 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Physics-Inspired Unsupervised Classification for Region of Interest in X-Ray Ptychography
Jun 29, 2022
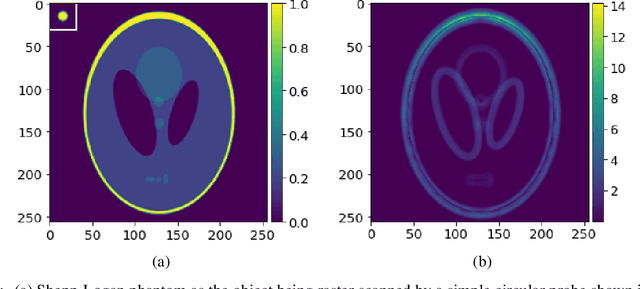
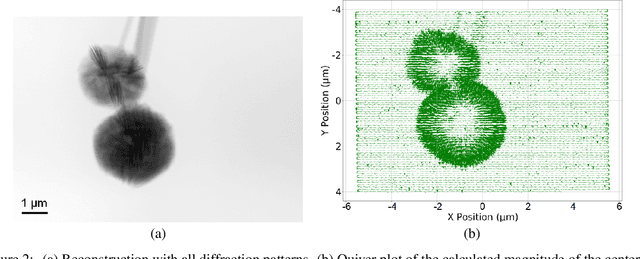
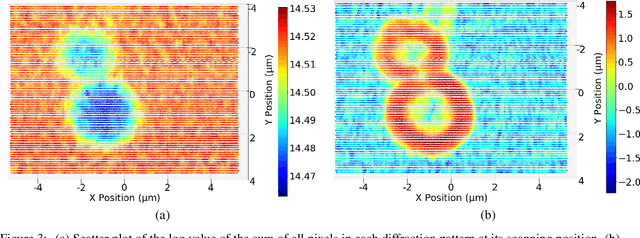
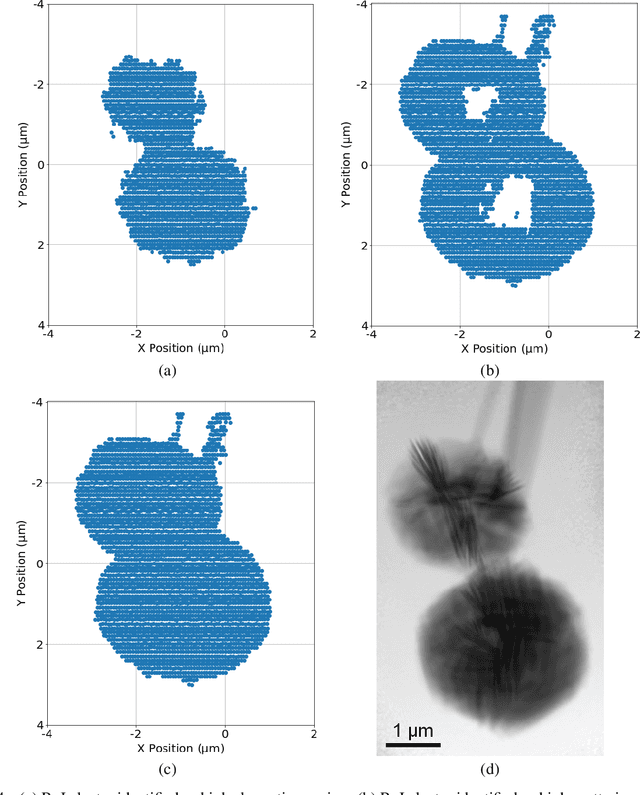
X-ray ptychography allows for large fields to be imaged at high resolution at the cost of additional computational expense due to the large volume of data. Given limited information regarding the object, the acquired data often has an excessive amount of information that is outside the region of interest (RoI). In this work we propose a physics-inspired unsupervised learning algorithm to identify the RoI of an object using only diffraction patterns from a ptychography dataset before committing computational resources to reconstruction. Obtained diffraction patterns that are automatically identified as not within the RoI are filtered out, allowing efficient reconstruction by focusing only on important data within the RoI while preserving image quality.
