 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Best Practices in the Creation and Use of Emotion Lexicons
Oct 13, 2022
Words play a central role in how we express ourselves. Lexicons of word-emotion associations are widely used in research and real-world applications for sentiment analysis, tracking emotions associated with products and policies, studying health disorders, tracking emotional arcs of stories, and so on. However, inappropriate and incorrect use of these lexicons can lead to not just sub-optimal results, but also inferences that are directly harmful to people. This paper brings together ideas from Affective Computing and AI Ethics to present, some of the practical and ethical considerations involved in the creation and use of emotion lexicons -- best practices. The goal is to provide a comprehensive set of relevant considerations, so that readers (especially those new to work with emotions) can find relevant information in one place. We hope this work will facilitate more thoughtfulness when one is deciding on what emotions to work on, how to create an emotion lexicon, how to use an emotion lexicon, how to draw meaningful inferences, and how to judge success.
Amortized Inference for Heterogeneous Reconstruction in Cryo-EM
Oct 13, 2022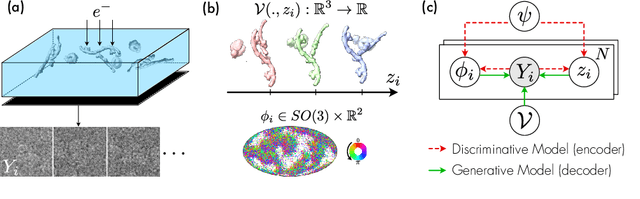
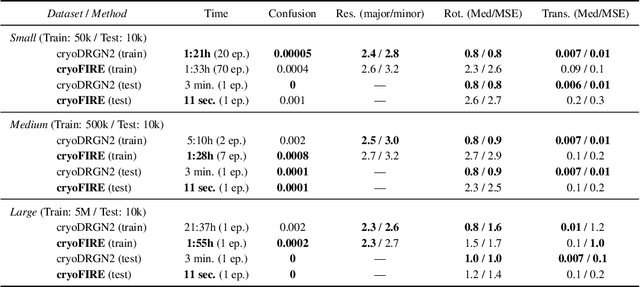
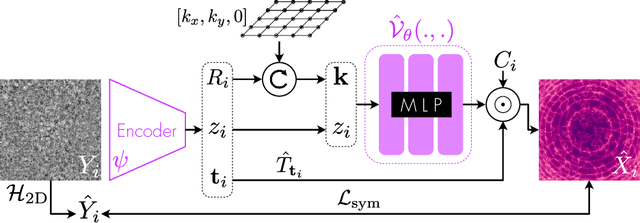
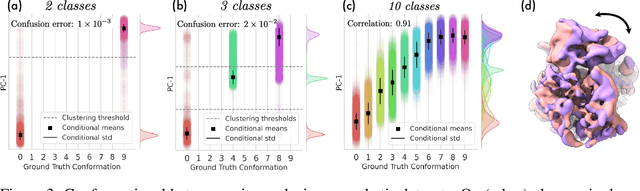
Cryo-electron microscopy (cryo-EM) is an imaging modality that provides unique insights into the dynamics of proteins and other building blocks of life. The algorithmic challenge of jointly estimating the poses, 3D structure, and conformational heterogeneity of a biomolecule from millions of noisy and randomly oriented 2D projections in a computationally efficient manner, however, remains unsolved. Our method, cryoFIRE, performs ab initio heterogeneous reconstruction with unknown poses in an amortized framework, thereby avoiding the computationally expensive step of pose search while enabling the analysis of conformational heterogeneity. Poses and conformation are jointly estimated by an encoder while a physics-based decoder aggregates the images into an implicit neural representation of the conformational space. We show that our method can provide one order of magnitude speedup on datasets containing millions of images without any loss of accuracy. We validate that the joint estimation of poses and conformations can be amortized over the size of the dataset. For the first time, we prove that an amortized method can extract interpretable dynamic information from experimental datasets.
