 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Curved Geometric Networks for Visual Anomaly Recognition
Aug 02, 2022
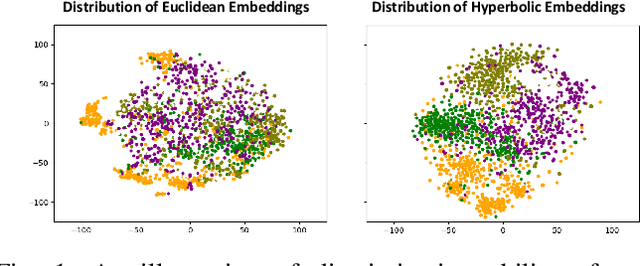
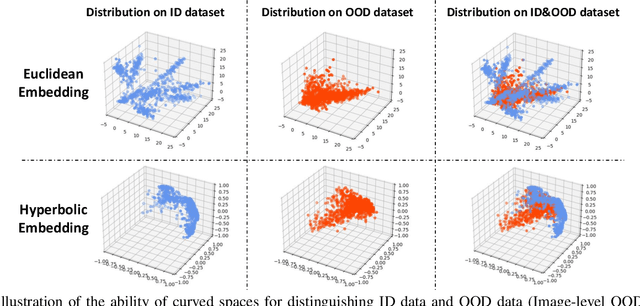
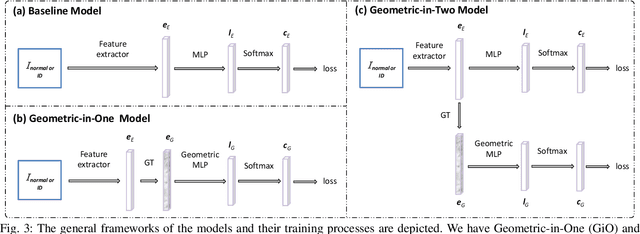
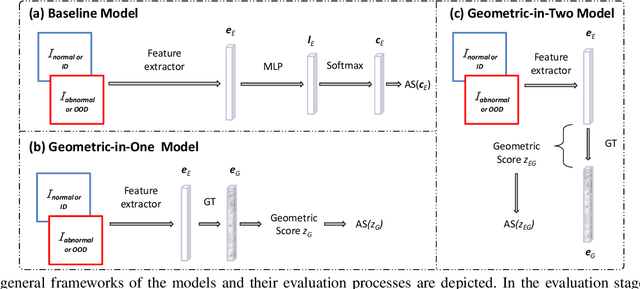
Learning a latent embedding to understand the underlying nature of data distribution is often formulated in Euclidean spaces with zero curvature. However, the success of the geometry constraints, posed in the embedding space, indicates that curved spaces might encode more structural information, leading to better discriminative power and hence richer representations. In this work, we investigate benefits of the curved space for analyzing anomalies or out-of-distribution objects in data. This is achieved by considering embeddings via three geometry constraints, namely, spherical geometry (with positive curvature), hyperbolic geometry (with negative curvature) or mixed geometry (with both positive and negative curvatures). Three geometric constraints can be chosen interchangeably in a unified design given the task at hand. Tailored for the embeddings in the curved space, we also formulate functions to compute the anomaly score. Two types of geometric modules (i.e., Geometric-in-One and Geometric-in-Two models) are proposed to plug in the original Euclidean classifier, and anomaly scores are computed from the curved embeddings. We evaluate the resulting designs under a diverse set of visual recognition scenarios, including image detection (multi-class OOD detection and one-class anomaly detection) and segmentation (multi-class anomaly segmentation and one-class anomaly segmentation). The empirical results show the effectiveness of our proposal through the consistent improvement over various scenarios.
