 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Robust and Lossless Fingerprinting of Deep Neural Networks via Pooled Membership Inference
Sep 09, 2022
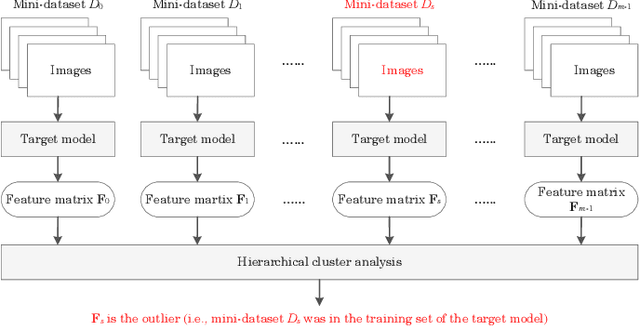
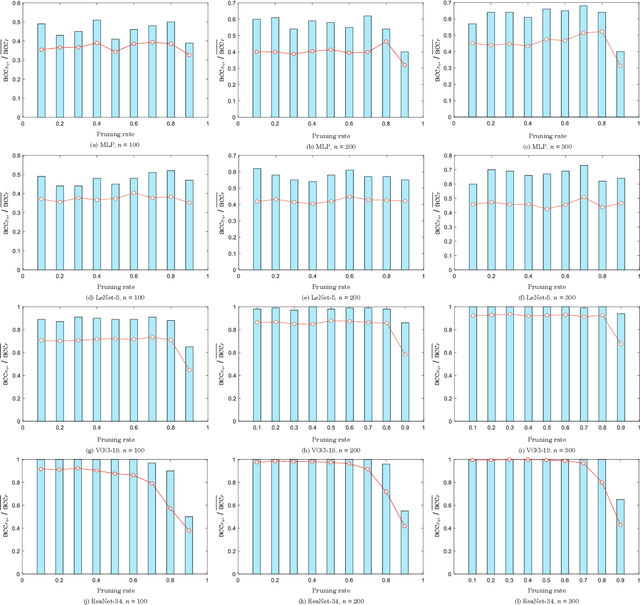
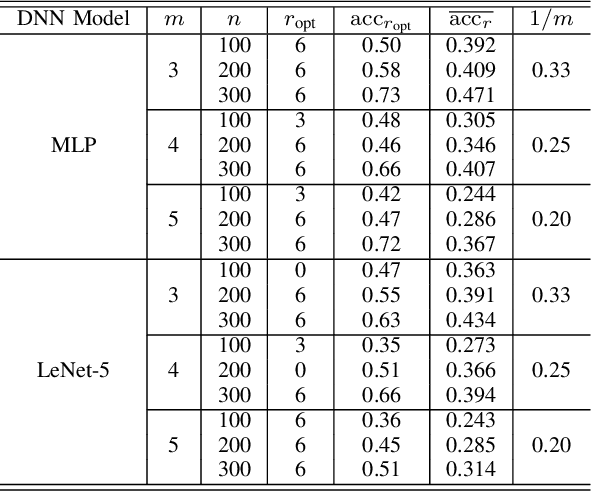
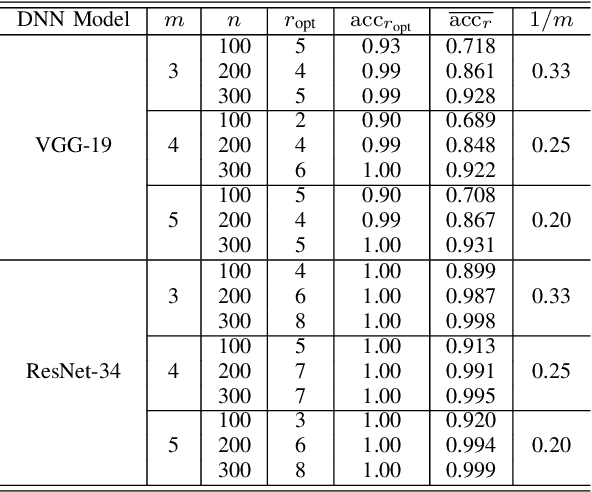
Deep neural networks (DNNs) have already achieved great success in a lot of application areas and brought profound changes to our society. However, it also raises new security problems, among which how to protect the intellectual property (IP) of DNNs against infringement is one of the most important yet very challenging topics. To deal with this problem, recent studies focus on the IP protection of DNNs by applying digital watermarking, which embeds source information and/or authentication data into DNN models by tuning network parameters directly or indirectly. However, tuning network parameters inevitably distorts the DNN and therefore surely impairs the performance of the DNN model on its original task regardless of the degree of the performance degradation. It has motivated the authors in this paper to propose a novel technique called \emph{pooled membership inference (PMI)} so as to protect the IP of the DNN models. The proposed PMI neither alters the network parameters of the given DNN model nor fine-tunes the DNN model with a sequence of carefully crafted trigger samples. Instead, it leaves the original DNN model unchanged, but can determine the ownership of the DNN model by inferring which mini-dataset among multiple mini-datasets was once used to train the target DNN model, which differs from previous arts and has remarkable potential in practice. Experiments also have demonstrated the superiority and applicability of this work.
