 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Improving Micro-video Recommendation by Controlling Position Bias
Aug 09, 2022
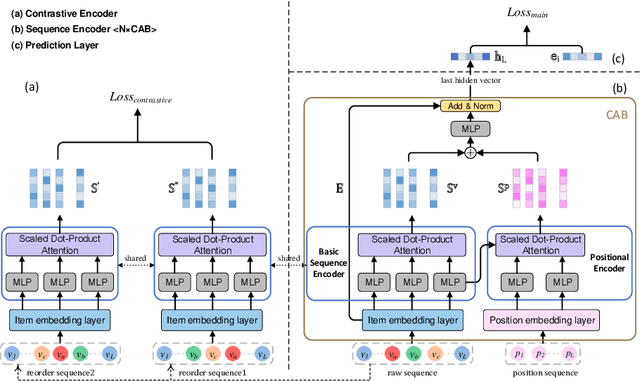
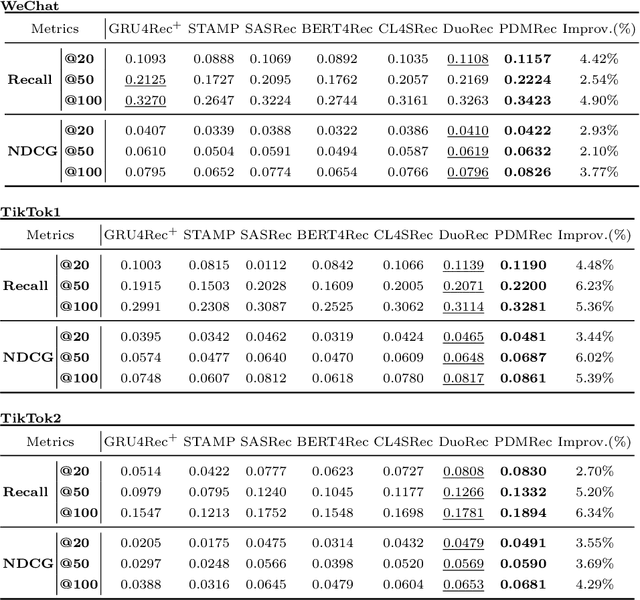
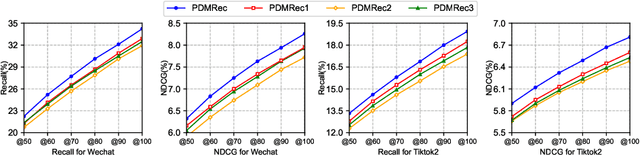
As the micro-video apps become popular, the numbers of micro-videos and users increase rapidly, which highlights the importance of micro-video recommendation. Although the micro-video recommendation can be naturally treated as the sequential recommendation, the previous sequential recommendation models do not fully consider the characteristics of micro-video apps, and in their inductive biases, the role of positions is not in accord with the reality in the micro-video scenario. Therefore, in the paper, we present a model named PDMRec (Position Decoupled Micro-video Recommendation). PDMRec applies separate self-attention modules to model micro-video information and the positional information and then aggregate them together, avoid the noisy correlations between micro-video semantics and positional information being encoded into the sequence embeddings. Moreover, PDMRec proposes contrastive learning strategies which closely match with the characteristics of the micro-video scenario, thus reducing the interference from micro-video positions in sequences. We conduct the extensive experiments on two real-world datasets. The experimental results shows that PDMRec outperforms existing multiple state-of-the-art models and achieves significant performance improvements.
