 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Disentangle and Remerge: Interventional Knowledge Distillation for Few-Shot Object Detection from A Conditional Causal Perspective
Aug 26, 2022

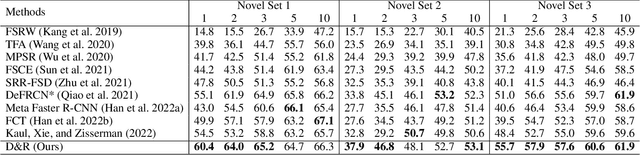
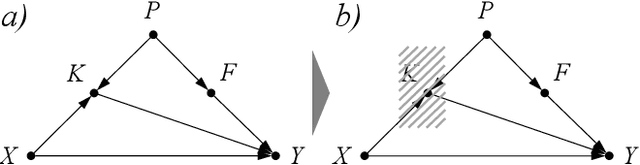
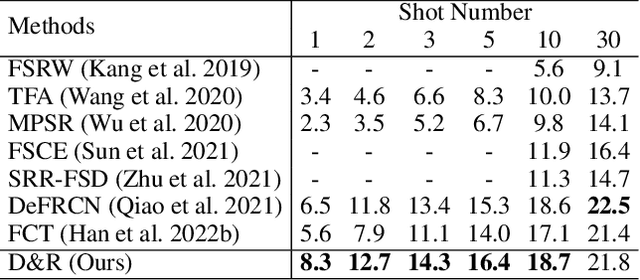
Few-shot learning models learn representations with limited human annotations, and such a learning paradigm demonstrates practicability in various tasks, e.g., image classification, object detection, etc. However, few-shot object detection methods suffer from an intrinsic defect that the limited training data makes the model cannot sufficiently explore semantic information. To tackle this, we introduce knowledge distillation to the few-shot object detection learning paradigm. We further run a motivating experiment, which demonstrates that in the process of knowledge distillation the empirical error of the teacher model degenerates the prediction performance of the few-shot object detection model, as the student. To understand the reasons behind this phenomenon, we revisit the learning paradigm of knowledge distillation on the few-shot object detection task from the causal theoretic standpoint, and accordingly, develop a Structural Causal Model. Following the theoretical guidance, we propose a backdoor adjustment-based knowledge distillation method for the few-shot object detection task, namely Disentangle and Remerge (D&R), to perform conditional causal intervention toward the corresponding Structural Causal Model. Theoretically, we provide an extended definition, i.e., general backdoor path, for the backdoor criterion, which can expand the theoretical application boundary of the backdoor criterion in specific cases. Empirically, the experiments on multiple benchmark datasets demonstrate that D&R can yield significant performance boosts in few-shot object detection.
Intelligence as information processing: brains, swarms, and computers
Aug 09, 2021There is no agreed definition of intelligence, so it is problematic to simply ask whether brains, swarms, computers, or other systems are intelligent or not. To compare the potential intelligence exhibited by different cognitive systems, I use the common approach used by artificial intelligence and artificial life: Instead of studying the substrate of systems, let us focus on their organization. This organization can be measured with information. Thus, I apply an informationist epistemology to describe cognitive systems, including brains and computers. This allows me to frame the usefulness and limitations of the brain-computer analogy in different contexts. I also use this perspective to discuss the evolution and ecology of intelligence.
