 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
IntereStyle: Encoding an Interest Region for Robust StyleGAN Inversion
Sep 22, 2022

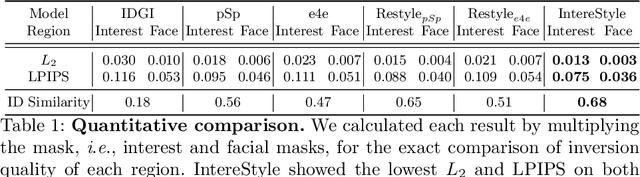

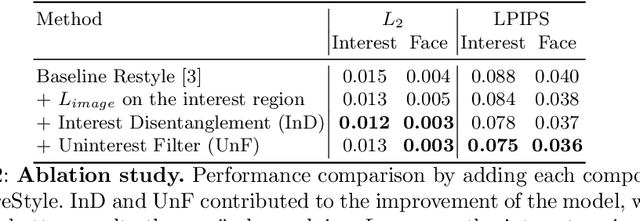
Recently, manipulation of real-world images has been highly elaborated along with the development of Generative Adversarial Networks (GANs) and corresponding encoders, which embed real-world images into the latent space. However, designing encoders of GAN still remains a challenging task due to the trade-off between distortion and perception. In this paper, we point out that the existing encoders try to lower the distortion not only on the interest region, e.g., human facial region but also on the uninterest region, e.g., background patterns and obstacles. However, most uninterest regions in real-world images are located at out-of-distribution (OOD), which are infeasible to be ideally reconstructed by generative models. Moreover, we empirically find that the uninterest region overlapped with the interest region can mangle the original feature of the interest region, e.g., a microphone overlapped with a facial region is inverted into the white beard. As a result, lowering the distortion of the whole image while maintaining the perceptual quality is very challenging. To overcome this trade-off, we propose a simple yet effective encoder training scheme, coined IntereStyle, which facilitates encoding by focusing on the interest region. IntereStyle steers the encoder to disentangle the encodings of the interest and uninterest regions. To this end, we filter the information of the uninterest region iteratively to regulate the negative impact of the uninterest region. We demonstrate that IntereStyle achieves both lower distortion and higher perceptual quality compared to the existing state-of-the-art encoders. Especially, our model robustly conserves features of the original images, which shows the robust image editing and style mixing results. We will release our code with the pre-trained model after the review.
DS-MVSNet: Unsupervised Multi-view Stereo via Depth Synthesis
Aug 13, 2022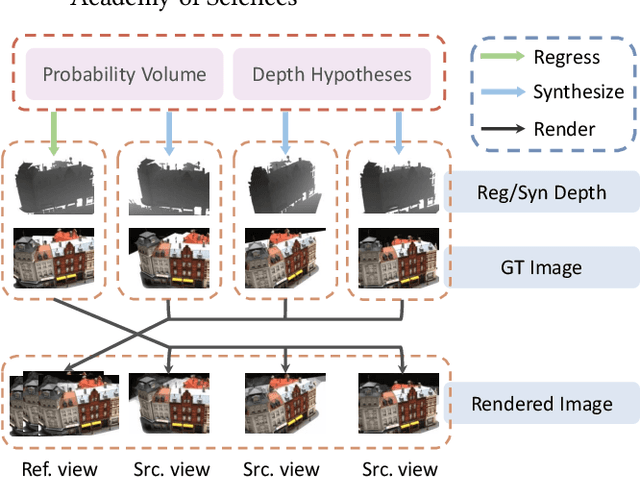
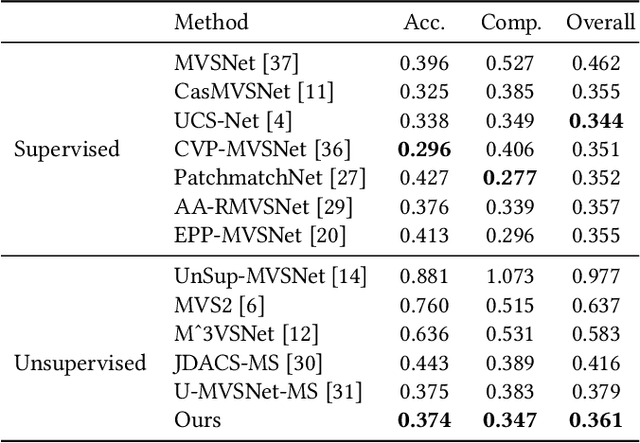