EEG-based Image Feature Extraction for Visual Classification using Deep Learning
Sep 27, 2022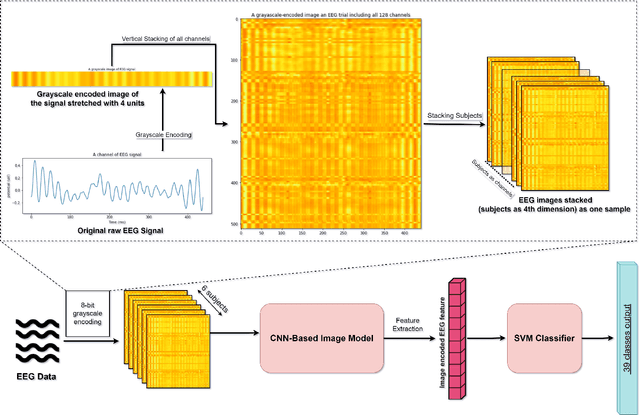
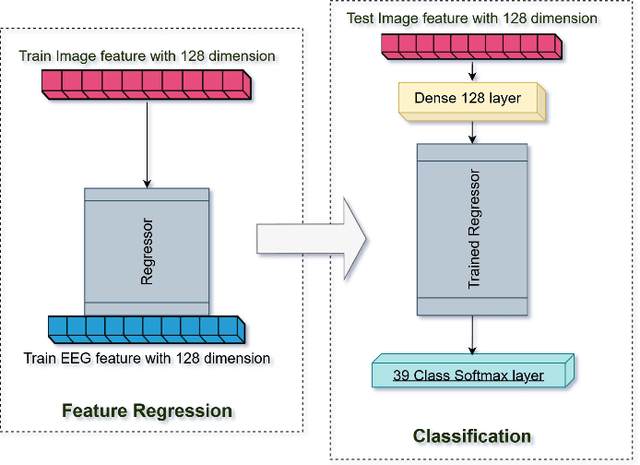
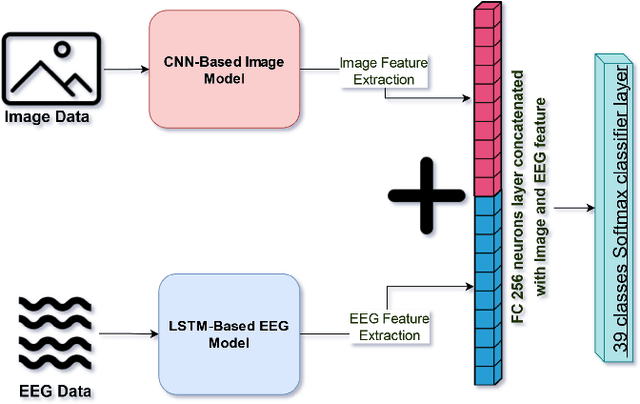
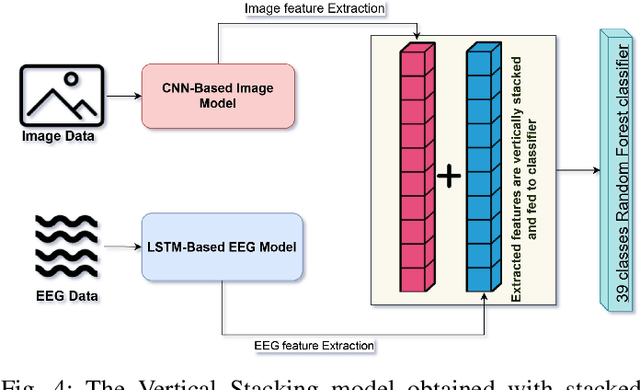
While capable of segregating visual data, humans take time to examine a single piece, let alone thousands or millions of samples. The deep learning models efficiently process sizeable information with the help of modern-day computing. However, their questionable decision-making process has raised considerable concerns. Recent studies have identified a new approach to extract image features from EEG signals and combine them with standard image features. These approaches make deep learning models more interpretable and also enables faster converging of models with fewer samples. Inspired by recent studies, we developed an efficient way of encoding EEG signals as images to facilitate a more subtle understanding of brain signals with deep learning models. Using two variations in such encoding methods, we classified the encoded EEG signals corresponding to 39 image classes with a benchmark accuracy of 70% on the layered dataset of six subjects, which is significantly higher than the existing work. Our image classification approach with combined EEG features achieved an accuracy of 82% compared to the slightly better accuracy of a pure deep learning approach; nevertheless, it demonstrates the viability of the theory.