Detecting Humans in RGB-D Data with CNNs
Jul 17, 2022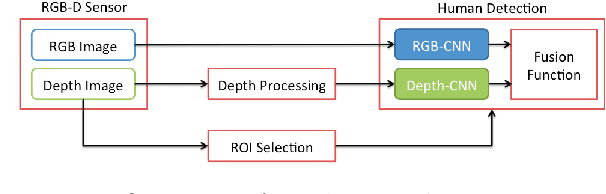
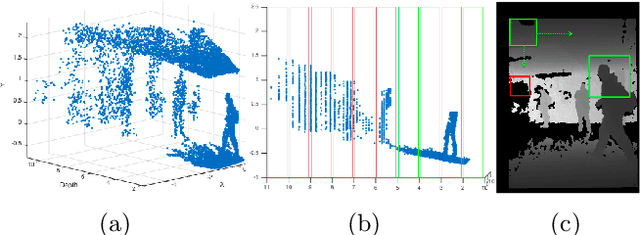
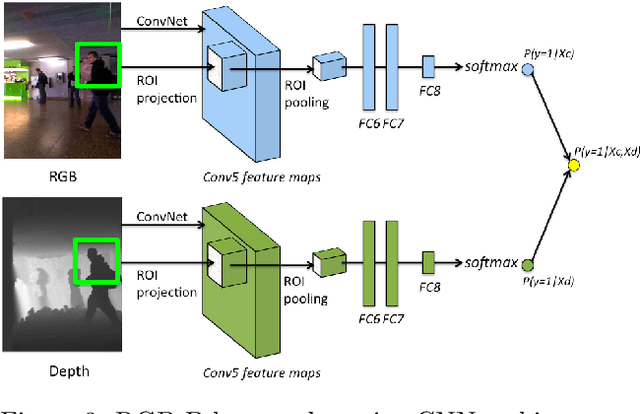
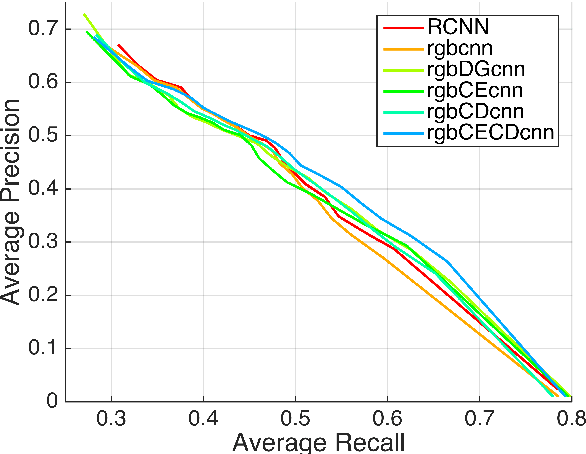
We address the problem of people detection in RGB-D data where we leverage depth information to develop a region-of-interest (ROI) selection method that provides proposals to two color and depth CNNs. To combine the detections produced by the two CNNs, we propose a novel fusion approach based on the characteristics of depth images. We also present a new depth-encoding scheme, which not only encodes depth images into three channels but also enhances the information for classification. We conduct experiments on a publicly available RGB-D people dataset and show that our approach outperforms the baseline models that only use RGB data.