In recent years, supervised or unsupervised learning-based MVS methods achieved excellent performance compared with traditional methods. However, these methods only use the probability volume computed by cost volume regularization to predict reference depths and this manner cannot mine enough information from the probability volume. Furthermore, the unsupervised methods usually try to use two-step or additional inputs for training which make the procedure more complicated. In this paper, we propose the DS-MVSNet, an end-to-end unsupervised MVS structure with the source depths synthesis. To mine the information in probability volume, we creatively synthesize the source depths by splattering the probability volume and depth hypotheses to source views. Meanwhile, we propose the adaptive Gaussian sampling and improved adaptive bins sampling approach that improve the depths hypotheses accuracy. On the other hand, we utilize the source depths to render the reference images and propose depth consistency loss and depth smoothness loss. These can provide additional guidance according to photometric and geometric consistency in different views without additional inputs. Finally, we conduct a series of experiments on the DTU dataset and Tanks & Temples dataset that demonstrate the efficiency and robustness of our DS-MVSNet compared with the state-of-the-art methods.
ATP: A holistic attention integrated approach to enhance ABSA
Aug 04, 2022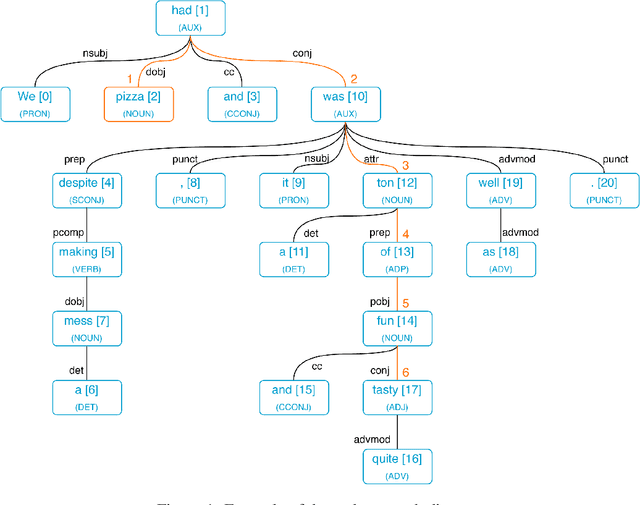
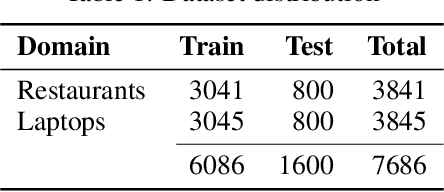
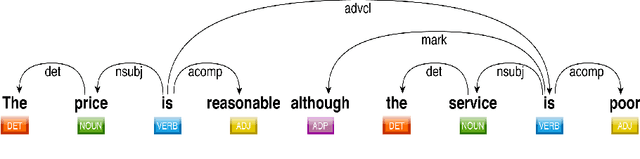
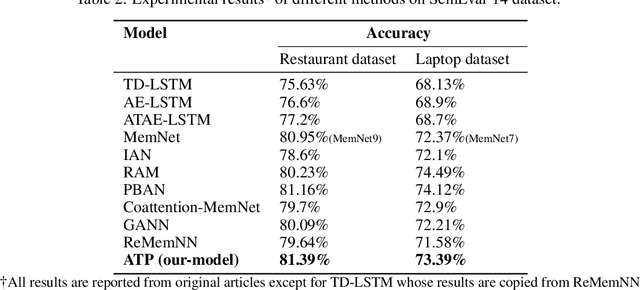
Aspect based sentiment analysis (ABSA) deals with the identification of the sentiment polarity of a review sentence towards a given aspect. Deep Learning sequential models like RNN, LSTM, and GRU are current state-of-the-art methods for inferring the sentiment polarity. These methods work well to capture the contextual relationship between the words of a review sentence. However, these methods are insignificant in capturing long-term dependencies. Attention mechanism plays a significant role by focusing only on the most crucial part of the sentence. In the case of ABSA, aspect position plays a vital role. Words near to aspect contribute more while determining the sentiment towards the aspect. Therefore, we propose a method that captures the position based information using dependency parsing tree and helps attention mechanism. Using this type of position information over a simple word-distance-based position enhances the deep learning model's performance. We performed the experiments on SemEval'14 dataset to demonstrate the effect of dependency parsing relation-based attention for ABSA.
