 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttentNet: Fully Convolutional 3D Attention for Lung Nodule Detection
Jul 19, 2024



Motivated by the increasing popularity of attention mechanisms, we observe that popular convolutional (conv.) attention models like Squeeze-and-Excite (SE) and Convolutional Block Attention Module (CBAM) rely on expensive multi-layer perception (MLP) layers. These MLP layers significantly increase computational complexity, making such models less applicable to 3D image contexts, where data dimensionality and computational costs are higher. In 3D medical imaging, such as 3D pulmonary CT scans, efficient processing is crucial due to the large data volume. Traditional 2D attention generalized to 3D increases the computational load, creating demand for more efficient attention mechanisms for 3D tasks. We investigate the possibility of incorporating fully convolutional (conv.) attention in 3D context. We present two 3D fully conv. attention blocks, demonstrating their effectiveness in 3D context. Using pulmonary CT scans for 3D lung nodule detection, we present AttentNet, an automated lung nodule detection framework from CT images, performing detection as an ensemble of two stages, candidate proposal and false positive (FP) reduction. We compare the proposed 3D attention blocks to popular 2D conv. attention methods generalized to 3D modules and to self-attention units. For the FP reduction stage, we also use a joint analysis approach to aggregate spatial information from different contextual levels. We use LUNA-16 lung nodule detection dataset to demonstrate the benefits of the proposed fully conv. attention blocks compared to baseline popular lung nodule detection methods when no attention is used. Our work does not aim at achieving state-of-the-art results in the lung nodule detection task, rather to demonstrate the benefits of incorporating fully conv. attention within a 3D context.
MLMT-CNN for Object Detection and Segmentation in Multi-layer and Multi-spectral Images
Jul 19, 2024Precisely localising solar Active Regions (AR) from multi-spectral images is a challenging but important task in understanding solar activity and its influence on space weather. A main challenge comes from each modality capturing a different location of the 3D objects, as opposed to typical multi-spectral imaging scenarios where all image bands observe the same scene. Thus, we refer to this special multi-spectral scenario as multi-layer. We present a multi-task deep learning framework that exploits the dependencies between image bands to produce 3D AR localisation (segmentation and detection) where different image bands (and physical locations) have their own set of results. Furthermore, to address the difficulty of producing dense AR annotations for training supervised machine learning (ML) algorithms, we adapt a training strategy based on weak labels (i.e. bounding boxes) in a recursive manner. We compare our detection and segmentation stages against baseline approaches for solar image analysis (multi-channel coronal hole detection, SPOCA for ARs) and state-of-the-art deep learning methods (Faster RCNN, U-Net). Additionally, both detection a nd segmentation stages are quantitatively validated on artificially created data of similar spatial configurations made from annotated multi-modal magnetic resonance images. Our framework achieves an average of 0.72 IoU (segmentation) and 0.90 F1 score (detection) across all modalities, comparing to the best performing baseline methods with scores of 0.53 and 0.58, respectively, on the artificial dataset, and 0.84 F1 score in the AR detection task comparing to baseline of 0.82 F1 score. Our segmentation results are qualitatively validated by an expert on real ARs.
Removing cloud shadows from ground-based solar imagery
Jul 18, 2024



The study and prediction of space weather entails the analysis of solar images showing structures of the Sun's atmosphere. When imaged from the Earth's ground, images may be polluted by terrestrial clouds which hinder the detection of solar structures. We propose a new method to remove cloud shadows, based on a U-Net architecture, and compare classical supervision with conditional GAN. We evaluate our method on two different imaging modalities, using both real images and a new dataset of synthetic clouds. Quantitative assessments are obtained through image quality indices (RMSE, PSNR, SSIM, and FID). We demonstrate improved results with regards to the traditional cloud removal technique and a sparse coding baseline, on different cloud types and textures.