Treating Point Cloud as Moving Camera Videos: A No-Reference Quality Assessment Metric
Aug 30, 2022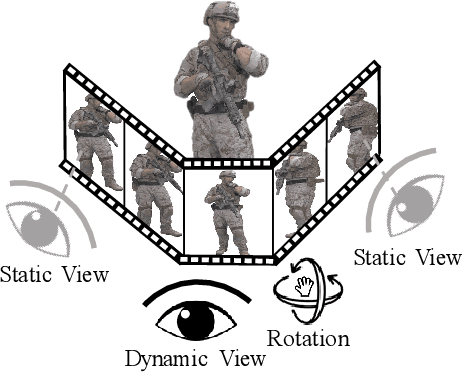

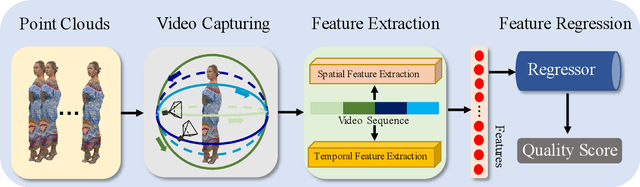
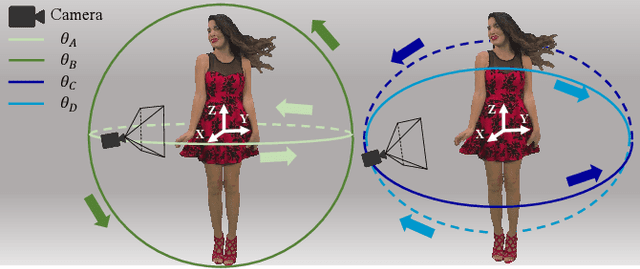
Point cloud is one of the most widely used digital representation formats for 3D contents, the visual quality of which may suffer from noise and geometric shift during the production procedure as well as compression and downsampling during the transmission process. To tackle the challenge of point cloud quality assessment (PCQA), many PCQA methods have been proposed to evaluate the visual quality levels of point clouds by assessing the rendered static 2D projections. Although such projection-based PCQA methods achieve competitive performance with the assistance of mature image quality assessment (IQA) methods, they neglect the dynamic quality-aware information, which does not fully match the fact that observers tend to perceive the point clouds through both static and dynamic views. Therefore, in this paper, we treat the point clouds as moving camera videos and explore the way of dealing with PCQA tasks via using video quality assessment (VQA) methods in a no-reference (NR) manner. First, we generate the captured videos by rotating the camera around the point clouds through four circular pathways. Then we extract both spatial and temporal quality-aware features from the selected key frames and the video clips by using trainable 2D-CNN and pre-trained 3D-CNN models respectively. Finally, the visual quality of point clouds is represented by the regressed video quality values. The experimental results reveal that the proposed method is effective for predicting the visual quality levels of the point clouds and even competitive with full-reference (FR) PCQA methods. The ablation studies further verify the rationality of the proposed framework and confirm the contributions made by the quality-aware features extracted from dynamic views.
A Comprehensive Review of Visual-Textual Sentiment Analysis from Social Media Networks
Jul 05, 2022
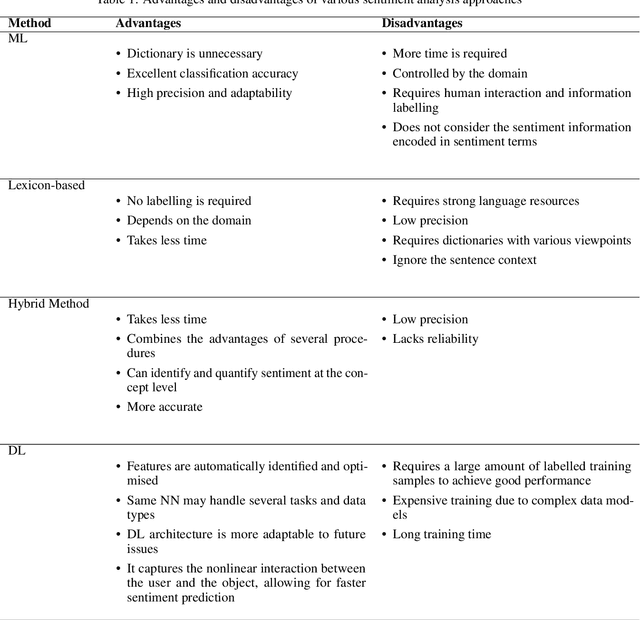
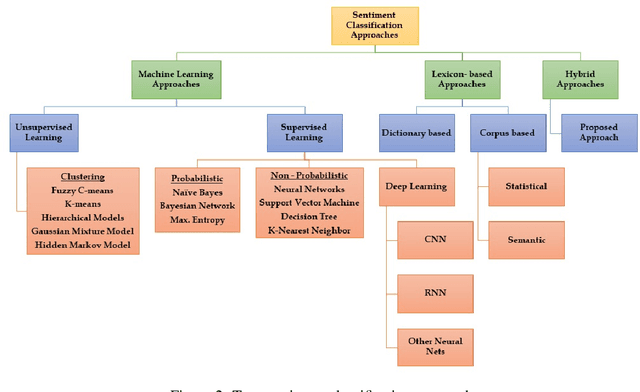
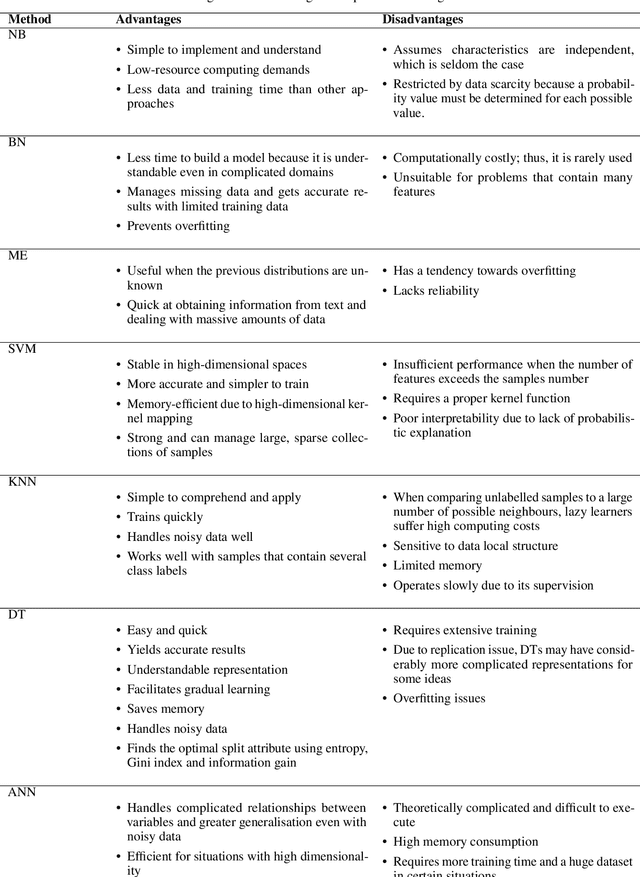
Social media networks have become a significant aspect of people's lives, serving as a platform for their ideas, opinions and emotions. Consequently, automated sentiment analysis (SA) is critical for recognising people's feelings in ways that other information sources cannot. The analysis of these feelings revealed various applications, including brand evaluations, YouTube film reviews and healthcare applications. As social media continues to develop, people post a massive amount of information in different forms, including text, photos, audio and video. Thus, traditional SA algorithms have become limited, as they do not consider the expressiveness of other modalities. By including such characteristics from various material sources, these multimodal data streams provide new