 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SPIn-NeRF: Multiview Segmentation and Perceptual Inpainting with Neural Radiance Fields
Nov 22, 2022

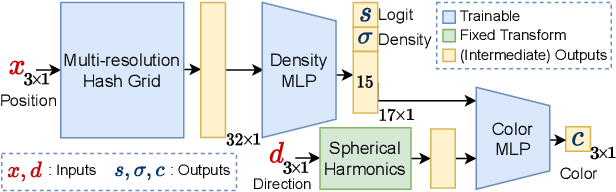
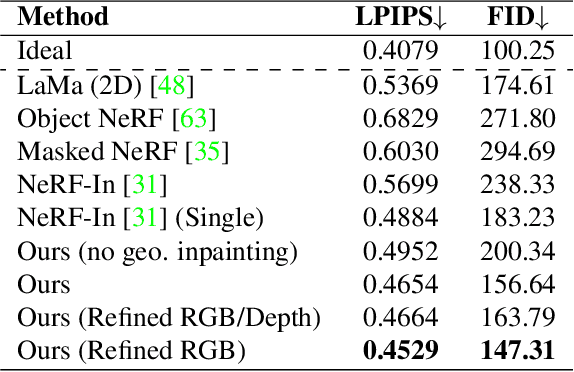
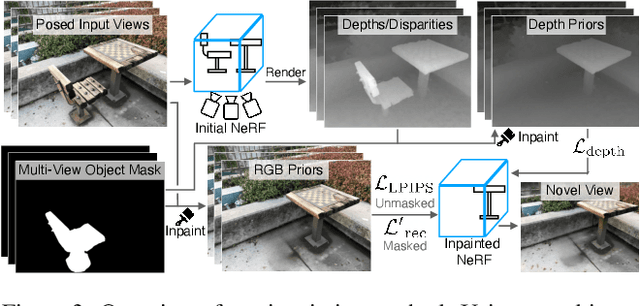
Neural Radiance Fields (NeRFs) have emerged as a popular approach for novel view synthesis. While NeRFs are quickly being adapted for a wider set of applications, intuitively editing NeRF scenes is still an open challenge. One important editing task is the removal of unwanted objects from a 3D scene, such that the replaced region is visually plausible and consistent with its context. We refer to this task as 3D inpainting. In 3D, solutions must be both consistent across multiple views and geometrically valid. In this paper, we propose a novel 3D inpainting method that addresses these challenges. Given a small set of posed images and sparse annotations in a single input image, our framework first rapidly obtains a 3D segmentation mask for a target object. Using the mask, a perceptual optimizationbased approach is then introduced that leverages learned 2D image inpainters, distilling their information into 3D space, while ensuring view consistency. We also address the lack of a diverse benchmark for evaluating 3D scene inpainting methods by introducing a dataset comprised of challenging real-world scenes. In particular, our dataset contains views of the same scene with and without a target object, enabling more principled benchmarking of the 3D inpainting task. We first demonstrate the superiority of our approach on multiview segmentation, comparing to NeRFbased methods and 2D segmentation approaches. We then evaluate on the task of 3D inpainting, establishing state-ofthe-art performance against other NeRF manipulation algorithms, as well as a strong 2D image inpainter baseline
Federated deep transfer learning for EEG decoding using multiple BCI tasks
Nov 22, 2022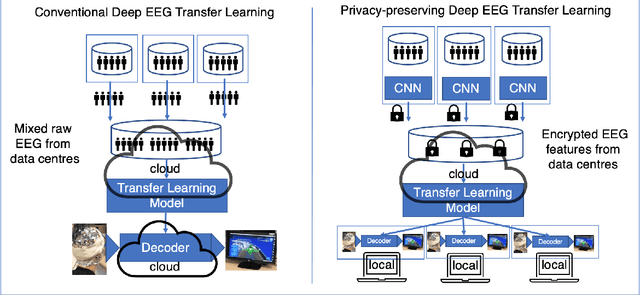
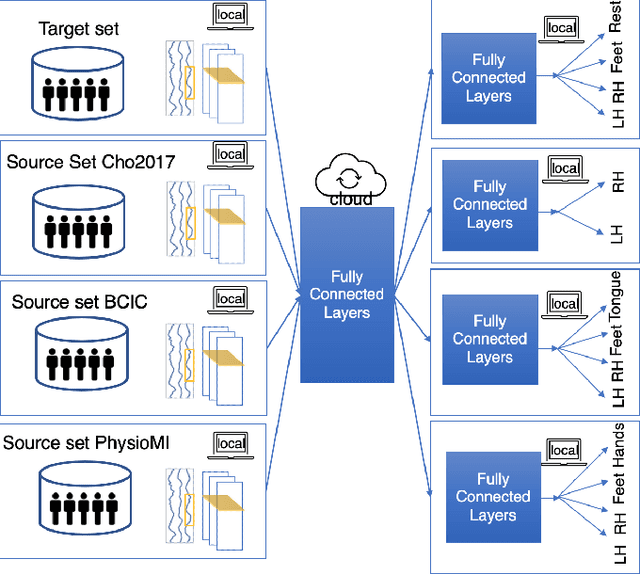
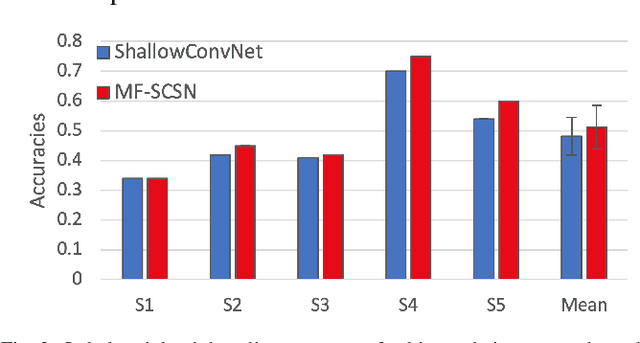
Deep learning has been successful in BCI decoding. However, it is very data-hungry and requires pooling data from multiple sources. EEG data from various sources decrease the decoding performance due to negative transfer. Recently, transfer learning for EEG decoding has been suggested as a remedy and become subject to recent BCI competitions (e.g. BEETL), but there are two complications in combining data from many subjects. First, privacy is not protected as highly personal brain data needs to be shared (and copied across increasingly tight information governance boundaries). Moreover, BCI data are collected from different sources and are often based on different BCI tasks, which has been thought to limit their reusability. Here, we demonstrate a federated deep