Multi-Modal Beam Prediction Challenge 2022: Towards Generalization
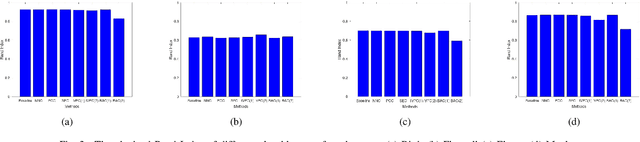
Sep 15, 2022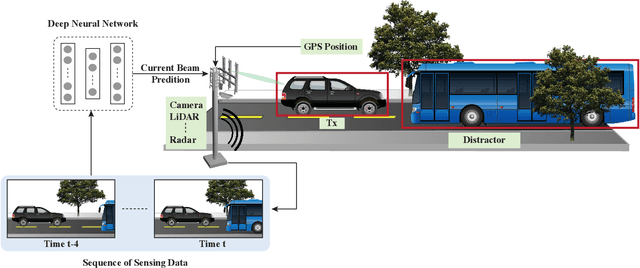
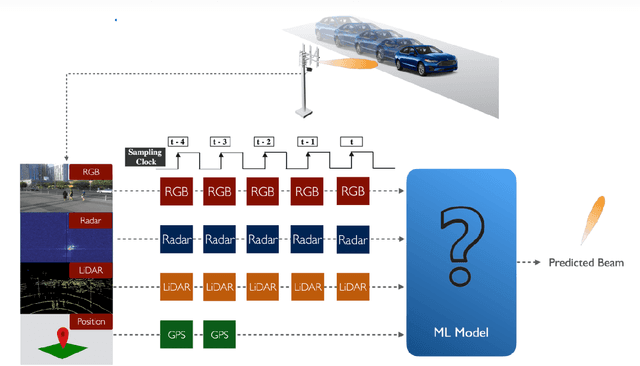

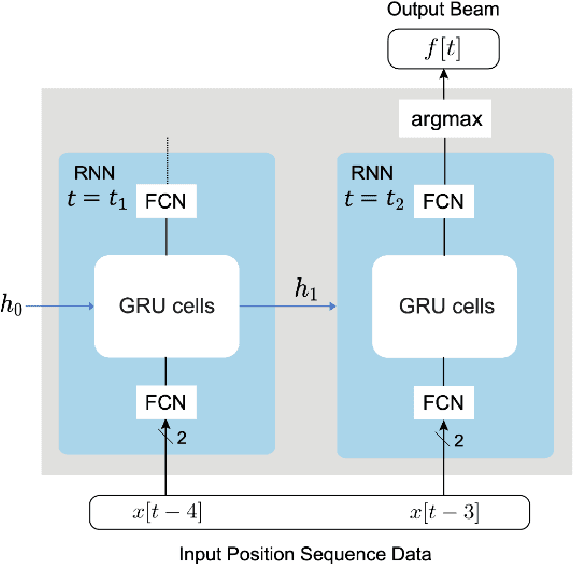
Beam management is a challenging task for millimeter wave (mmWave) and sub-terahertz communication systems, especially in scenarios with highly-mobile users. Leveraging external sensing modalities such as vision, LiDAR, radar, position, or a combination of them, to address this beam management challenge has recently attracted increasing interest from both academia and industry. This is mainly motivated by the dependency of the beam direction decision on the user location and the geometry of the surrounding environment -- information that can be acquired from the sensory data. To realize the promised beam management gains, such as the significant reduction in beam alignment overhead, in practice, however, these solutions need to account for important aspects. For example, these multi-modal sensing aided beam selection approaches should be able to generalize their learning to unseen scenarios and should be able to operate in realistic dense deployments. The "Multi-Modal Beam Prediction Challenge 2022: Towards Generalization" competition is offered to provide a platform for investigating these critical questions. In order to facilitate the generalizability study, the competition offers a large-scale multi-modal dataset with co-existing communication and sensing data collected across multiple real-world locations and different times of the day. In this paper, along with the detailed descriptions of the problem statement and the development dataset, we provide a baseline solution that utilizes the user position data to predict the optimal beam indices. The objective of this challenge is to go beyond a simple feasibility study and enable necessary research in this direction, paving the way towards generalizable multi-modal sensing-aided beam management for real-world future communication systems.
