 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussianPOP: Principled Simplification Framework for Compact 3D Gaussian Splatting via Error Quantification
Feb 06, 2026Existing 3D Gaussian Splatting simplification methods commonly use importance scores, such as blending weights or sensitivity, to identify redundant Gaussians. However, these scores are not driven by visual error metrics, often leading to suboptimal trade-offs between compactness and rendering fidelity. We present GaussianPOP, a principled simplification framework based on analytical Gaussian error quantification. Our key contribution is a novel error criterion, derived directly from the 3DGS rendering equation, that precisely measures each Gaussian's contribution to the rendered image. By introducing a highly efficient algorithm, our framework enables practical error calculation in a single forward pass. The framework is both accurate and flexible, supporting on-training pruning as well as post-training simplification via iterative error re-quantification for improved stability. Experimental results show that our method consistently outperforms existing state-of-the-art pruning methods across both application scenarios, achieving a superior trade-off between model compactness and high rendering quality.
G-PCC Post-Processing Using Fractional Super-Resolution
Aug 09, 2022
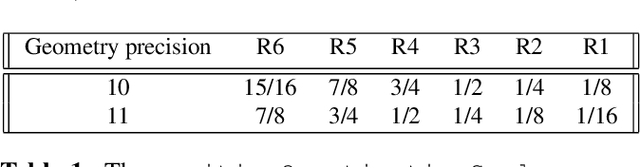

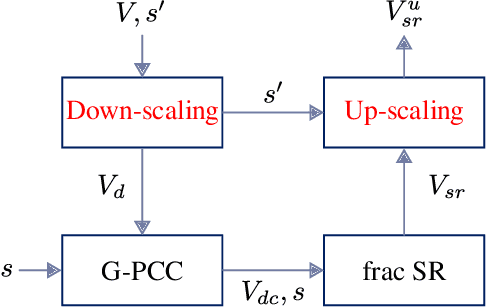
We present a method for post-processing point clouds' geometric information by applying a previously proposed fractional super-resolution technique to clouds compressed and decoded with MPEG's G-PCC codec. In some sense, this is a continuation of that previous work, which requires only a down-scaled point cloud and a scaling factor, both of which are provided by the G-PCC codec. For non-solid point clouds, an a priori down-scaling is required for improved efficiency. The method is compared to the GPCC itself, as well as machine-learning-based techniques. Results show a great improvement in quality over GPCC and comparable performance to the latter techniques, with the
Towards robustness under occlusion for face recognition
Sep 19, 2021


In this paper, we evaluate the effects of occlusions in the performance of a face recognition pipeline that uses a ResNet backbone. The classifier was trained on a subset of the CelebA-HQ dataset containing 5,478 images from 307 classes, to achieve top-1 error rate of 17.91%. We designed 8 different occlusion masks which were applied to the input images. This caused a significant drop in the classifier performance: its error rate for each mask became at least two times worse than before. In order to increase robustness under occlusions, we followed two approaches. The first is image inpainting using the pre-trained pluralistic image completion network. The second is Cutmix, a regularization strategy consisting of mixing training images and their labels using rectangular patches, making the classifier more robust against input corruptions. Both strategies revealed effective and interesting results were observed. In particular, the Cutmix approach makes the network more robust without requiring additional steps at the application time, though its training time is considerably longer. Our datasets containing the different occlusion masks as well as their inpainted counterparts are made publicly available to promote research on the field.