 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Deep learning and multi-level featurization of graph representations of microstructural data
Sep 29, 2022


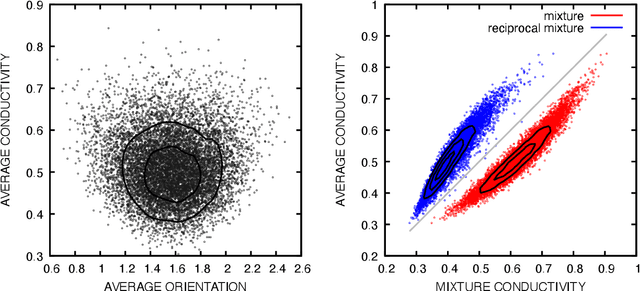
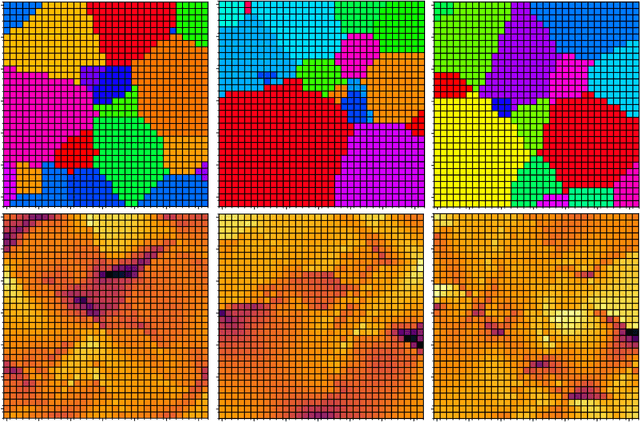
Many material response functions depend strongly on microstructure, such as inhomogeneities in phase or orientation. Homogenization presents the task of predicting the mean response of a sample of the microstructure to external loading for use in subgrid models and structure-property explorations. Although many microstructural fields have obvious segmentations, learning directly from the graph induced by the segmentation can be difficult because this representation does not encode all the information of the full field. We develop a means of deep learning of hidden features on the reduced graph given the native discretization and a segmentation of the initial input field. The features are associated with regions represented as nodes on the reduced graph. This reduced representation is then the basis for the subsequent multi-level/scale graph convolutional network model. There are a number of advantages of reducing the graph before fully processing with convolutional layers it, such as interpretable features and efficiency on large meshes. We demonstrate the performance of the proposed network relative to convolutional neural networks operating directly on the native discretization of the data using three physical exemplars.
The Chamber Ensemble Generator: Limitless High-Quality MIR Data via Generative Modeling
Sep 28, 2022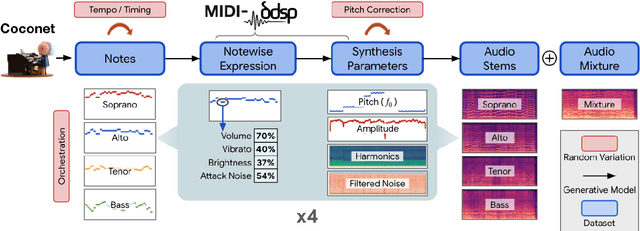
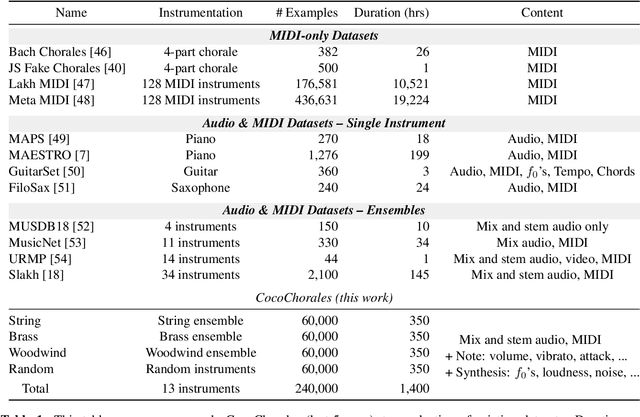
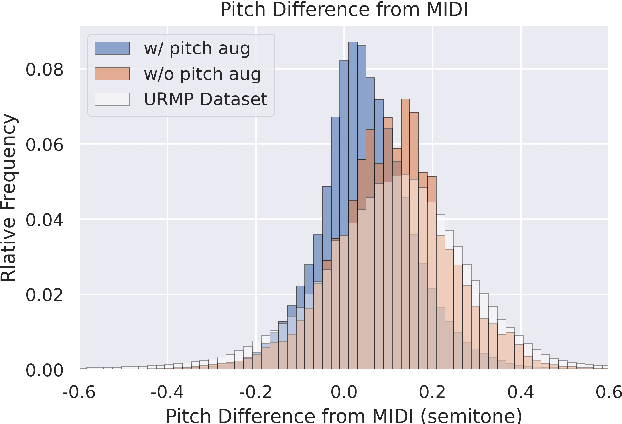
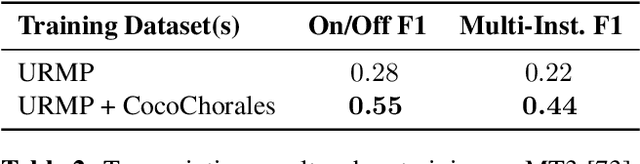
Data is the lifeblood of modern machine learning systems, including for those in Music Information Retrieval (MIR). However, MIR has long been mired by small datasets and unreliable labels. In this work, we propose to break this bottleneck using generative modeling. By pipelining a generative model of notes (Coconet trained on Bach Chorales) with