 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A multi-task network approach for calculating discrimination-free insurance prices
Jul 06, 2022

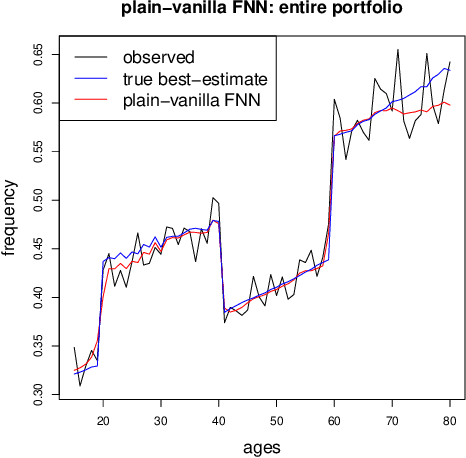
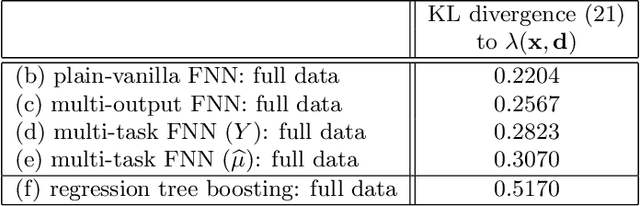
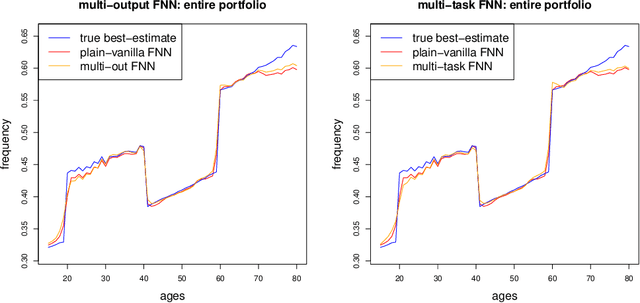
In applications of predictive modeling, such as insurance pricing, indirect or proxy discrimination is an issue of major concern. Namely, there exists the possibility that protected policyholder characteristics are implicitly inferred from non-protected ones by predictive models, and are thus having an undesirable (or illegal) impact on prices. A technical solution to this problem relies on building a best-estimate model using all policyholder characteristics (including protected ones) and then averaging out the protected characteristics for calculating individual prices. However, such approaches require full knowledge of policyholders' protected characteristics, which may in itself be problematic. Here, we address this issue by using a multi-task neural network architecture for claim predictions, which can be trained using only partial information on protected characteristics, and it produces prices that are free from proxy discrimination. We demonstrate the use of the proposed model and we find that its predictive accuracy is comparable to a conventional feedforward neural network (on full information). However, this multi-task network has clearly superior performance in the case of partially missing policyholder information.
Mutual-Information Based Few-Shot Classification
Jun 23, 2021
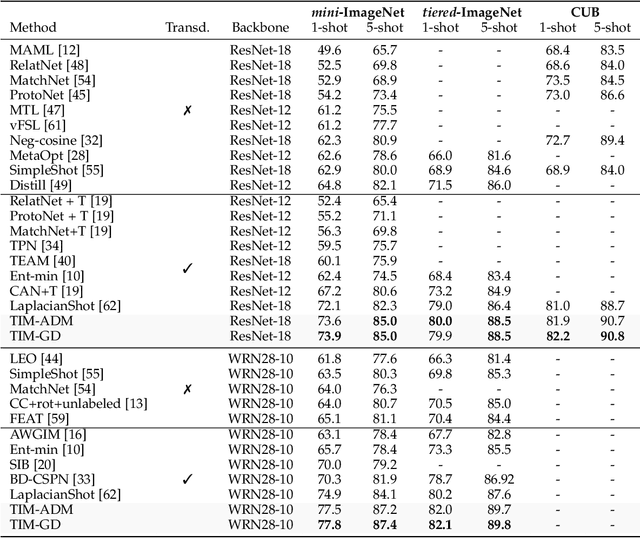
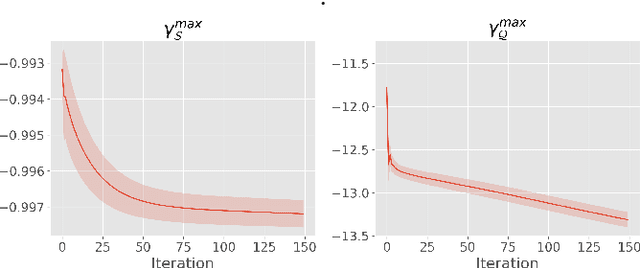
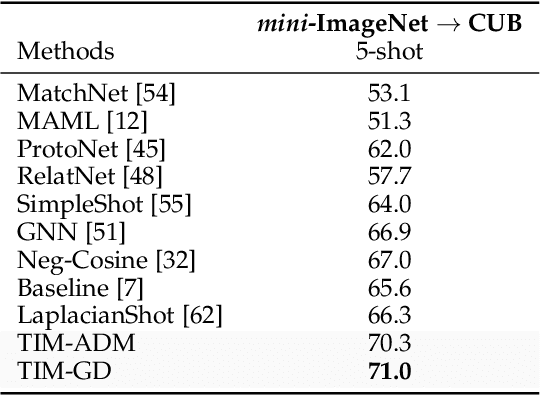
We introduce Transductive Infomation Maximization (TIM) for few-shot learning. Our method maximizes the mutual information between the query features and their label predictions for a given few-shot task, in conjunction with a supervision loss based on the support set. We motivate our transductive loss by deriving a formal relation between the classification accuracy and mutual-information maximization. Furthermore, we propose a new alternating-direction solver, which substantially speeds up transductive inference