 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeITO: Images and Texts as One via Synergizing Multiple Alignment and Training-Time Fusion
Mar 04, 2026Image-text contrastive pretraining has become a dominant paradigm for visual representation learning, yet existing methods often yield representations that remain partially organized by modality. We propose ITO, a framework addressing this limitation through two synergistic mechanisms. Multimodal multiple alignment enriches supervision by mining diverse image-text correspondences, while a lightweight training-time multimodal fusion module enforces structured cross-modal interaction. Crucially, the fusion module is discarded at inference, preserving the efficiency of standard dual-encoder architectures. Extensive experiments show that ITO consistently outperforms strong baselines across classification, retrieval, and multimodal benchmarks. Our analysis reveals that while multiple alignment drives discriminative power, training-time fusion acts as a critical structural regularizer -- eliminating the modality gap and stabilizing training dynamics to prevent the early saturation often observed in aggressive contrastive learning.
Separators in Enhancing Autoregressive Pretraining for Vision Mamba
Mar 04, 2026The state space model Mamba has recently emerged as a promising paradigm in computer vision, attracting significant attention due to its efficient processing of long sequence tasks. Mamba's inherent causal mechanism renders it particularly suitable for autoregressive pretraining. However, current autoregressive pretraining methods are constrained to short sequence tasks, failing to fully exploit Mamba's prowess in handling extended sequences. To address this limitation, we introduce an innovative autoregressive pretraining method for Vision Mamba that substantially extends the input sequence length. We introduce new \textbf{S}epara\textbf{T}ors for \textbf{A}uto\textbf{R}egressive pretraining to demarcate and differentiate between different images, known as \textbf{STAR}. Specifically, we insert identical separators before each image to demarcate its inception. This strategy enables us to quadruple the input sequence length of Vision Mamba while preserving the original dimensions of the dataset images. Employing this long sequence pretraining technique, our STAR-B model achieved an impressive accuracy of 83.5\% on ImageNet-1k, which is highly competitive in Vision Mamba. These results underscore the potential of our method in enhancing the performance of vision models through improved leveraging of long-range dependencies.
iGVLM: Dynamic Instruction-Guided Vision Encoding for Question-Aware Multimodal Understanding
Mar 03, 2026Despite the success of Large Vision--Language Models (LVLMs), most existing architectures suffer from a representation bottleneck: they rely on static, instruction-agnostic vision encoders whose visual representations are utilized in an invariant manner across different textual tasks. This rigidity hinders fine-grained reasoning where task-specific visual cues are critical. To address this issue, we propose iGVLM, a general framework for instruction-guided visual modulation. iGVLM introduces a decoupled dual-branch architecture: a frozen representation branch that preserves task-agnostic visual representations learned during pre-training, and a dynamic conditioning branch that performs affine feature modulation via Adaptive Layer Normalization (AdaLN). This design enables a smooth transition from general-purpose perception to instruction-aware reasoning while maintaining the structural integrity and stability of pre-trained visual priors. Beyond standard benchmarks, we introduce MM4, a controlled diagnostic probe for quantifying logical consistency under multi-query, multi-instruction settings. Extensive results show that iGVLM consistently enhances instruction sensitivity across diverse language backbones, offering a plug-and-play paradigm for bridging passive perception and active reasoning.
Enhancing Pre-Trained Model-Based Class-Incremental Learning through Neural Collapse
Apr 25, 2025



Class-Incremental Learning (CIL) is a critical capability for real-world applications, enabling learning systems to adapt to new tasks while retaining knowledge from previous ones. Recent advancements in pre-trained models (PTMs) have significantly advanced the field of CIL, demonstrating superior performance over traditional methods. However, understanding how features evolve and are distributed across incremental tasks remains an open challenge. In this paper, we propose a novel approach to modeling feature evolution in PTM-based CIL through the lens of neural collapse (NC), a striking phenomenon observed in the final phase of training, which leads to a well-separated, equiangular feature space. We explore the connection between NC and CIL effectiveness, showing that aligning feature distributions with the NC geometry enhances the ability to capture the dynamic behavior of continual learning. Based on this insight, we introduce Neural Collapse-inspired Pre-Trained Model-based CIL (NCPTM-CIL), a method that dynamically adjusts the feature space to conform to the elegant NC structure, thereby enhancing the continual learning process. Extensive experiments demonstrate that NCPTM-CIL outperforms state-of-the-art methods across four benchmark datasets. Notably, when initialized with ViT-B/16-IN1K, NCPTM-CIL surpasses the runner-up method by 6.73% on VTAB, 1.25% on CIFAR-100, and 2.5% on OmniBenchmark.