Sapling Similarity outperforms other local similarity metrics in collaborative filtering
Oct 13, 2022
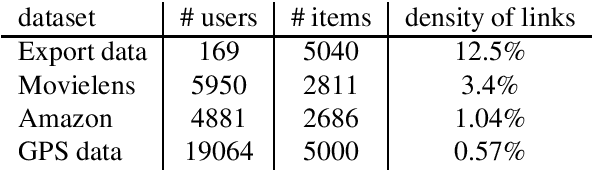
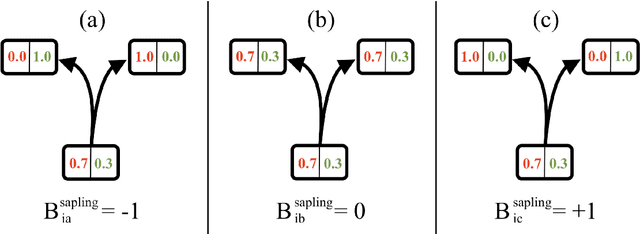
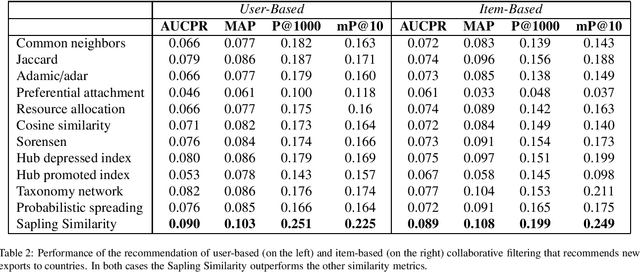
Many bipartite networks describe systems where a link represents a relation between a user and an item. Measuring the similarity between either users or items is the basis of memory-based collaborative filtering, a widely used method to build a recommender system with the purpose of proposing items to users. When the edges of the network are unweighted, traditional approaches allow only positive similarity values, so neglecting the possibility and the effect of two users (or two items) being very dissimilar. Here we propose a method to compute similarity that allows also negative values, the Sapling Similarity. The key idea is to look at how the information that a user is connected to an item influences our prior estimation of the probability that another user is connected to the same item: if it is reduced, then the similarity between the two users will be negative, otherwise it will be positive. Using different datasets, we show that the Sapling Similarity outperforms other similarity metrics when it is used to recommend new items to users.
Threshold Treewidth and Hypertree Width
Oct 13, 2022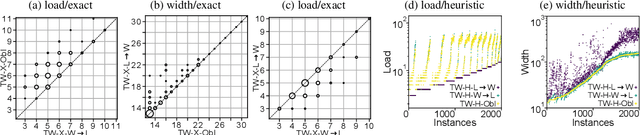
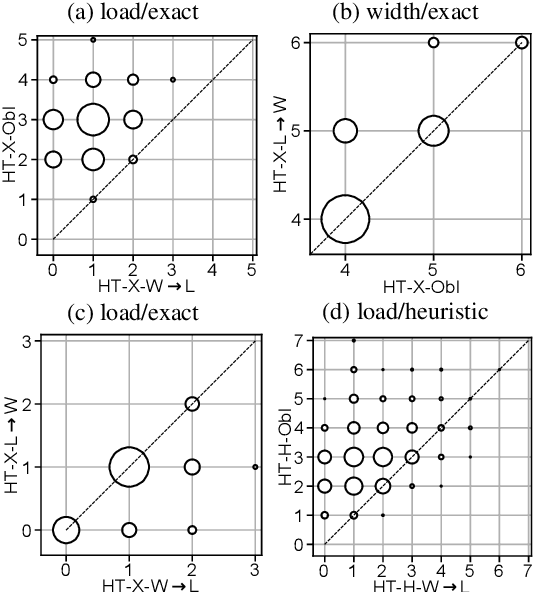
Treewidth and hypertree width have proven to be highly successful structural parameters in the context of the Constraint Satisfaction Problem (CSP). When either of these parameters is bounded by a constant, then CSP becomes solvable in polynomial time. However, here the order of the polynomial in the running time depends on the width, and this is known to be unavoidable; therefore, the problem is not fixed-parameter tractable parameterized by either of these width measures. Here we introduce an enhancement of tree and hypertree width through a novel notion of thresholds, allowing the associated decompositions to take into account information about the computational costs associated with solving the given CSP instance. Aside from introducing these notions, we obtain efficient theoretical as well as empirical algorithms for computing threshold treewidth and hypertree width and show that these parameters give rise to fixed-parameter algorithms for CSP as well as other, more general problems. We complement our theoretical results with experimental evaluations in terms of heuristics as well as exact methods based on SAT/SMT encodings.
