 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SIGN: Spatial-information Incorporated Generative Network for Generalized Zero-shot Semantic Segmentation
Aug 27, 2021
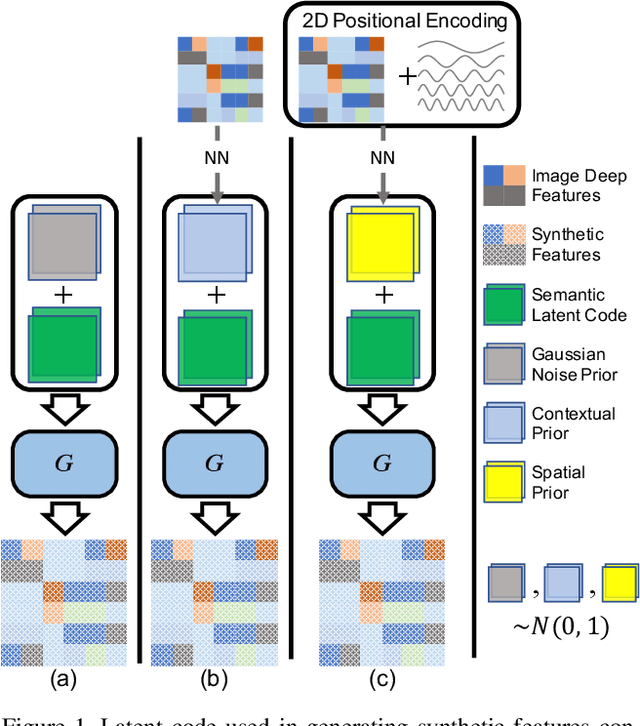
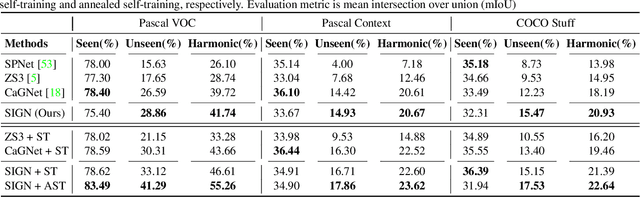
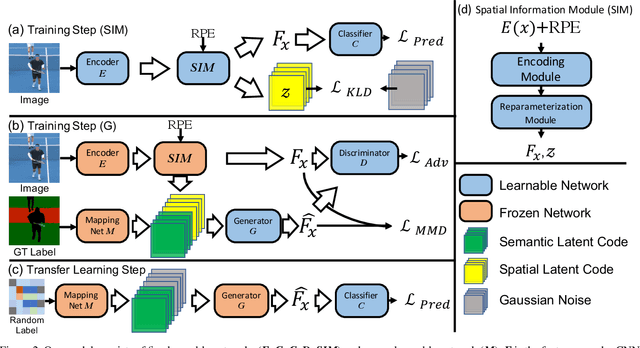
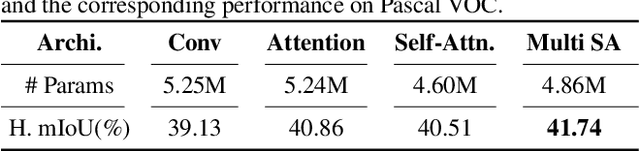
Unlike conventional zero-shot classification, zero-shot semantic segmentation predicts a class label at the pixel level instead of the image level. When solving zero-shot semantic segmentation problems, the need for pixel-level prediction with surrounding context motivates us to incorporate spatial information using positional encoding. We improve standard positional encoding by introducing the concept of Relative Positional Encoding, which integrates spatial information at the feature level and can handle arbitrary image sizes. Furthermore, while self-training is widely used in zero-shot semantic segmentation to generate pseudo-labels, we propose a new knowledge-distillation-inspired self-training strategy, namely Annealed Self-Training, which can automatically assign different importance to pseudo-labels to improve performance. We systematically study the proposed Relative Positional Encoding and Annealed Self-Training in a comprehensive experimental evaluation, and our empirical results confirm the effectiveness of our method on three benchmark datasets.
