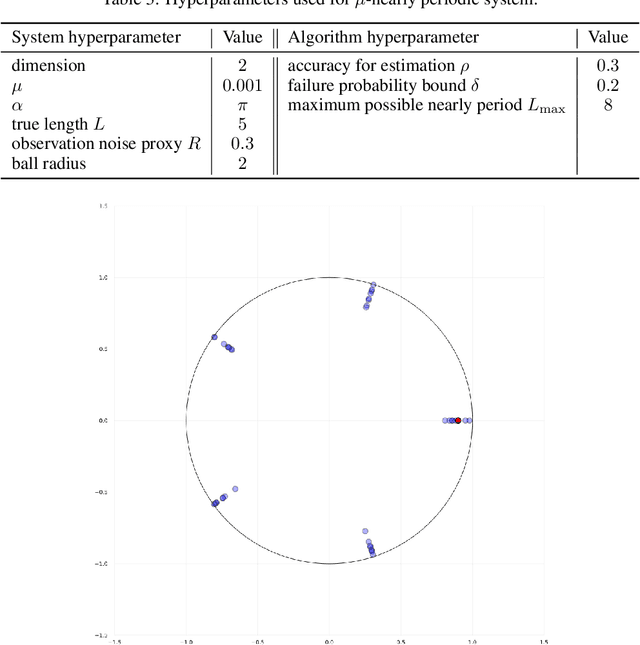
This work present novel method for structure estimation of an underlying dynamical system. We tackle problems of estimating dynamic structure from bandit feedback contaminated by sub-Gaussian noise. In particular, we focus on periodically behaved discrete dynamical system in the Euclidean space, and carefully identify certain obtainable subset of full information of the periodic structure. We then derive a sample complexity bound for periodic structure estimation. Technically, asymptotic results for exponential sums are adopted to effectively average out the noise effects while preventing the information to be estimated from vanishing. For linear systems, the use of the Weyl sum further allows us to extract eigenstructures. Our theoretical claims are experimentally validated on simulations of toy examples, including Cellular Automata.
On the Robustness of 3D Object Detectors
Jul 20, 2022
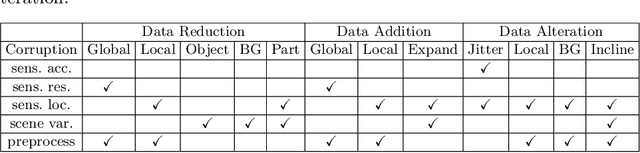

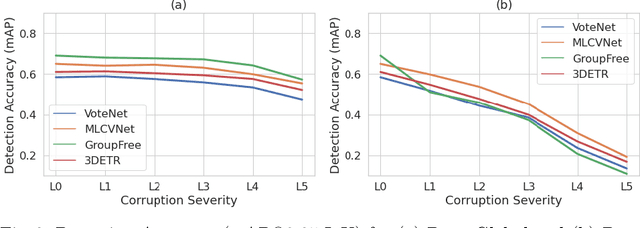
In recent years, significant progress has been achieved for 3D object detection on point clouds thanks to the advances in 3D data collection and deep learning techniques. Nevertheless, 3D scenes exhibit a lot of variations and are prone to sensor inaccuracies as well as information loss during pre-processing. Thus, it is crucial to design techniques that are robust against these variations. This requires a detailed analysis and understanding of the effect of such variations. This work aims to analyze and benchmark popular point-based 3D object detectors against several data corruptions. To the best of our knowledge, we are the first to investigate the robustness of point-based 3D object detectors. To this end, we design and evaluate corruptions that involve data addition, reduction, and alteration. We further study the robustness of different modules against local and global variations. Our experimental results reveal several intriguing findings. For instance, we show that methods that integrate Transformers at a patch or object level lead to increased robustness, compared to using Transformers at the point level.