* 24 pages, 4 figures. An extended abstract appeared at IJCAI 2020. A full version appeared in the Journal of Artificial Intelligence Research
Interpreting Neural Policies with Disentangled Tree Representations
Oct 13, 2022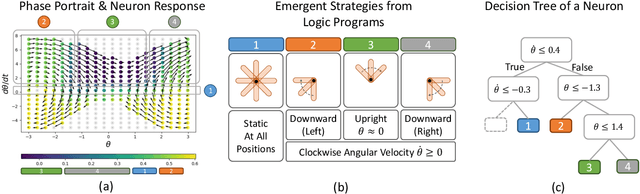
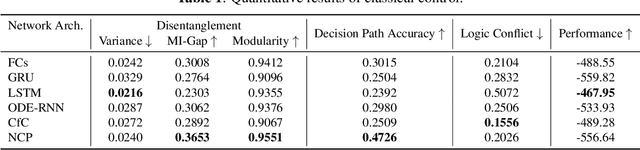
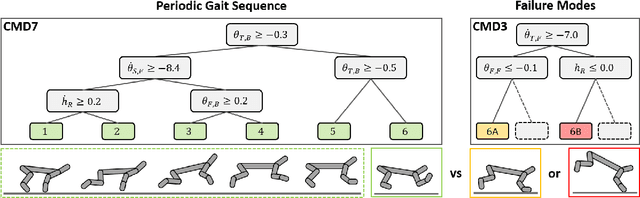
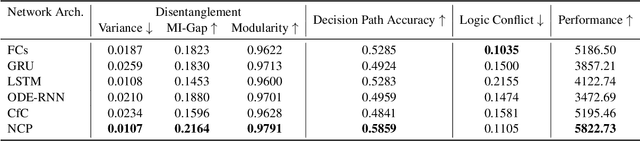
Compact neural networks used in policy learning and closed-loop end-to-end control learn representations from data that encapsulate agent dynamics and potentially the agent-environment's factors of variation. A formal and quantitative understanding and interpretation of these explanatory factors in neural representations is difficult to achieve due to the complex and intertwined correspondence of neural activities with emergent behaviors. In this paper, we design a new algorithm that programmatically extracts tree representations from compact neural policies, in the form of a set of logic programs grounded by the world state. To assess how well networks uncover the dynamics of the task and their factors of variation, we introduce interpretability metrics that measure the disentanglement of learned neural dynamics from a concentration of decisions, mutual information, and modularity perspectives. Moreover, our method allows us to quantify how accurate the extracted decision paths (explanations) are and computes cross-neuron logic conflict. We demonstrate the effectiveness of our approach with several types of compact network architectures on a series of end-to-end learning to control tasks.
