 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom A to B to A: Palindromic Zero-Shot Voice Conversion with Non-Parallel Data
Jun 07, 2026We present a voice conversion (VC) framework that utilizes K-Nearest Neighbors (KNN) retrieval over WavLM representations to align non-parallel source and target speech, constructing synthetic training pairs for supervised learning. The retrieved segments serve as synthetic inputs, while real target audio provides ground-truth outputs, forming a synthetic-to-real training paradigm that naturally supports multilingual data without requiring parallel corpora or explicit alignment. To ensure consistent target-speaker identity, we incorporate a speaker loss derived from a pretrained speaker verification model. Experiments across multiple languages demonstrate that the proposed approach achieves high naturalness and strong speaker similarity, outperforming competitive VC baselines, despite being trained exclusively on English data. Samples can be accessed at: https://palindromic-vc.github.io.
AERO: Audio Super Resolution in the Spectral Domain
Nov 22, 2022We present AERO, a audio super-resolution model that processes speech and music signals in the spectral domain. AERO is based on an encoder-decoder architecture with U-Net like skip connections. We optimize the model using both time and frequency domain loss functions. Specifically, we consider a set of reconstruction losses together with perceptual ones in the form of adversarial and feature discriminator loss functions. To better handle phase information the proposed method operates over the complex-valued spectrogram using two separate channels. Unlike prior work which mainly considers low and high frequency concatenation for audio super-resolution, the proposed method directly predicts the full frequency range. We demonstrate high performance across a wide range of sample rates considering both speech and music. AERO outperforms the evaluated baselines considering Log-Spectral Distance, ViSQOL, and the subjective MUSHRA test. Audio samples and code are available at https://pages.cs.huji.ac.il/adiyoss-lab/aero
A Systematic Comparison of Phonetic Aware Techniques for Speech Enhancement
Jun 22, 2022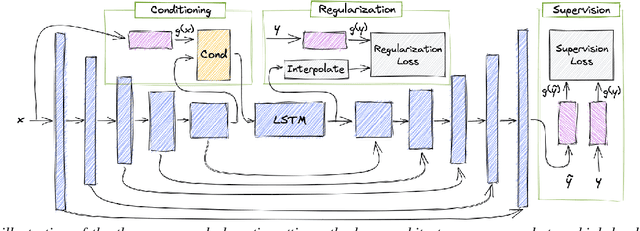
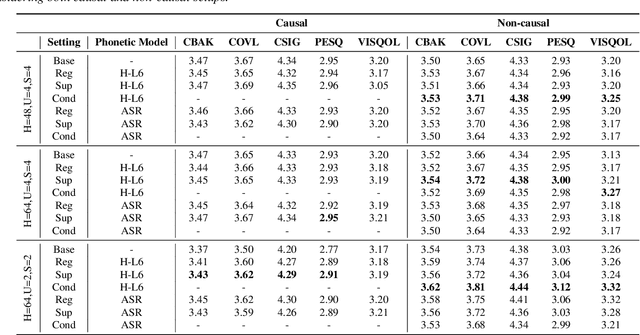
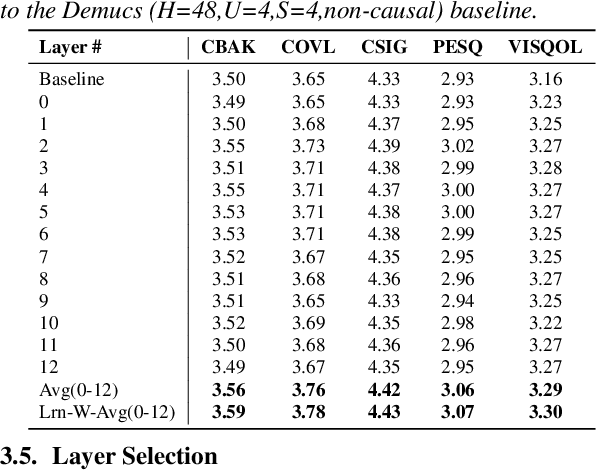
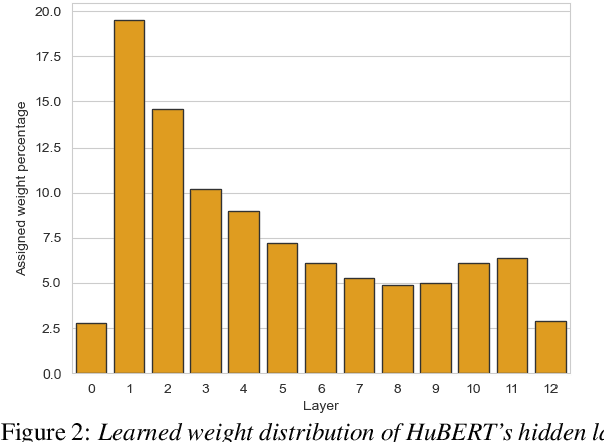
Speech enhancement has seen great improvement in recent years using end-to-end neural networks. However, most models are agnostic to the spoken phonetic content. Recently, several studies suggested phonetic-aware speech enhancement, mostly using perceptual supervision. Yet, injecting phonetic features during model optimization can take additional forms (e.g., model conditioning). In this paper, we conduct a systematic comparison between different methods of incorporating phonetic information in a speech enhancement model. By conducting a series of controlled experiments, we observe the influence of different phonetic content models as well as various feature-injection techniques on enhancement performance, considering both causal and non-causal models. Specifically, we evaluate three settings for injecting phonetic information, namely: i) feature conditioning; ii) perceptual supervision; and iii) regularization. Phonetic features are obtained using an intermediate layer of either a supervised pre-trained Automatic Speech Recognition (ASR) model or by using a pre-trained Self-Supervised Learning (SSL) model. We further observe the effect of choosing different embedding layers on performance, considering both manual and learned configurations. Results suggest that using a SSL model as phonetic features outperforms the ASR one in most cases. Interestingly, the conditioning setting performs best among the evaluated configurations.