Basic Binary Convolution Unit for Binarized Image Restoration Network
Oct 02, 2022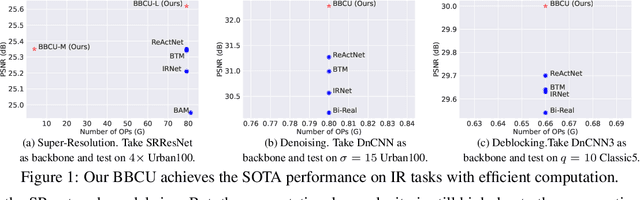
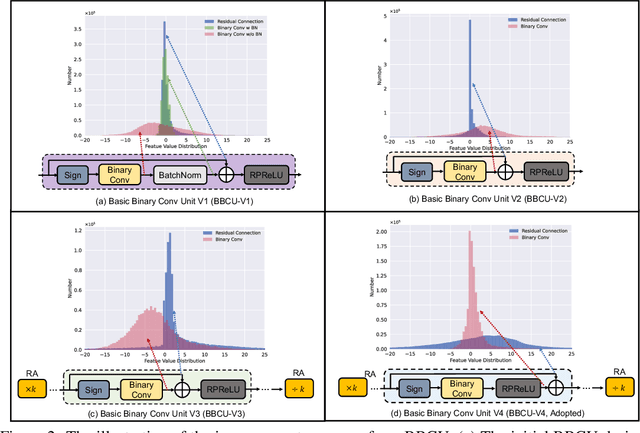
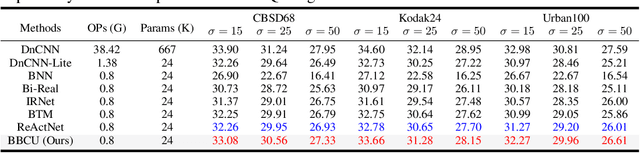
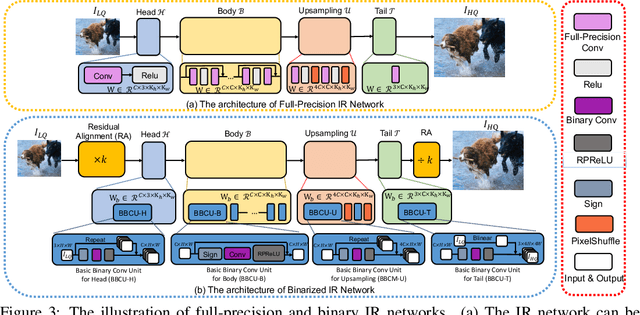
Lighter and faster image restoration (IR) models are crucial for the deployment on resource-limited devices. Binary neural network (BNN), one of the most promising model compression methods, can dramatically reduce the computations and parameters of full-precision convolutional neural networks (CNN). However, there are different properties between BNN and full-precision CNN, and we can hardly use the experience of designing CNN to develop BNN. In this study, we reconsider components in binary convolution, such as residual connection, BatchNorm, activation function, and structure, for IR tasks. We conduct systematic analyses to explain each component's role in binary convolution and discuss the pitfalls. Specifically, we find that residual connection can reduce the information loss caused by binarization; BatchNorm can solve the value range gap between residual connection and binary convolution; The position of the activation function dramatically affects the performance of BNN. Based on our findings and analyses, we design a simple yet efficient basic binary convolution unit (BBCU). Furthermore, we divide IR networks into four parts and specially design variants of BBCU for each part to explore the benefit of binarizing these parts. We conduct experiments on different IR tasks, and our BBCU significantly outperforms other BNNs and lightweight models, which shows that BBCU can serve as a basic unit for binarized IR networks. All codes and models will be released.