Time Gated Convolutional Neural Networks for Crop Classification
Jun 20, 2022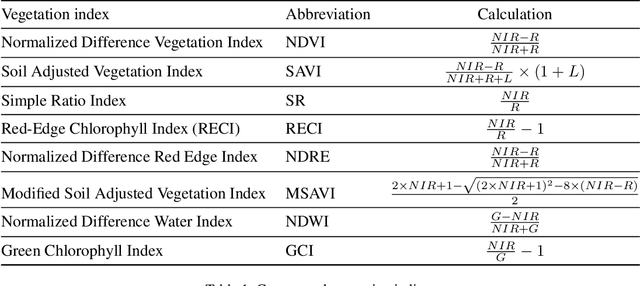
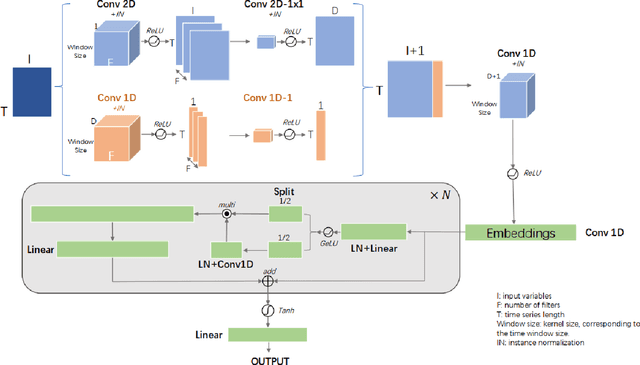
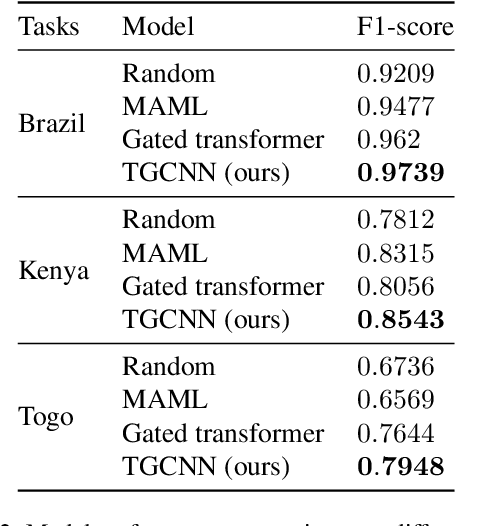
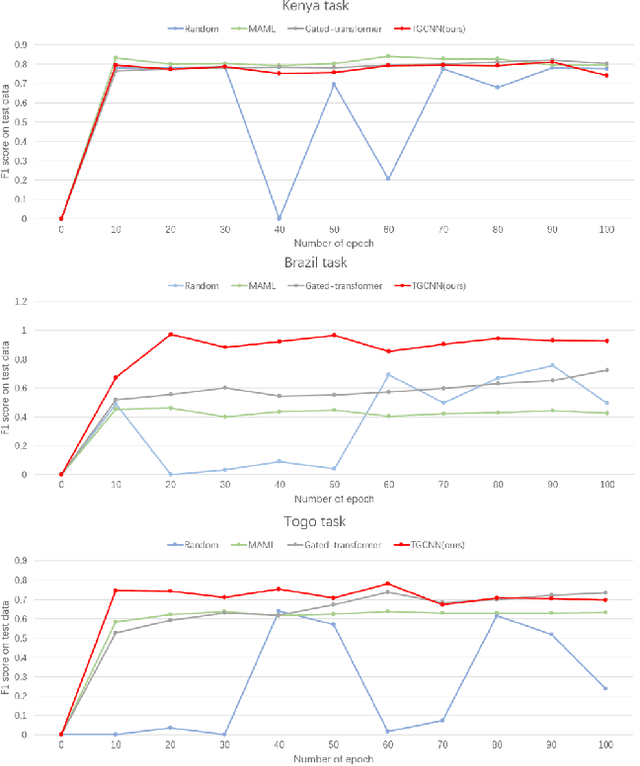
This paper presented a state-of-the-art framework, Time Gated Convolutional Neural Network (TGCNN) that takes advantage of temporal information and gating mechanisms for the crop classification problem. Besides, several vegetation indices were constructed to expand dimensions of input data to take advantage of spectral information. Both spatial (channel-wise) and temporal (step-wise) correlation are considered in TGCNN. Specifically, our preliminary analysis indicates that step-wise information is of greater importance in this data set. Lastly, the gating mechanism helps capture high-order relationship. Our TGCNN solution achieves $0.973$ F1 score, $0.977$ AUC ROC and $0.948$ IoU, respectively. In addition, it outperforms three other benchmarks in different local tasks (Kenya, Brazil and Togo). Overall, our experiments demonstrate that TGCNN is advantageous in this earth observation time series classification task.