Neural Collapse Inspired Knowledge Distillation
Dec 16, 2024



Existing knowledge distillation (KD) methods have demonstrated their ability in achieving student network performance on par with their teachers. However, the knowledge gap between the teacher and student remains significant and may hinder the effectiveness of the distillation process. In this work, we introduce the structure of Neural Collapse (NC) into the KD framework. NC typically occurs in the final phase of training, resulting in a graceful geometric structure where the last-layer features form a simplex equiangular tight frame. Such phenomenon has improved the generalization of deep network training. We hypothesize that NC can also alleviate the knowledge gap in distillation, thereby enhancing student performance. This paper begins with an empirical analysis to bridge the connection between knowledge distillation and neural collapse. Through this analysis, we establish that transferring the teacher's NC structure to the student benefits the distillation process. Therefore, instead of merely transferring instance-level logits or features, as done by existing distillation methods, we encourage students to learn the teacher's NC structure. Thereby, we propose a new distillation paradigm termed Neural Collapse-inspired Knowledge Distillation (NCKD). Comprehensive experiments demonstrate that NCKD is simple yet effective, improving the generalization of all distilled student models and achieving state-of-the-art accuracy performance.
You Only Need Less Attention at Each Stage in Vision Transformers
Jun 01, 2024The advent of Vision Transformers (ViTs) marks a substantial paradigm shift in the realm of computer vision. ViTs capture the global information of images through self-attention modules, which perform dot product computations among patchified image tokens. While self-attention modules empower ViTs to capture long-range dependencies, the computational complexity grows quadratically with the number of tokens, which is a major hindrance to the practical application of ViTs. Moreover, the self-attention mechanism in deep ViTs is also susceptible to the attention saturation issue. Accordingly, we argue against the necessity of computing the attention scores in every layer, and we propose the Less-Attention Vision Transformer (LaViT), which computes only a few attention operations at each stage and calculates the subsequent feature alignments in other layers via attention transformations that leverage the previously calculated attention scores. This novel approach can mitigate two primary issues plaguing traditional self-attention modules: the heavy computational burden and attention saturation. Our proposed architecture offers superior efficiency and ease of implementation, merely requiring matrix multiplications that are highly optimized in contemporary deep learning frameworks. Moreover, our architecture demonstrates exceptional performance across various vision tasks including classification, detection and segmentation.
Knowledge Distillation via Token-level Relationship Graph
Jun 20, 2023Knowledge distillation is a powerful technique for transferring knowledge from a pre-trained teacher model to a student model. However, the true potential of knowledge transfer has not been fully explored. Existing approaches primarily focus on distilling individual information or instance-level relationships, overlooking the valuable information embedded in token-level relationships, which may be particularly affected by the long-tail effects. To address the above limitations, we propose a novel method called Knowledge Distillation with Token-level Relationship Graph (TRG) that leverages the token-wise relational knowledge to enhance the performance of knowledge distillation. By employing TRG, the student model can effectively emulate higher-level semantic information from the teacher model, resulting in improved distillation results. To further enhance the learning process, we introduce a token-wise contextual loss called contextual loss, which encourages the student model to capture the inner-instance semantic contextual of the teacher model. We conduct experiments to evaluate the effectiveness of the proposed method against several state-of-the-art approaches. Empirical results demonstrate the superiority of TRG across various visual classification tasks, including those involving imbalanced data. Our method consistently outperforms the existing baselines, establishing a new state-of-the-art performance in the field of knowledge distillation.