Learning to Predict Persona Information forDialogue Personalization without Explicit Persona Description
Nov 30, 2021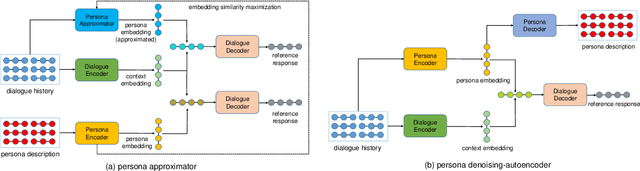
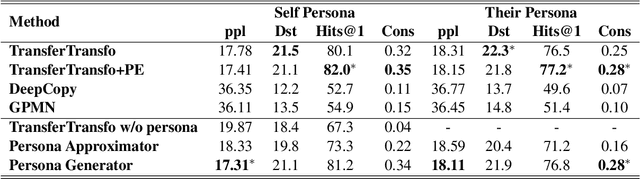
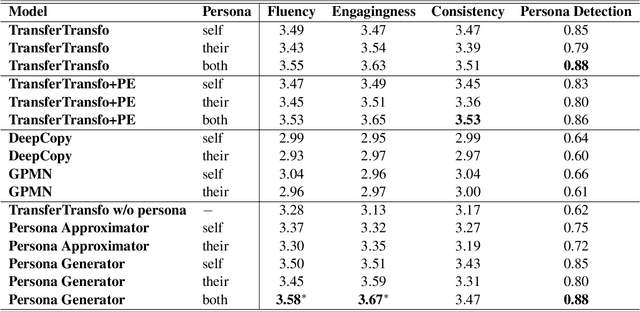
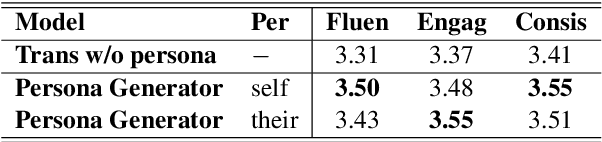
Personalizing dialogue agents is important for dialogue systems to generate more specific, consistent, and engaging responses. However, most current dialogue personalization approaches rely on explicit persona descriptions during inference, which severely restricts its application. In this paper, we propose a novel approach that learns to predict persona information based on the dialogue history to personalize the dialogue agent without relying on any explicit persona descriptions during inference. Experimental results on the PersonaChat dataset show that the proposed method can improve the consistency of generated responses when conditioning on the predicted profile of the dialogue agent (i.e. "self persona"), and improve the engagingness of the generated responses when conditioning on the predicted persona of the dialogue partner (i.e. "their persona"). We also find that a trained persona prediction model can be successfully transferred to other datasets and help generate more relevant responses.