Equivariant Representation Learning via Class-Pose Decomposition
Jul 07, 2022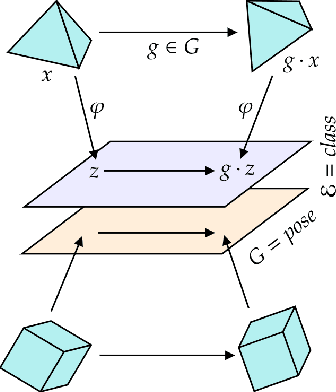
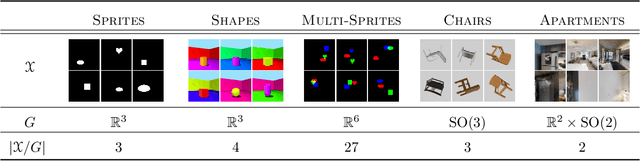
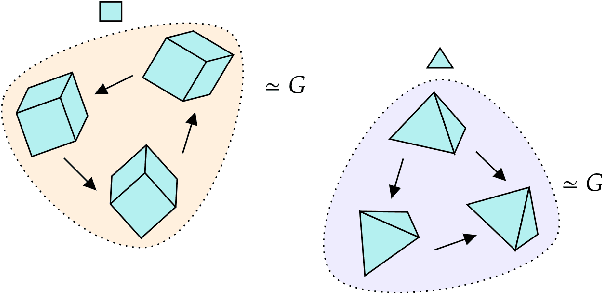
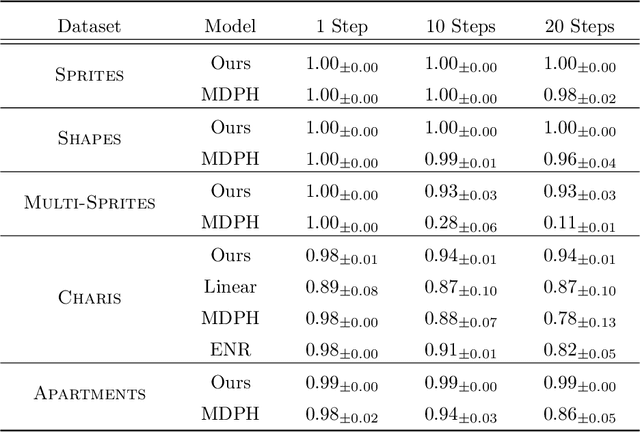
We introduce a general method for learning representations that are equivariant to symmetries of data. The central idea is to to decompose the latent space in an invariant factor and the symmetry group itself. The components semantically correspond to intrinsic data classes and poses respectively. The learner is self-supervised and infers these semantics based on relative symmetry information. The approach is motivated by theoretical results from group theory and guarantees representations that are lossless, interpretable and disentangled. We empirically investigate the approach via experiments involving datasets with a variety of symmetries. Results show that our representations capture the geometry of data and outperform other equivariant representation learning frameworks.
A Comprehensive Survey of Natural Language Generation Advances from the Perspective of Digital Deception
Aug 11, 2022


In recent years there has been substantial growth in the capabilities of systems designed to generate text that mimics the fluency and coherence of human language. From this, there has been considerable research aimed at examining the potential uses of these natural language generators (NLG) towards a wide number of tasks. The increasing capabilities of powerful text generators to mimic human writing convincingly raises the potential for deception and other forms of dangerous misuse. As these systems improve, and it becomes ever harder to distinguish between human-written and machine-generated text, malicious actors could leverage these powerful NLG systems to a wide variety of ends, including the creation of fake news and misinformation, the generation of fake online product reviews, or via chatbots as means of convincing users to divulge private information. In this paper, we provide an overview of the NLG field via the identification and examination of 119 survey-like papers focused on NLG research. From these identified papers, we outline a proposed high-level taxonomy of the central concepts that constitute NLG, including the methods used to develop generalised NLG systems, the means by which these systems are evaluated, and the popular NLG tasks and subtasks that exist. In turn, we provide an overview and discussion of each of these items with respect to current research and offer an examination of the potential roles of NLG in deception and detection systems to counteract these threats. Moreover, we discuss the broader challenges of NLG, including the risks of bias that are often exhibited by existing text generation systems. This work offers a broad overview of the field of NLG with respect to its potential for misuse, aiming to provide a high-level understanding of this rapidly developing area of research.