Class-aware Information for Logit-based Knowledge Distillation
Nov 27, 2022



Knowledge distillation aims to transfer knowledge to the student model by utilizing the predictions/features of the teacher model, and feature-based distillation has recently shown its superiority over logit-based distillation. However, due to the cumbersome computation and storage of extra feature transformation, the training overhead of feature-based methods is much higher than that of logit-based distillation. In this work, we revisit the logit-based knowledge distillation, and observe that the existing logit-based distillation methods treat the prediction logits only in the instance level, while many other useful semantic information is overlooked. To address this issue, we propose a Class-aware Logit Knowledge Distillation (CLKD) method, that extents the logit distillation in both instance-level and class-level. CLKD enables the student model mimic higher semantic information from the teacher model, hence improving the distillation performance. We further introduce a novel loss called Class Correlation Loss to force the student learn the inherent class-level correlation of the teacher. Empirical comparisons demonstrate the superiority of the proposed method over several prevailing logit-based methods and feature-based methods, in which CLKD achieves compelling results on various visual classification tasks and outperforms the state-of-the-art baselines.
Generating Pseudo-labels Adaptively for Few-shot Model-Agnostic Meta-Learning
Jul 09, 2022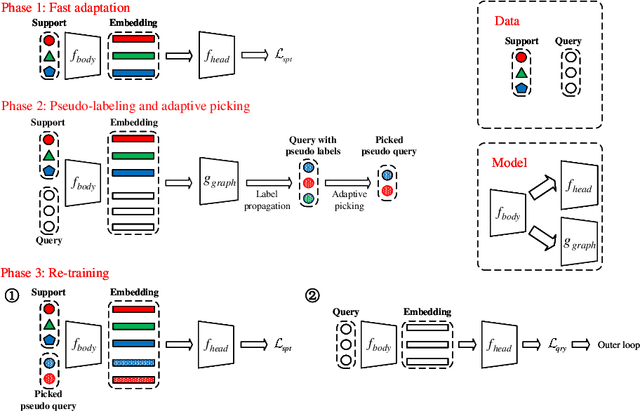
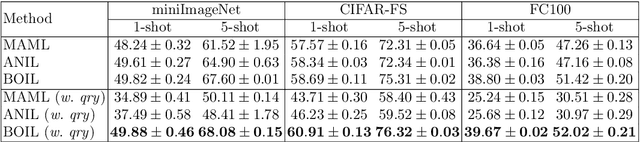
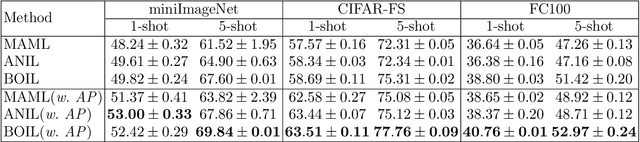
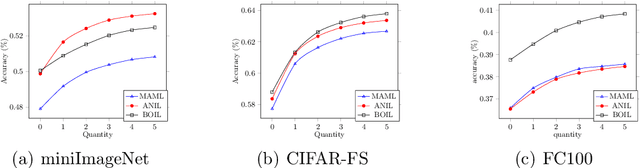
Model-Agnostic Meta-Learning (MAML) is a famous few-shot learning method that has inspired many follow-up efforts, such as ANIL and BOIL. However, as an inductive method, MAML is unable to fully utilize the information of query set, limiting its potential of gaining higher generality. To address this issue, we propose a simple yet effective method that generates psuedo-labels adaptively and could boost the performance of the MAML family. The proposed methods, dubbed Generative Pseudo-label based MAML (GP-MAML), GP-ANIL and GP-BOIL, leverage statistics of the query set to improve the performance on new tasks. Specifically, we adaptively add pseudo labels and pick samples from the query set, then re-train the model using the picked query samples together with the support set. The GP series can also use information from the pseudo query set to re-train the network during the meta-testing. While some transductive methods, such as Transductive Propagation Network (TPN), struggle to achieve this goal.