 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion Gait: Gait Recognition via Motion Excitation
Jun 22, 2022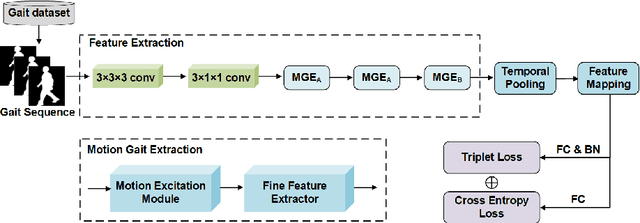
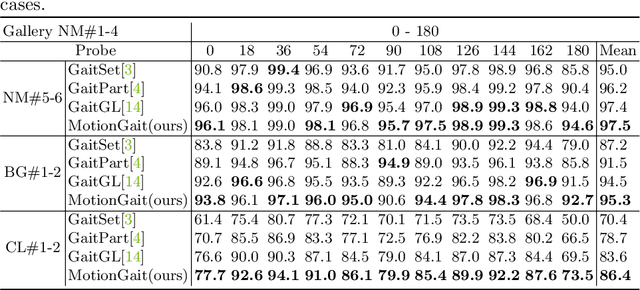
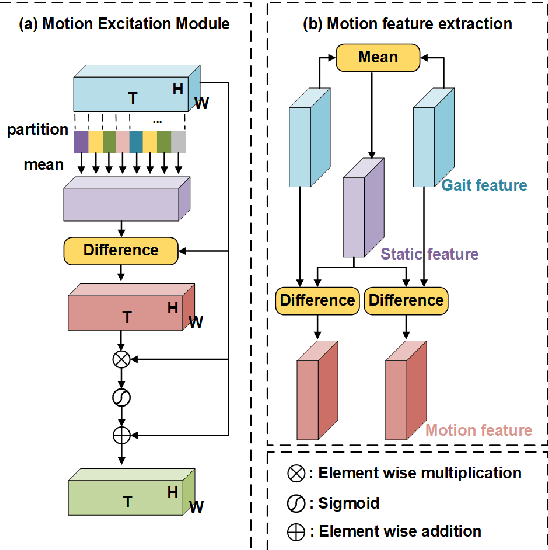

Gait recognition, which can realize long-distance and contactless identification, is an important biometric technology. Recent gait recognition methods focus on learning the pattern of human movement or appearance during walking, and construct the corresponding spatio-temporal representations. However, different individuals have their own laws of movement patterns, simple spatial-temporal features are difficult to describe changes in motion of human parts, especially when confounding variables such as clothing and carrying are included, thus distinguishability of features is reduced. In this paper, we propose the Motion Excitation Module (MEM) to guide spatio-temporal features to focus on human parts with large dynamic changes, MEM learns the difference information between frames and intervals, so as to obtain the representation of temporal motion changes, it is worth mentioning that MEM can adapt to frame sequences with uncertain length, and it does not add any additional parameters. Furthermore, we present the Fine Feature Extractor (FFE), which independently learns the spatio-temporal representations of human body according to different horizontal parts of individuals. Benefiting from MEM and FFE, our method innovatively combines motion change information, significantly improving the performance of the model under cross appearance conditions. On the popular dataset CASIA-B, our proposed Motion Gait is better than the existing gait recognition methods.
Cross-Enhancement Transformer for Action Segmentation
May 19, 2022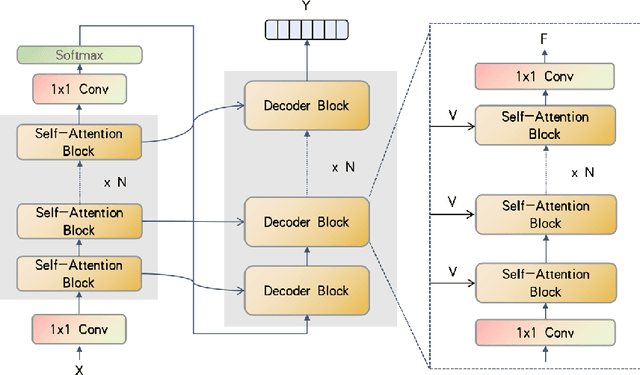

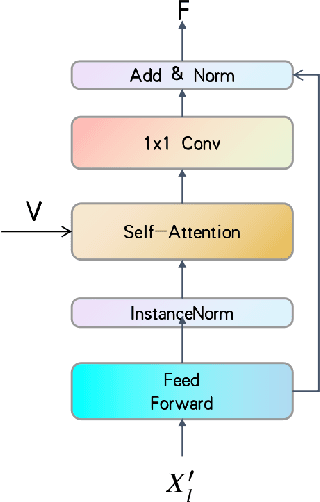
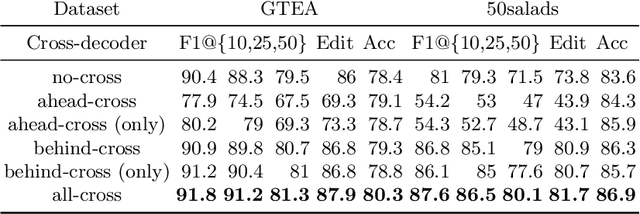
Temporal convolutions have been the paradigm of choice in action segmentation, which enhances long-term receptive fields by increasing convolution layers. However, high layers cause the loss of local information necessary for frame recognition. To solve the above problem, a novel encoder-decoder structure is proposed in this paper, called Cross-Enhancement Transformer. Our approach can be effective learning of temporal structure representation with interactive self-attention mechanism. Concatenated each layer convolutional feature maps in encoder with a set of features in decoder produced via self-attention. Therefore, local and global information are used in a series of frame actions simultaneously. In addition, a new loss function is proposed to enhance the training process that penalizes over-segmentation errors. Experiments show that our framework performs state-of-the-art on three challenging datasets: 50Salads, Georgia Tech Egocentric Activities and the Breakfast dataset.