A Systematic Comparison of Phonetic Aware Techniques for Speech Enhancement
Jun 22, 2022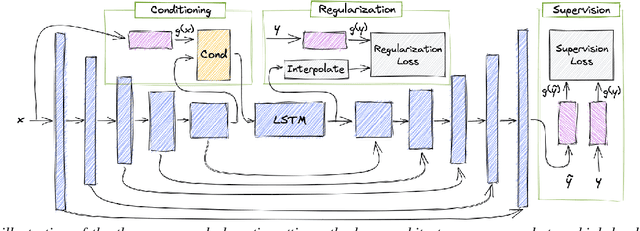
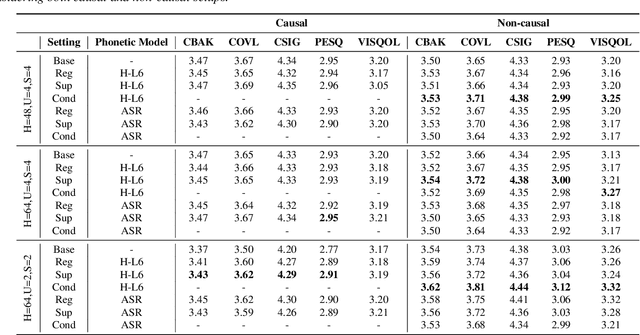
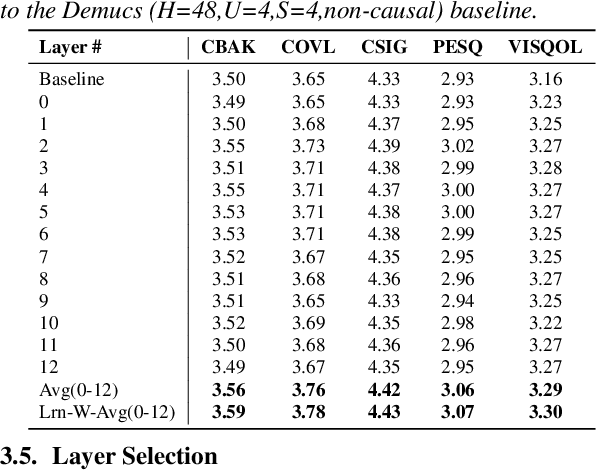
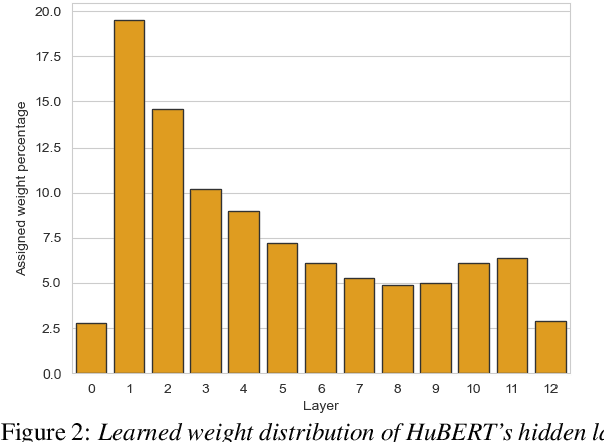
Speech enhancement has seen great improvement in recent years using end-to-end neural networks. However, most models are agnostic to the spoken phonetic content. Recently, several studies suggested phonetic-aware speech enhancement, mostly using perceptual supervision. Yet, injecting phonetic features during model optimization can take additional forms (e.g., model conditioning). In this paper, we conduct a systematic comparison between different methods of incorporating phonetic information in a speech enhancement model. By conducting a series of controlled experiments, we observe the influence of different phonetic content models as well as various feature-injection techniques on enhancement performance, considering both causal and non-causal models. Specifically, we evaluate three settings for injecting phonetic information, namely: i) feature conditioning; ii) perceptual supervision; and iii) regularization. Phonetic features are obtained using an intermediate layer of either a supervised pre-trained Automatic Speech Recognition (ASR) model or by using a pre-trained Self-Supervised Learning (SSL) model. We further observe the effect of choosing different embedding layers on performance, considering both manual and learned configurations. Results suggest that using a SSL model as phonetic features outperforms the ASR one in most cases. Interestingly, the conditioning setting performs best among the evaluated configurations.