Leachable Component Clustering
Aug 28, 2022

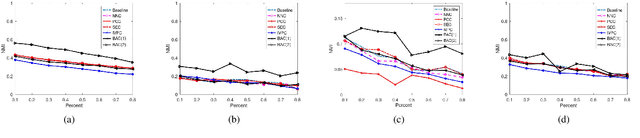
Clustering attempts to partition data instances into several distinctive groups, while the similarities among data belonging to the common partition can be principally reserved. Furthermore, incomplete data frequently occurs in many realworld applications, and brings perverse influence on pattern analysis. As a consequence, the specific solutions to data imputation and handling are developed to conduct the missing values of data, and independent stage of knowledge exploitation is absorbed for information understanding. In this work, a novel approach to clustering of incomplete data, termed leachable component clustering, is proposed. Rather than existing methods, the proposed method handles data imputation with Bayes alignment, and collects the lost patterns in theory. Due to the simple numeric computation of equations, the proposed method can learn optimized partitions while the calculation efficiency is held. Experiments on several artificial incomplete data sets demonstrate that, the proposed method is able to present superior performance compared with other state-of-the-art algorithms.
A Review of Machine Learning-based Failure Management in Optical Networks
Aug 23, 2022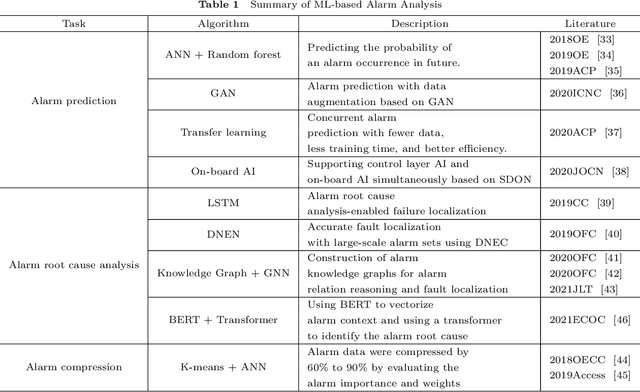
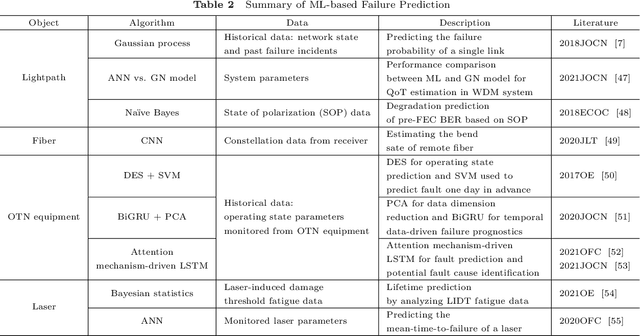
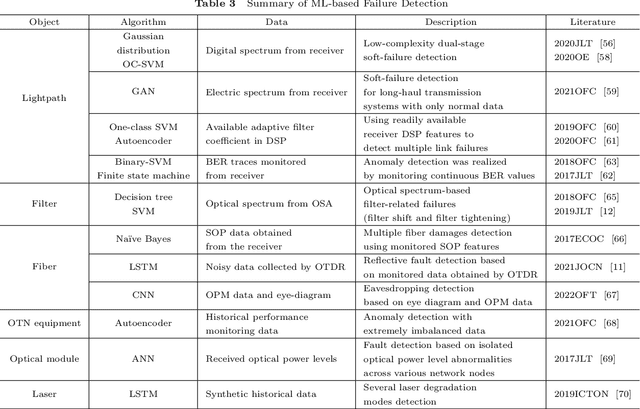
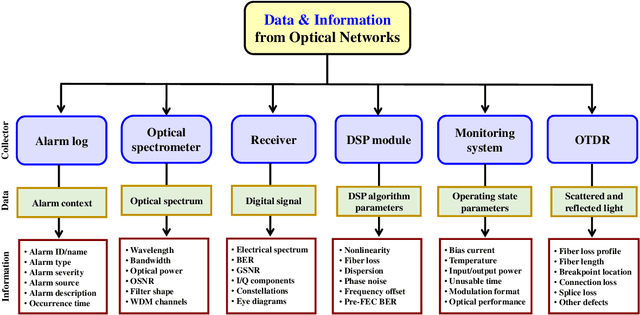
Failure management plays a significant role in optical networks. It ensures secure operation, mitigates potential risks, and executes proactive protection. Machine learning (ML) is considered to be an extremely powerful technique for performing comprehensive data analysis and complex network management and is widely utilized for failure management in optical networks to revolutionize the conventional manual methods. In this study, the background of failure management is introduced, where typical failure tasks, physical objects, ML algorithms, data source, and extracted information are illustrated in detail. An overview of the applications of ML in failure management is provided in terms of alarm analysis, failure prediction, failure detection, failure localization, and failure identification. Finally, the future directions on ML for failure management are discussed from the perspective of data, model, task, and emerging techniques.