transfer learning technique, the Multi-dataset Federated Separate-Common-Separate Network (MF-SCSN) based on our previous work of SCSN, which integrates privacy-preserving properties into deep transfer learning to utilise data sets with different tasks. This framework trains a BCI decoder using different source data sets obtained from different imagery tasks (e.g. some data sets with hands and feet, vs others with single hands and tongue, etc). Therefore, by introducing privacy-preserving transfer learning techniques, we unlock the reusability and scalability of existing BCI data sets. We evaluated our federated transfer learning method on the NeurIPS 2021 BEETL competition BCI task. The proposed architecture outperformed the baseline decoder by 3%. Moreover, compared with the baseline and other transfer learning algorithms, our method protects the privacy of the brain data from different data centres.
Multimodal Data Augmentation for Visual-Infrared Person ReID with Corrupted Data
Nov 22, 2022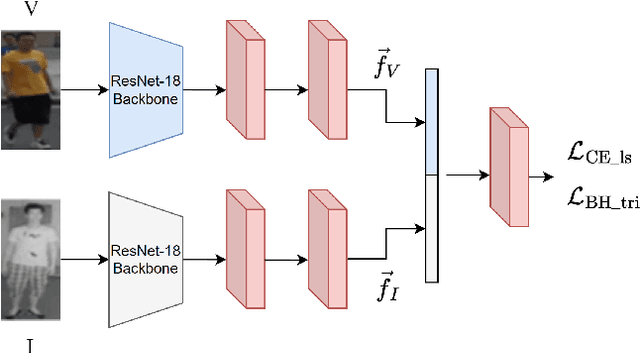
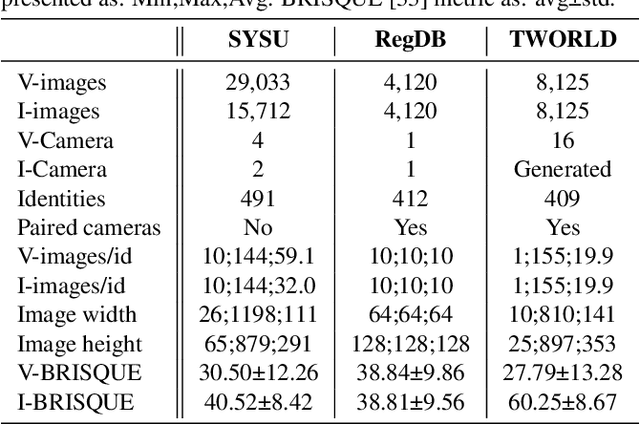

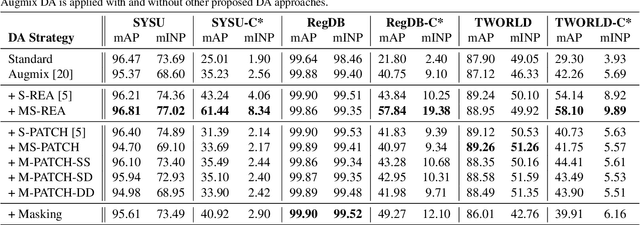
The re-identification (ReID) of individuals over a complex network of cameras is a challenging task, especially under real-world surveillance conditions. Several deep learning models have been proposed for visible-infrared (V-I) person ReID to recognize individuals from images captured using RGB and IR cameras. However, performance may decline considerably if RGB and IR images captured at test time are corrupted (e.g., noise, blur, and weather conditions). Although various data augmentation (DA) methods have been explored to improve the generalization capacity, these are not adapted for V-I person ReID. In this paper, a specialized DA strategy is proposed to address this multimodal setting. Given both the V and I modalities, this strategy allows to diminish the impact of corruption on the accuracy of deep person ReID models. Corruption may be modality-specific, and an additional modality often provides complementary information. Our multimodal DA strategy is designed specifically to encourage modality collaboration and reinforce generalization capability. For instance, punctual masking of modalities forces the model to select the informative modality. Local DA is also explored for advanced selection of features within and among modalities. The impact of training baseline fusion models for V-I person ReID using the proposed multimodal DA strategy is assessed on corrupted versions of the SYSU-MM01, RegDB, and ThermalWORLD datasets in terms of complexity and efficiency. Results indicate that using our strategy provides V-I ReID models the ability to exploit both shared and individual modality knowledge so they can outperform models trained with no or unimodal DA. GitHub code: https://github.com/art2611/ML-MDA.