Virtual-Reality based Vestibular Ocular Motor Screening for Concussion Detection using Machine-Learning
Oct 13, 2022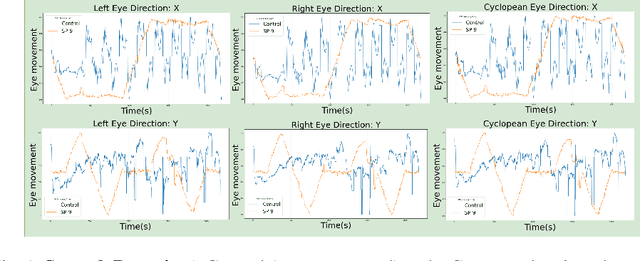

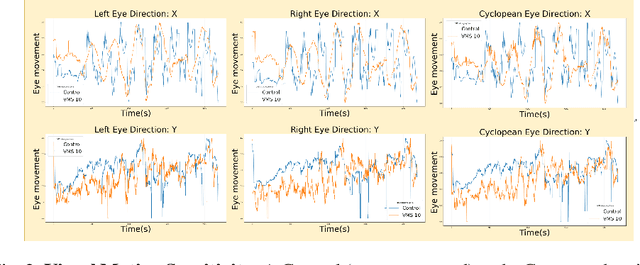
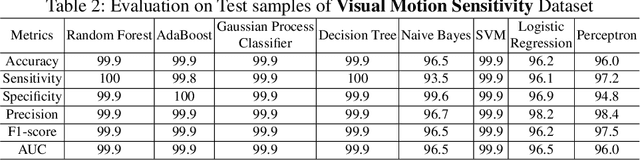
Sport-related concussion (SRC) depends on sensory information from visual, vestibular, and somatosensory systems. At the same time, the current clinical administration of Vestibular/Ocular Motor Screening (VOMS) is subjective and deviates among administrators. Therefore, for the assessment and management of concussion detection, standardization is required to lower the risk of injury and increase the validation among clinicians. With the advancement of technology, virtual reality (VR) can be utilized to advance the standardization of the VOMS, increasing the accuracy of testing administration and decreasing overall false positive rates. In this paper, we experimented with multiple machine learning methods to detect SRC on VR-generated data using VOMS. In our observation, the data generated from VR for smooth pursuit (SP) and the Visual Motion Sensitivity (VMS) tests are highly reliable for concussion detection. Furthermore, we train and evaluate these models, both qualitatively and quantitatively. Our findings show these models can reach high true-positive-rates of around 99.9 percent of symptom provocation on the VR stimuli-based VOMS vs. current clinical manual VOMS.
Sample Efficient Dynamics Learning for Symmetrical Legged Robots:Leveraging Physics Invariance and Geometric Symmetries
Oct 13, 2022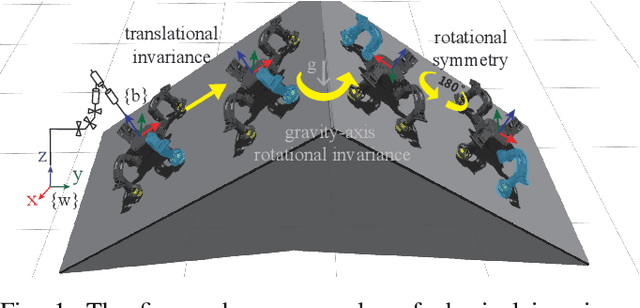
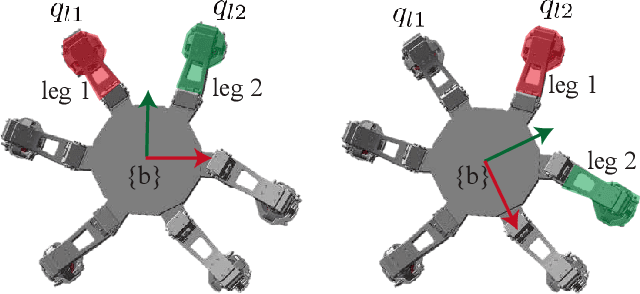
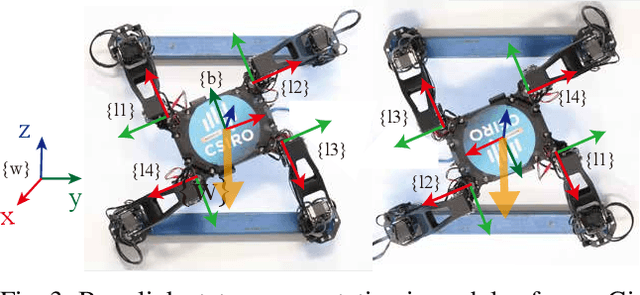
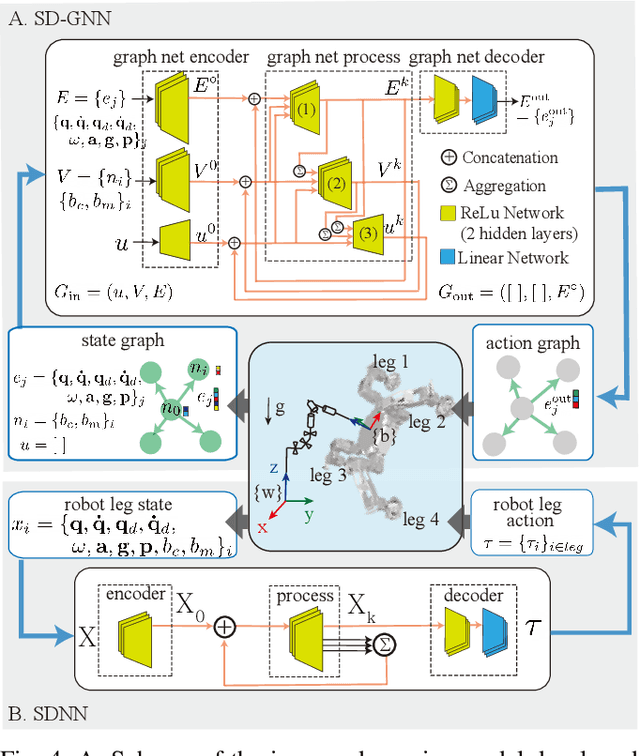
Model generalization of the underlying dynamics is critical for achieving data efficiency when learning for robot control. This paper proposes a novel approach for learning dynamics leveraging the symmetry in the underlying robotic system, which allows for robust extrapolation from fewer samples. Existing frameworks that represent all data in vector space fail to consider the structured information of the robot, such as leg symmetry, rotational