over gradient-based optimization, while yielding competitive accuracy. We also provide a convergence analysis of our solver based on Zangwill's theory and bound-optimization arguments. TIM inference is modular: it can be used on top of any base-training feature extractor. Following standard transductive few-shot settings, our comprehensive experiments demonstrate that TIM outperforms state-of-the-art methods significantly across various datasets and networks, while used on top of a fixed feature extractor trained with simple cross-entropy on the base classes, without resorting to complex meta-learning schemes. It consistently brings between 2 % and 5 % improvement in accuracy over the best performing method, not only on all the well-established few-shot benchmarks but also on more challenging scenarios, with random tasks, domain shift and larger numbers of classes, as in the recently introduced META-DATASET. Our code is publicly available at https://github.com/mboudiaf/TIM. We also publicly release a standalone PyTorch implementation of META-DATASET, along with additional benchmarking results, at https://github.com/mboudiaf/pytorch-meta-dataset.
Temporally Adjustable Longitudinal Fluid-Attenuated Inversion Recovery MRI Estimation / Synthesis for Multiple Sclerosis
Sep 09, 2022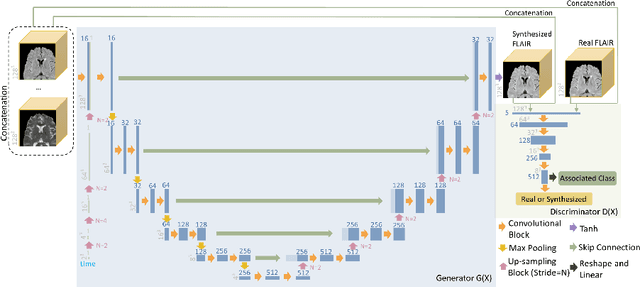
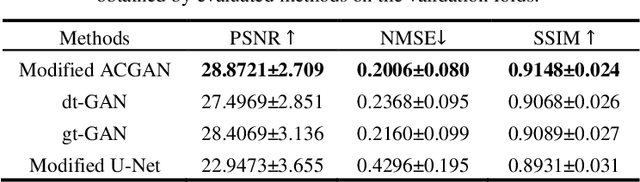
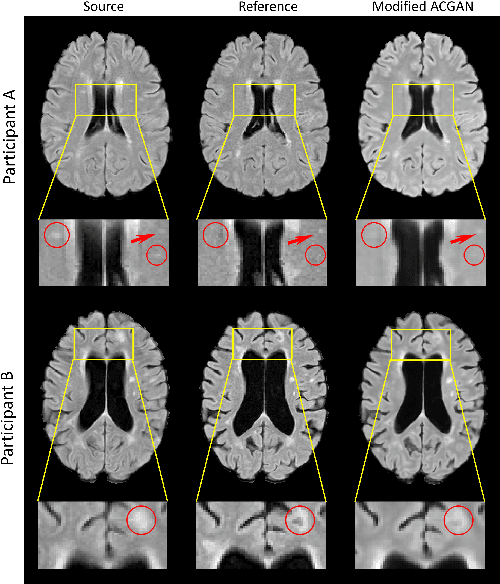
Multiple Sclerosis (MS) is a chronic progressive neurological disease characterized by the development of lesions in the white matter of the brain. T2-fluid-attenuated inversion recovery (FLAIR) brain magnetic resonance imaging (MRI) provides superior visualization and characterization of MS lesions, relative to other MRI modalities. Longitudinal brain FLAIR MRI in MS, involving repetitively imaging a patient over time, provides helpful information for clinicians towards monitoring disease progression. Predicting future whole brain MRI examinations with variable time lag has only been attempted in limited applications, such as healthy aging and structural degeneration in Alzheimer's Disease. In this article, we present novel modifications to deep learning architectures for MS FLAIR image