Conditional Independence Testing via Latent Representation Learning
Sep 04, 2022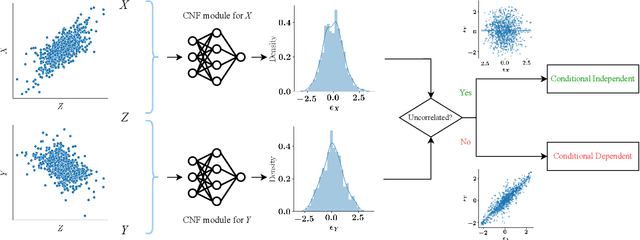
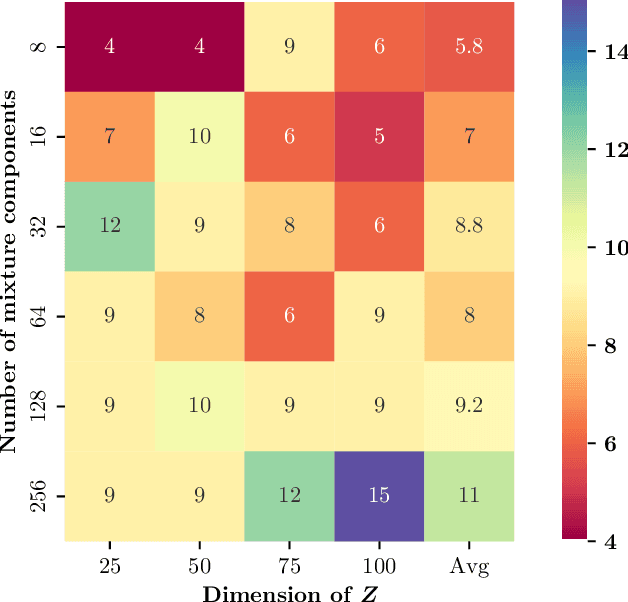
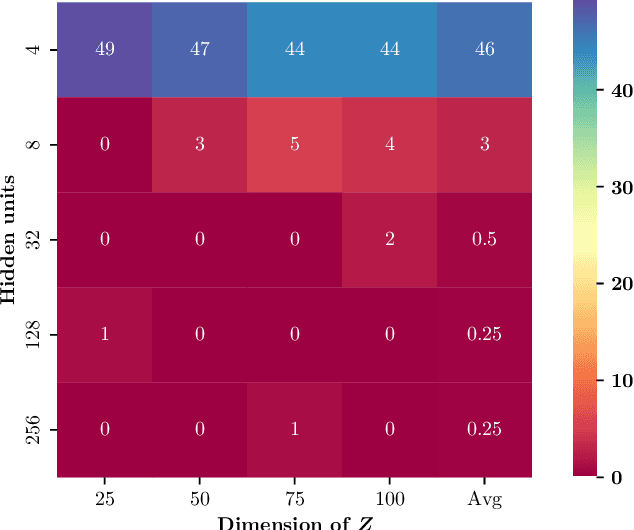
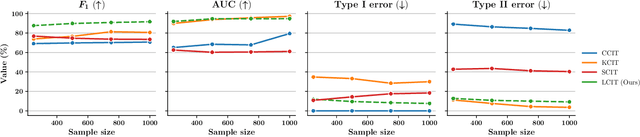
Detecting conditional independencies plays a key role in several statistical and machine learning tasks, especially in causal discovery algorithms. In this study, we introduce LCIT (Latent representation based Conditional Independence Test)-a novel non-parametric method for conditional independence testing based on representation learning. Our main contribution involves proposing a generative framework in which to test for the independence between X and Y given Z, we first learn to infer the latent representations of target variables X and Y that contain no information about the conditioning variable Z. The latent variables are then investigated for any significant remaining dependencies, which can be performed using the conventional partial correlation test. The empirical evaluations show that LCIT outperforms several state-of-the-art baselines consistently under different evaluation metrics, and is able to adapt really well to both non-linear and high-dimensional settings on a diverse collection of synthetic and real data sets.