Efficient Utility Function Learning for Multi-Objective Parameter Optimization with Prior Knowledge
Aug 22, 2022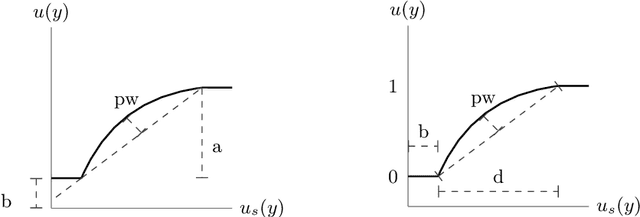

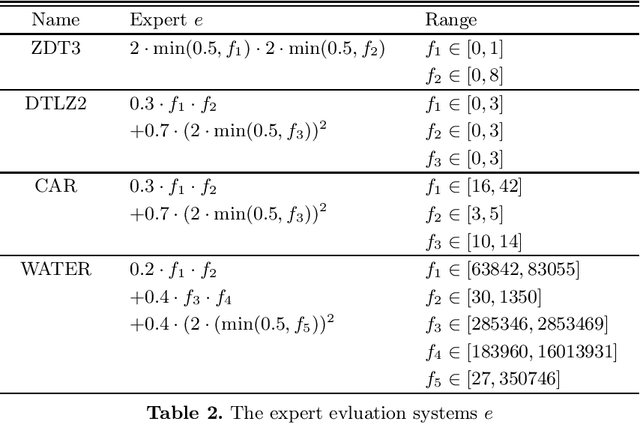
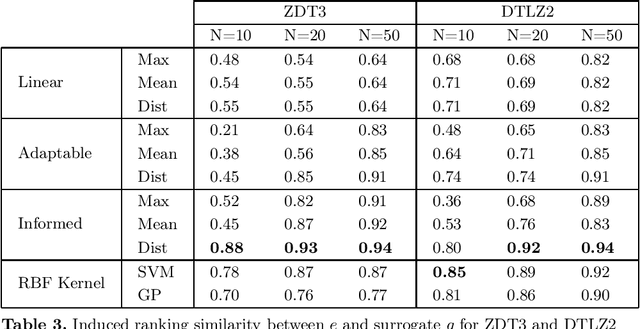
The current state-of-the-art in multi-objective optimization assumes either a given utility function, learns a utility function interactively or tries to determine the complete Pareto front, requiring a post elicitation of the preferred result. However, result elicitation in real world problems is often based on implicit and explicit expert knowledge, making it difficult to define a utility function, whereas interactive learning or post elicitation requires repeated and expensive expert involvement. To mitigate this, we learn a utility function offline, using expert knowledge by means of preference learning. In contrast to other works, we do not only use (pairwise) result preferences, but also coarse information about the utility function space. This enables us to improve the utility function estimate, especially when using very few results. Additionally, we model the occurring uncertainties in the utility function learning task and propagate them through the whole optimization chain. Our method to learn a utility function eliminates the need of repeated expert involvement while still leading to high-quality results. We show the sample efficiency and quality gains of the proposed method in 4 domains, especially in cases where the surrogate utility function is not able to exactly capture the true expert utility function. We also show that to obtain good results, it is important to consider the induced uncertainties and analyze the effect of biased samples, which is a common problem in real world domains.
Learning Branched Fusion and Orthogonal Projection for Face-Voice Association
Aug 22, 2022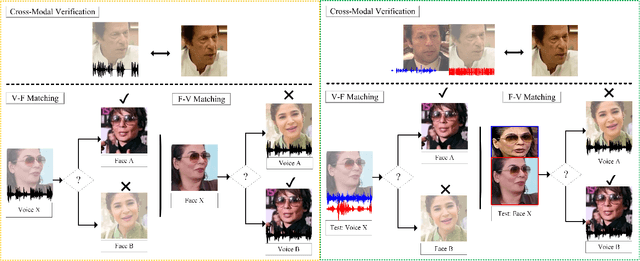
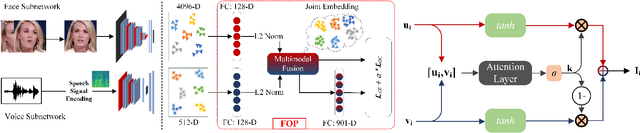
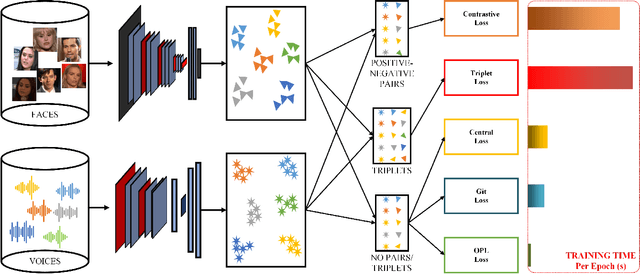
Recent years have seen an increased interest in establishing association between faces and voices of celebrities leveraging audio-visual information from YouTube. Prior works adopt metric learning methods to learn an embedding space that is amenable for associated matching and verification tasks. Albeit showing some progress, such formulations are, however, restrictive due to dependency on distance-dependent