Reinforcement Learning based Multi-connectivity Resource Allocation in Factory Automation Systems
Aug 26, 2022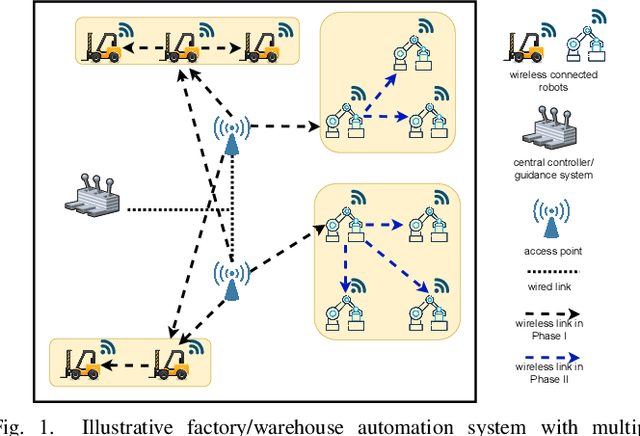
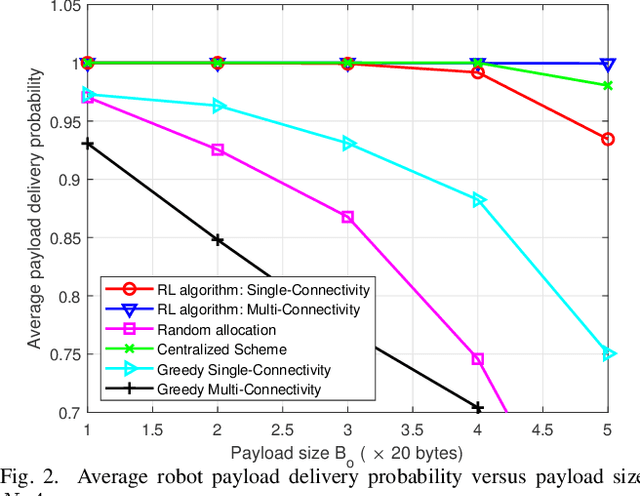
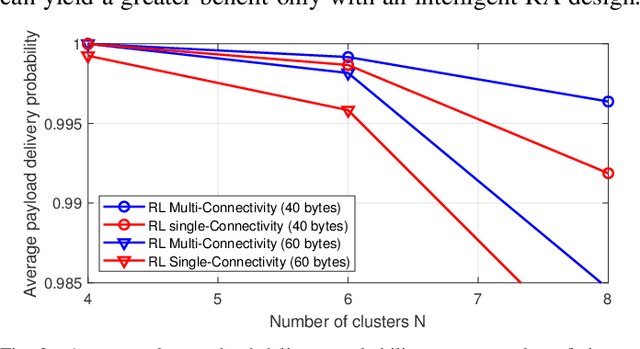
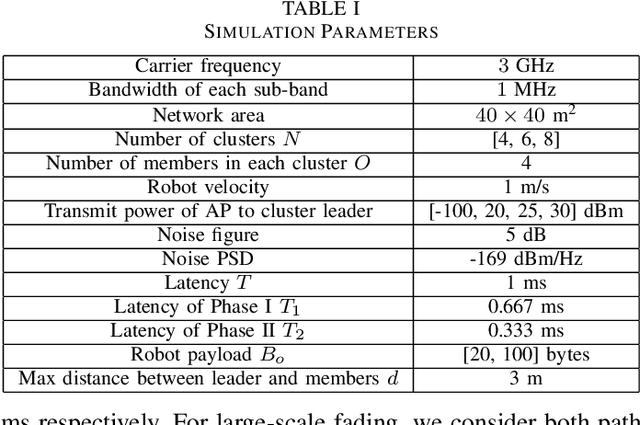
We propose joint user association, channel assignment and power allocation for mobile robot Ultra-Reliable and Low Latency Communications (URLLC) based on multi-connectivity and reinforcement learning. The mobile robots require control messages from the central guidance system at regular intervals. We use a two-phase communication scheme where robots can form multiple clusters. The robots in a cluster are close to each other and can have reliable Device-to-Device (D2D) communications. In Phase I, the APs transmit the combined payload of a cluster to the cluster leader within a latency constraint. The cluster leader broadcasts this message to its members in Phase II. We develop a distributed Multi-Agent Reinforcement Learning (MARL) algorithm for joint user association and resource allocation (RA) for Phase I. The cluster leaders use their local Channel State Information (CSI) to decide the APs for connection along with the sub-band and power level. The cluster leaders utilize multi-connectivity to connect to multiple APs to increase their reliability. The objective is to maximize the successful payload delivery probability for all robots. Illustrative simulation results indicate that the proposed scheme can approach the performance of the centralized algorithm and offer a substantial gain in reliability as compared to single-connectivity (when cluster leaders are able to connect to 1 AP).