Adversarial Learning-based Stance Classifier for COVID-19-related Health Policies
Sep 10, 2022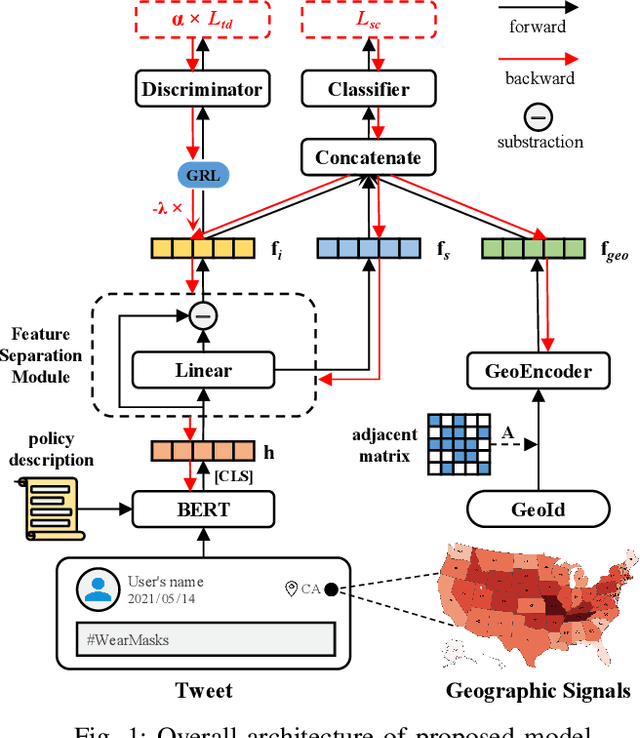
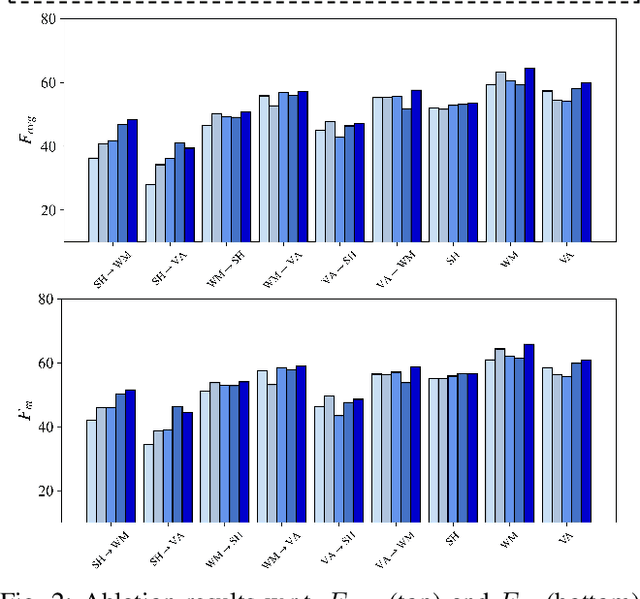
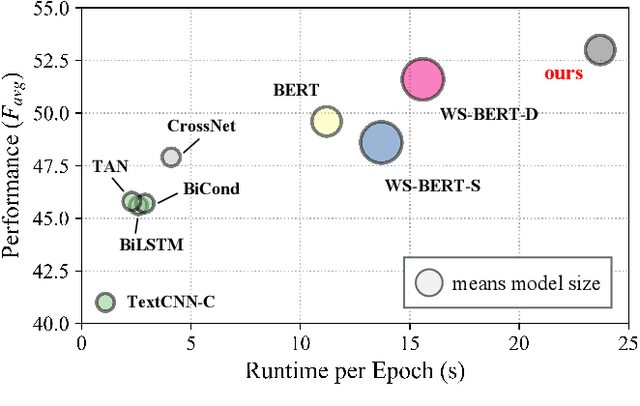
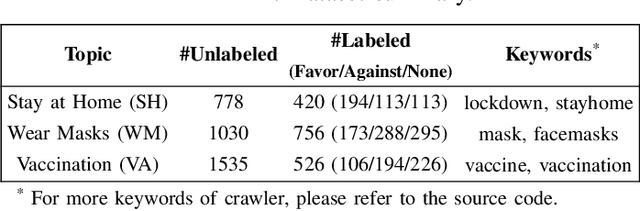
The ongoing COVID-19 pandemic has caused immeasurable losses for people worldwide. To contain the spread of virus and further alleviate the crisis, various health policies (e.g., stay-at-home orders) have been issued which spark heat discussion as users turn to share their attitudes on social media. In this paper, we consider a more realistic scenario on stance detection (i.e., cross-target and zero-shot settings) for the pandemic and propose an adversarial learning-based stance classifier to automatically identify the public attitudes toward COVID-19-related health policies. Specifically, we adopt adversarial learning which allows the model to train on a large amount of labeled data and capture transferable knowledge from source topics, so as to enable generalize to the emerging health policy with sparse labeled data. Meanwhile, a GeoEncoder is designed which encourages model to learn unobserved contextual factors specified by each region and represents them as non-text information to enhance model's deeper understanding. We evaluate the performance of a broad range of baselines in stance detection task for COVID-19-related policies, and experimental results show that our proposed method achieves state-of-the-art performance in both cross-target and zero-shot settings.