DARE: A large-scale handwritten date recognition system
Oct 02, 2022

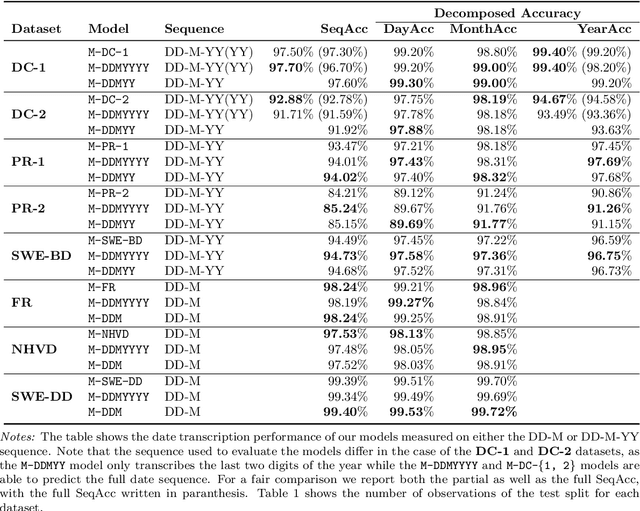

Handwritten text recognition for historical documents is an important task but it remains difficult due to a lack of sufficient training data in combination with a large variability of writing styles and degradation of historical documents. While recurrent neural network architectures are commonly used for handwritten text recognition, they are often computationally expensive to train and the benefit of recurrence drastically differs by task. For these reasons, it is important to consider non-recurrent architectures. In the context of handwritten date recognition, we propose an architecture based on the EfficientNetV2 class of models that is fast to train, robust to parameter choices, and accurately transcribes handwritten dates from a number of sources. For training, we introduce a database containing almost 10 million tokens, originating from more than 2.2 million handwritten dates which are segmented from different historical documents. As dates are some of the most common information on historical documents, and with historical archives containing millions of such documents, the efficient and automatic transcription of dates has the potential to lead to significant cost-savings over manual transcription. We show that training on handwritten text with high variability in writing styles result in robust models for general handwritten text recognition and that transfer learning from the DARE system increases transcription accuracy substantially, allowing one to obtain high accuracy even when using a relatively small training sample.
Uncertainty estimations methods for a deep learning model to aid in clinical decision-making -- a clinician's perspective
Oct 02, 2022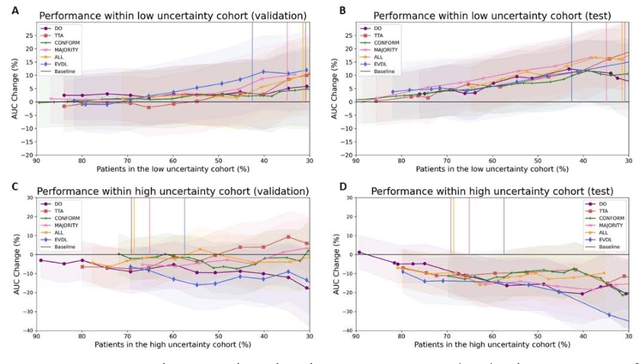
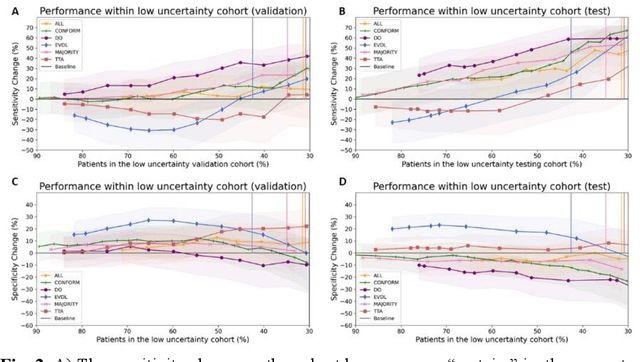
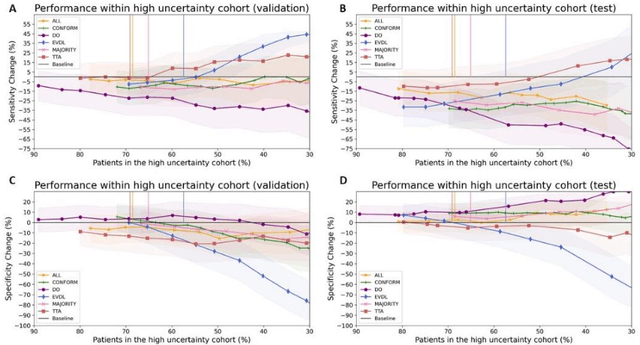
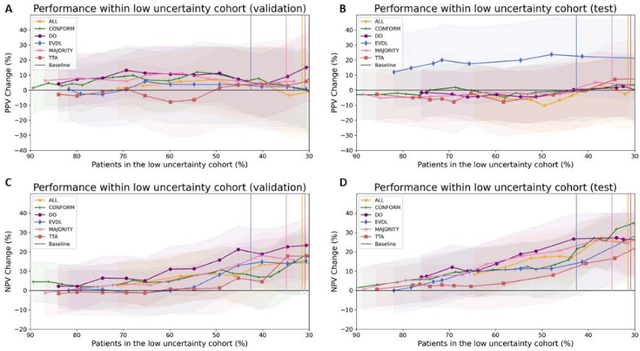
Prediction uncertainty estimation has clinical significance as it can potentially quantify prediction reliability. Clinicians may trust 'blackbox' models more if robust reliability information is available, which may lead to more models being adopted into clinical practice. There are several deep learning-inspired uncertainty estimation techniques, but few are implemented on medical datasets -- fewer on single institutional datasets/models. We