Exploiting Inductive Bias in Transformers for Unsupervised Disentanglement of Syntax and Semantics with VAEs
May 12, 2022
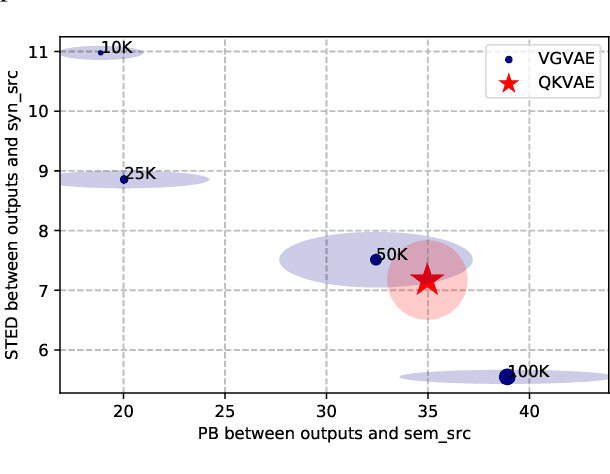
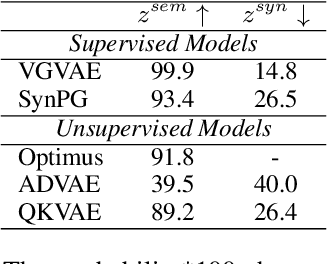
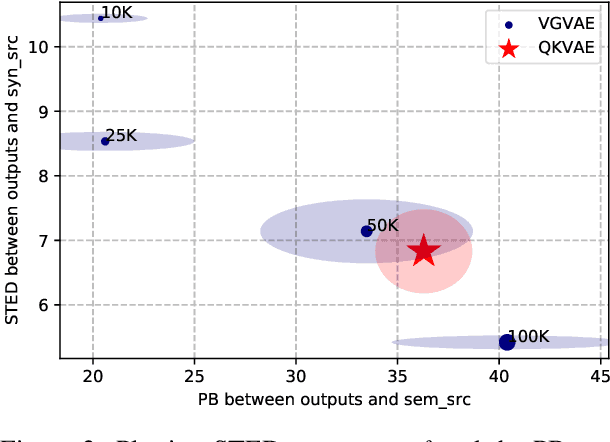
We propose a generative model for text generation, which exhibits disentangled latent representations of syntax and semantics. Contrary to previous work, this model does not need syntactic information such as constituency parses, or semantic information such as paraphrase pairs. Our model relies solely on the inductive bias found in attention-based architectures such as Transformers. In the attention of Transformers, keys handle information selection while values specify what information is conveyed. Our model, dubbed QKVAE, uses Attention in its decoder to read latent variables where one latent variable infers keys while another infers values. We run experiments on latent representations and experiments on syntax/semantics transfer which show that QKVAE displays clear signs of disentangled syntax and semantics. We also show that our model displays competitive syntax transfer capabilities when compared to supervised models and that comparable supervised models need a fairly large amount of data (more than 50K samples) to outperform it on both syntactic and semantic transfer. The code for our experiments is publicly available.
Beam Aware Stochastic Multihop Routing for Flying Ad-hoc Networks
May 24, 2022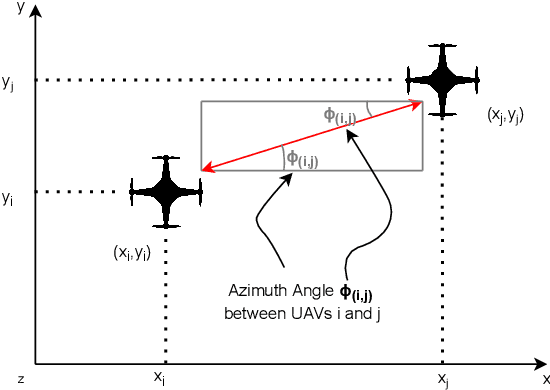
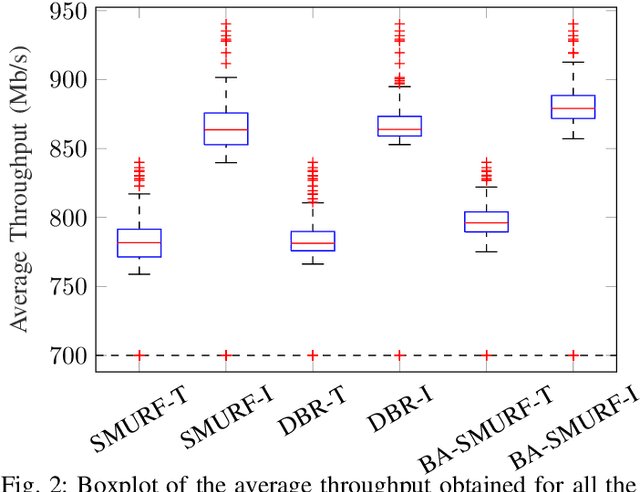
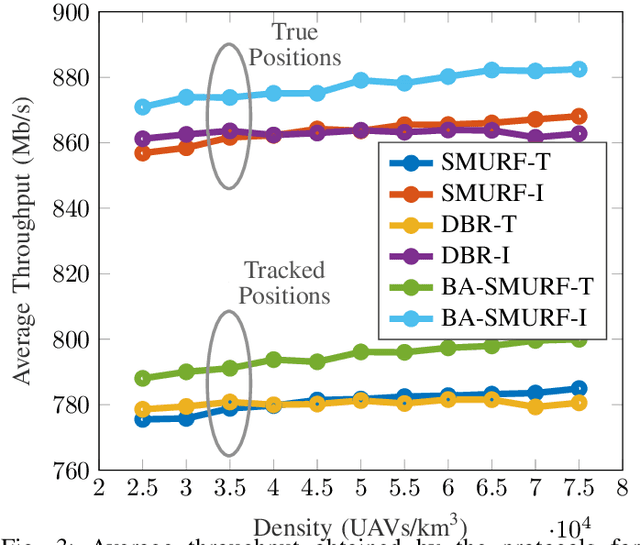
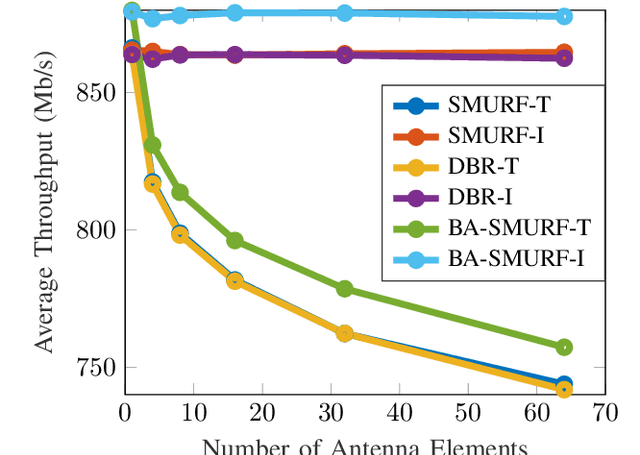
