 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDARE: A large-scale handwritten date recognition system
Oct 02, 2022


Handwritten text recognition for historical documents is an important task but it remains difficult due to a lack of sufficient training data in combination with a large variability of writing styles and degradation of historical documents. While recurrent neural network architectures are commonly used for handwritten text recognition, they are often computationally expensive to train and the benefit of recurrence drastically differs by task. For these reasons, it is important to consider non-recurrent architectures. In the context of handwritten date recognition, we propose an architecture based on the EfficientNetV2 class of models that is fast to train, robust to parameter choices, and accurately transcribes handwritten dates from a number of sources. For training, we introduce a database containing almost 10 million tokens, originating from more than 2.2 million handwritten dates which are segmented from different historical documents. As dates are some of the most common information on historical documents, and with historical archives containing millions of such documents, the efficient and automatic transcription of dates has the potential to lead to significant cost-savings over manual transcription. We show that training on handwritten text with high variability in writing styles result in robust models for general handwritten text recognition and that transfer learning from the DARE system increases transcription accuracy substantially, allowing one to obtain high accuracy even when using a relatively small training sample.
Applications of Machine Learning in Document Digitisation
Feb 05, 2021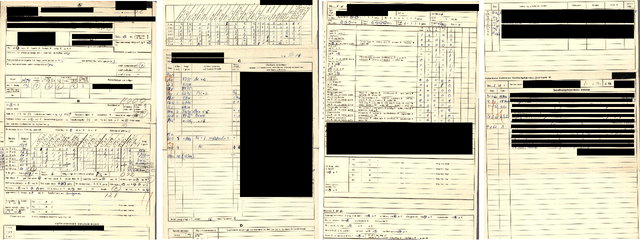
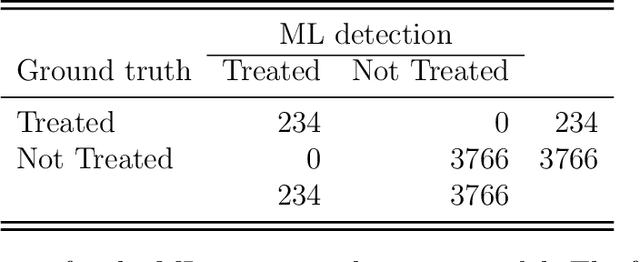
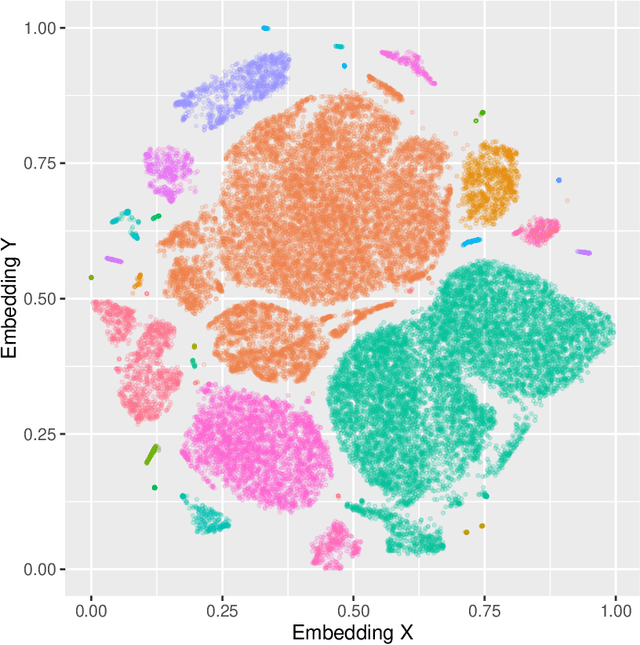
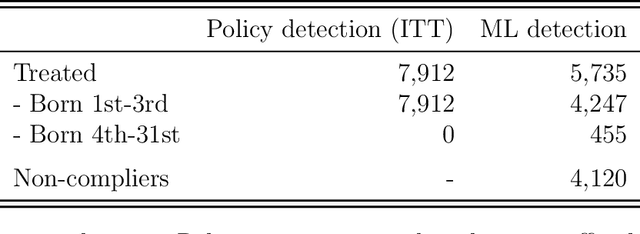
Data acquisition forms the primary step in all empirical research. The availability of data directly impacts the quality and extent of conclusions and insights. In particular, larger and more detailed datasets provide convincing answers even to complex research questions. The main problem is that 'large and detailed' usually implies 'costly and difficult', especially when the data medium is paper and books. Human operators and manual transcription have been the traditional approach for collecting historical data. We instead advocate the use of modern machine learning techniques to automate the digitisation process. We give an overview of the potential for applying machine digitisation for data collection through two illustrative applications. The first demonstrates that unsupervised layout classification applied to raw scans of nurse journals can be used to construct a treatment indicator. Moreover, it allows an assessment of assignment compliance. The second application uses attention-based neural networks for handwritten text recognition in order to transcribe age and birth and death dates from a large collection of Danish death certificates. We describe each step in the digitisation pipeline and provide implementation insights.