margin parameter, poor run-time training complexity, and reliance on carefully crafted negative mining procedures. In this work, we hypothesize that an enriched representation coupled with an effective yet efficient supervision is important towards realizing a discriminative joint embedding space for face-voice association tasks. To this end, we propose a light-weight, plug-and-play mechanism that exploits the complementary cues in both modalities to form enriched fused embeddings and clusters them based on their identity labels via orthogonality constraints. We coin our proposed mechanism as fusion and orthogonal projection (FOP) and instantiate in a two-stream network. The overall resulting framework is evaluated on VoxCeleb1 and MAV-Celeb datasets with a multitude of tasks, including cross-modal verification and matching. Results reveal that our method performs favourably against the current state-of-the-art methods and our proposed formulation of supervision is more effective and efficient than the ones employed by the contemporary methods. In addition, we leverage cross-modal verification and matching tasks to analyze the impact of multiple languages on face-voice association. Code is available: \url{https://github.com/msaadsaeed/FOP}
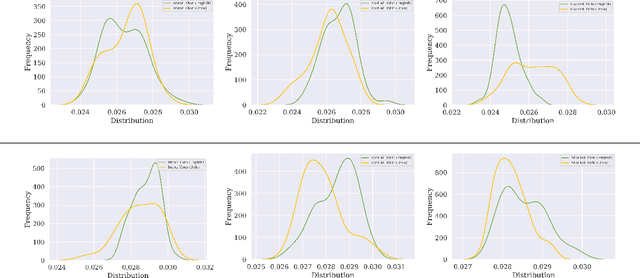
Meta-data Study in Autism Spectrum Disorder Classification Based on Structural MRI
Jun 09, 2022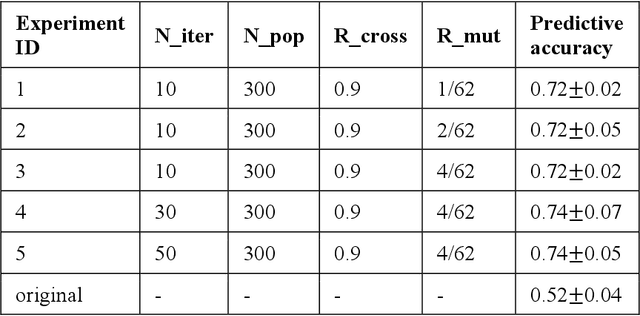
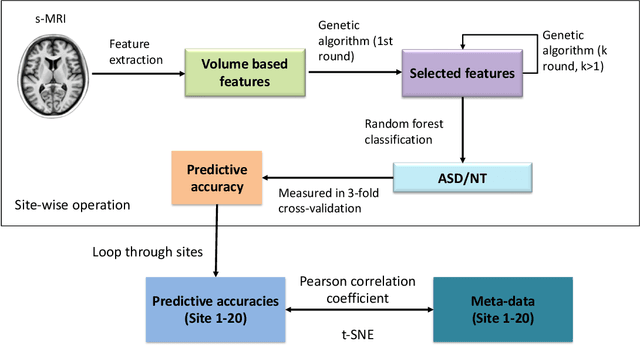
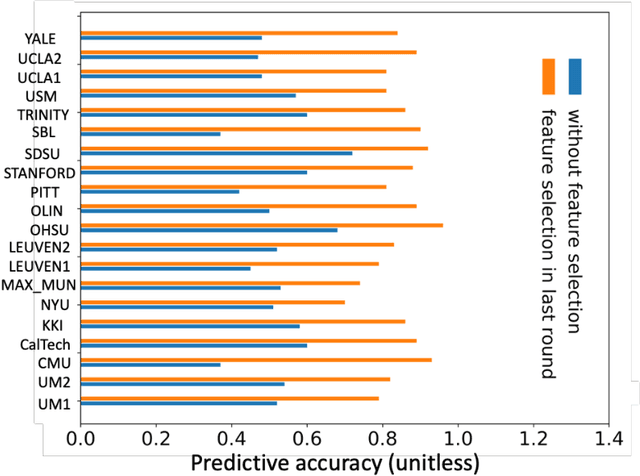
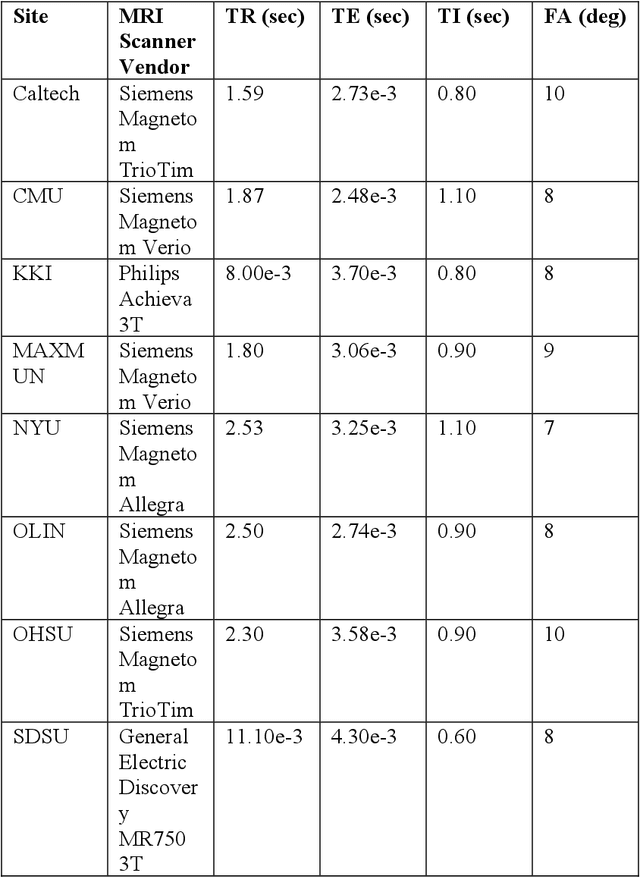
Accurate diagnosis of autism spectrum disorder (ASD) based on neuroimaging data has significant implications, as extracting useful information from neuroimaging data for ASD detection is challenging. Even though machine learning techniques have been leveraged to improve the information extraction from neuroimaging data, the varying data quality caused by different meta-data conditions (i.e., data collection strategies) limits the effective information that can be extracted, thus leading to data-dependent predictive accuracies in ASD detection, which can be worse than random guess in some cases. In this work, we systematically investigate the impact of three kinds of meta-data on the predictive accuracy of classifying ASD based on structural MRI collected from 20 different sites, where meta-data conditions vary.