Image quality enhancement of embedded holograms in holographic information hiding using deep neural networks
Dec 20, 2021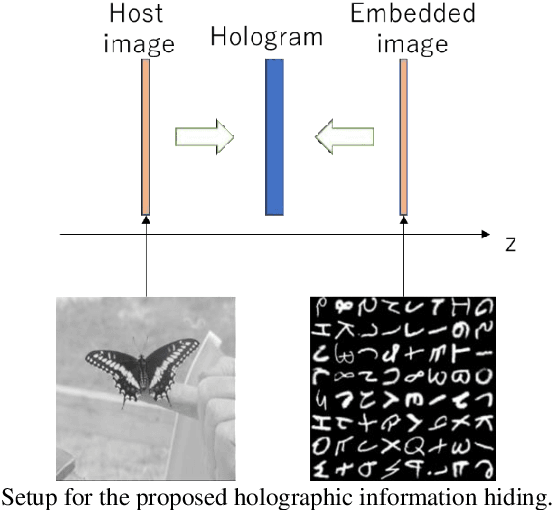

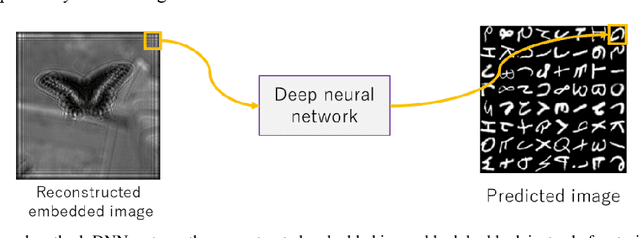
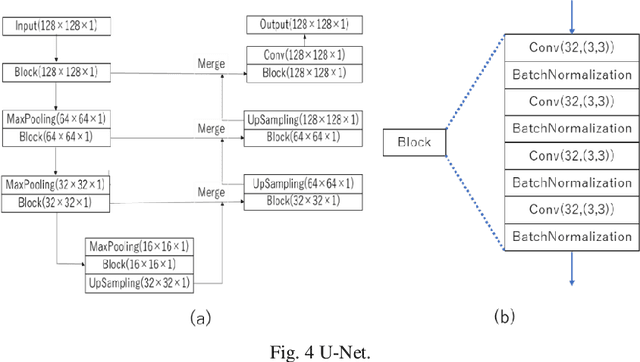
Holographic information hiding is a technique for embedding holograms or images into another hologram, used for copyright protection and steganography of holograms. Using deep neural networks, we offer a way to improve the visual quality of embedded holograms. The brightness of an embedded hologram is set to a fraction of that of the host hologram, resulting in a barely damaged reconstructed image of the host hologram. However, it is difficult to perceive because the embedded hologram's reconstructed image is darker than the reconstructed host image. In this study, we use deep neural networks to restore the darkened image.
PHEMEPlus: Enriching Social Media Rumour Verification with External Evidence
Jul 28, 2022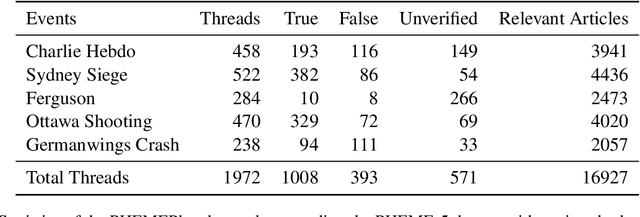


Work on social media rumour verification utilises signals from posts, their propagation and users involved. Other lines of work target identifying and fact-checking claims based on information from Wikipedia, or trustworthy news articles without considering social media context. However works combining the information from social media with external evidence from the wider web are lacking. To facilitate research in this direction, we release a novel dataset, PHEMEPlus, an extension of the PHEME benchmark, which contains social media conversations as well as relevant external evidence for each rumour. We demonstrate the effectiveness of incorporating such evidence in improving rumour verification models. Additionally, as part of the evidence collection, we evaluate various ways of query formulation to identify the most effective method.