DPIT: Dual-Pipeline Integrated Transformer for Human Pose Estimation
Sep 02, 2022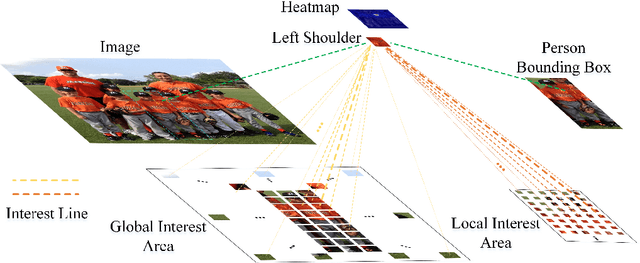
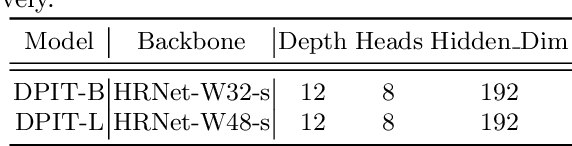
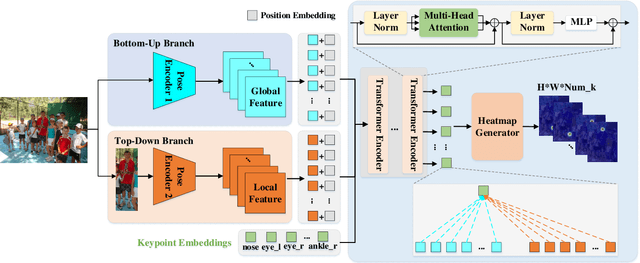
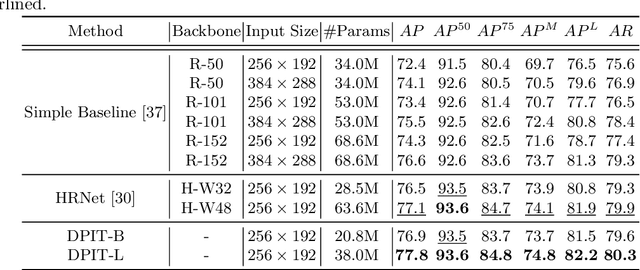
Human pose estimation aims to figure out the keypoints of all people in different scenes. Current approaches still face some challenges despite promising results. Existing top-down methods deal with a single person individually, without the interaction between different people and the scene they are situated in. Consequently, the performance of human detection degrades when serious occlusion happens. On the other hand, existing bottom-up methods consider all people at the same time and capture the global knowledge of the entire image. However, they are less accurate than the top-down methods due to the scale variation. To address these problems, we propose a novel Dual-Pipeline Integrated Transformer (DPIT) by integrating top-down and bottom-up pipelines to explore the visual clues of different receptive fields and achieve their complementarity. Specifically, DPIT consists of two branches, the bottom-up branch deals with the whole image to capture the global visual information, while the top-down branch extracts the feature representation of local vision from the single-human bounding box. Then, the extracted feature representations from bottom-up and top-down branches are fed into the transformer encoder to fuse the global and local knowledge interactively. Moreover, we define the keypoint queries to explore both full-scene and single-human posture visual clues to realize the mutual complementarity of the two pipelines. To the best of our knowledge, this is one of the first works to integrate the bottom-up and top-down pipelines with transformers for human pose estimation. Extensive experiments on COCO and MPII datasets demonstrate that our DPIT achieves comparable performance to the state-of-the-art methods.