symmetry, and physics invariance. As a result, these schemes require vast amounts of training data to learn the system's redundant elements because they are learned independently. Instead, we propose considering the geometric prior by representing the system in symmetrical object groups and designing neural network architecture to assess invariance and equivariance between the objects. Finally, we demonstrate the effectiveness of our approach by comparing the generalization to unseen data of the proposed model and the existing models. We also implement a controller of a climbing robot based on learned inverse dynamics models. The results show that our method generates accurate control inputs that help the robot reach the desired state while requiring less training data than existing methods.
3DEG: Data-Driven Descriptor Extraction for Global re-localization in subterranean environments
Oct 13, 2022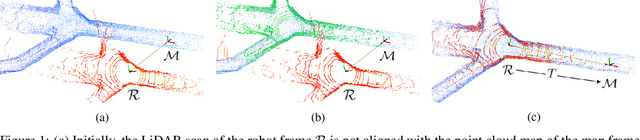
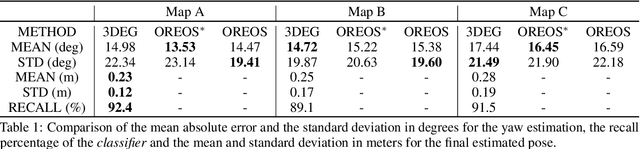
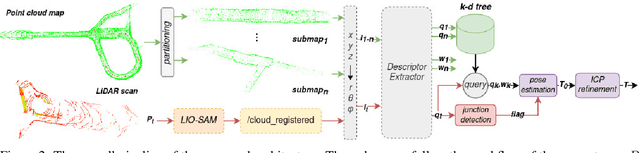
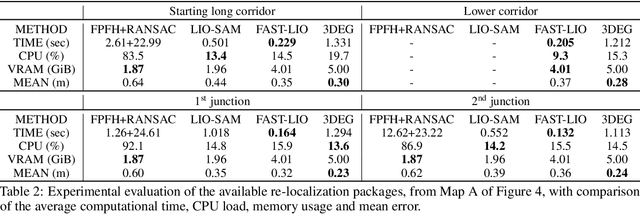
Current global re-localization algorithms are built on top of localization and mapping methods and heavily rely on scan matching and direct point cloud feature extraction and therefore are vulnerable in featureless demanding environments like caves and tunnels. In this article, we propose a novel global re-localization framework that: a) does not require an initial guess, like most methods do, while b) it has the capability to offer the top-k candidates to choose from and last but not least provides an event-based re-localization trigger module for enabling, and c) supporting completely autonomous robotic missions. With the focus on subterranean environments with low features, we opt to use descriptors based on range images from 3D LiDAR scans in order to maintain the depth information of the environment. In our novel approach, we make use of a state-of-the-art data-driven descriptor extraction framework for place recognition and orientation regression and enhance it with the addition of a junction detection module that also utilizes the descriptors for classification purposes.