Contrastive Image Synthesis and Self-supervised Feature Adaptation for Cross-Modality Biomedical Image Segmentation
Jul 27, 2022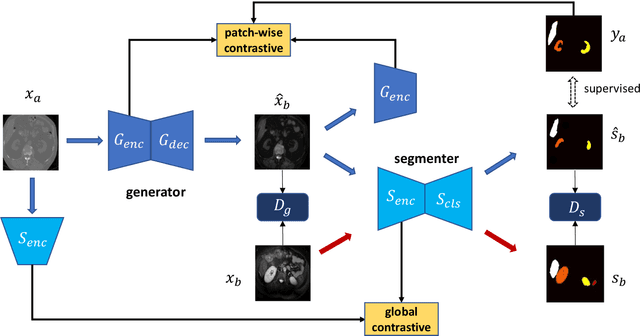
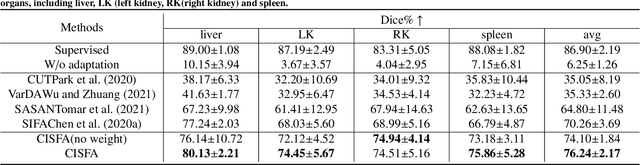
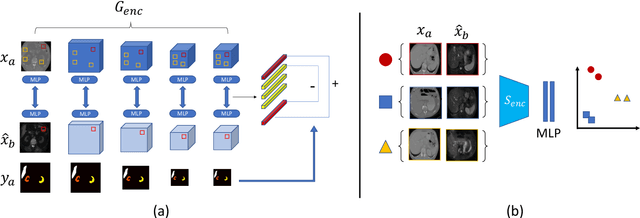
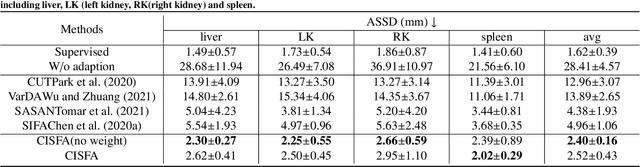
This work presents a novel framework CISFA (Contrastive Image synthesis and Self-supervised Feature Adaptation)that builds on image domain translation and unsupervised feature adaptation for cross-modality biomedical image segmentation. Different from existing works, we use a one-sided generative model and add a weighted patch-wise contrastive loss between sampled patches of the input image and the corresponding synthetic image, which serves as shape constraints. Moreover, we notice that the generated images and input images share similar structural information but are in different modalities. As such, we enforce contrastive losses on the generated images and the input images to train the encoder of a segmentation model to minimize the discrepancy between paired images in the learned embedding space. Compared with existing works that rely on adversarial learning for feature adaptation, such a method enables the encoder to learn domain-independent features in a more explicit way. We extensively evaluate our methods on segmentation tasks containing CT and MRI images for abdominal cavities and whole hearts. Experimental results show that the proposed framework not only outputs synthetic images with less distortion of organ shapes, but also outperforms state-of-the-art domain adaptation methods by a large margin.