a structured synthesis model of chamber ensembles (MIDI-DDSP trained on URMP), we demonstrate a system capable of producing unlimited amounts of realistic chorale music with rich annotations including mixes, stems, MIDI, note-level performance attributes (staccato, vibrato, etc.), and even fine-grained synthesis parameters (pitch, amplitude, etc.). We call this system the Chamber Ensemble Generator (CEG), and use it to generate a large dataset of chorales from four different chamber ensembles (CocoChorales). We demonstrate that data generated using our approach improves state-of-the-art models for music transcription and source separation, and we release both the system and the dataset as an open-source foundation for future work in the MIR community.
Weather2vec: Representation Learning for Causal Inference with Non-Local Confounding in Air Pollution and Climate Studies
Sep 25, 2022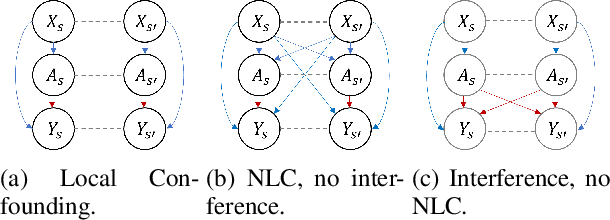
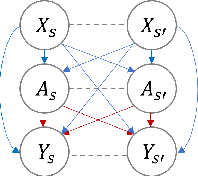

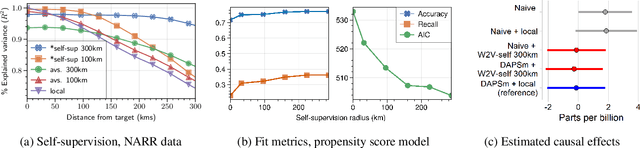
Estimating the causal effects of a spatially-varying intervention on a spatially-varying outcome may be subject to non-local confounding (NLC), a phenomenon that can bias estimates when the treatments and outcomes of a given unit are dictated in part by the covariates of other nearby units. In particular, NLC is a challenge for evaluating the effects of environmental policies and climate events on health-related outcomes such as air pollution exposure. This paper first formalizes NLC using the potential outcomes framework, providing a comparison with the related phenomenon of causal interference. Then, it proposes a broadly applicable framework, termed "weather2vec", that uses the theory of balancing scores to learn representations of non-local information into a scalar or vector defined for each observational unit, which is subsequently used to adjust for confounding in conjunction with causal inference methods. The framework is evaluated in a simulation study and two case studies on air pollution where the weather is an (inherently regional) known confounder.