RaP: Redundancy-aware Video-language Pre-training for Text-Video Retrieval
Oct 13, 2022
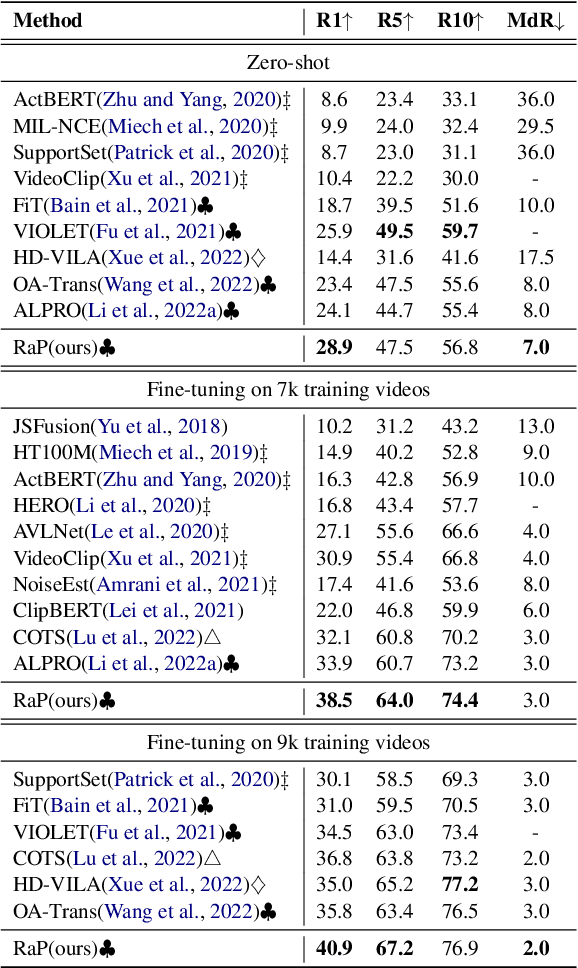
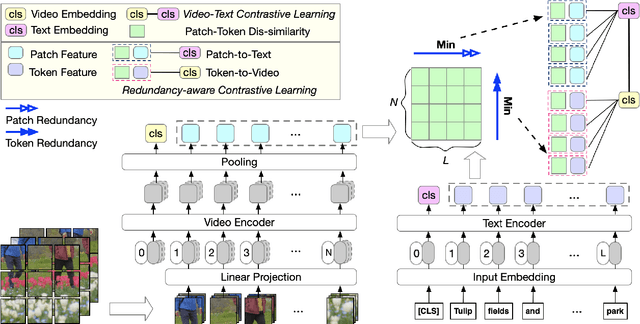
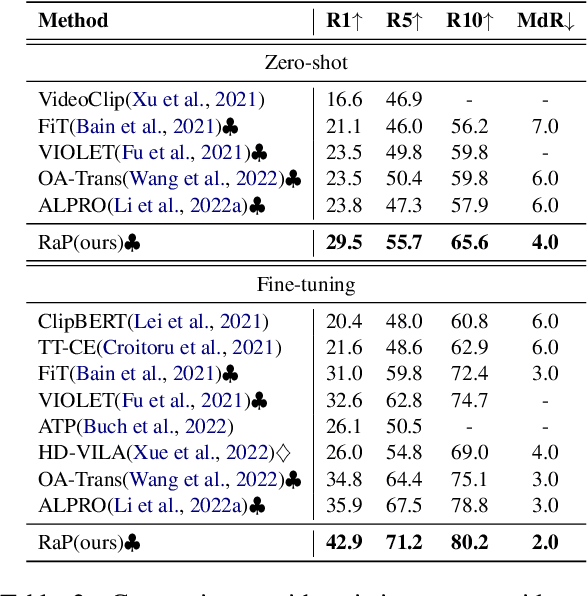
Video language pre-training methods have mainly adopted sparse sampling techniques to alleviate the temporal redundancy of videos. Though effective, sparse sampling still suffers inter-modal redundancy: visual redundancy and textual redundancy. Compared with highly generalized text, sparsely sampled frames usually contain text-independent portions, called visual redundancy. Sparse sampling is also likely to miss important frames corresponding to some text portions, resulting in textual redundancy. Inter-modal redundancy leads to a mismatch of video and text information, hindering the model from better learning the shared semantics across modalities. To alleviate it, we propose Redundancy-aware Video-language Pre-training. We design a redundancy measurement of video patches and text tokens by calculating the cross-modal minimum dis-similarity. Then, we penalize the highredundant video patches and text tokens through a proposed redundancy-aware contrastive learning. We evaluate our method on four benchmark datasets, MSRVTT, MSVD, DiDeMo, and LSMDC, achieving a significant improvement over the previous stateof-the-art results. Our code are available at https://github.com/caskcsg/VLP/tree/main/RaP.