Mining Relations among Cross-Frame Affinities for Video Semantic Segmentation
Jul 21, 2022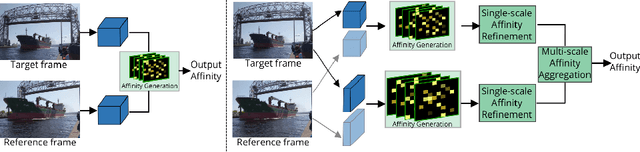
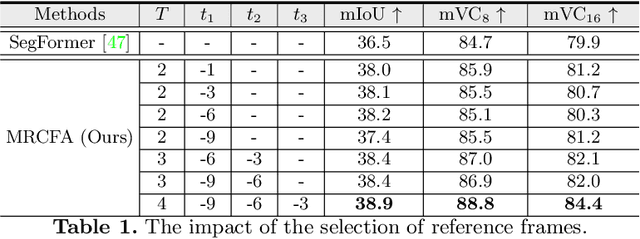
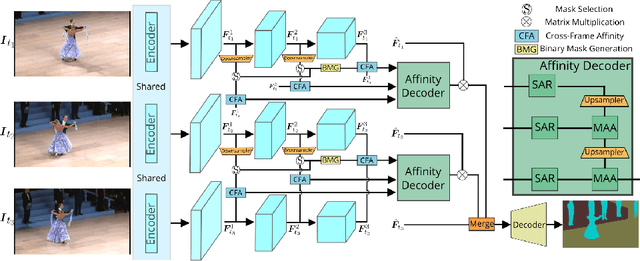
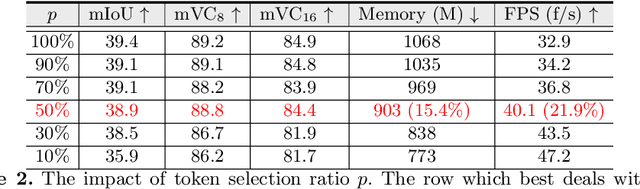
The essence of video semantic segmentation (VSS) is how to leverage temporal information for prediction. Previous efforts are mainly devoted to developing new techniques to calculate the cross-frame affinities such as optical flow and attention. Instead, this paper contributes from a different angle by mining relations among cross-frame affinities, upon which better temporal information aggregation could be achieved. We explore relations among affinities in two aspects: single-scale intrinsic correlations and multi-scale relations. Inspired by traditional feature processing, we propose Single-scale Affinity Refinement (SAR) and Multi-scale Affinity Aggregation (MAA). To make it feasible to execute MAA, we propose a Selective Token Masking (STM) strategy to select a subset of consistent reference tokens for different scales when calculating affinities, which also improves the efficiency of our method. At last, the cross-frame affinities strengthened by SAR and MAA are adopted for adaptively aggregating temporal information. Our experiments demonstrate that the proposed method performs favorably against state-of-the-art VSS methods. The code is publicly available at https://github.com/GuoleiSun/VSS-MRCFA