Routing is a crucial component in the design of Flying Ad-Hoc Networks (FANETs). State of the art routing solutions exploit the position of Unmanned Aerial Vehicles (UAVs) and their mobility information to determine the existence of links between them, but this information is often unreliable, as the topology of FANETs can change quickly and unpredictably. In order to improve the tracking performance, the uncertainty introduced by imperfect measurements and tracking algorithms needs to be accounted for in the routing. Another important element to consider is beamforming, which can reduce interference, but requires accurate channel and position information to work. In this work, we present the Beam Aware Stochastic Multihop Routing for FANETs (BA-SMURF), a Software-Defined Networking (SDN) routing scheme that takes into account the positioning uncertainty and beamforming design to find the most reliable routes in a FANET. Our simulation results show that joint consideration of the beamforming and routing can provide a 5% throughput improvement with respect to the state of the art.
Learning to Order for Inventory Systems with Lost Sales and Uncertain Supplies
Jul 10, 2022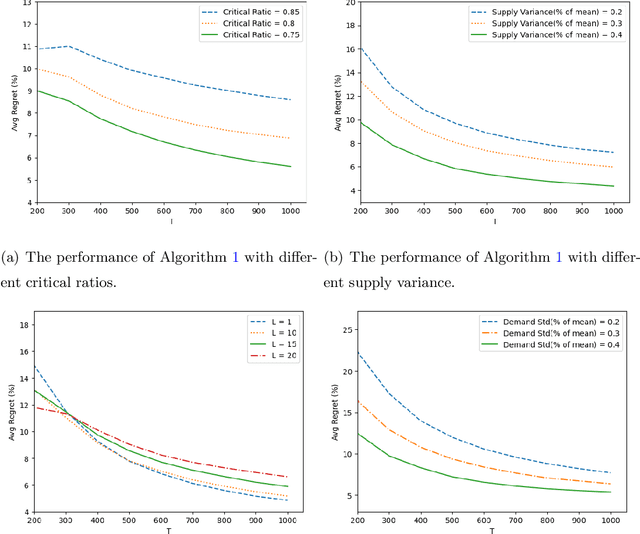
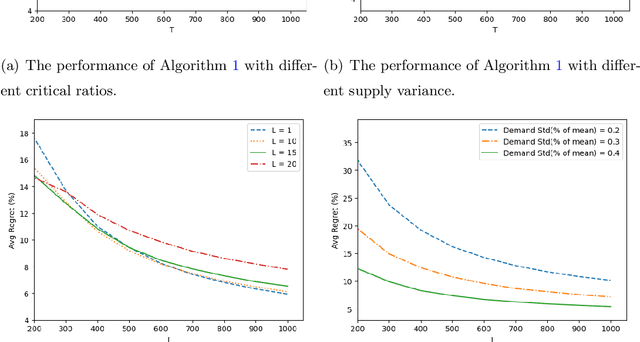
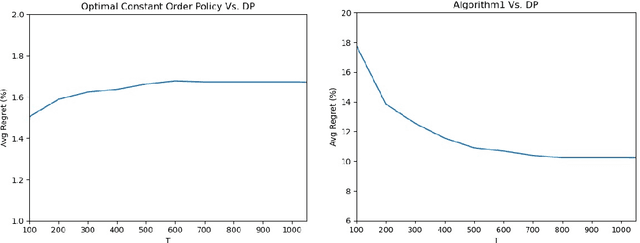
We consider a stochastic lost-sales inventory control system with a lead time $L$ over a planning horizon $T$. Supply is uncertain, and is a function of the order quantity (due to random yield/capacity, etc). We aim to minimize the $T$-period cost, a problem that is known to be computationally intractable even under known distributions of demand and supply. In this paper, we assume that both the demand and supply distributions are unknown and develop a computationally efficient online learning algorithm. We show that our algorithm achieves a regret (i.e. the performance gap between the cost of our algorithm and that of an optimal policy over $T$ periods) of $O(L+\sqrt{T})$ when $L\geq\log(T)$. We do so by 1) showing our algorithm cost is higher by at most $O(L+\sqrt{T})$ for any $L\geq 0$ compared to an optimal constant-order policy under