MRI-MECH: Mechanics-informed MRI to estimate esophageal health
Sep 15, 2022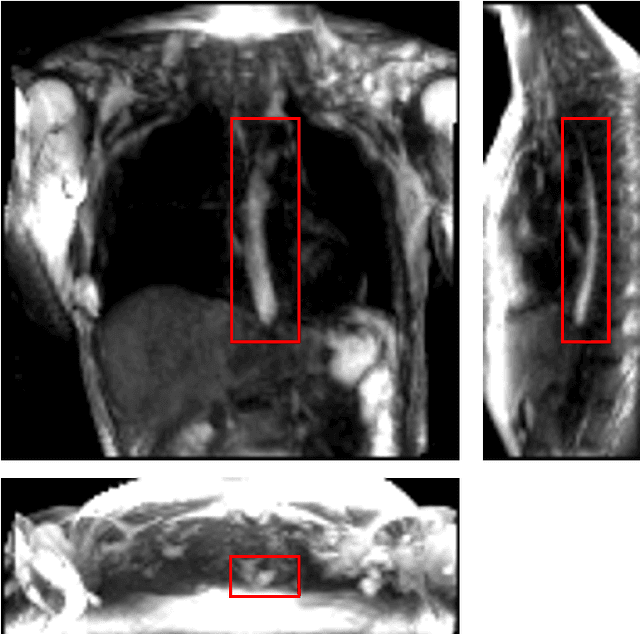
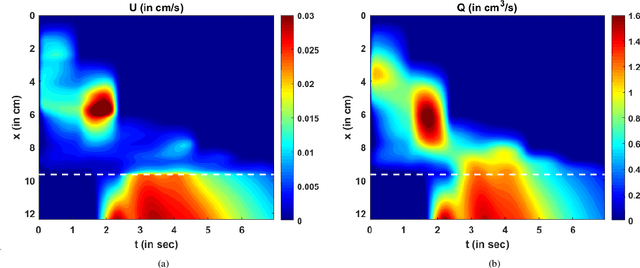
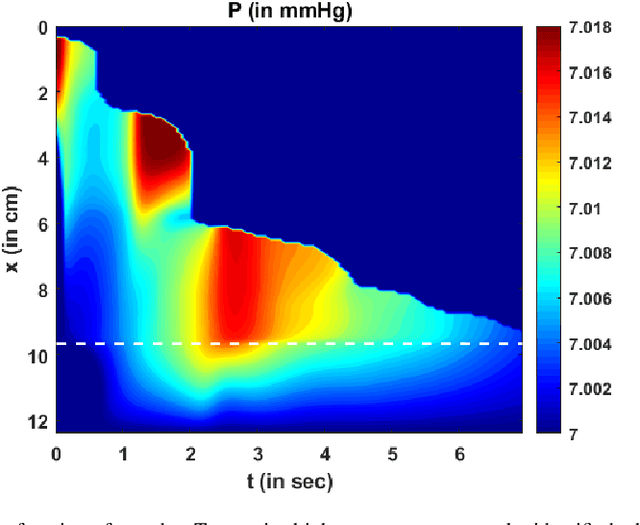
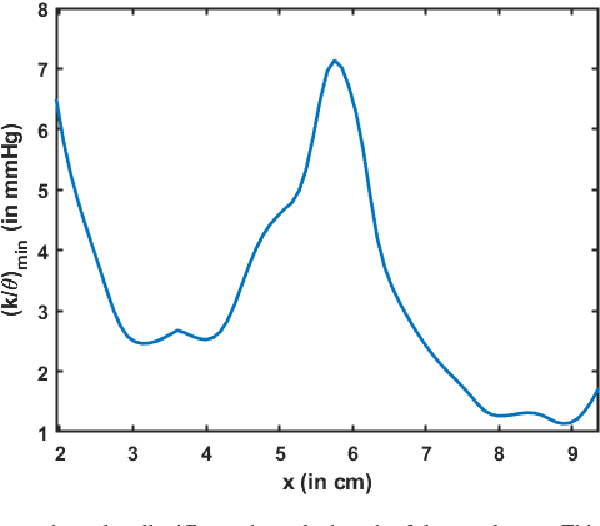
Dynamic magnetic resonance imaging (MRI) is a popular medical imaging technique to generate image sequences of the flow of a contrast material inside tissues and organs. However, its application to imaging bolus movement through the esophagus has only been demonstrated in few feasibility studies and is relatively unexplored. In this work, we present a computational framework called mechanics-informed MRI (MRI-MECH) that enhances that capability thereby increasing the applicability of dynamic MRI for diagnosing esophageal disorders. Pineapple juice was used as the swallowed contrast material for the dynamic MRI and the MRI image sequence was used as input to the MRI-MECH. The MRI-MECH modeled the esophagus as a flexible one-dimensional tube and the elastic tube walls followed a linear tube law. Flow through the esophagus was then governed by one-dimensional mass and momentum conservation equations. These equations were solved using a physics-informed neural network (PINN). The PINN minimized the difference between the measurements from the MRI and model predictions ensuring that the physics of the fluid flow problem was always followed. MRI-MECH calculated the fluid velocity and pressure during esophageal transit and estimated the mechanical health of the esophagus by calculating wall stiffness and active relaxation. Additionally, MRI-MECH predicted missing information about the lower esophageal sphincter during the emptying process, demonstrating its applicability to scenarios with missing data or poor image resolution. In addition to potentially improving clinical decisions based on quantitative estimates of the mechanical health of the esophagus, MRI-MECH can also be enhanced for application to other medical imaging modalities to enhance their functionality as well.
