 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-Regressive vs Flow-Matching: a Comparative Study of Modeling Paradigms for Text-to-Music Generation
Jun 11, 2025Recent progress in text-to-music generation has enabled models to synthesize high-quality musical segments, full compositions, and even respond to fine-grained control signals, e.g. chord progressions. State-of-the-art (SOTA) systems differ significantly across many dimensions, such as training datasets, modeling paradigms, and architectural choices. This diversity complicates efforts to evaluate models fairly and pinpoint which design choices most influence performance. While factors like data and architecture are important, in this study we focus exclusively on the modeling paradigm. We conduct a systematic empirical analysis to isolate its effects, offering insights into associated trade-offs and emergent behaviors that can guide future text-to-music generation systems. Specifically, we compare the two arguably most common modeling paradigms: Auto-Regressive decoding and Conditional Flow-Matching. We conduct a controlled comparison by training all models from scratch using identical datasets, training configurations, and similar backbone architectures. Performance is evaluated across multiple axes, including generation quality, robustness to inference configurations, scalability, adherence to both textual and temporally aligned conditioning, and editing capabilities in the form of audio inpainting. This comparative study sheds light on distinct strengths and limitations of each paradigm, providing actionable insights that can inform future architectural and training decisions in the evolving landscape of text-to-music generation. Audio sampled examples are available at: https://huggingface.co/spaces/ortal1602/ARvsFM
PAST: Phonetic-Acoustic Speech Tokenizer
May 20, 2025We present PAST, a novel end-to-end framework that jointly models phonetic information alongside signal reconstruction, eliminating the need for external pretrained models. Unlike previous approaches that rely on pretrained self-supervised models, PAST employs supervised phonetic data, directly integrating domain knowledge into the tokenization process via auxiliary tasks. Additionally, we introduce a streamable, causal variant of PAST, enabling real-time speech applications. Results demonstrate that PAST surpasses existing evaluated baseline tokenizers across common evaluation metrics, including phonetic representation and speech reconstruction. Notably, PAST also achieves superior performance when serving as a speech representation for speech language models, further highlighting its effectiveness as a foundation for spoken language generation. To foster further research, we release the full implementation. For code, model checkpoints, and samples see: https://pages.cs.huji.ac.il/adiyoss-lab/PAST
Enhancing TTS Stability in Hebrew using Discrete Semantic Units
Oct 28, 2024This study introduces a refined approach to Text-to-Speech (TTS) generation that significantly enhances sampling stability across languages, with a particular focus on Hebrew. By leveraging discrete semantic units with higher phonetic correlation obtained from a self-supervised model, our method addresses the inherent instability often encountered in TTS systems, especially those dealing with non-diacriticized scripts like Hebrew. Utilizing HuBERT codes, our model generates discrete representations that are optimized for TTS tasks, thereby reducing the dependency on diacritic-based text processing. This advancement not only simplifies the language modeling process but also improves the robustness and shows controllability of the speech output due to disentenglement properties of the semantic units. The inclusion of a speaker embedding in the vocoder further aids in capturing the unique vocal characteristics of the speaker, contributing to the naturalness of the synthesized speech. Our experimental results demonstrate that this approach not only maintains high performance in Hebrew but also shows adaptability to English, underscoring its effectiveness in enhancing stability in TTS systems universally. Our method, named LOTHM (Language of The Hebrew Man), outperforms existing methods in terms of stability while achieving naturalness and speaker similarity on par with previous methods, making it a compelling choice for future speech synthesis applications. Samples can be found in our page pages.cs.huji.ac.il/adiyoss-lab/LoTHM .
HebDB: a Weakly Supervised Dataset for Hebrew Speech Processing
Jul 10, 2024We present HebDB, a weakly supervised dataset for spoken language processing in the Hebrew language. HebDB offers roughly 2500 hours of natural and spontaneous speech recordings in the Hebrew language, consisting of a large variety of speakers and topics. We provide raw recordings together with a pre-processed, weakly supervised, and filtered version. The goal of HebDB is to further enhance research and development of spoken language processing tools for the Hebrew language. Hence, we additionally provide two baseline systems for Automatic Speech Recognition (ASR): (i) a self-supervised model; and (ii) a fully supervised model. We present the performance of these two methods optimized on HebDB and compare them to current multi-lingual ASR alternatives. Results suggest the proposed method reaches better results than the evaluated baselines considering similar model sizes. Dataset, code, and models are publicly available under https://pages.cs.huji.ac.il/adiyoss-lab/HebDB/.
Joint Audio and Symbolic Conditioning for Temporally Controlled Text-to-Music Generation
Jun 16, 2024We present JASCO, a temporally controlled text-to-music generation model utilizing both symbolic and audio-based conditions. JASCO can generate high-quality music samples conditioned on global text descriptions along with fine-grained local controls. JASCO is based on the Flow Matching modeling paradigm together with a novel conditioning method. This allows music generation controlled both locally (e.g., chords) and globally (text description). Specifically, we apply information bottleneck layers in conjunction with temporal blurring to extract relevant information with respect to specific controls. This allows the incorporation of both symbolic and audio-based conditions in the same text-to-music model. We experiment with various symbolic control signals (e.g., chords, melody), as well as with audio representations (e.g., separated drum tracks, full-mix). We evaluate JASCO considering both generation quality and condition adherence, using both objective metrics and human studies. Results suggest that JASCO is comparable to the evaluated baselines considering generation quality while allowing significantly better and more versatile controls over the generated music. Samples are available on our demo page https://pages.cs.huji.ac.il/adiyoss-lab/JASCO.