synthesis, in order to support prediction of longitudinal images in a flexible continuous way. This is achieved with learned transposed convolutions, which support modelling time as a spatially distributed array with variable temporal properties at different spatial locations. Thus, this approach can theoretically model spatially-specific time-dependent brain development, supporting the modelling of more rapid growth at appropriate physical locations, such as the site of an MS brain lesion. This approach also supports the clinician user to define how far into the future a predicted examination should target. Accurate prediction of future rounds of imaging can inform clinicians of potentially poor patient outcomes, which may be able to contribute to earlier treatment and better prognoses. Four distinct deep learning architectures have been developed. The ISBI2015 longitudinal MS dataset was used to validate and compare our proposed approaches. Results demonstrate that a modified ACGAN achieves the best performance and reduces variability in model accuracy.
Using Multi-Encoder Fusion Strategies to Improve Personalized Response Selection
Aug 20, 2022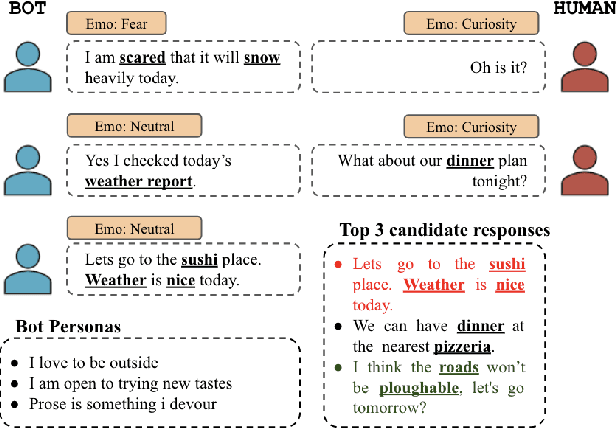

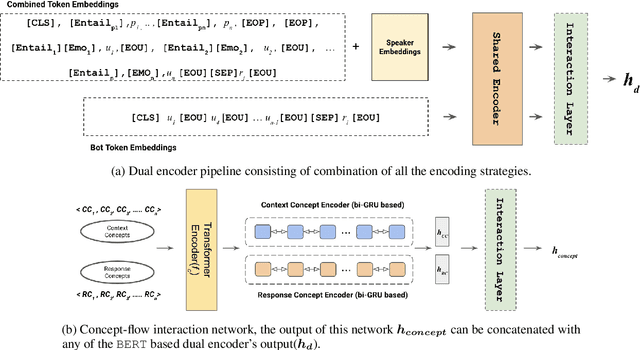
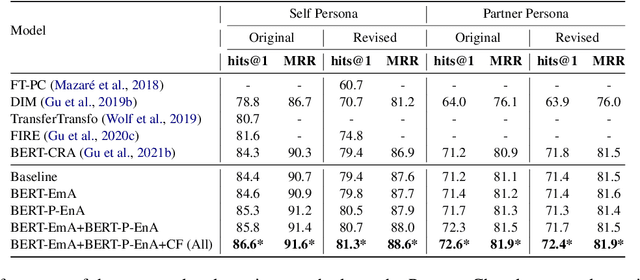
Personalized response selection systems are generally grounded on persona. However, there exists a co-relation between persona and empathy, which is not explored well in these systems. Also, faithfulness to the conversation context plunges when a contradictory or an off-topic response is selected. This paper attempts to address these issues by proposing a suite of fusion strategies that capture the interaction between persona, emotion, and entailment information of the utterances. Ablation studies on the Persona-Chat dataset show that incorporating emotion and entailment improves the accuracy of response selection. We combine our fusion strategies and concept-flow encoding to train a BERT-based model which outperforms the previous methods by margins larger than 2.3 % on original personas and 1.9 % on revised personas in terms of hits@1 (top-1 accuracy), achieving a new state-of-the-art performance on the Persona-Chat dataset.