A Scene-Text Synthesis Engine Achieved Through Learning from Decomposed Real-World Data
Sep 06, 2022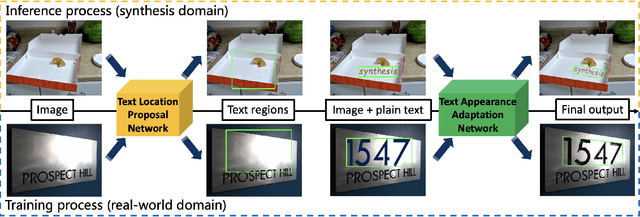
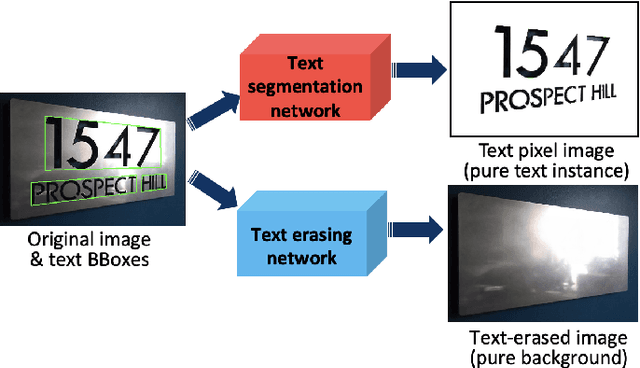


Scene-text image synthesis techniques aimed at naturally composing text instances on background scene images are very appealing for training deep neural networks because they can provide accurate and comprehensive annotation information. Prior studies have explored generating synthetic text images on two-dimensional and three-dimensional surfaces based on rules derived from real-world observations. Some of these studies have proposed generating scene-text images from learning; however, owing to the absence of a suitable training dataset, unsupervised frameworks have been explored to learn from existing real-world data, which may not result in a robust performance. To ease this dilemma and facilitate research on learning-based scene text synthesis, we propose DecompST, a real-world dataset prepared using public benchmarks, with three types of annotations: quadrilateral-level BBoxes, stroke-level text masks, and text-erased images. Using the DecompST dataset, we propose an image synthesis engine that includes a text location proposal network (TLPNet) and a text appearance adaptation network (TAANet). TLPNet first predicts the suitable regions for text embedding. TAANet then adaptively changes the geometry and color of the text instance according to the context of the background. Our comprehensive experiments verified the effectiveness of the proposed method for generating pretraining data for scene text detectors.