opportunities for optimising the expected results beyond text-based SA. Our study focuses on the forefront field of multimodal SA, which examines visual and textual data posted on social media networks. Many people are more likely to utilise this information to express themselves on these platforms. To serve as a resource for academics in this rapidly growing field, we introduce a comprehensive overview of textual and visual SA, including data pre-processing, feature extraction techniques, sentiment benchmark datasets, and the efficacy of multiple classification methodologies suited to each field. We also provide a brief introduction of the most frequently utilised data fusion strategies and a summary of existing research on visual-textual SA. Finally, we highlight the most significant challenges and investigate several important sentiment applications.
Spacecraft depth completion based on the gray image and the sparse depth map
Aug 30, 2022
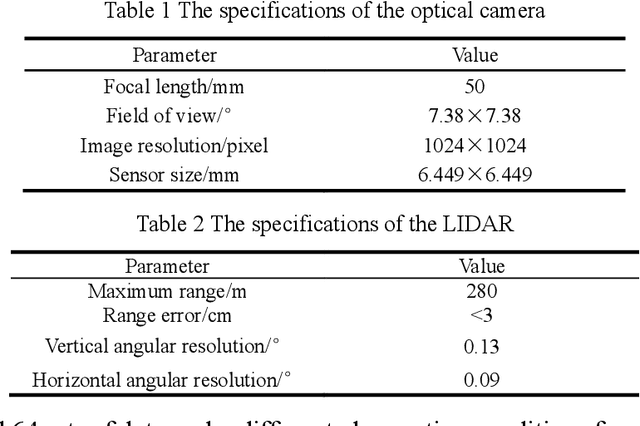
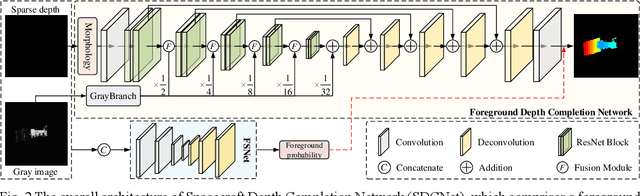
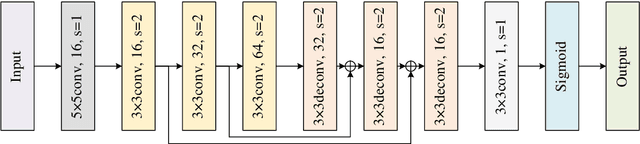
Perceiving the three-dimensional (3D) structure of the spacecraft is a prerequisite for successfully executing many on-orbit space missions, and it can provide critical input for many downstream vision algorithms. In this paper, we propose to sense the 3D structure of spacecraft using light detection and ranging sensor (LIDAR) and a monocular camera. To this end, Spacecraft Depth Completion Network (SDCNet) is proposed to recover the dense depth map based on gray image and sparse depth map. Specifically, SDCNet decomposes the object-level spacecraft depth completion task into foreground segmentation subtask and foreground depth completion subtask, which segments the spacecraft region first and then performs depth completion on the segmented foreground area. In this way, the background interference to foreground spacecraft depth completion is effectively avoided. Moreover, an attention-based feature fusion module is also proposed to aggregate the complementary information between different inputs, which deduces the correlation between different features along the channel and the spatial dimension sequentially. Besides, four metrics are also proposed to evaluate object-level depth completion performance, which can more intuitively reflect the quality of spacecraft depth completion results. Finally, a large-scale satellite depth completion dataset is constructed for training and testing spacecraft depth completion algorithms. Empirical experiments on the dataset demonstrate the effectiveness of the proposed SDCNet, which achieves 0.25m mean absolute error of interest and 0.759m mean absolute truncation error, surpassing state-of-the-art methods by a large margin. The spacecraft pose estimation experiment is also conducted based on the depth completion results, and the experimental results indicate that the predicted dense depth map could meet the needs of downstream vision tasks.