Adaptive Feature Fusion for Cooperative Perception using LiDAR Point Clouds
Jul 30, 2022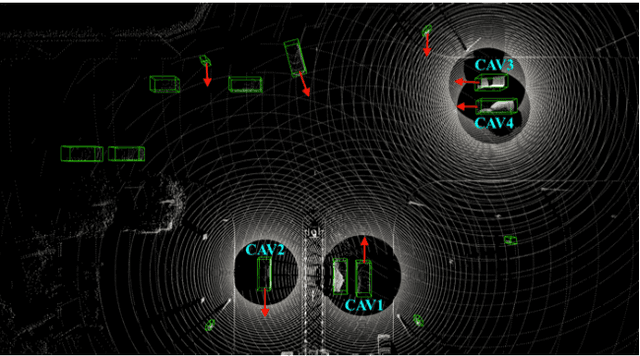
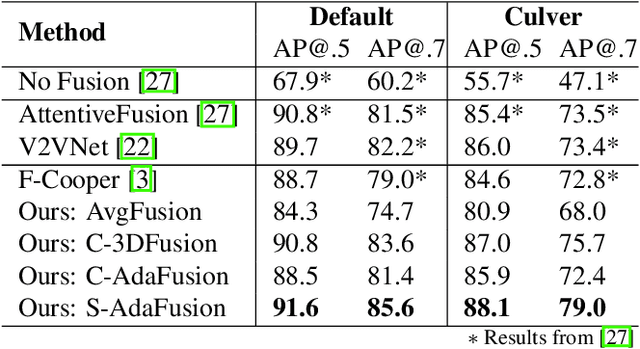
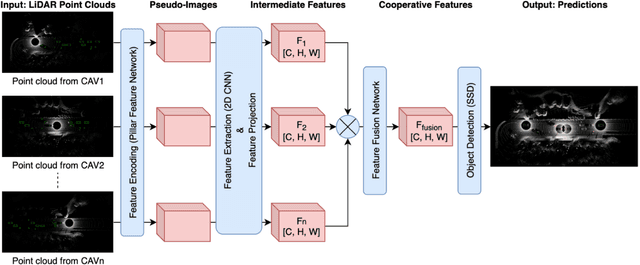
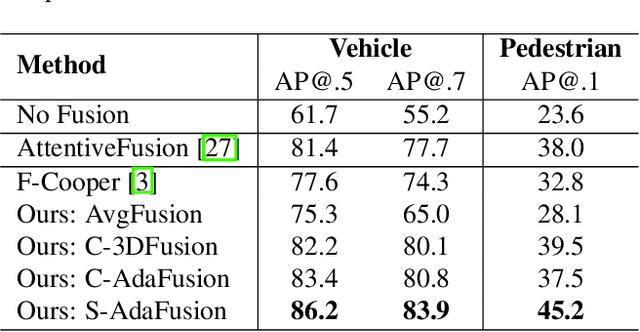
Cooperative perception allows a Connected Autonomous Vehicle (CAV) to interact with the other CAVs in the vicinity to enhance perception of surrounding objects to increase safety and reliability. It can compensate for the limitations of the conventional vehicular perception such as blind spots, low resolution, and weather effects. An effective feature fusion model for the intermediate fusion methods of cooperative perception can improve feature selection and information aggregation to further enhance the perception accuracy. We propose adaptive feature fusion models with trainable feature selection modules. One of our proposed models Spatial-wise Adaptive feature Fusion (S-AdaFusion) outperforms all other state-of-the-art models on the two subsets of OPV2V dataset: default CARLA towns for vehicle detection and the Culver City for domain adaptation. In addition, previous studies have only tested cooperative perception for vehicle detection. A pedestrian, however, is much more likely to be seriously injured in a traffic accident. We evaluate the performance of cooperative perception for both vehicle and pedestrian detection using the CODD dataset. Our architecture achieves higher Average Precision (AP) than other existing models for both vehicle and pedestrian detection on the CODD dataset. The experiments demonstrate that cooperative perception also can improve the pedestrian detection accuracy compared to the conventional perception process.