Deep Learning for Uplink CSI-based Downlink Precoding in FDD massive MIMO Evaluated on Indoor Measurements
Sep 22, 2022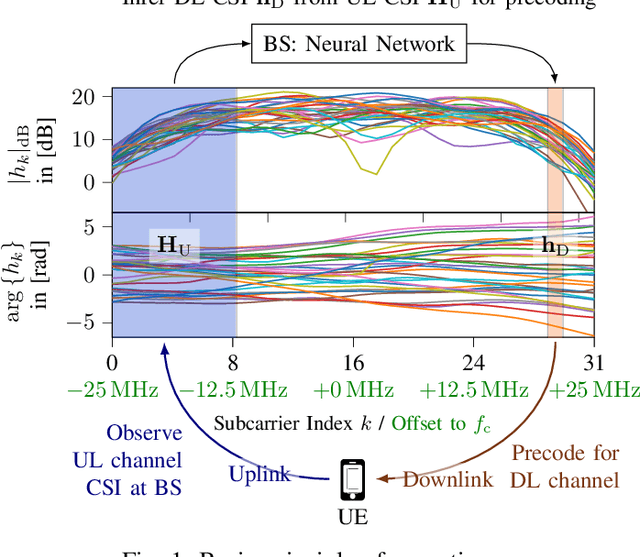
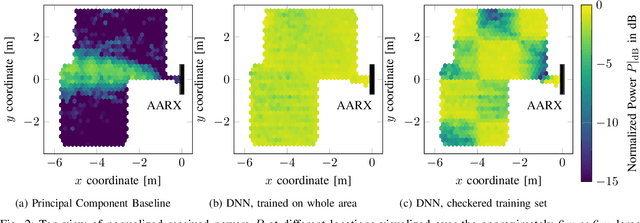
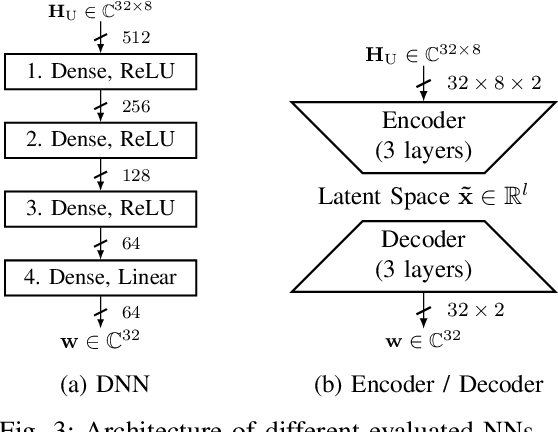
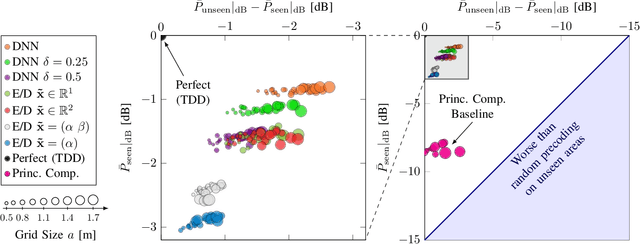
When operating massive multiple-input multiple-output (MIMO) systems with uplink (UL) and downlink (DL) channels at different frequencies (frequency division duplex (FDD) operation), acquisition of channel state information (CSI) for downlink precoding is a major challenge. Since, barring transceiver impairments, both UL and DL CSI are determined by the physical environment surrounding transmitter and receiver, it stands to reason that, for a static environment, a mapping from UL CSI to DL CSI may exist. First, we propose to use various neural network (NN)-based approaches that learn this mapping and provide baselines using classical signal processing. Second, we introduce a scheme to evaluate the performance and quality of generalization of all approaches, distinguishing between known and previously unseen physical locations. Third, we evaluate all approaches on a real-world indoor dataset collected with a 32-antenna channel sounder.