A Temporal Extension of Latent Dirichlet Allocation for Unsupervised Acoustic Unit Discovery
Jun 23, 2022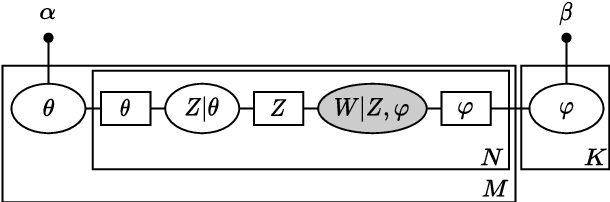
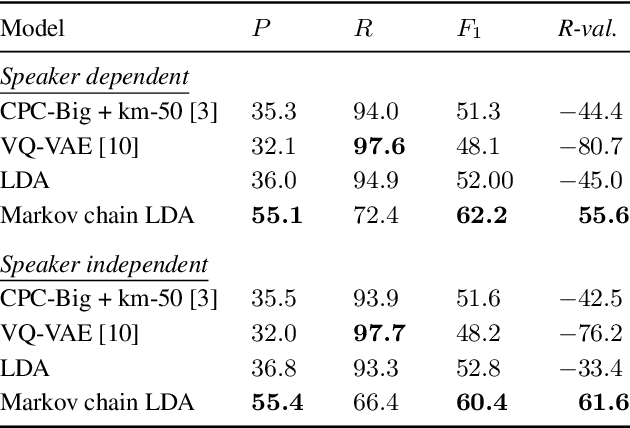
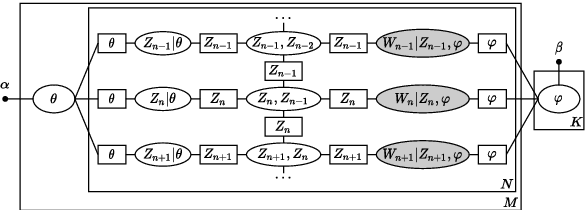
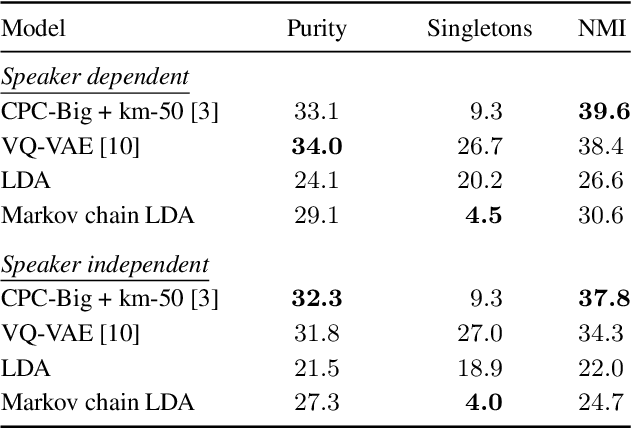
Latent Dirichlet allocation (LDA) is widely used for unsupervised topic modelling on sets of documents. No temporal information is used in the model. However, there is often a relationship between the corresponding topics of consecutive tokens. In this paper, we present an extension to LDA that uses a Markov chain to model temporal information. We use this new model for acoustic unit discovery from speech. As input tokens, the model takes a discretised encoding of speech from a vector quantised (VQ) neural network with 512 codes. The goal is then to map these 512 VQ codes to 50 phone-like units (topics) in order to more closely resemble true phones. In contrast to the base LDA, which only considers how VQ codes co-occur within utterances (documents), the Markov chain LDA additionally captures how consecutive codes follow one another. This extension leads to an increase in cluster quality and phone segmentation results compared to the base LDA. Compared to a recent vector quantised neural network approach that also learns 50 units, the extended LDA model performs better in phone segmentation but worse in mutual information.