MorDeephy: Face Morphing Detection Via Fused Classification
Aug 05, 2022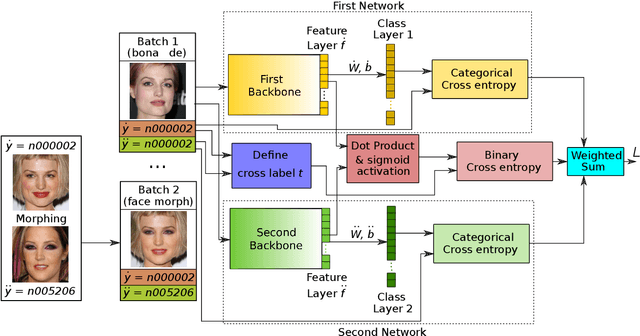
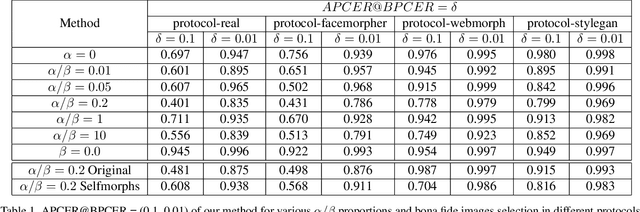
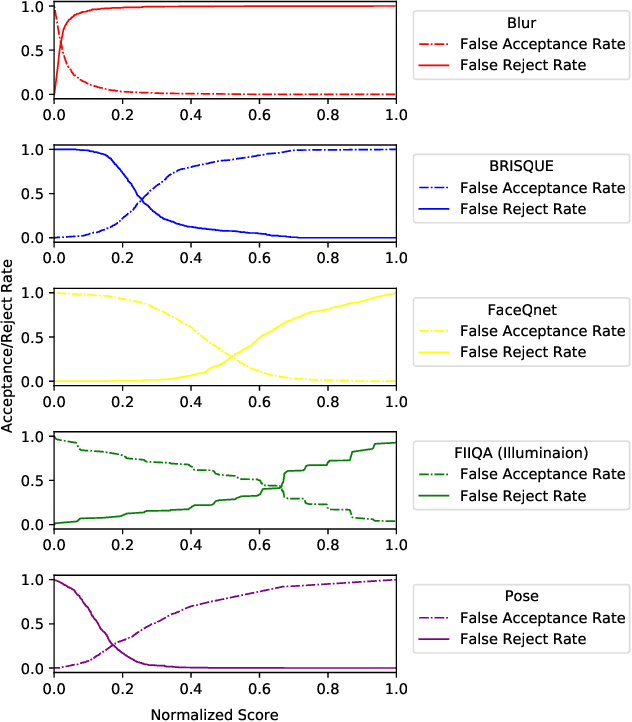
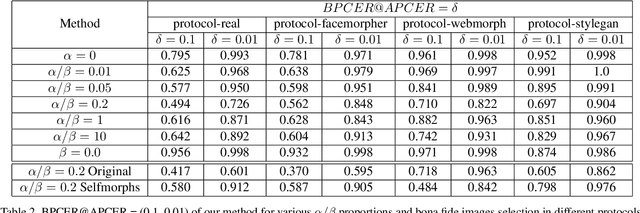
Face morphing attack detection (MAD) is one of the most challenging tasks in the field of face recognition nowadays. In this work, we introduce a novel deep learning strategy for a single image face morphing detection, which implies the discrimination of morphed face images along with a sophisticated face recognition task in a complex classification scheme. It is directed onto learning the deep facial features, which carry information about the authenticity of these features. Our work also introduces several additional contributions: the public and easy-to-use face morphing detection benchmark and the results of our wild datasets filtering strategy. Our method, which we call MorDeephy, achieved the state of the art performance and demonstrated a prominent ability for generalising the task of morphing detection to unseen scenarios.