Expanding Language-Image Pretrained Models for General Video Recognition
Aug 04, 2022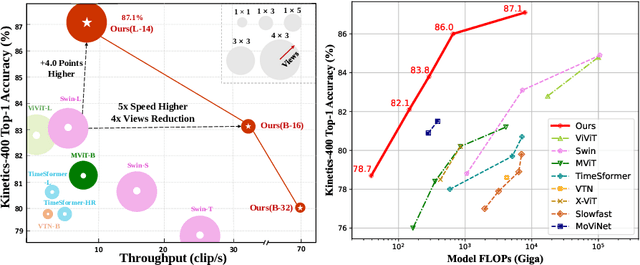
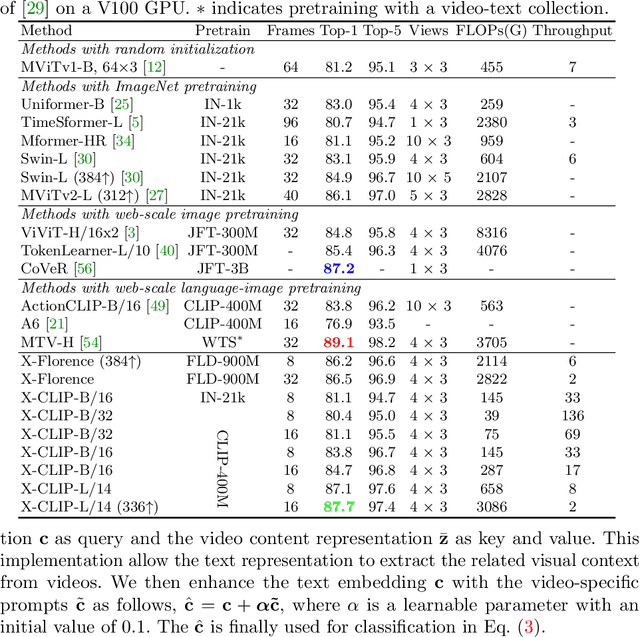
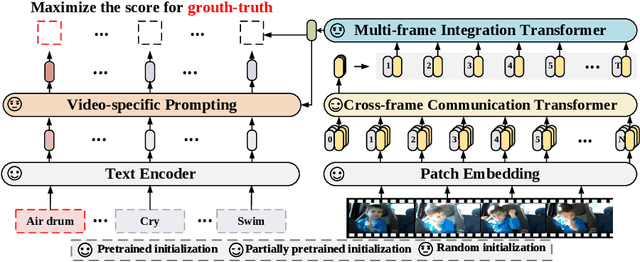
Contrastive language-image pretraining has shown great success in learning visual-textual joint representation from web-scale data, demonstrating remarkable "zero-shot" generalization ability for various image tasks. However, how to effectively expand such new language-image pretraining methods to video domains is still an open problem. In this work, we present a simple yet effective approach that adapts the pretrained language-image models to video recognition directly, instead of pretraining a new model from scratch. More concretely, to capture the long-range dependencies of frames along the temporal dimension, we propose a cross-frame attention mechanism that explicitly exchanges information across frames. Such module is lightweight and can be plugged into pretrained language-image models seamlessly. Moreover, we propose a video-specific prompting scheme, which leverages video content information for generating discriminative textual prompts. Extensive experiments demonstrate that our approach is effective and can be generalized to different video recognition scenarios. In particular, under fully-supervised settings, our approach achieves a top-1 accuracy of 87.1% on Kinectics-400, while using 12 times fewer FLOPs compared with Swin-L and ViViT-H. In zero-shot experiments, our approach surpasses the current state-of-the-art methods by +7.6% and +14.9% in terms of top-1 accuracy under two popular protocols. In few-shot scenarios, our approach outperforms previous best methods by +32.1% and +23.1% when the labeled data is extremely limited. Code and models are available at https://aka.ms/X-CLIP