Towards Disentangled Speech Representations
Aug 28, 2022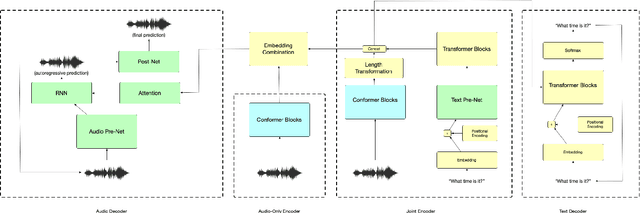
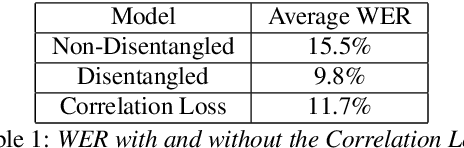

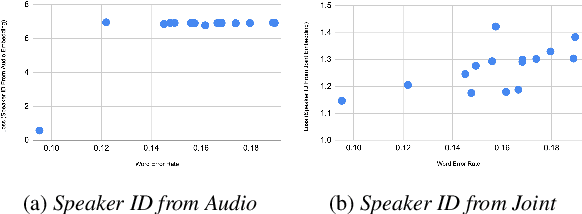
The careful construction of audio representations has become a dominant feature in the design of approaches to many speech tasks. Increasingly, such approaches have emphasized "disentanglement", where a representation contains only parts of the speech signal relevant to transcription while discarding irrelevant information. In this paper, we construct a representation learning task based on joint modeling of ASR and TTS, and seek to learn a representation of audio that disentangles that part of the speech signal that is relevant to transcription from that part which is not. We present empirical evidence that successfully finding such a representation is tied to the randomness inherent in training. We then make the observation that these desired, disentangled solutions to the optimization problem possess unique statistical properties. Finally, we show that enforcing these properties during training improves WER by 24.5% relative on average for our joint modeling task. These observations motivate a novel approach to learning effective audio representations.
Task Selection for AutoML System Evaluation
Aug 26, 2022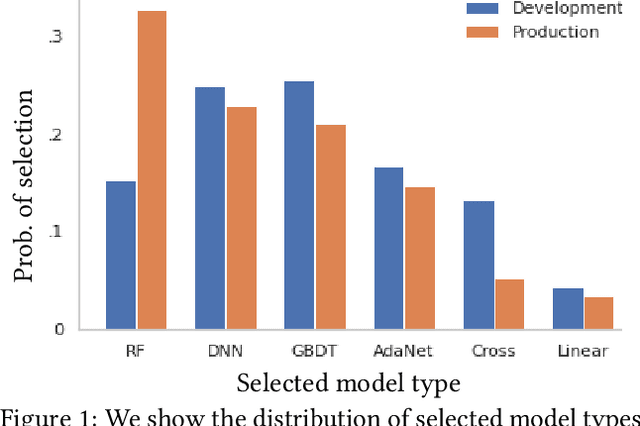

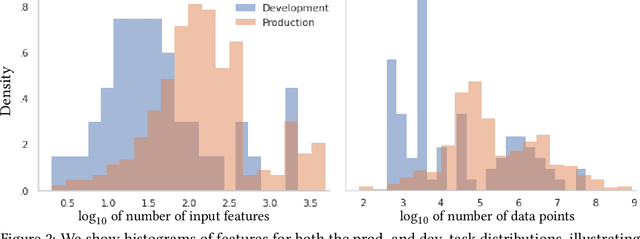

Our goal is to assess if AutoML system changes - i.e., to the search space or hyperparameter optimization - will improve the final model's performance on production tasks. However, we cannot test the changes on production tasks. Instead, we only have access to limited descriptors about tasks that our AutoML system previously executed, like the number of data points or features. We also have a set of development tasks to test changes, ex., sampled from OpenML with no usage constraints. However, the development and production task distributions are different leading us to pursue changes that only improve development and not production. This paper proposes a method to leverage descriptor information about AutoML production tasks to select a filtered subset of the most relevant development tasks. Empirical studies show that our filtering strategy improves the ability to assess AutoML system changes on holdout tasks with different distributions than development.