Knowledge Graph Construction and Its Application in Automatic Radiology Report Generation from Radiologist's Dictation
Jun 14, 2022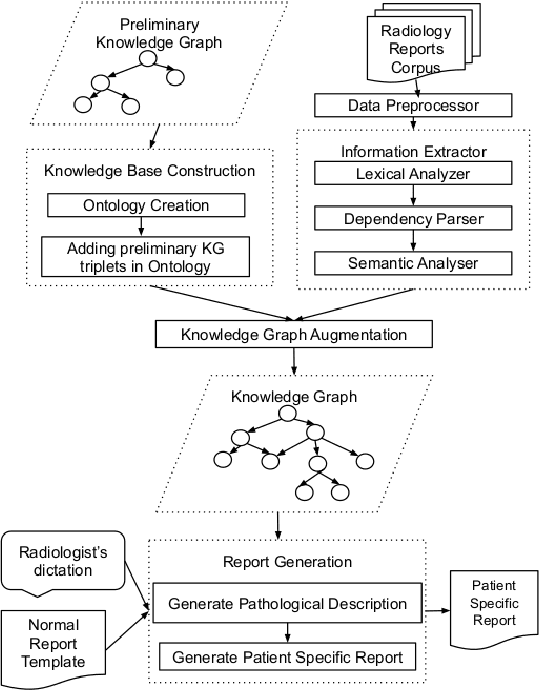
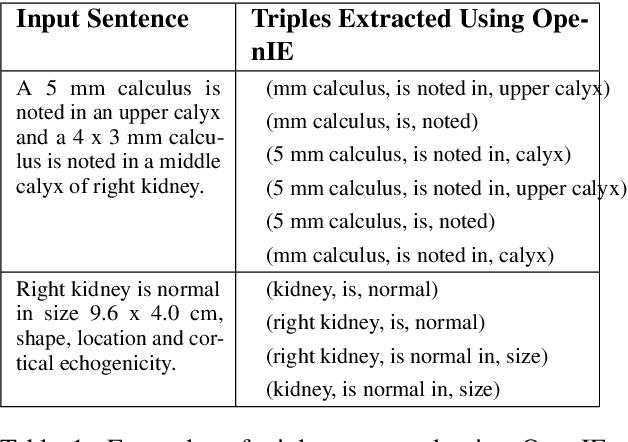
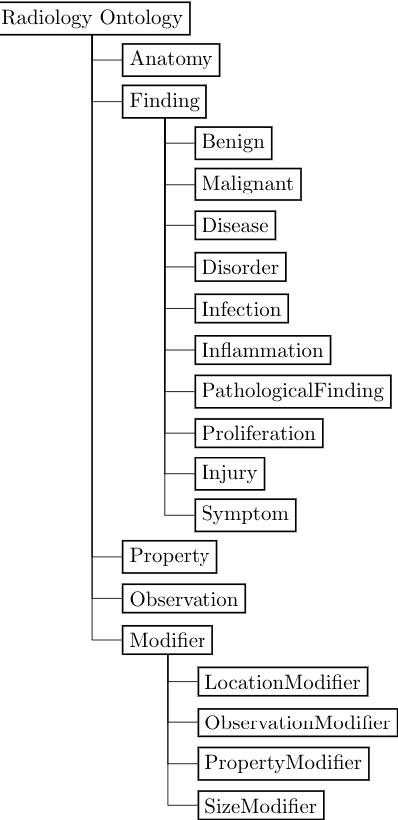

Conventionally, the radiologist prepares the diagnosis notes and shares them with the transcriptionist. Then the transcriptionist prepares a preliminary formatted report referring to the notes, and finally, the radiologist reviews the report, corrects the errors, and signs off. This workflow causes significant delays and errors in the report. In current research work, we focus on applications of NLP techniques like Information Extraction (IE) and domain-specific Knowledge Graph (KG) to automatically generate radiology reports from radiologist's dictation. This paper focuses on KG construction for each organ by extracting information from an existing large corpus of free-text radiology reports. We develop an information extraction pipeline that combines rule-based, pattern-based, and dictionary-based techniques with lexical-semantic features to extract entities and relations. Missing information in short dictation can be accessed from the KGs to generate pathological descriptions and hence the radiology report. Generated pathological descriptions evaluated using semantic similarity metrics, which shows 97% similarity with gold standard pathological descriptions. Also, our analysis shows that our IE module is performing better than the OpenIE tool for the radiology domain. Furthermore, we include a manual qualitative analysis from radiologists, which shows that 80-85% of the generated reports are correctly written, and the remaining are partially correct.