sought to compare dropout variational inference (DO), test-time augmentation (TTA), conformal predictions, and single deterministic methods for estimating uncertainty using our model trained to predict feeding tube placement for 271 head and neck cancer patients treated with radiation. We compared the area under the curve (AUC), sensitivity, specificity, positive predictive value (PPV), and negative predictive value (NPV) trends for each method at various cutoffs that sought to stratify patients into 'certain' and 'uncertain' cohorts. These cutoffs were obtained by calculating the percentile "uncertainty" within the validation cohort and applied to the testing cohort. Broadly, the AUC, sensitivity, and NPV increased as the predictions were more 'certain' -- i.e., lower uncertainty estimates. However, when a majority vote (implementing 2/3 criteria: DO, TTA, conformal predictions) or a stricter approach (3/3 criteria) were used, AUC, sensitivity, and NPV improved without a notable loss in specificity or PPV. Especially for smaller, single institutional datasets, it may be important to evaluate multiple estimations techniques before incorporating a model into clinical practice.
Adaptive Local-Component-aware Graph Convolutional Network for One-shot Skeleton-based Action Recognition
Sep 21, 2022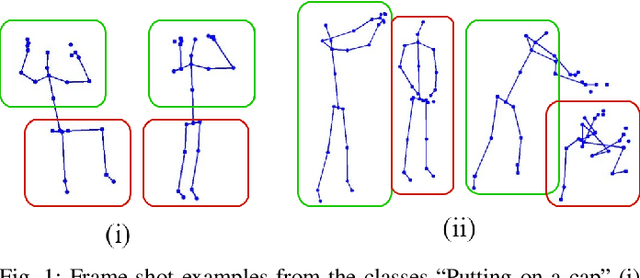
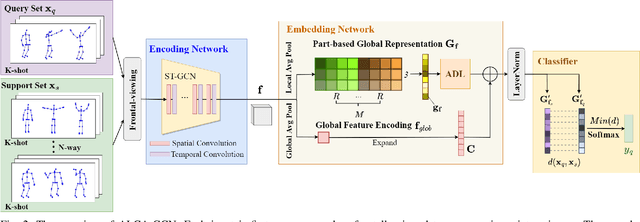
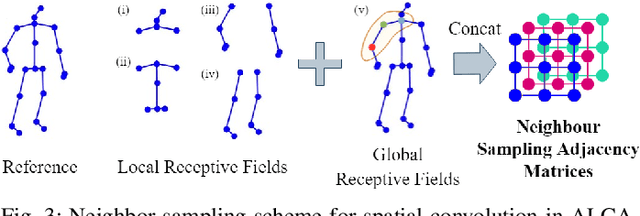
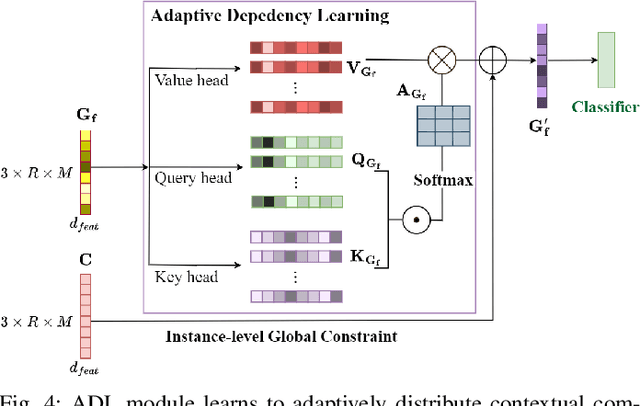
Skeleton-based action recognition receives increasing attention because the skeleton representations reduce the amount of training data by eliminating visual information irrelevant to actions. To further improve the sample efficiency, meta-learning-based one-shot learning solutions were developed for skeleton-based action recognition. These methods find the nearest neighbor according to the similarity between instance-level global average embedding. However, such measurement holds unstable representativity due to inadequate generalized learning on local invariant and noisy features, while intuitively, more fine-grained recognition usually relies on determining key local body movements. To address this limitation, we present the Adaptive Local-Component-aware Graph Convolutional Network, which replaces the comparison metric with a focused sum of similarity measurements on aligned local embedding of action-critical spatial/temporal segments. Comprehensive one-shot experiments on the public benchmark of NTU-RGB+D 120 indicate that our method provides a stronger representation than the global embedding and helps our model reach state-of-the-art.