Label and Distribution-discriminative Dual Representation Learning for Out-of-Distribution Detection
Jun 19, 2022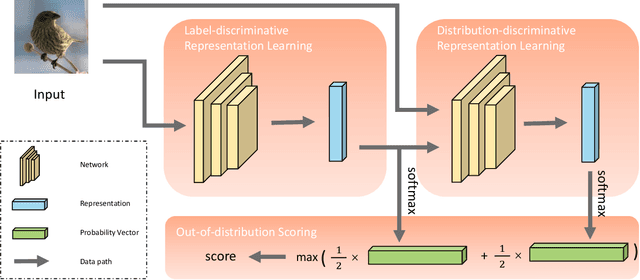
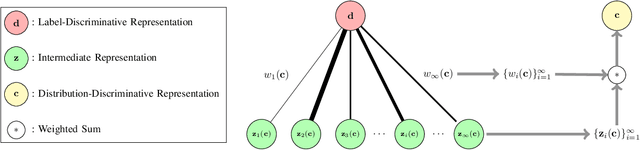
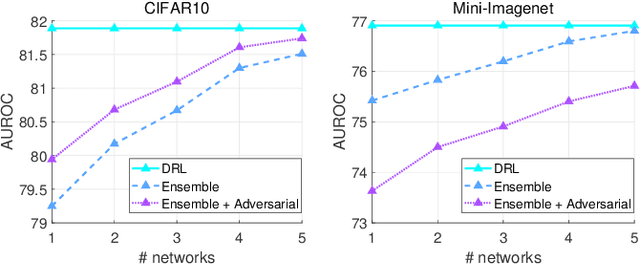
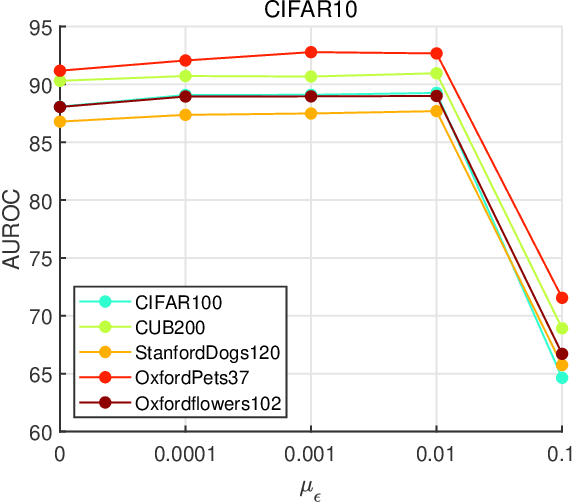
To classify in-distribution samples, deep neural networks learn label-discriminative representations, which, however, are not necessarily distribution-discriminative according to the information bottleneck. Therefore, trained networks could assign unexpected high-confidence predictions to out-of-distribution samples drawn from distributions differing from that of in-distribution samples. Specifically, networks extract the strongly label-related information from in-distribution samples to learn the label-discriminative representations but discard the weakly label-related information. Accordingly, networks treat out-of-distribution samples with minimum label-sensitive information as in-distribution samples. According to the different informativeness properties of in- and out-of-distribution samples, a Dual Representation Learning (DRL) method learns distribution-discriminative representations that are weakly related to the labeling of in-distribution samples and combines label- and distribution-discriminative representations to detect out-of-distribution samples. For a label-discriminative representation, DRL constructs the complementary distribution-discriminative representation by an implicit constraint, i.e., integrating diverse intermediate representations where an intermediate representation less similar to the label-discriminative representation owns a higher weight. Experiments show that DRL outperforms the state-of-the-art methods for out-of-distribution detection.
On the evolution of research in hypersonics: application of natural language processing and machine learning
Aug 17, 2022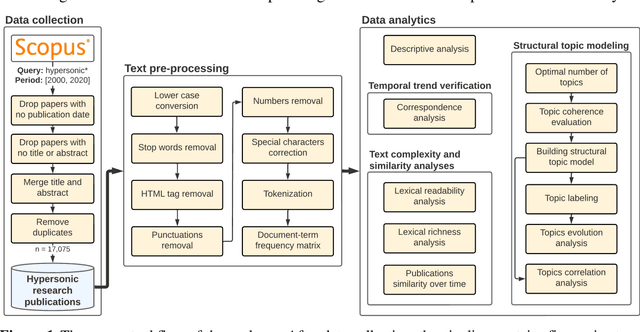
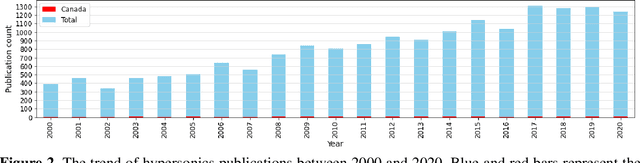
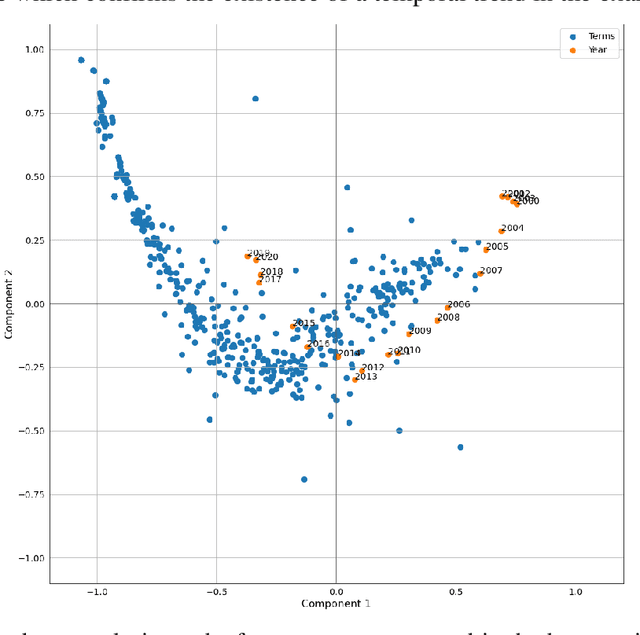
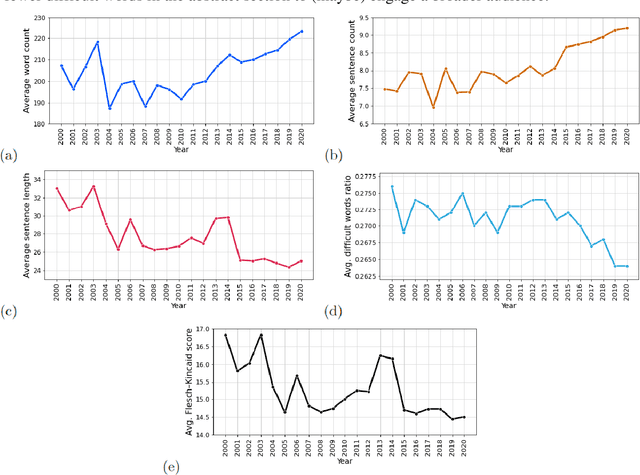