Generating Pseudo-labels Adaptively for Few-shot Model-Agnostic Meta-Learning
Jul 09, 2022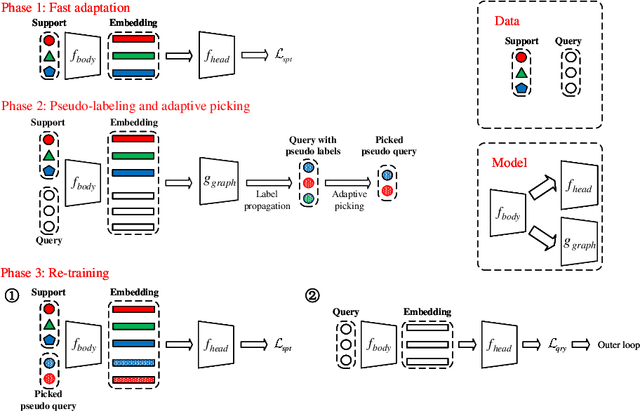
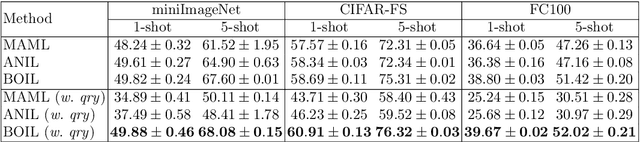
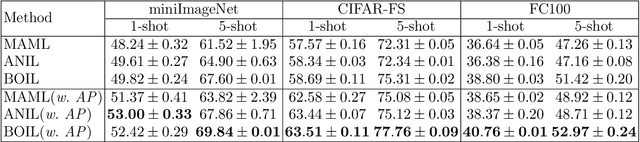
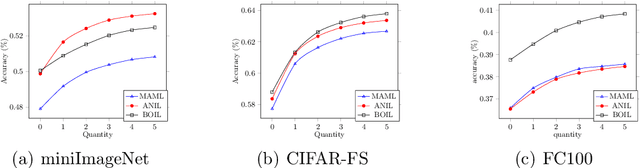
Model-Agnostic Meta-Learning (MAML) is a famous few-shot learning method that has inspired many follow-up efforts, such as ANIL and BOIL. However, as an inductive method, MAML is unable to fully utilize the information of query set, limiting its potential of gaining higher generality. To address this issue, we propose a simple yet effective method that generates psuedo-labels adaptively and could boost the performance of the MAML family. The proposed methods, dubbed Generative Pseudo-label based MAML (GP-MAML), GP-ANIL and GP-BOIL, leverage statistics of the query set to improve the performance on new tasks. Specifically, we adaptively add pseudo labels and pick samples from the query set, then re-train the model using the picked query samples together with the support set. The GP series can also use information from the pseudo query set to re-train the network during the meta-testing. While some transductive methods, such as Transductive Propagation Network (TPN), struggle to achieve this goal.
Differentially Private Federated Combinatorial Bandits with Constraints
Jun 27, 2022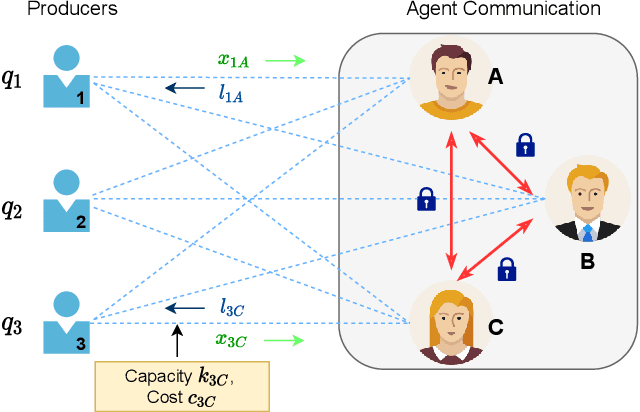