Searching for the Essence of Adversarial Perturbations
May 30, 2022


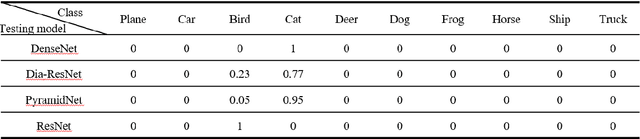
Neural networks have achieved the state-of-the-art performance on various machine learning fields, yet the incorporation of malicious perturbations with input data (adversarial example) is able to fool neural networks' predictions. This would lead to potential risks in real-world applications, for example, auto piloting and facial recognition. However, the reason for the existence of adversarial examples remains controversial. Here we demonstrate that adversarial perturbations contain human-recognizable information, which is the key conspirator responsible for a neural network's erroneous prediction. This concept of human-recognizable information allows us to explain key features related to adversarial perturbations, which include the existence of adversarial examples, the transferability among different neural networks, and the increased neural network interpretability for adversarial training. Two unique properties in adversarial perturbations that fool neural networks are uncovered: masking and generation. A special class, the complementary class, is identified when neural networks classify input images. The human-recognizable information contained in adversarial perturbations allows researchers to gain insight on the working principles of neural networks and may lead to develop techniques that detect/defense adversarial attacks.
High-Resolution Swin Transformer for Automatic Medical Image Segmentation
Jul 23, 2022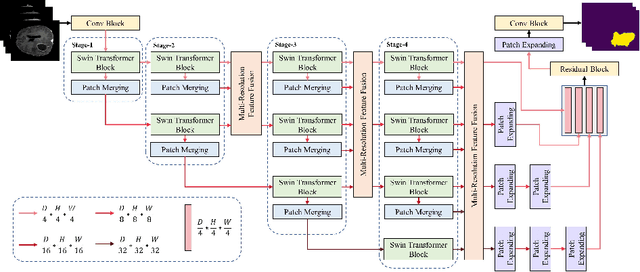
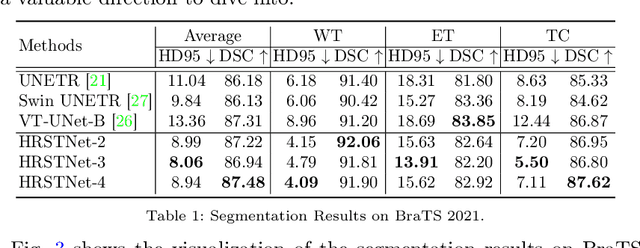
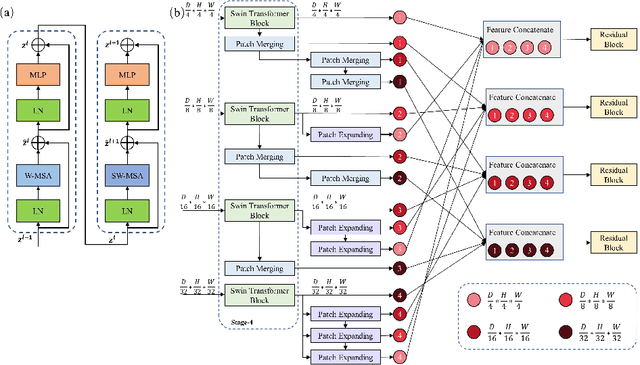
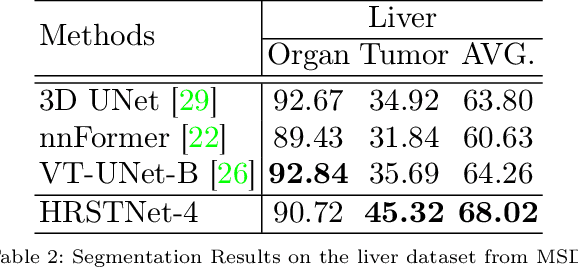
The Resolution of feature maps is critical for medical image segmentation. Most of the existing Transformer-based networks for medical image segmentation are U-Net-like architecture that contains an encoder that utilizes a sequence of Transformer blocks to convert the input medical image from high-resolution representation into low-resolution feature maps and a decoder that gradually recovers the high-resolution representation from low-resolution feature maps. Unlike previous studies, in this paper, we utilize the network design style from the High-Resolution Network (HRNet), replace the convolutional layers with Transformer blocks, and continuously exchange information from the different resolution feature maps that are generated by Transformer blocks. The newly Transformer-based network presented in this paper is denoted as High-Resolution Swin Transformer Network (HRSTNet). Extensive experiments illustrate that HRSTNet can achieve comparable performance with the state-of-the-art Transformer-based U-Net-like architecture on Brain Tumor Segmentation(BraTS) 2021 and the liver dataset from Medical Segmentation Decathlon. The code of HRSTNet will be publicly available at https://github.com/auroua/HRSTNet.