Multi-scale gridded Gabor attention for cirrus segmentation
Jul 11, 2024In this paper, we address the challenge of segmenting global contaminants in large images. The precise delineation of such structures requires ample global context alongside understanding of textural patterns. CNNs specialise in the latter, though their ability to generate global features is limited. Attention measures long range dependencies in images, capturing global context, though at a large computational cost. We propose a gridded attention mechanism to address this limitation, greatly increasing efficiency by processing multi-scale features into smaller tiles. We also enhance the attention mechanism for increased sensitivity to texture orientation, by measuring correlations across features dependent on different orientations, in addition to channel and positional attention. We present results on a new dataset of astronomical images, where the task is segmenting large contaminating dust clouds.
Panoptic Segmentation of Galactic Structures in LSB Images
Jul 10, 2024


We explore the use of deep learning to localise galactic structures in low surface brightness (LSB) images. LSB imaging reveals many interesting structures, though these are frequently confused with galactic dust contamination, due to a strong local visual similarity. We propose a novel unified approach to multi-class segmentation of galactic structures and of extended amorphous image contaminants. Our panoptic segmentation model combines Mask R-CNN with a contaminant specialised network and utilises an adaptive preprocessing layer to better capture the subtle features of LSB images. Further, a human-in-the-loop training scheme is employed to augment ground truth labels. These different approaches are evaluated in turn, and together greatly improve the detection of both galactic structures and contaminants in LSB images.
Domain-informed graph neural networks: a quantum chemistry case study
Aug 25, 2022
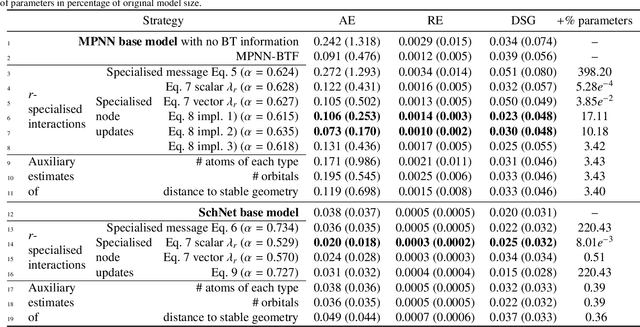
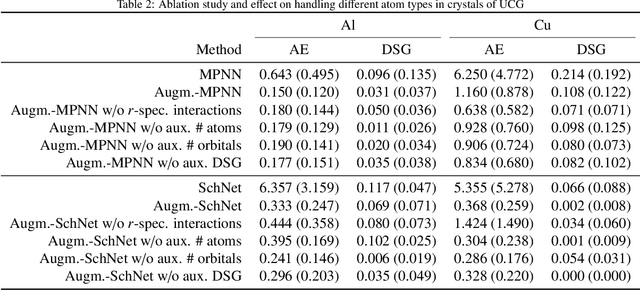
We explore different strategies to integrate prior domain knowledge into the design of a deep neural network (DNN). We focus on graph neural networks (GNN), with a use case of estimating the potential energy of chemical systems (molecules and crystals) represented as graphs. We integrate two elements of domain knowledge into the design of the GNN to constrain and regularise its learning, towards higher accuracy and generalisation. First, knowledge on the existence of different types of relations (chemical bonds) between atoms is used to modulate the interaction of nodes in the GNN. Second, knowledge of the relevance of some physical quantities is used to constrain the learnt features towards a higher physical relevance using a simple multi-task paradigm. We demonstrate the general applicability of our knowledge integrations by applying them to two architectures that rely on different mechanisms to propagate information between nodes and to update node states.