Research and development in hypersonics have progressed significantly in recent years, with various military and commercial applications being demonstrated increasingly. Public and private organizations in several countries have been investing in hypersonics, with the aim to overtake their competitors and secure/improve strategic advantage and deterrence. For these organizations, being able to identify emerging technologies in a timely and reliable manner is paramount. Recent advances in information technology have made it possible to analyze large amounts of data, extract hidden patterns, and provide decision-makers with new insights. In this study, we focus on scientific publications about hypersonics within the period of 2000-2020, and employ natural language processing and machine learning to characterize the research landscape by identifying 12 key latent research themes and analyzing their temporal evolution. Our publication similarity analysis revealed patterns that are indicative of cycles during two decades of research. The study offers a comprehensive analysis of the research field and the fact that the research themes are algorithmically extracted removes subjectivity from the exercise and enables consistent comparisons between topics and between time intervals.
Reliability analysis of discrete-state performance functions via adaptive sequential sampling with detection of failure surfaces
Aug 04, 2022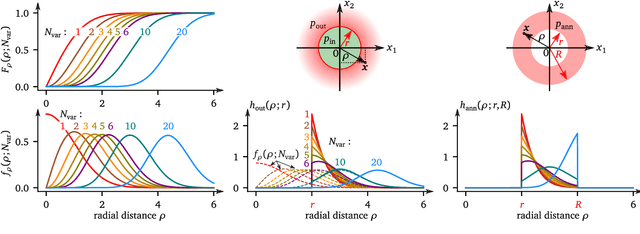
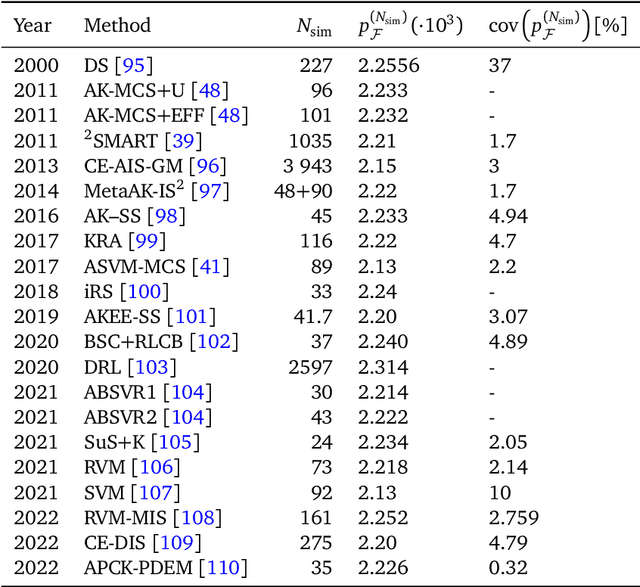
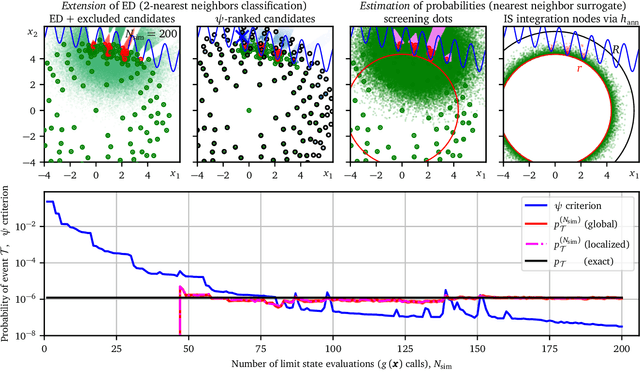
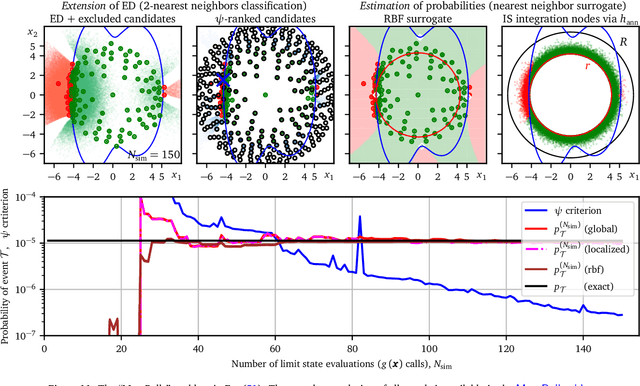
The paper presents a new efficient and robust method for rare event probability estimation for computational models of an engineering product or a process returning categorical information only, for example, either success or failure. For such models, most of the methods designed for the estimation of failure probability, which use the numerical value of the outcome to compute gradients or to estimate the proximity to the failure surface, cannot be applied. Even if the performance function provides more than just binary output, the state of the system may be a non-smooth or even a discontinuous function defined in