Learning an Ensemble of Deep Fingerprint Representations
Sep 02, 2022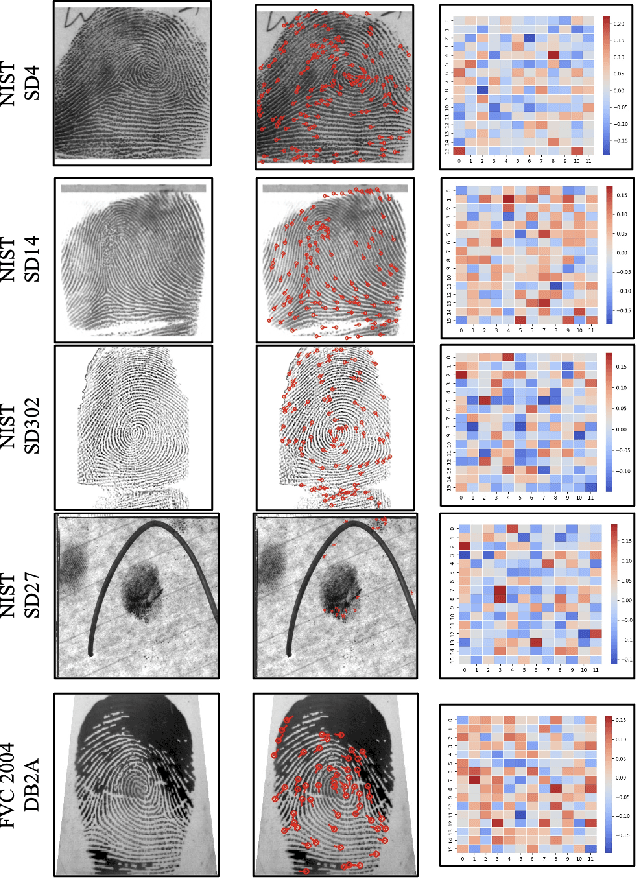

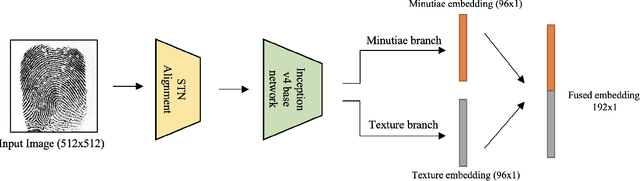
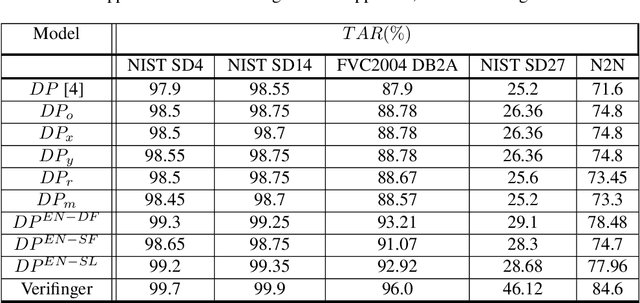
Deep neural networks (DNNs) have shown incredible promise in learning fixed-length representations from fingerprints. Since the representation learning is often focused on capturing specific prior knowledge (e.g., minutiae), there is no universal representation that comprehensively encapsulates all the discriminatory information available in a fingerprint. While learning an ensemble of representations can mitigate this problem, two critical challenges need to be addressed: (i) How to extract multiple diverse representations from the same fingerprint image? and (ii) How to optimally exploit these representations during the matching process? In this work, we train multiple instances of DeepPrint (a state-of-the-art DNN-based fingerprint encoder) on different transformations of the input image to generate an ensemble of fingerprint embeddings. We also propose a feature fusion technique that distills these multiple representations into a single embedding, which faithfully captures the diversity present in the ensemble without increasing the computational complexity. The proposed approach has been comprehensively evaluated on five databases containing rolled, plain, and latent fingerprints (NIST SD4, NIST SD14, NIST SD27, NIST SD302, and FVC2004 DB2A) and statistically significant improvements in accuracy have been consistently demonstrated across a range of verification as well as closed- and open-set identification settings. The proposed approach serves as a wrapper capable of improving the accuracy of any DNN-based recognition system.