Detecting Humans in RGB-D Data with CNNs
Jul 17, 2022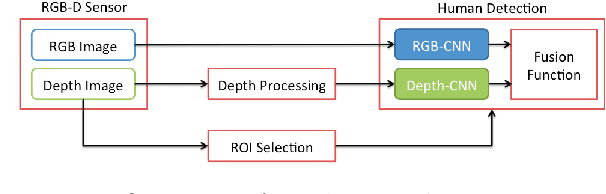
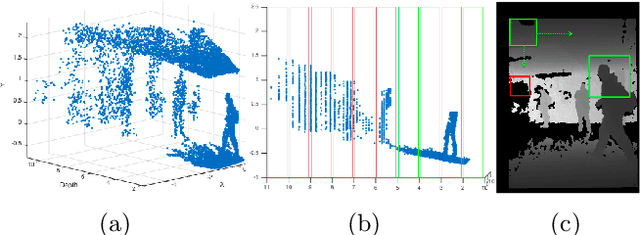
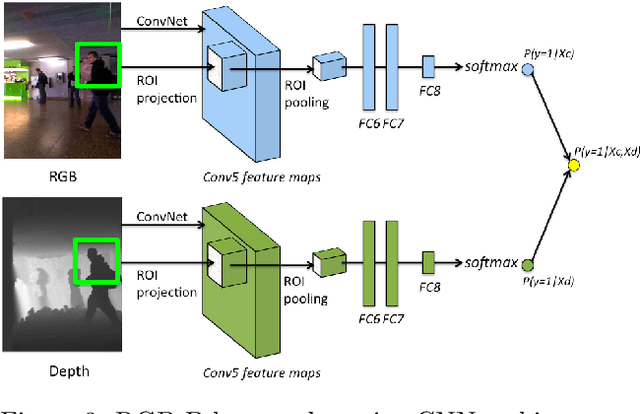
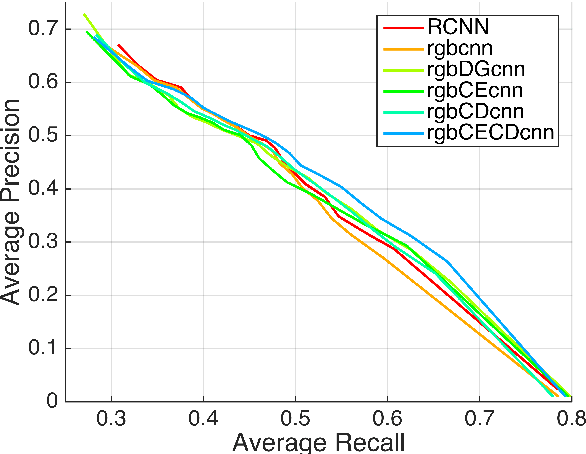
We address the problem of people detection in RGB-D data where we leverage depth information to develop a region-of-interest (ROI) selection method that provides proposals to two color and depth CNNs. To combine the detections produced by the two CNNs, we propose a novel fusion approach based on the characteristics of depth images. We also present a new depth-encoding scheme, which not only encodes depth images into three channels but also enhances the information for classification. We conduct experiments on a publicly available RGB-D people dataset and show that our approach outperforms the baseline models that only use RGB data.
A DNN Framework for Learning Lagrangian Drift With Uncertainty
Apr 12, 2022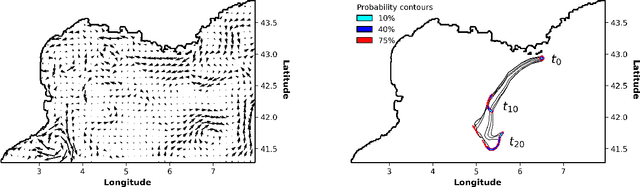

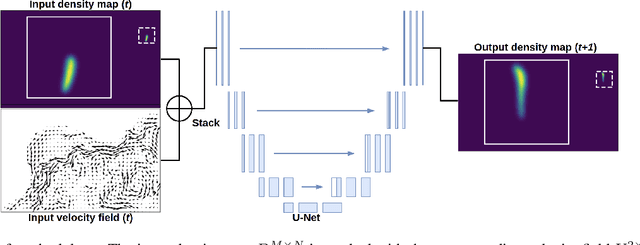
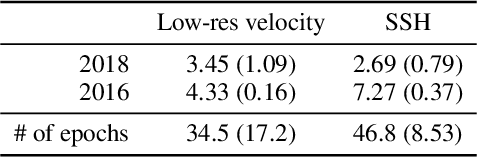
Reconstructions of Lagrangian drift, for example for objects lost at sea, are often uncertain due to unresolved physical phenomena within the data. Uncertainty is usually overcome by introducing stochasticity into the drift, but this approach requires specific assumptions for modelling uncertainty. We remove this constraint by presenting a purely data-driven framework for modelling probabilistic drift in flexible environments. We train a CNN to predict the temporal evolution of probability density maps of particle locations from $t$ to $t+1$ given an input velocity field. We generate groundtruth density maps on the basis of ocean circulation model simulations by simulating uncertainty in the initial position of particle trajectories. Several loss functions for regressing the predicted density maps are tested. Through evaluating our model on unseen velocities from a different year, we find its outputs to be in good agreement with numerical simulations, suggesting satisfactory generalisation to different dynamical situations.