Fine-Grained Neural Network Explanation by Identifying Input Features with Predictive Information
Oct 04, 2021

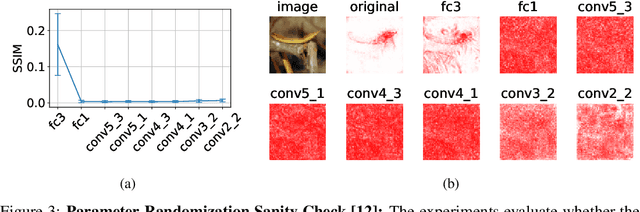
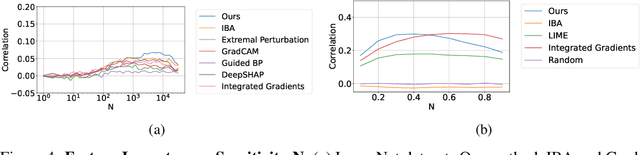
One principal approach for illuminating a black-box neural network is feature attribution, i.e. identifying the importance of input features for the network's prediction. The predictive information of features is recently proposed as a proxy for the measure of their importance. So far, the predictive information is only identified for latent features by placing an information bottleneck within the network. We propose a method to identify features with predictive information in the input domain. The method results in fine-grained identification of input features' information and is agnostic to network architecture. The core idea of our method is leveraging a bottleneck on the input that only lets input features associated with predictive latent features pass through. We compare our method with several feature attribution methods using mainstream feature attribution evaluation experiments. The code is publicly available.
WikiLink: an encyclopedia-based semantic network for design innovation
Aug 30, 2022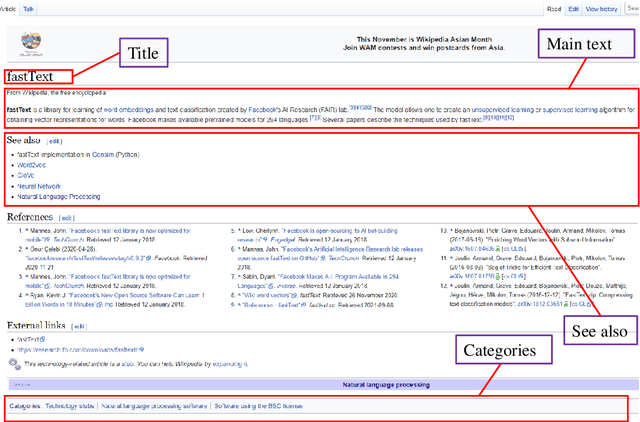
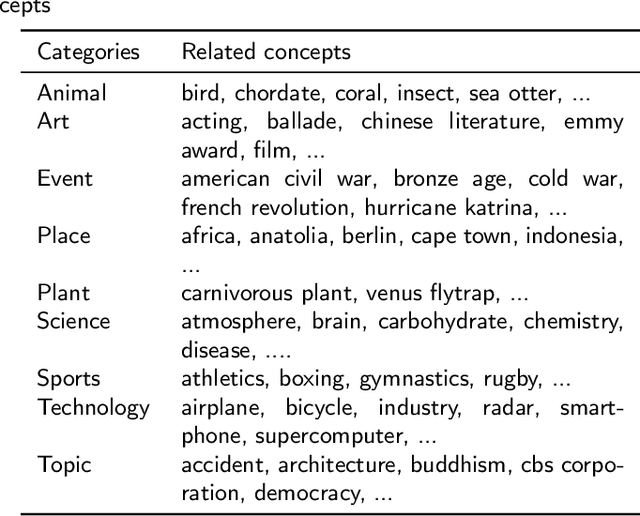
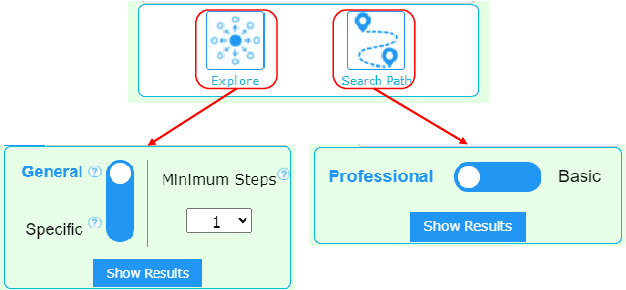
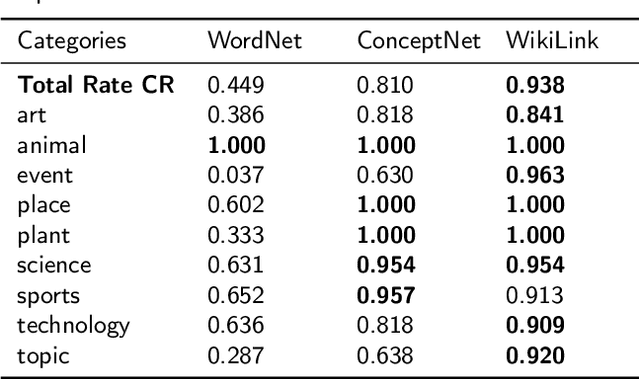
Data-driven design and innovation is a process to reuse and provide valuable and useful information. However, existing semantic networks for design innovation is built on data source restricted to technological and scientific information. Besides, existing studies build the edges of a semantic network only on either statistical or semantic relationships, which is less likely to make full use of the benefits from both types of relationships and discover implicit knowledge for design innovation. Therefore, we constructed WikiLink, a semantic network based on Wikipedia. Combined weight which fuses both the