Real-Time Massive MIMO Channel Prediction: A Combination of Deep Learning and NeuralProphet
Aug 11, 2022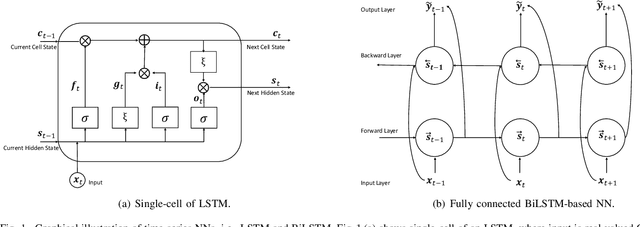
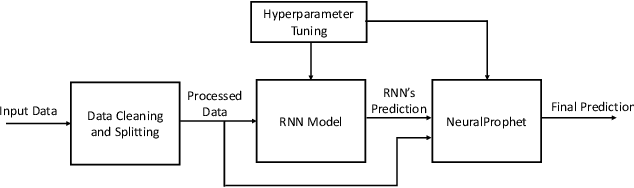
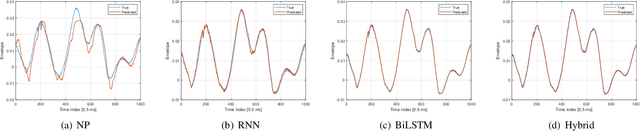
Channel state information (CSI) is of pivotal importance as it enables wireless systems to adapt transmission parameters more accurately, thus improving the system's overall performance. However, it becomes challenging to acquire accurate CSI in a highly dynamic environment, mainly due to multi-path fading. Inaccurate CSI can deteriorate the performance, particularly of a massive multiple-input multiple-output (mMIMO) system. This paper adapts machine learning (ML) for CSI prediction. Specifically, we exploit time-series models of deep learning (DL) such as recurrent neural network (RNN) and Bidirectional long-short term memory (BiLSTM). Further, we use NeuralProphet (NP), a recently introduced time-series model, composed of statistical components, e.g., auto-regression (AR) and Fourier terms, for CSI prediction. Inspired by statistical models, we also develop a novel hybrid framework comprising RNN and NP to achieve better prediction accuracy. The proposed channel predictors (CPs) performance is evaluated on a real-time dataset recorded at the Nokia Bell-Labs campus in Stuttgart, Germany. Numerical results show that DL brings performance gain when used with statistical models and showcases robustness.
Regret-Optimal Full-Information Control
May 04, 2021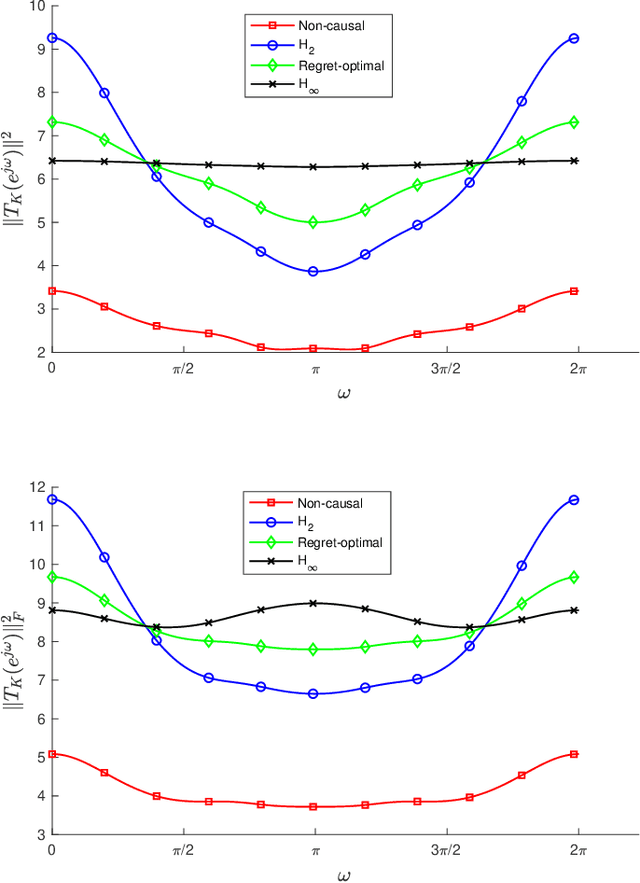
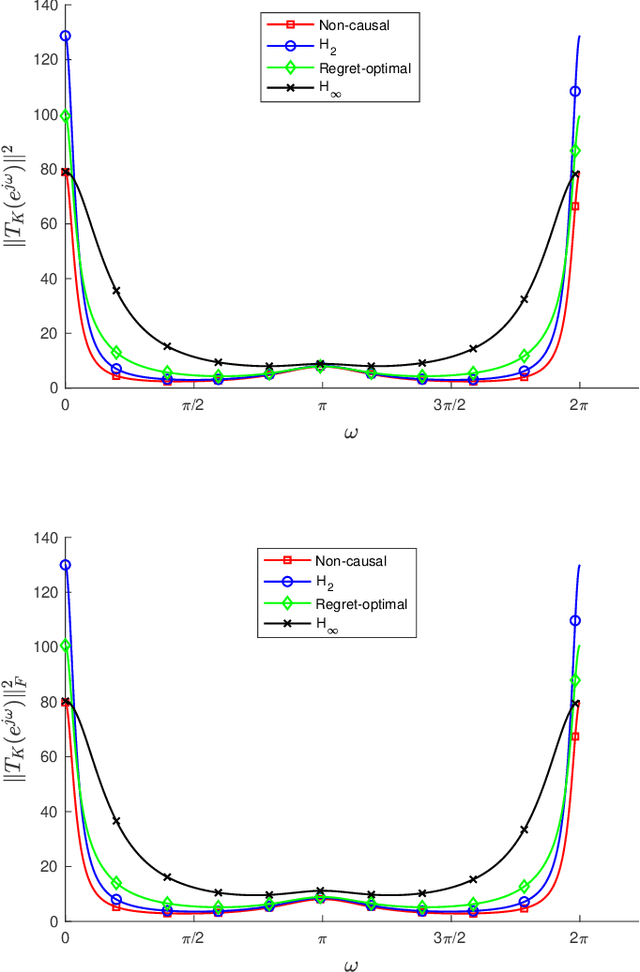
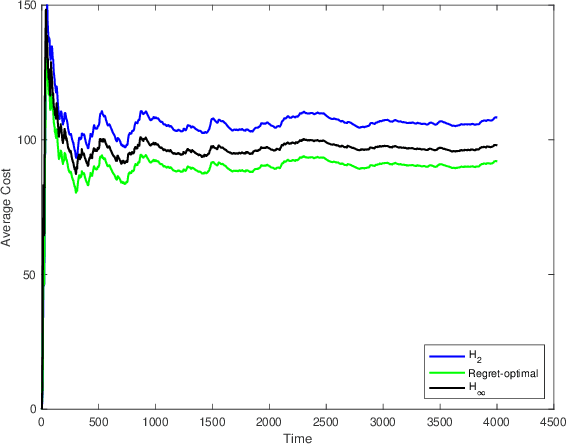
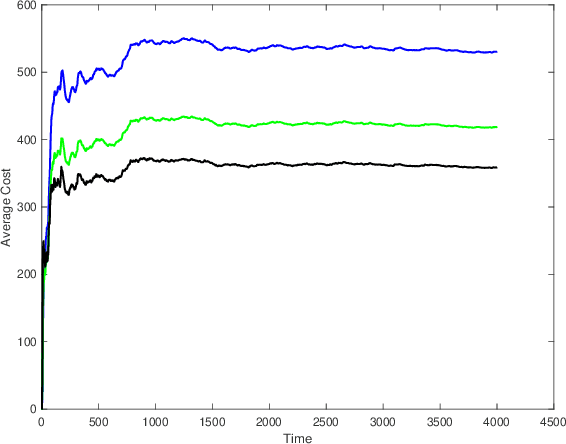