Singing Beat Tracking With Self-supervised Front-end and Linear Transformers
Aug 31, 2022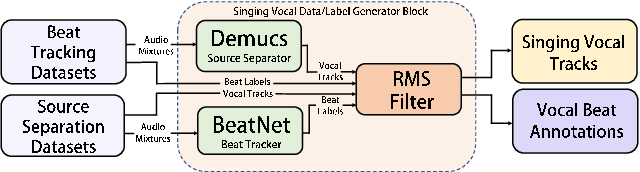
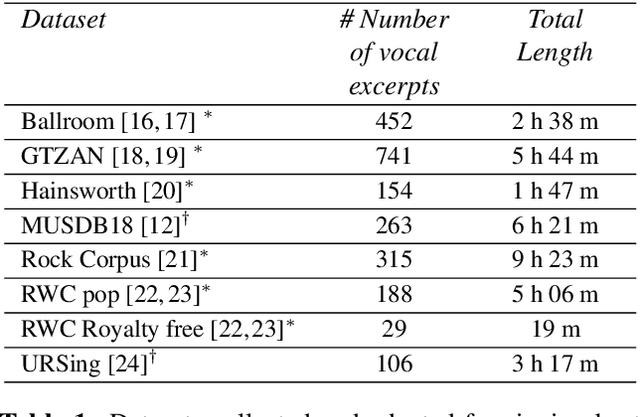

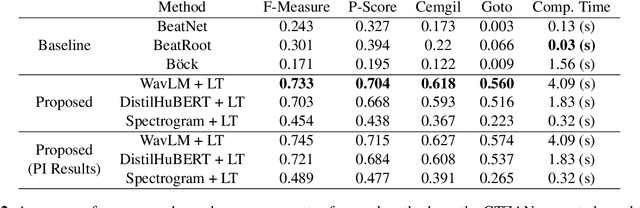
Tracking beats of singing voices without the presence of musical accompaniment can find many applications in music production, automatic song arrangement, and social media interaction. Its main challenge is the lack of strong rhythmic and harmonic patterns that are important for music rhythmic analysis in general. Even for human listeners, this can be a challenging task. As a result, existing music beat tracking systems fail to deliver satisfactory performance on singing voices. In this paper, we propose singing beat tracking as a novel task, and propose the first approach to solving this task. Our approach leverages semantic information of singing voices by employing pre-trained self-supervised WavLM and DistilHuBERT speech representations as the front-end and uses a self-attention encoder layer to predict beats. To train and test the system, we obtain separated singing voices and their beat annotations using source separation and beat tracking on complete songs, followed by manual corrections. Experiments on the 741 separated vocal tracks of the GTZAN dataset show that the proposed system outperforms several state-of-the-art music beat tracking methods by a large margin in terms of beat tracking accuracy. Ablation studies also confirm the advantages of pre-trained self-supervised speech representations over generic spectral features.
Unbiased Multi-Modality Guidance for Image Inpainting
Aug 25, 2022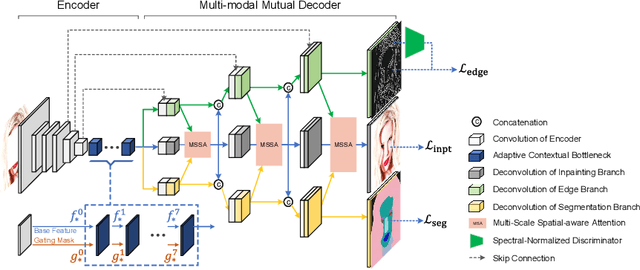
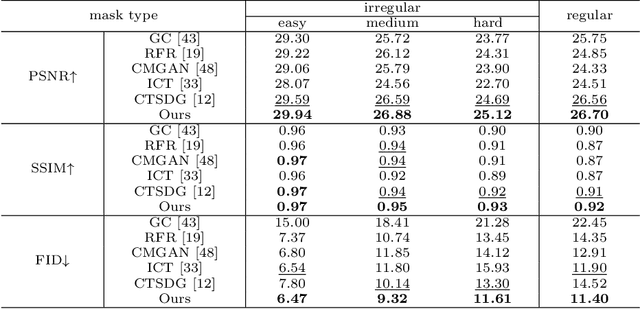
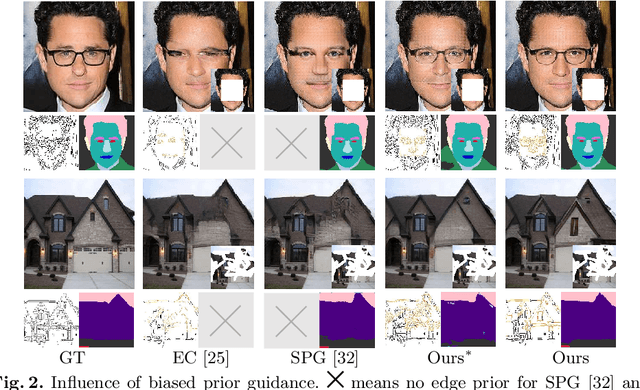
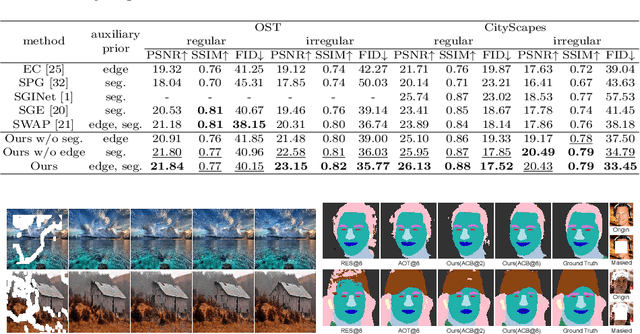
Image inpainting is an ill-posed problem to recover missing or damaged image content based on incomplete images with masks. Previous works usually predict the auxiliary structures (e.g., edges, segmentation and contours) to help fill visually realistic patches in a multi-stage fashion. However, imprecise auxiliary priors may yield biased inpainted results. Besides, it is time-consuming for some methods to be implemented by multiple stages of complex neural networks. To solve this issue, we develop an end-to-end multi-modality guided transformer network, including one inpainting branch and two auxiliary branches for semantic segmentation and edge textures. Within each transformer block, the proposed multi-scale spatial-aware attention module can learn the multi-modal structural features efficiently via