AERO: Audio Super Resolution in the Spectral Domain
Nov 22, 2022We present AERO, a audio super-resolution model that processes speech and music signals in the spectral domain. AERO is based on an encoder-decoder architecture with U-Net like skip connections. We optimize the model using both time and frequency domain loss functions. Specifically, we consider a set of reconstruction losses together with perceptual ones in the form of adversarial and feature discriminator loss functions. To better handle phase information the proposed method operates over the complex-valued spectrogram using two separate channels. Unlike prior work which mainly considers low and high frequency concatenation for audio super-resolution, the proposed method directly predicts the full frequency range. We demonstrate high performance across a wide range of sample rates considering both speech and music. AERO outperforms the evaluated baselines considering Log-Spectral Distance, ViSQOL, and the subjective MUSHRA test. Audio samples and code are available at https://pages.cs.huji.ac.il/adiyoss-lab/aero
A Systematic Comparison of Phonetic Aware Techniques for Speech Enhancement
Jun 22, 2022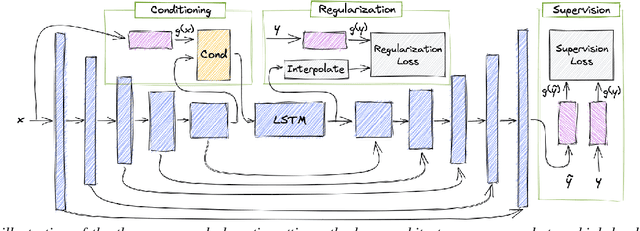
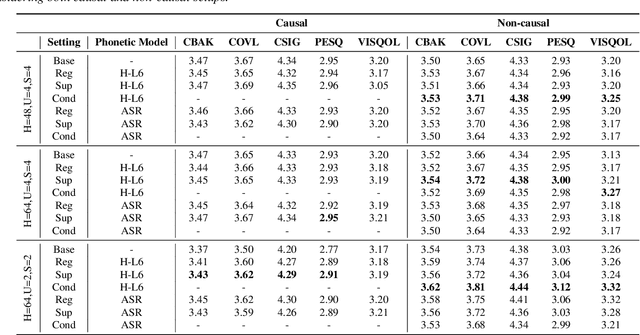
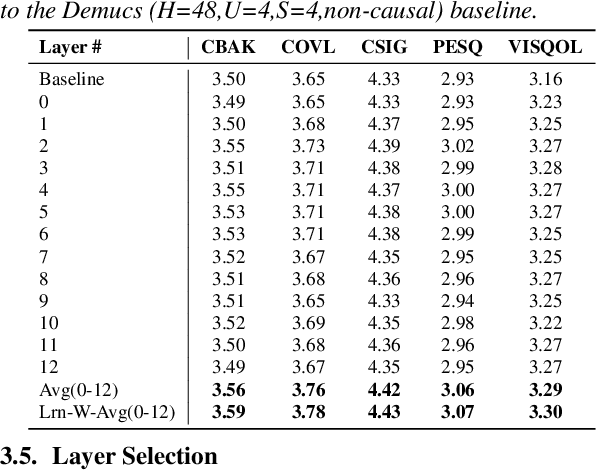
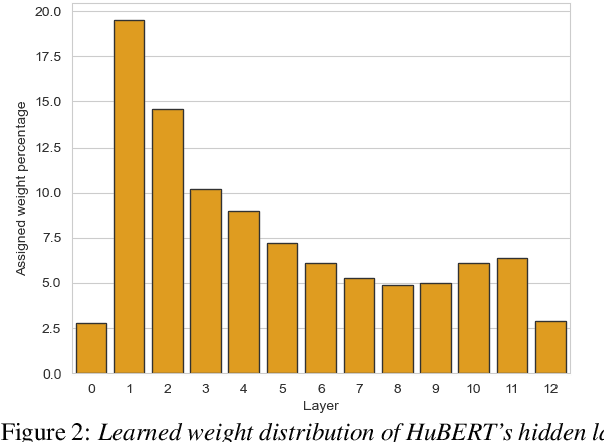
Speech enhancement has seen great improvement in recent years using end-to-end neural networks. However, most models are agnostic to the spoken phonetic content. Recently, several studies suggested phonetic-aware speech enhancement, mostly using perceptual supervision. Yet, injecting phonetic features during model optimization can take additional forms (e.g., model conditioning). In this paper, we conduct a systematic comparison between different methods of incorporating phonetic information in a speech enhancement model. By conducting a series of controlled experiments, we observe the influence of different phonetic content models as well as various feature-injection techniques on enhancement performance, considering both causal and non-causal models. Specifically, we evaluate three settings for injecting phonetic information, namely: i) feature conditioning; ii) perceptual supervision; and iii) regularization. Phonetic features are obtained using an intermediate layer of either a supervised pre-trained Automatic Speech Recognition (ASR) model or by using a pre-trained Self-Supervised Learning (SSL) model. We further observe the effect of choosing different embedding layers on performance, considering both manual and learned configurations. Results suggest that using a SSL model as phonetic features outperforms the ASR one in most cases. Interestingly, the conditioning setting performs best among the evaluated configurations.