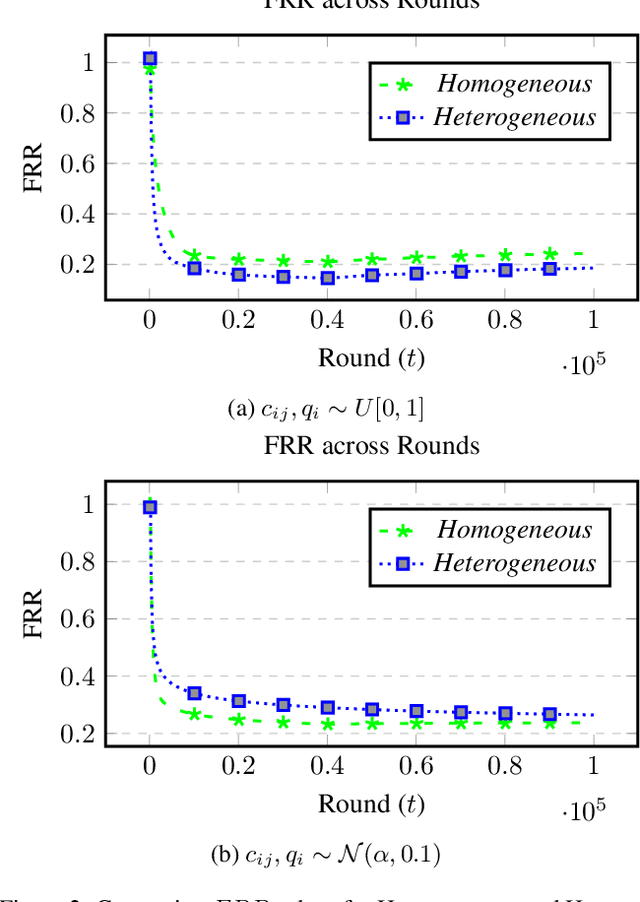
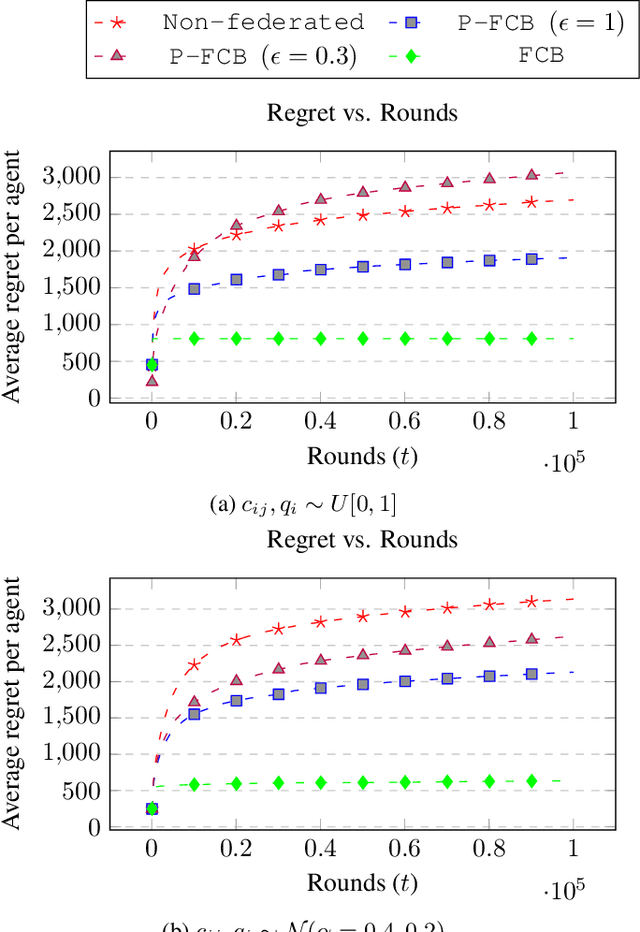
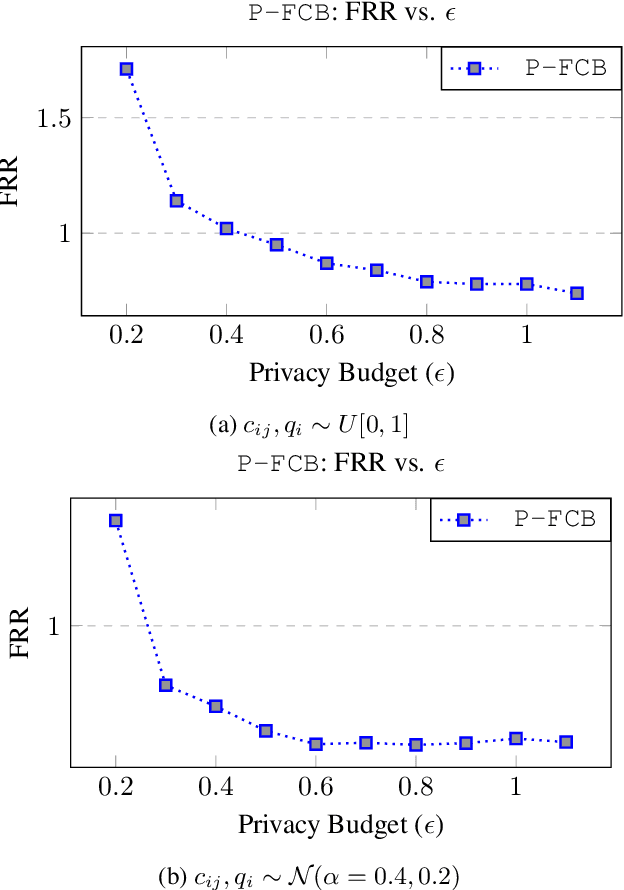
There is a rapid increase in the cooperative learning paradigm in online learning settings, i.e., federated learning (FL). Unlike most FL settings, there are many situations where the agents are competitive. Each agent would like to learn from others, but the part of the information it shares for others to learn from could be sensitive; thus, it desires its privacy. This work investigates a group of agents working concurrently to solve similar combinatorial bandit problems while maintaining quality constraints. Can these agents collectively learn while keeping their sensitive information confidential by employing differential privacy? We observe that communicating can reduce the regret. However, differential privacy techniques for protecting sensitive information makes the data noisy and may deteriorate than help to improve regret. Hence, we note that it is essential to decide when to communicate and what shared data to learn to strike a functional balance between regret and privacy. For such a federated combinatorial MAB setting, we propose a Privacy-preserving Federated Combinatorial Bandit algorithm, P-FCB. We illustrate the efficacy of P-FCB through simulations. We further show that our algorithm provides an improvement in terms of regret while upholding quality threshold and meaningful privacy guarantees.