the domain of continuous input variables. In these cases, the classical gradient-based methods usually fail. We propose a simple yet efficient algorithm, which performs a sequential adaptive selection of points from the input domain of random variables to extend and refine a simple distance-based surrogate model. Two different tasks can be accomplished at any stage of sequential sampling: (i) estimation of the failure probability, and (ii) selection of the best possible candidate for the subsequent model evaluation if further improvement is necessary. The proposed criterion for selecting the next point for model evaluation maximizes the expected probability classified by using the candidate. Therefore, the perfect balance between global exploration and local exploitation is maintained automatically. The method can estimate the probabilities of multiple failure types. Moreover, when the numerical value of model evaluation can be used to build a smooth surrogate, the algorithm can accommodate this information to increase the accuracy of the estimated probabilities. Lastly, we define a new simple yet general geometrical measure of the global sensitivity of the rare-event probability to individual variables, which is obtained as a by-product of the proposed algorithm.
Self-Supervision Can Be a Good Few-Shot Learner
Jul 19, 2022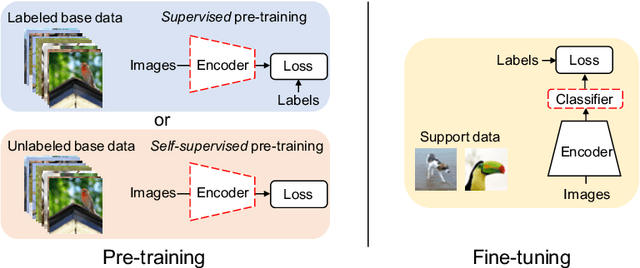
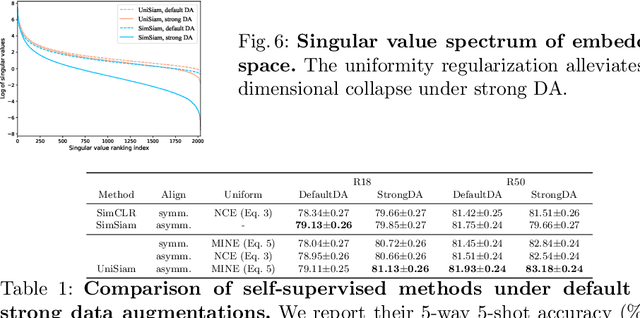
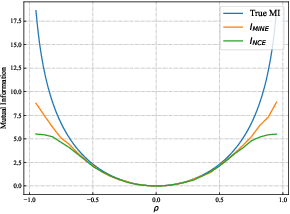
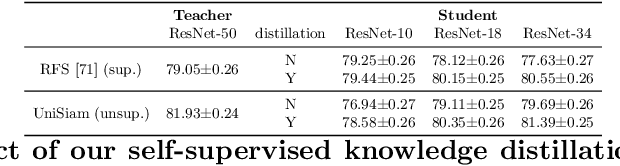
Existing few-shot learning (FSL) methods rely on training with a large labeled dataset, which prevents them from leveraging abundant unlabeled data. From an information-theoretic perspective, we propose an effective unsupervised FSL method, learning representations with self-supervision. Following the InfoMax principle, our method learns comprehensive representations by capturing the intrinsic structure of the data. Specifically, we maximize the mutual information (MI) of instances and their representations with a low-bias MI estimator to perform self-supervised pre-training. Rather than supervised pre-training focusing on