Adaptive Neighbourhoods for the Discovery of Adversarial Examples
Jan 22, 2021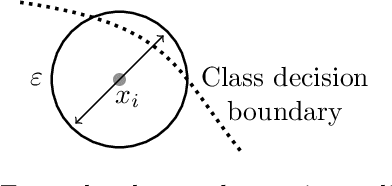

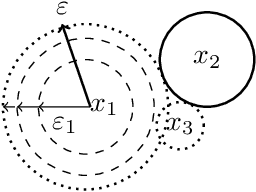
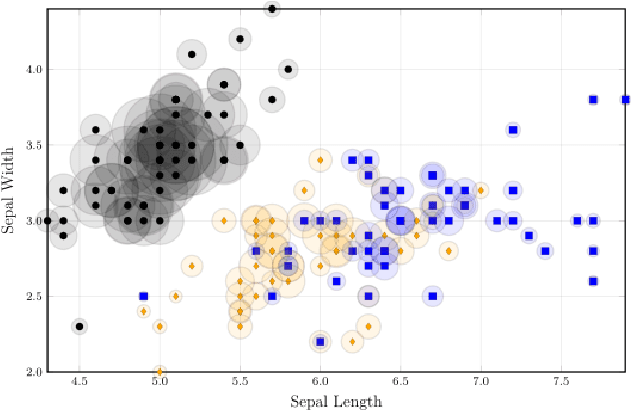
Deep Neural Networks (DNNs) have often supplied state-of-the-art results in pattern recognition tasks. Despite their advances, however, the existence of adversarial examples have caught the attention of the community. Many existing works have proposed methods for searching for adversarial examples within fixed-sized regions around training points. Our work complements and improves these existing approaches by adapting the size of these regions based on the problem complexity and data sampling density. This makes such approaches more appropriate for other types of data and may further improve adversarial training methods by increasing the region sizes without creating incorrect labels.
Learnable Gabor modulated complex-valued networks for orientation robustness
Nov 23, 2020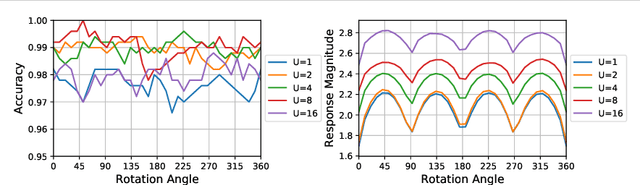



Robustness to transformation is desirable in many computer vision tasks, given that input data often exhibits pose variance within classes. While translation invariance and equivariance is a documented phenomenon of CNNs, sensitivity to other transformations is typically encouraged through data augmentation. We investigate the modulation of complex valued convolutional weights with learned Gabor filters to enable orientation robustness. With Gabor modulation, the designed network is able to generate orientation dependent features free of interpolation with a single set of rotation-governing parameters. Moreover, by learning rotation parameters alongside traditional convolutional weights, the representation space is not constrained and may adapt to the exact input transformation. We present Learnable Convolutional Gabor Networks (LCGNs), that are parameter-efficient and offer increased model complexity while keeping backpropagation simple. We demonstrate that learned Gabor modulation utilising an end-to-end complex architecture enables rotation invariance and equivariance on MNIST and a new dataset of simulated images of galactic cirri.