We consider the infinite-horizon, discrete-time full-information control problem. Motivated by learning theory, as a criterion for controller design we focus on regret, defined as the difference between the LQR cost of a causal controller (that has only access to past and current disturbances) and the LQR cost of a clairvoyant one (that has also access to future disturbances). In the full-information setting, there is a unique optimal non-causal controller that in terms of LQR cost dominates all other controllers. Since the regret itself is a function of the disturbances, we consider the worst-case regret over all possible bounded energy disturbances, and propose to find a causal controller that minimizes this worst-case regret. The resulting controller has the interpretation of guaranteeing the smallest possible regret compared to the best non-causal controller, no matter what the future disturbances are. We show that the regret-optimal control problem can be reduced to a Nehari problem, i.e., to approximate an anticausal operator with a causal one in the operator norm. In the state-space setting, explicit formulas for the optimal regret and for the regret-optimal controller (in both the causal and the strictly causal settings) are derived. The regret-optimal controller is the sum of the classical $H_2$ state-feedback law and a finite-dimensional controller obtained from the Nehari problem. The controller construction simply requires the solution to the standard LQR Riccati equation, in addition to two Lyapunov equations. Simulations over a range of plants demonstrates that the regret-optimal controller interpolates nicely between the $H_2$ and the $H_\infty$ optimal controllers, and generally has $H_2$ and $H_\infty$ costs that are simultaneously close to their optimal values. The regret-optimal controller thus presents itself as a viable option for control system design.