Volumetric Image Projection Super-Resolution Ultrasound (VIP-SR) with a 1D Unfocused Linear Array
Jun 08, 2022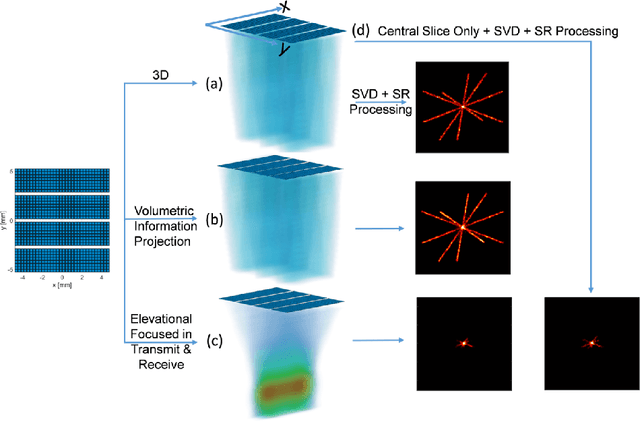
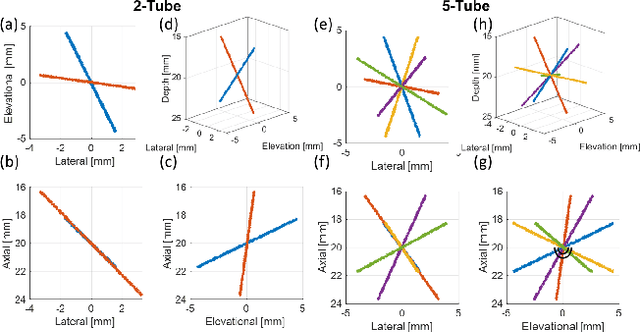
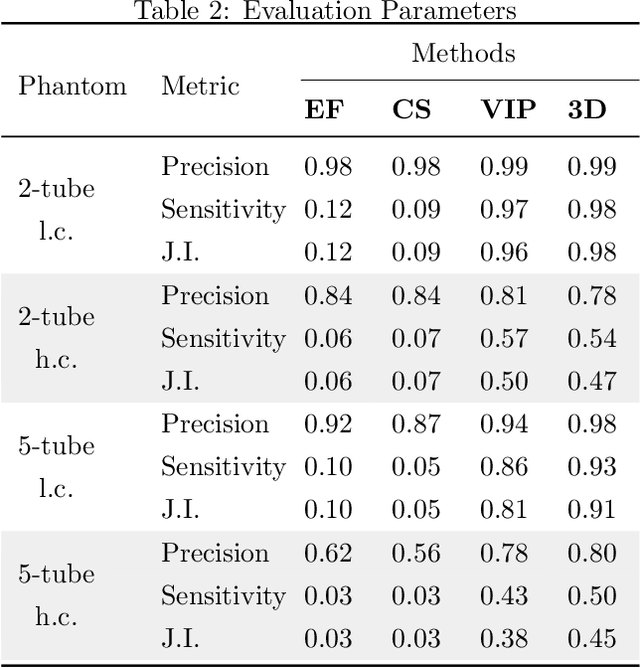
Super-Resolution Ultrasound (SRUS) through localizing spatially isolated microbubbles has been demonstrated to overcome the wave diffraction limit and reveal the microvascular structure and flow information at the microscopic scale. However, 3D SRUS imaging remains a challenge due to the fabrication and computational complexity of 2D matrix array probes and connections. Inspired by X-ray radiography which can present volumetric information in a single projection image with much simpler hardware than X-ray CT, this study investigates the feasibility of volumetric image projection super-resolution (VIP-SR) ultrasound using a 1D unfocused linear array. Both simulation and experiments were conducted on 3D microvessel phantoms using a 1D linear array with or without an elevational focus, and a 2D matrix array as the reference. Results show that, VIP-SR, using an unfocused 1D array probe can capture significantly more volumetric information than the conventional 1D elevational focused probe. Compared with the 2D projection image of the full 3D SRUS results using the 2D array probe with the same aperture size, VIP-SR has similar volumetric coverage using 32 folds less independent elements. The impact of bubble concentration and vascular density on the VIP-SR US was also investigated. This study demonstrates the ability of high-resolution volumetric imaging of microvascular structures at significantly reduced costs with VIP-SR.