Feature Learning for Neural-Network-Based Positioning with Channel State Information
Oct 28, 2021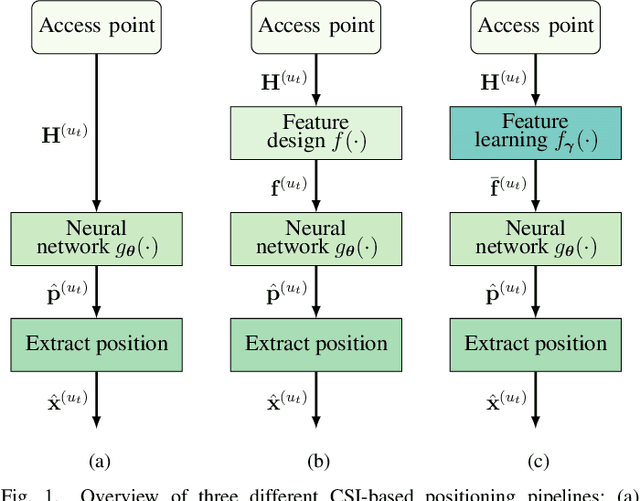
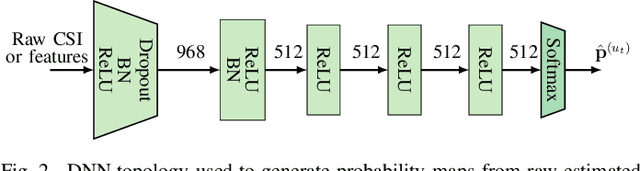
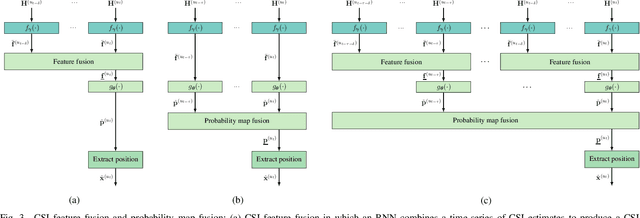
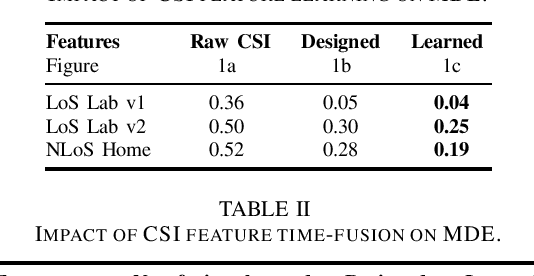
Recent channel state information (CSI)-based positioning pipelines rely on deep neural networks (DNNs) in order to learn a mapping from estimated CSI to position. Since real-world communication transceivers suffer from hardware impairments, CSI-based positioning systems typically rely on features that are designed by hand. In this paper, we propose a CSI-based positioning pipeline that directly takes raw CSI measurements and learns features using a structured DNN in order to generate probability maps describing the likelihood of the transmitter being at pre-defined grid points. To further improve the positioning accuracy of moving user equipments, we propose to fuse a time-series of learned CSI features or a time-series of probability maps. To demonstrate the efficacy of our methods, we perform experiments with real-world indoor line-of-sight (LoS) and non-LoS channel measurements. We show that CSI feature learning and time-series fusion can reduce the mean distance error by up to 2.5$\boldsymbol\times$ compared to the state-of-the-art.