Measuring and Clustering Network Attackers using Medium-Interaction Honeypots
Jun 27, 2022
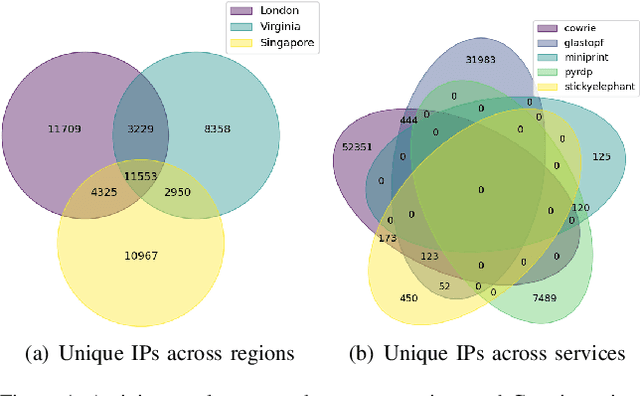
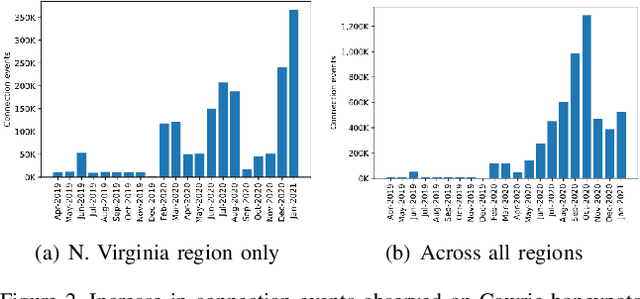
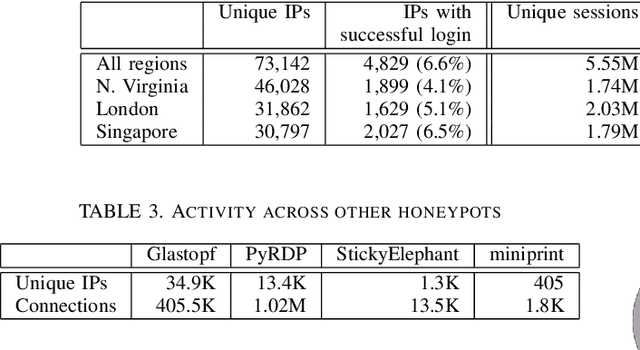
Network honeypots are often used by information security teams to measure the threat landscape in order to secure their networks. With the advancement of honeypot development, today's medium-interaction honeypots provide a way for security teams and researchers to deploy these active defense tools that require little maintenance on a variety of protocols. In this work, we deploy such honeypots on five different protocols on the public Internet and study the intent and sophistication of the attacks we observe. We then use the information gained to develop a clustering approach that identifies correlations in attacker behavior to discover IPs that are highly likely to be controlled by a single operator, illustrating the advantage of using these honeypots for data collection.
Community-based Cyberreading for Information Understanding
Mar 27, 2021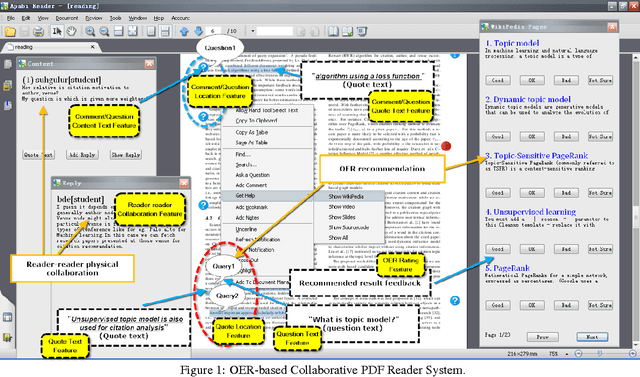
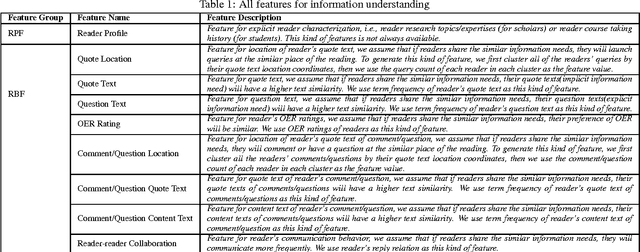
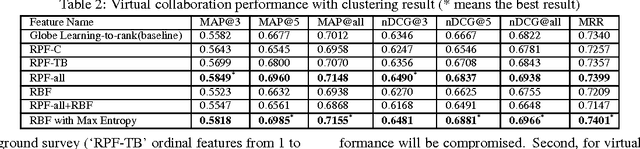
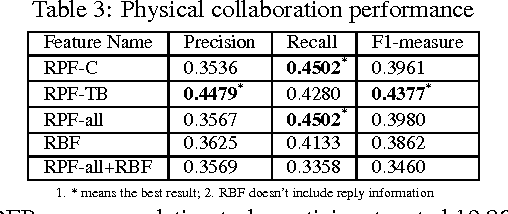
Although the content in scientific publications is increasingly challenging, it is necessary to investigate another important problem, that of scientific information understanding. For this proposed problem, we investigate novel methods to assist scholars (readers) to better understand scientific publications by enabling physical and virtual collaboration. For physical collaboration, an algorithm will group readers together based on their profiles and reading behavior, and will enable the cyberreading collaboration within a online reading group. For virtual collaboration, instead of pushing readers to communicate with others, we cluster readers based on their estimated information needs. For each cluster, a learning to rank model will be generated to recommend readers' communitized resources (i.e., videos, slides, and wikis) to help them understand the target publication.