complete information (a well-known and widely-used algorithm) and 2) leveraging its known performance guarantee from the existing literature. To the best of our knowledge, a finite-sample $O(\sqrt{T})$ (and polynomial in $L$) regret bound when benchmarked against an optimal policy is not known before in the online inventory control literature. A key challenge in this learning problem is that both demand and supply data can be censored; hence only truncated values are observable. We circumvent this challenge by showing that the data generated under an order quantity $q^2$ allows us to simulate the performance of not only $q^2$ but also $q^1$ for all $q^1<q^2$, a key observation to obtain sufficient information even under data censoring. By establishing a high probability coupling argument, we are able to evaluate and compare the performance of different order policies at their steady state within a finite time horizon. Since the problem lacks convexity, we develop an active elimination method that adaptively rules out suboptimal solutions.
Pre-training Transformers for Molecular Property Prediction Using Reaction Prediction
Jul 06, 2022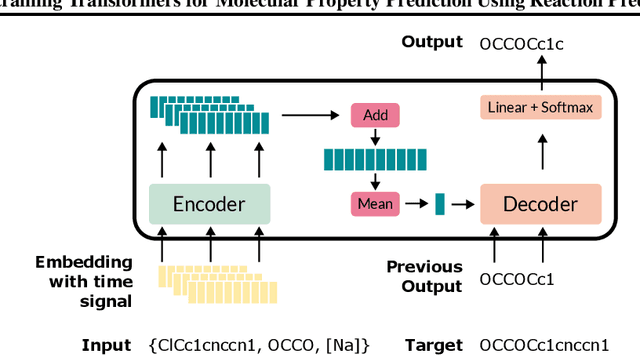
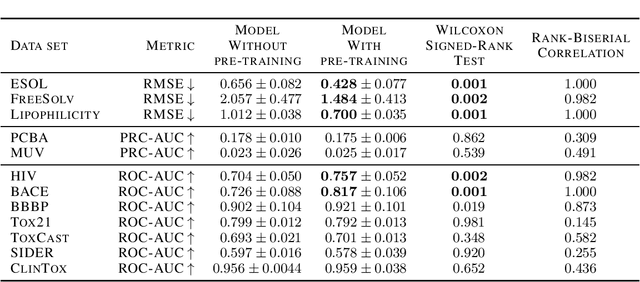
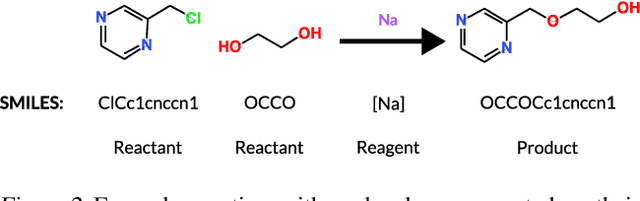
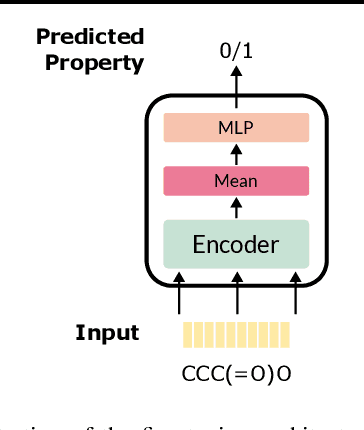
Molecular property prediction is essential in chemistry, especially for drug discovery applications. However, available molecular property data is often limited, encouraging the transfer of information from related data. Transfer learning has had a tremendous impact in fields like Computer Vision and Natural Language Processing signaling for its potential in molecular property prediction. We present a pre-training procedure for molecular representation learning using reaction data and use it to pre-train a SMILES Transformer. We fine-tune and evaluate the pre-trained model on 12 molecular property prediction tasks from MoleculeNet within physical chemistry, biophysics, and physiology and show a statistically significant positive effect on 5 of the 12 tasks compared to a non-pre-trained baseline model.