Ask Question First for Enhancing Lifelong Language Learning
Aug 17, 2022


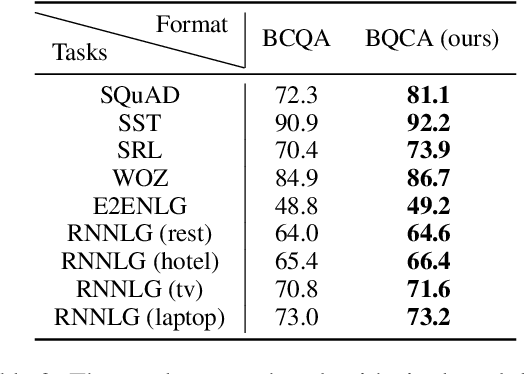
Lifelong language learning aims to stream learning NLP tasks while retaining knowledge of previous tasks. Previous works based on the language model and following data-free constraint approaches have explored formatting all data as "begin token (\textit{B}) + context (\textit{C}) + question (\textit{Q}) + answer (\textit{A})" for different tasks. However, they still suffer from catastrophic forgetting and are exacerbated when the previous task's pseudo data is insufficient for the following reasons: (1) The model has difficulty generating task-corresponding pseudo data, and (2) \textit{A} is prone to error when \textit{A} and \textit{C} are separated by \textit{Q} because the information of the \textit{C} is diminished before generating \textit{A}. Therefore, we propose the Ask Question First and Replay Question (AQF-RQ), including a novel data format "\textit{BQCA}" and a new training task to train pseudo questions of previous tasks. Experimental results demonstrate that AQF-RQ makes it easier for the model to generate more pseudo data that match corresponding tasks, and is more robust to both sufficient and insufficient pseudo-data when the task boundary is both clear and unclear. AQF-RQ can achieve only 0.36\% lower performance than multi-task learning.
Airway Tree Modeling Using Dual-channel 3D UNet 3+ with Vesselness Prior
Aug 30, 2022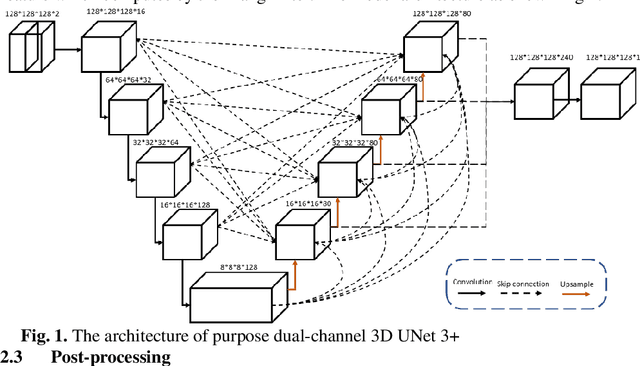
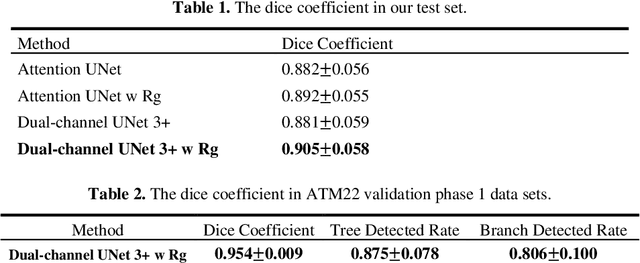
The lung airway tree modeling is essential to work for the diagnosis of pulmonary diseases, especially for X-Ray computed tomography (CT). The airway tree modeling on CT images can provide the experts with 3-dimension measurements like wall thickness, etc. This information can tremendously aid the diagnosis of pulmonary diseases like chronic obstructive pulmonary disease [1-4]. Many scholars have attempted various ways to model the lung airway tree, which can be split into two major categories based on its nature. Namely, the model-based approach and the deep learning approach. The performance of a typical model-based approach usually depends on the manual tuning of the model parameter, which can be its advantages and disadvantages. The advantage is its don't require a large amount of training data which can be beneficial for a small dataset like medical imaging. On the other hand, the performance of model-based may be a misconcep-tion [5,6]. In recent years, deep learning has achieved good results in the field of medical image processing, and many scholars have used UNet-based methods in medical image segmentation [7-11]. Among all the variation of UNet, the UNet 3+ [11] have relatively good result compare to the rest of the variation of UNet. Therefor to further improve the accuracy of lung airway tree modeling, this study combines the Frangi filter [5] with UNet 3+ [11] to develop a dual-channel 3D UNet 3+. The Frangi filter is used to extracting vessel-like feature. The vessel-like feature then used as input to guide the dual-channel UNet 3+ training and testing procedures.