auxiliary denormalization. Different from previous methods relying on direct guidance from biased priors, our method enriches semantically consistent context in an image based on discriminative interplay information from multiple modalities. Comprehensive experiments on several challenging image inpainting datasets show that our method achieves state-of-the-art performance to deal with various regular/irregular masks efficiently.
G-PCC Post-Processing Using Fractional Super-Resolution
Aug 09, 2022

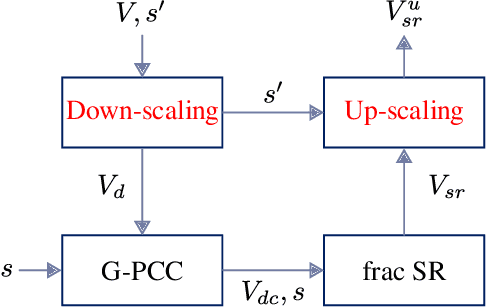
We present a method for post-processing point clouds' geometric information by applying a previously proposed fractional super-resolution technique to clouds compressed and decoded with MPEG's G-PCC codec. In some sense, this is a continuation of that previous work, which requires only a down-scaled point cloud and a scaling factor, both of which are provided by the G-PCC codec. For non-solid point clouds, an a priori down-scaling is required for improved efficiency. The method is compared to the GPCC itself, as well as machine-learning-based techniques. Results show a great improvement in quality over GPCC and comparable performance to the latter techniques, with the
Polarimetric Inverse Rendering for Transparent Shapes Reconstruction
Aug 25, 2022

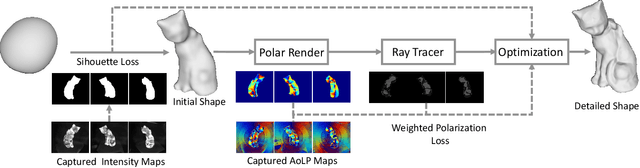

In this work, we propose a novel method for the detailed reconstruction of transparent objects by exploiting polarimetric cues. Most of the existing methods usually lack sufficient constraints and suffer from the over-smooth problem. Hence, we introduce polarization information as a complementary cue. We implicitly represent the object's geometry as a neural network, while the polarization render is capable of rendering the object's polarization images from the given shape and illumination configuration. Direct comparison of the rendered polarization images to the real-world captured images will have additional errors due to the transmission in the transparent object. To address this issue, the concept of reflection percentage which represents the proportion of the reflection component is introduced. The reflection percentage is calculated by a ray tracer and then used for weighting the polarization loss. We build a polarization dataset for multi-view transparent shapes reconstruction to verify our method. The experimental results show that our method is capable of recovering detailed shapes and improving the reconstruction quality of transparent objects. Our dataset and code will be publicly available at https://github.com/shaomq2187/TransPIR.