Motion Gait: Gait Recognition via Motion Excitation
Jun 22, 2022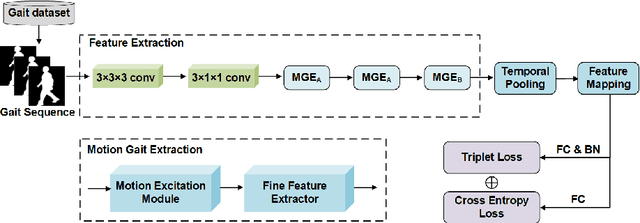
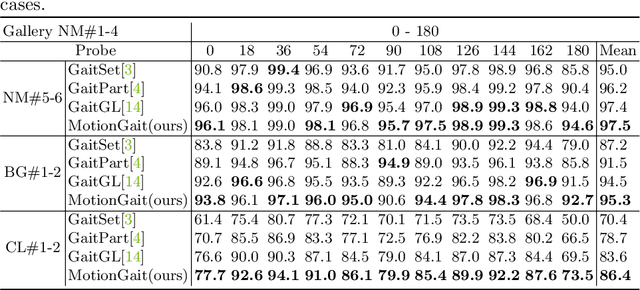
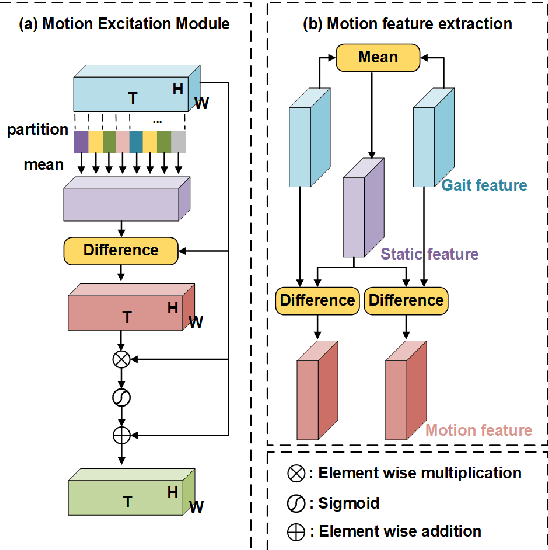

Gait recognition, which can realize long-distance and contactless identification, is an important biometric technology. Recent gait recognition methods focus on learning the pattern of human movement or appearance during walking, and construct the corresponding spatio-temporal representations. However, different individuals have their own laws of movement patterns, simple spatial-temporal features are difficult to describe changes in motion of human parts, especially when confounding variables such as clothing and carrying are included, thus distinguishability of features is reduced. In this paper, we propose the Motion Excitation Module (MEM) to guide spatio-temporal features to focus on human parts with large dynamic changes, MEM learns the difference information between frames and intervals, so as to obtain the representation of temporal motion changes, it is worth mentioning that MEM can adapt to frame sequences with uncertain length, and it does not add any additional parameters. Furthermore, we present the Fine Feature Extractor (FFE), which independently learns the spatio-temporal representations of human body according to different horizontal parts of individuals. Benefiting from MEM and FFE, our method innovatively combines motion change information, significantly improving the performance of the model under cross appearance conditions. On the popular dataset CASIA-B, our proposed Motion Gait is better than the existing gait recognition methods.