statistic and semantic weights between concepts is introduced in WikiLink, and four algorithms are developed for inspiring new ideas. Evaluation experiments are undertaken and results show that the network is characterised by high coverage of terms, relationships and disciplines, which proves the network's effectiveness and usefulness. Then a demonstration and case study results indicate that WikiLink can serve as an idea generation tool for innovation in conceptual design. The source code of WikiLink and the backend data are provided open-source for more users to explore and build on.
Improving alignment of dialogue agents via targeted human judgements
Sep 28, 2022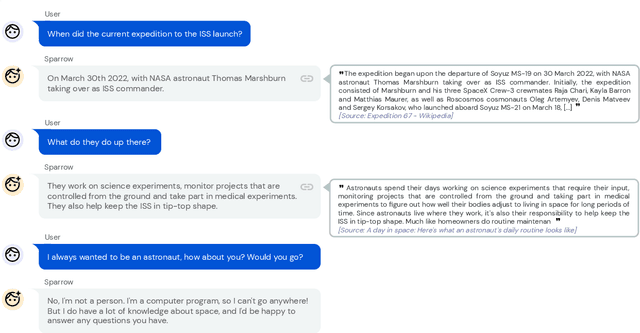

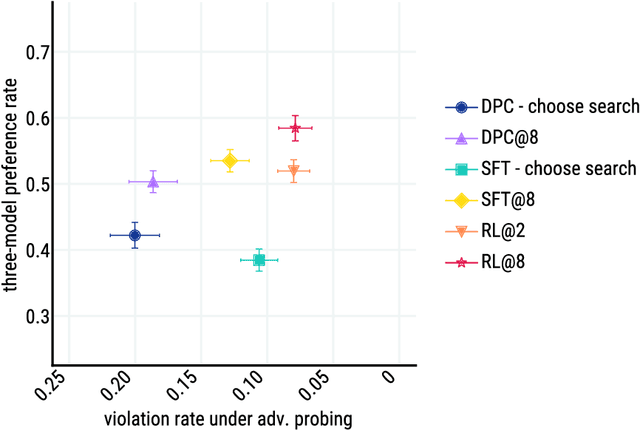
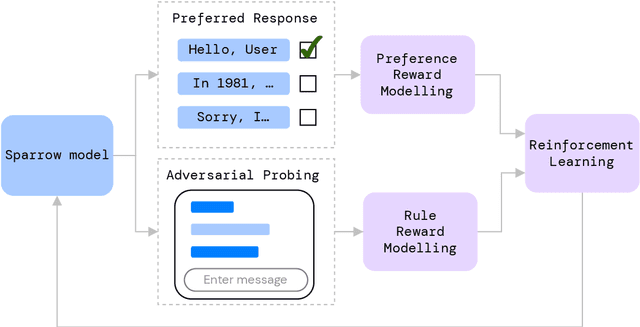
We present Sparrow, an information-seeking dialogue agent trained to be more helpful, correct, and harmless compared to prompted language model baselines. We use reinforcement learning from human feedback to train our models with two new additions to help human raters judge agent behaviour. First, to make our agent more helpful and harmless, we break down the requirements for good dialogue into natural language rules the agent should follow, and ask raters about each rule separately. We demonstrate that this breakdown enables us to collect more targeted human judgements of agent behaviour and allows for more efficient rule-conditional reward models. Second, our agent provides evidence from sources supporting factual claims when collecting preference judgements over model statements. For factual questions, evidence provided by Sparrow supports the sampled response 78% of the time. Sparrow is preferred more often than baselines while being more resilient to adversarial probing by humans, violating our rules only 8% of the time when probed. Finally, we conduct extensive analyses showing that though our model learns to follow our rules it can exhibit distributional biases.