Information Leakage Games: Exploring Information as a Utility Function
Dec 22, 2020



A common goal in the areas of secure information flow and privacy is to build effective defenses against unwanted leakage of information. To this end, one must be able to reason about potential attacks and their interplay with possible defenses. In this paper we propose a game-theoretic framework to formalize strategies of attacker and defender in the context of information leakage, and provide a basis for developing optimal defense methods. A crucial novelty of our games is that their utility is given by information leakage, which in some cases may behave in a non-linear way. This causes a significant deviation from classic game theory, in which utility functions are linear with respect to players' strategies. Hence, a key contribution of this paper is the establishment of the foundations of information leakage games. We consider two main categories of games, depending on the particular notion of information leakage being captured. The first category, which we call QIF-games, is tailored for the theory of quantitative information flow (QIF). The second one, which we call DP-games, corresponds to differential privacy (DP).
Synergistic Integration of Techniques of VC, Communication Technologies and Unities of Calculation Transportable for Generate a System Embedded That Monitors Pyroclastic Flows in Real Time
Aug 15, 2022At the end of an extensive investigation of the volcanic eruptions in the world, we determined patterns that coincide in this process, this data can be analyzed by artificial vision, obtaining the largest amount of information from images in an embedded system, using monitoring algorithms for compare continuous matrices, control camera positioning and link this information with mass communication technologies. The present work shows the development of a viable early warning technology solution that allows to analyze the behavior of volcanic flows automatically in a rash in real time, with a very high level of efficiency in the analysis of possible trajectories, direction and quantity of the lava flows as well as the massive mass media directed to the affected people.