Graph-based Robust Sequential Localization in Obstructed LOS Situations
Jul 18, 2022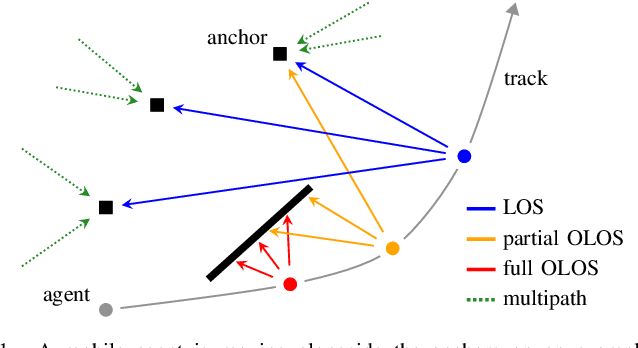
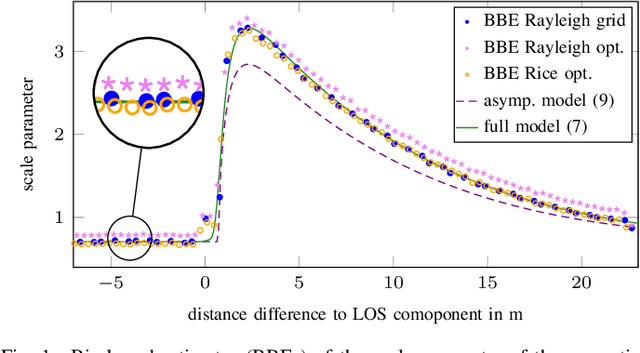
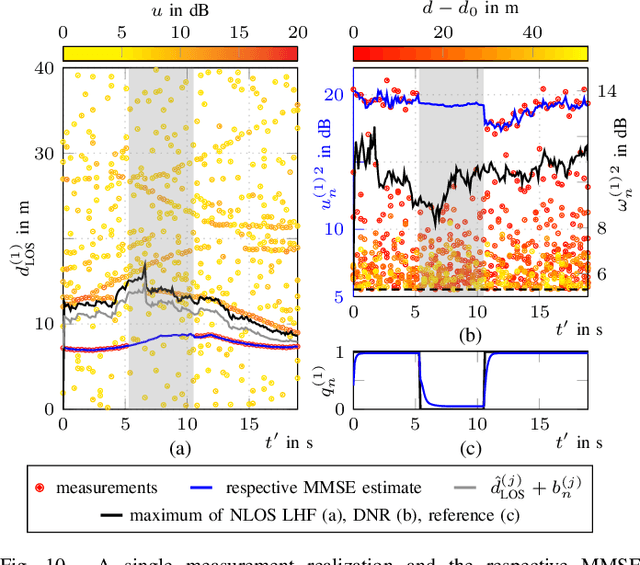
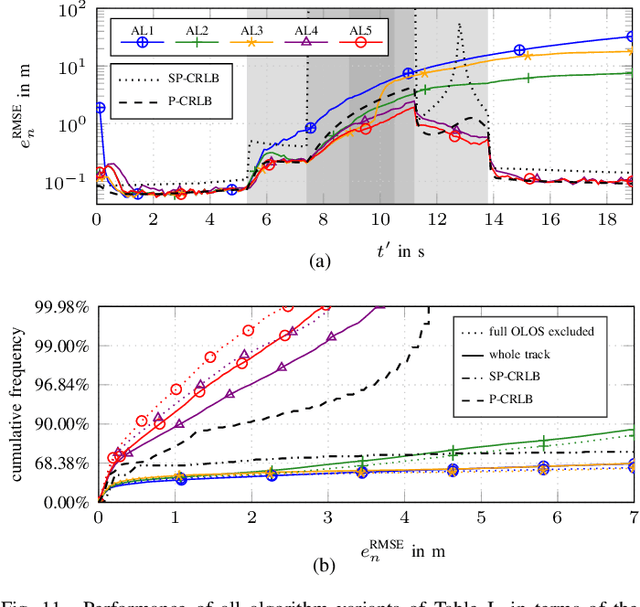
This paper presents a factor graph formulation and particle-based sum-product algorithm (SPA) for robust sequential localization in multipath-prone environments. The proposed algorithm jointly performs data association, sequential estimation of a mobile agent position, and adapts all relevant model parameters. We derive a novel non-uniform false alarm (FA) model that captures the delay and amplitude statistics of the multipath radio channel. This model enables the algorithm to indirectly exploit position-related information contained in the MPCs for the estimation of the agent position. Using simulated and real measurements, we demonstrate that the algorithm can provide high-accuracy position estimates even in fully obstructed line-of-sight (OLOS) situations, significantly outperforming the conventional amplitude-information probabilistic data association (AIPDA) filter. We show that the performance of our algorithm constantly attains the posterior Cramer-Rao lower bound (PCRLB), or even succeeds it, due to the additional information contained in the presented FA model.