Improved Pancreatic Tumor Detection by Utilizing Clinically-Relevant Secondary Features
Aug 06, 2022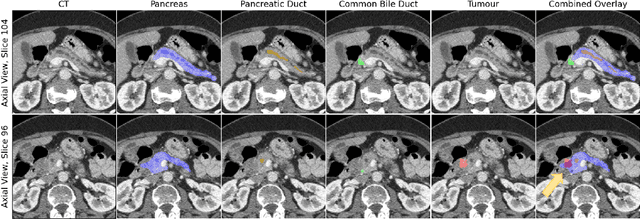
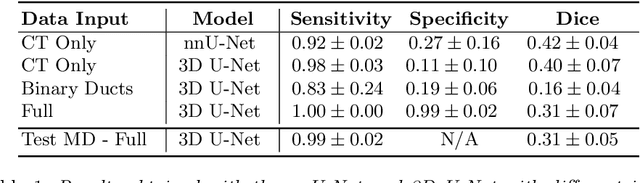
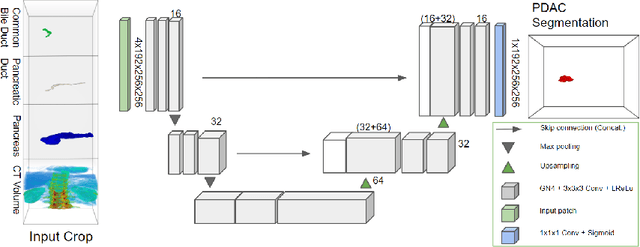

Pancreatic cancer is one of the global leading causes of cancer-related deaths. Despite the success of Deep Learning in computer-aided diagnosis and detection (CAD) methods, little attention has been paid to the detection of Pancreatic Cancer. We propose a method for detecting pancreatic tumor that utilizes clinically-relevant features in the surrounding anatomical structures, thereby better aiming to exploit the radiologist's knowledge compared to other, conventional deep learning approaches. To this end, we collect a new dataset consisting of 99 cases with pancreatic ductal adenocarcinoma (PDAC) and 97 control cases without any pancreatic tumor. Due to the growth pattern of pancreatic cancer, the tumor may not be always visible as a hypodense lesion, therefore experts refer to the visibility of secondary external features that may indicate the presence of the tumor. We propose a method based on a U-Net-like Deep CNN that exploits the following external secondary features: the pancreatic duct, common bile duct and the pancreas, along with a processed CT scan. Using these features, the model segments the pancreatic tumor if it is present. This segmentation for classification and localization approach achieves a performance of 99% sensitivity (one case missed) and 99% specificity, which realizes a 5% increase in sensitivity over the previous state-of-the-art method. The model additionally provides location information with reasonable accuracy and a shorter inference time compared to previous PDAC detection methods. These results offer a significant performance improvement and highlight the importance of incorporating the knowledge of the clinical expert when developing novel CAD methods.