Language-aware Domain Generalization Network for Cross-Scene Hyperspectral Image Classification
Sep 06, 2022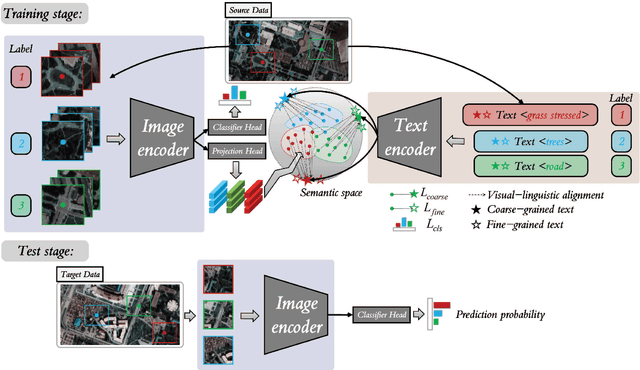
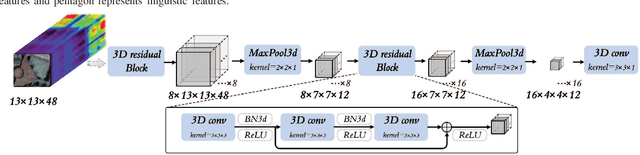
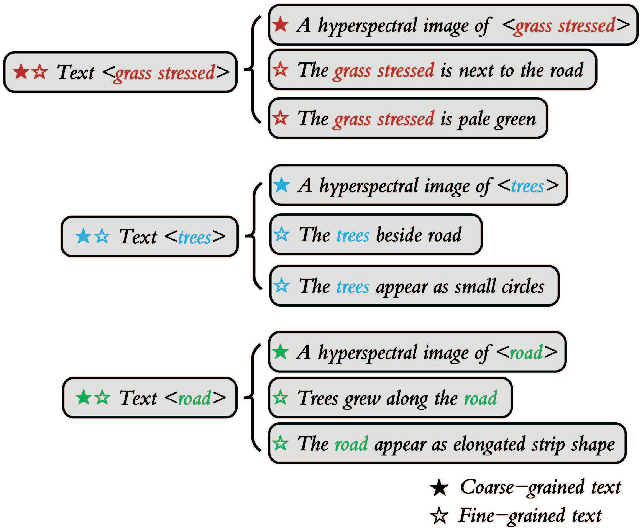
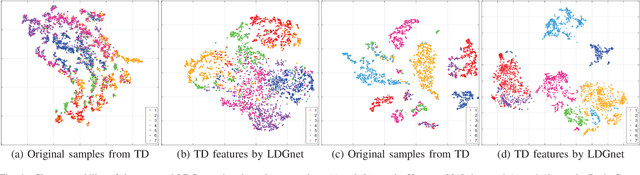
Text information including extensive prior knowledge about land cover classes has been ignored in hyperspectral image classification (HSI) tasks. It is necessary to explore the effectiveness of linguistic mode in assisting HSI classification. In addition, the large-scale pre-training image-text foundation models have demonstrated great performance in a variety of downstream applications, including zero-shot transfer. However, most domain generalization methods have never addressed mining linguistic modal knowledge to improve the generalization performance of model. To compensate for the inadequacies listed above, a Language-aware Domain Generalization Network (LDGnet) is proposed to learn cross-domain invariant representation from cross-domain shared prior knowledge. The proposed method only trains on the source domain (SD) and then transfers the model to the target domain (TD). The dual-stream architecture including image encoder and text encoder is used to extract visual and linguistic features, in which coarse-grained and fine-grained text representations are designed to extract two levels of linguistic features. Furthermore, linguistic features are used as cross-domain shared semantic space, and visual-linguistic alignment is completed by supervised contrastive learning in semantic space. Extensive experiments on three datasets demonstrate the superiority of the proposed method when compared with state-of-the-art techniques.