SchenQL: A query language for bibliographic data with aggregations and domain-specific functions
May 13, 2022


Current search interfaces of digital libraries are not suitable to satisfy complex or convoluted information needs directly, when it comes to cases such as "Find authors who only recently started working on a topic". They might offer possibilities to obtain this information only by requiring vast user interaction. We present SchenQL, a web interface of a domain-specific query language on bibliographic metadata, which offers information search and exploration by query formulation and navigation in the system. Our system focuses on supporting aggregation of data and providing specialised domain dependent functions while being suitable for domain experts as well as casual users of digital libraries.
Probabilistic forecasts of extreme heatwaves using convolutional neural networks in a regime of lack of data
Aug 01, 2022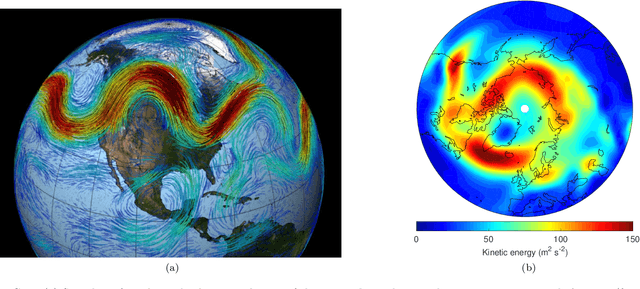
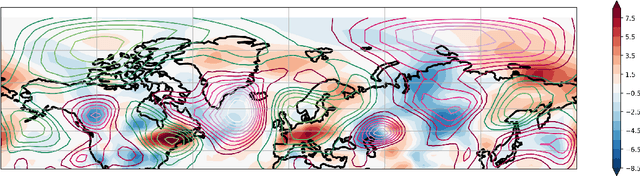
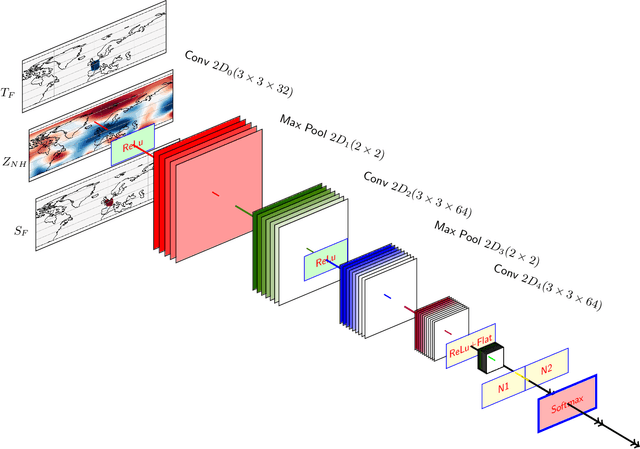
Understanding extreme events and their probability is key for the study of climate change impacts, risk assessment, adaptation, and the protection of living beings. In this work we develop a methodology to build forecasting models for extreme heatwaves. These models are based on convolutional neural networks, trained on extremely long 8,000-year climate model outputs. Because the relation between extreme events is intrinsically probabilistic, we emphasise probabilistic forecast and validation. We demonstrate that deep neural networks are suitable for this purpose for long lasting 14-day heatwaves over France, up to 15 days ahead of time for fast dynamical drivers (500 hPa geopotential height fields), and also at much longer lead times for slow physical drivers (soil moisture). The method is easily implemented and versatile. We find that the deep neural network selects extreme heatwaves associated with a North-Hemisphere wavenumber-3 pattern. We find that the 2 meter temperature field does not contain any new useful statistical information for heatwave forecast, when added to the 500 hPa geopotential height and soil moisture fields. The main scientific message is that training deep neural networks for predicting extreme heatwaves occurs in a regime of drastic lack of data. We suggest that this is likely the case for most other applications to large scale atmosphere and climate phenomena. We discuss perspectives for dealing with the lack of data regime, for instance rare event simulations, and how transfer learning may play a role in this latter task.