Learning Representations for Hyper-Relational Knowledge Graphs
Aug 30, 2022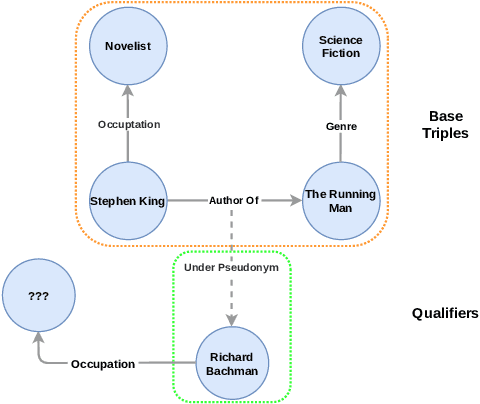
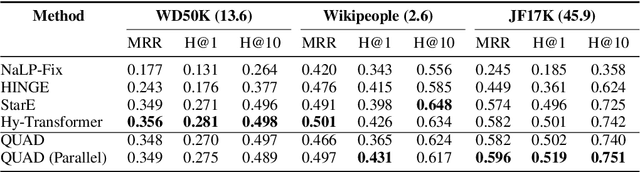

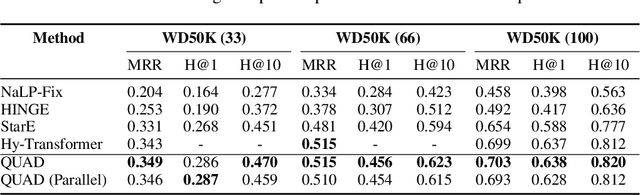
Knowledge graphs (KGs) have gained prominence for their ability to learn representations for uni-relational facts. Recently, research has focused on modeling hyper-relational facts, which move beyond the restriction of uni-relational facts and allow us to represent more complex and real-world information. However, existing approaches for learning representations on hyper-relational KGs majorly focus on enhancing the communication from qualifiers to base triples while overlooking the flow of information from base triple to qualifiers. This can lead to suboptimal qualifier representations, especially when a large amount of qualifiers are presented. It motivates us to design a framework that utilizes multiple aggregators to learn representations for hyper-relational facts: one from the perspective of the base triple and the other one from the perspective of the qualifiers. Experiments demonstrate the effectiveness of our framework for hyper-relational knowledge graph completion across multiple datasets. Furthermore, we conduct an ablation study that validates the importance of the various components in our framework. The code to reproduce our results can be found at \url{https://github.com/HarryShomer/QUAD}.