the discriminable features of the seen classes, our self-supervised model has less bias toward the seen classes, resulting in better generalization for unseen classes. We explain that supervised pre-training and self-supervised pre-training are actually maximizing different MI objectives. Extensive experiments are further conducted to analyze their FSL performance with various training settings. Surprisingly, the results show that self-supervised pre-training can outperform supervised pre-training under the appropriate conditions. Compared with state-of-the-art FSL methods, our approach achieves comparable performance on widely used FSL benchmarks without any labels of the base classes.
Urdu Speech and Text Based Sentiment Analyzer
Jul 19, 2022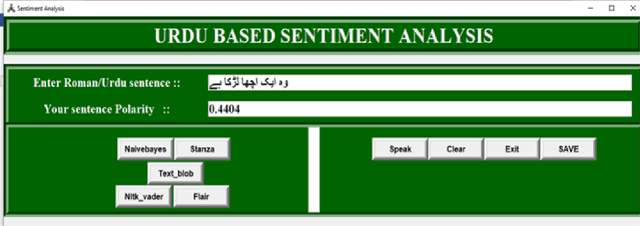
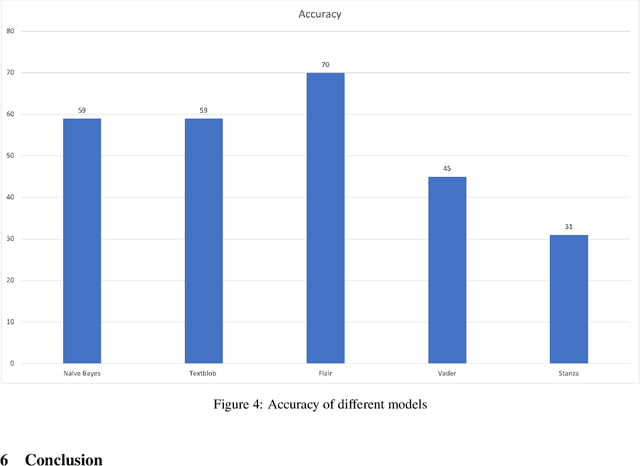
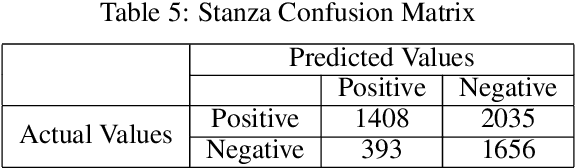
Discovering what other people think has always been a key aspect of our information-gathering strategy. People can now actively utilize information technology to seek out and comprehend the ideas of others, thanks to the increased availability and popularity of opinion-rich resources such as online review sites and personal blogs. Because of its crucial function in understanding people's opinions, sentiment analysis (SA) is a crucial task. Existing research, on the other hand, is primarily focused on the English language, with just a small amount of study devoted to low-resource languages. For sentiment analysis, this work presented a new multi-class Urdu dataset based on user evaluations. The tweeter website was used to get Urdu dataset. Our proposed dataset includes 10,000 reviews that have been carefully classified into two categories by human experts: positive, negative. The primary purpose of this research is to construct a manually annotated dataset for Urdu sentiment analysis and to establish the baseline result. Five different lexicon- and rule-based algorithms including Naivebayes, Stanza, Textblob, Vader, and Flair are employed and the experimental results show that Flair with an accuracy of 70% outperforms other tested algorithms.