Enhanced Meta Reinforcement Learning using Demonstrations in Sparse Reward Environments
Sep 26, 2022
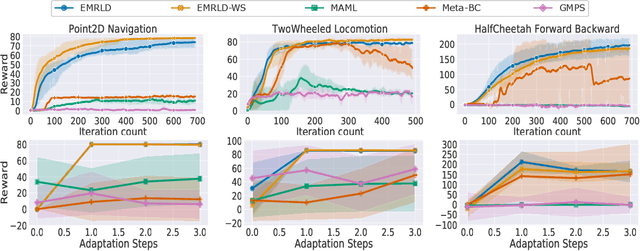
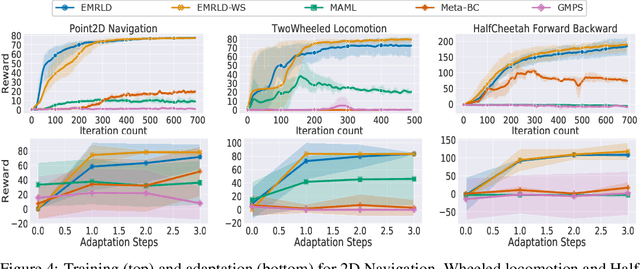
Meta reinforcement learning (Meta-RL) is an approach wherein the experience gained from solving a variety of tasks is distilled into a meta-policy. The meta-policy, when adapted over only a small (or just a single) number of steps, is able to perform near-optimally on a new, related task. However, a major challenge to adopting this approach to solve real-world problems is that they are often associated with sparse reward functions that only indicate whether a task is completed partially or fully. We consider the situation where some data, possibly generated by a sub-optimal agent, is available for each task. We then develop a class of algorithms entitled Enhanced Meta-RL using Demonstrations (EMRLD) that exploit this information even if sub-optimal to obtain guidance during training. We show how EMRLD jointly utilizes RL and supervised learning over the offline data to generate a meta-policy that demonstrates monotone performance improvements. We also develop a warm started variant called EMRLD-WS that is particularly efficient for sub-optimal demonstration data. Finally, we show that our EMRLD algorithms significantly outperform existing approaches in a variety of sparse reward environments, including that of a mobile robot.
Physics-based Digital Twins for Autonomous Thermal Food Processing: Efficient, Non-intrusive Reduced-order Modeling
Sep 07, 2022
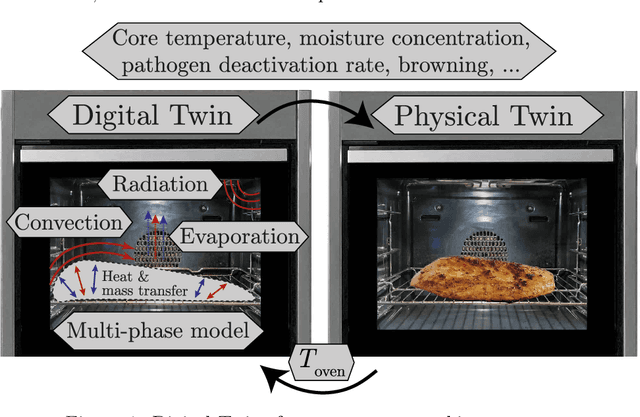

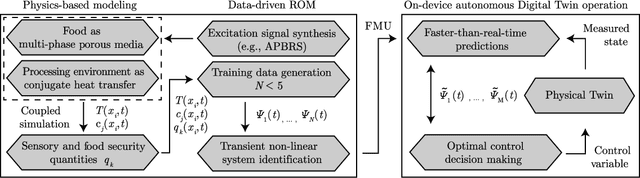
One possible way of making thermal processing controllable is to gather real-time information on the product's current state. Often, sensory equipment cannot capture all relevant information easily or at all. Digital Twins close this gap with virtual probes in real-time simulations, synchronized with the process. This paper proposes a physics-based, data-driven Digital Twin framework for autonomous food processing. We suggest a lean Digital Twin concept that is executable at the device level, entailing minimal computational load, data storage, and sensor data requirements. This study focuses on a parsimonious experimental design for training non-intrusive reduced-order models (ROMs) of a thermal process. A correlation ($R=-0.76$) between a high standard deviation of the surface temperatures in the training data and a low root mean square error in ROM testing enables efficient selection of training data. The mean test root mean square error of the best ROM is less than 1 Kelvin (0.2 % mean average percentage error) on representative test sets. Simulation speed-ups of Sp $\approx$ 1.8E4 allow on-device model predictive control. The proposed Digital Twin framework is designed to be applicable within the industry. Typically, non-intrusive reduced-order modeling is required as soon as the modeling of the process is performed in software, where root-level access to the solver is not provided, such as commercial simulation software. The data-driven training of the reduced-order model is achieved with only one data set, as correlations are utilized to predict the training success a priori.