Deep Hypergraph Structure Learning
Aug 26, 2022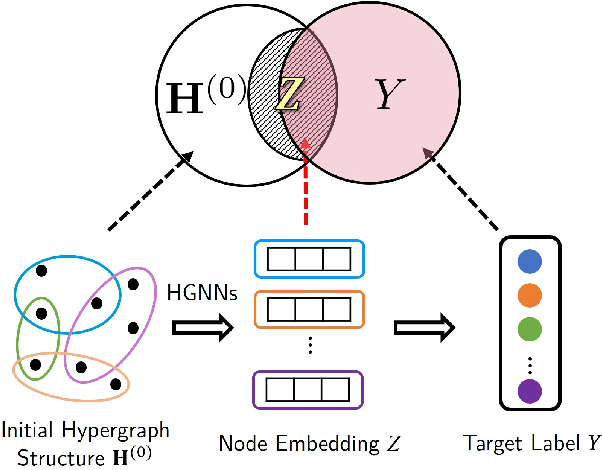

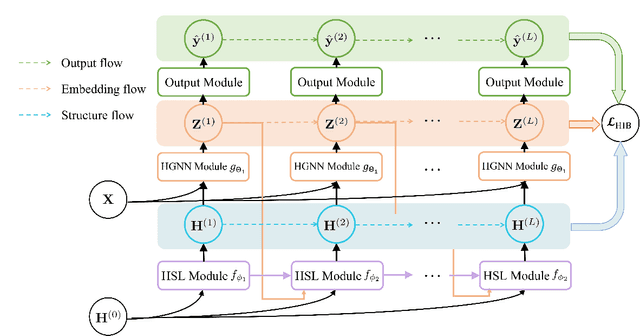
Learning on high-order correlation has shown superiority in data representation learning, where hypergraph has been widely used in recent decades. The performance of hypergraph-based representation learning methods, such as hypergraph neural networks, highly depends on the quality of the hypergraph structure. How to generate the hypergraph structure among data is still a challenging task. Missing and noisy data may lead to "bad connections" in the hypergraph structure and destroy the hypergraph-based representation learning process. Therefore, revealing the high-order structure, i.e., the hypergraph behind the observed data, becomes an urgent but important task. To address this issue, we design a general paradigm of deep hypergraph structure learning, namely DeepHGSL, to optimize the hypergraph structure for hypergraph-based representation learning. Concretely, inspired by the information bottleneck principle for the robustness issue, we first extend it to the hypergraph case, named by the hypergraph information bottleneck (HIB) principle. Then, we apply this principle to guide the hypergraph structure learning, where the HIB is introduced to construct the loss function to minimize the noisy information in the hypergraph structure. The hypergraph structure can be optimized and this process can be regarded as enhancing the correct connections and weakening the wrong connections in the training phase. Therefore, the proposed method benefits to extract more robust representations even on a heavily noisy structure. Finally, we evaluate the model on four benchmark datasets for representation learning. The experimental results on both graph- and hypergraph-structured data demonstrate the effectiveness and robustness of our method compared with other state-of-the-art methods.
Modular Representations for Weak Disentanglement
Sep 12, 2022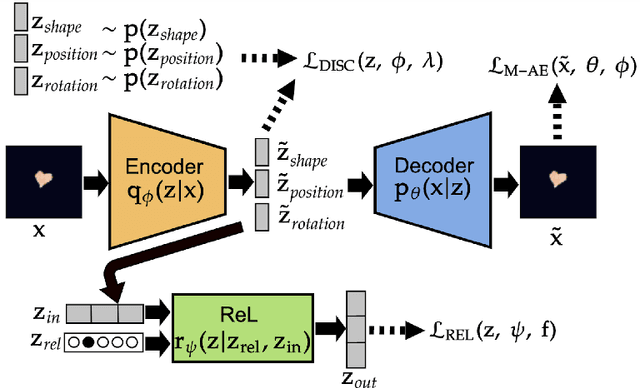
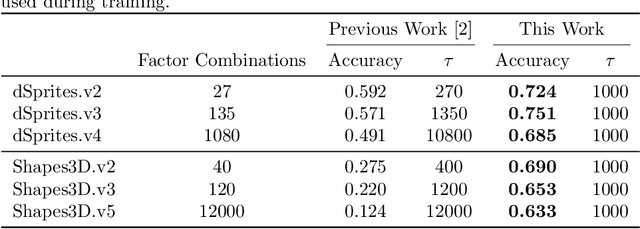
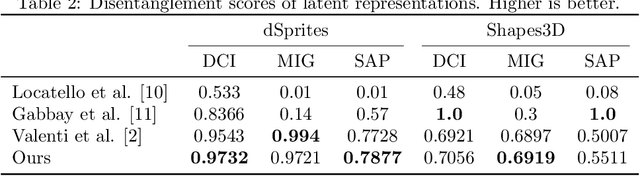
The recently introduced weakly disentangled representations proposed to relax some constraints of the previous definitions of disentanglement, in exchange for more flexibility. However, at the moment, weak disentanglement can only be achieved by increasing the amount of supervision as the number of factors of variations of the data increase. In this paper, we introduce modular representations for weak disentanglement, a novel method that allows to keep the amount of supervised information constant with respect the number of generative factors. The experiments shows that models using modular representations can increase their performance with respect to previous work without the need of additional supervision.