Geometric Active Learning for Segmentation of Large 3D Volumes
Oct 13, 2022
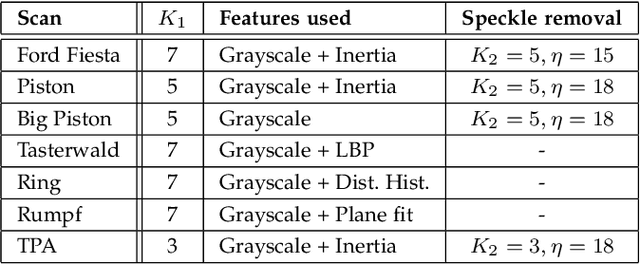
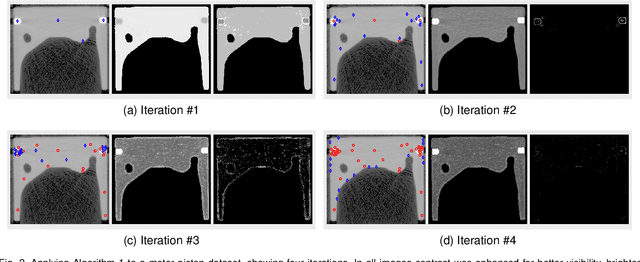
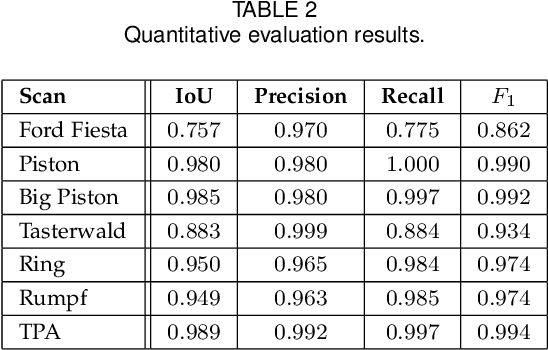
Segmentation, i.e., the partitioning of volumetric data into components, is a crucial task in many image processing applications ever since such data could be generated. Most existing applications nowadays, specifically CNNs, make use of voxelwise classification systems which need to be trained on a large number of annotated training volumes. However, in many practical applications such data sets are seldom available and the generation of annotations is time-consuming and cumbersome. In this paper, we introduce a novel voxelwise segmentation method based on active learning on geometric features. Our method uses interactively provided seed points to train a voxelwise classifier based entirely on local information. The combination of an ad hoc incorporation of domain knowledge and local processing results in a flexible yet efficient segmentation method that is applicable to three-dimensional volumes without size restrictions. We illustrate the potential and flexibility of our approach by applying it to selected computed tomography scans where we perform different segmentation tasks to scans from different domains and of different sizes.