Consistent Direct Time-of-Flight Video Depth Super-Resolution
Nov 16, 2022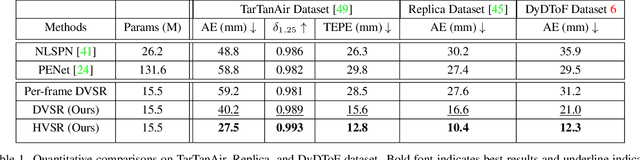
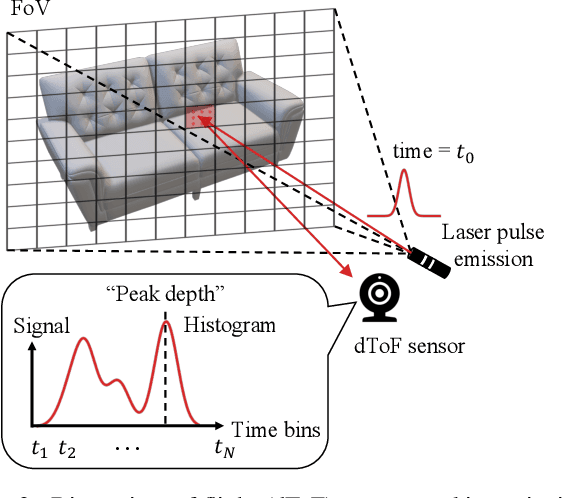
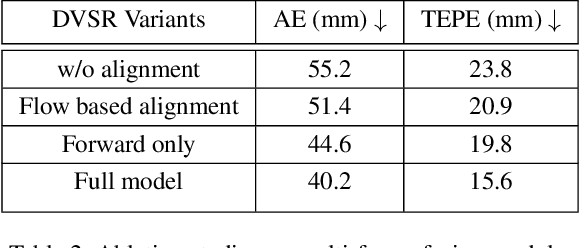
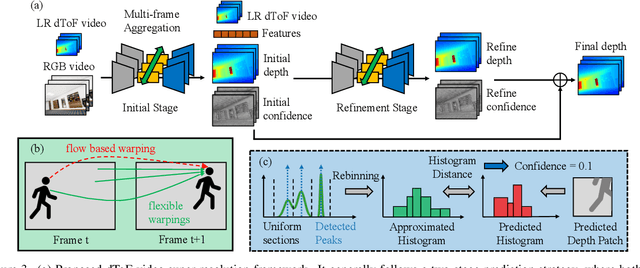
Direct time-of-flight (dToF) sensors are promising for next-generation on-device 3D sensing. However, to achieve the sufficient signal-to-noise-ratio (SNR) in a compact module, the dToF data has limited spatial resolution (e.g., ~20x30 for iPhone dToF), and it requires a super-resolution step before being passed to downstream tasks. In this paper, we solve this super-resolution problem by fusing the low-resolution dToF data with the corresponding high-resolution RGB guidance. Unlike the conventional RGB-guided depth enhancement approaches which perform the fusion in a per-frame manner, we propose the first multi-frame fusion scheme to mitigate the spatial ambiguity resulting from the low-resolution dToF imaging. In addition, dToF sensors provide unique depth histogram information for each local patch, and we incorporate this dToF-specific feature in our network design to further alleviate spatial ambiguity. To evaluate our models on complex dynamic indoor environments and to provide a large-scale dToF sensor dataset, we introduce DyDToF, the first synthetic RGB-dToF video dataset that features dynamic objects and a realistic dToF simulator following the physical imaging process. We believe the methods and dataset are beneficial to a broad community as dToF depth sensing is becoming mainstream on mobile devices.
A Generalized Framework for Video Instance Segmentation
Nov 16, 2022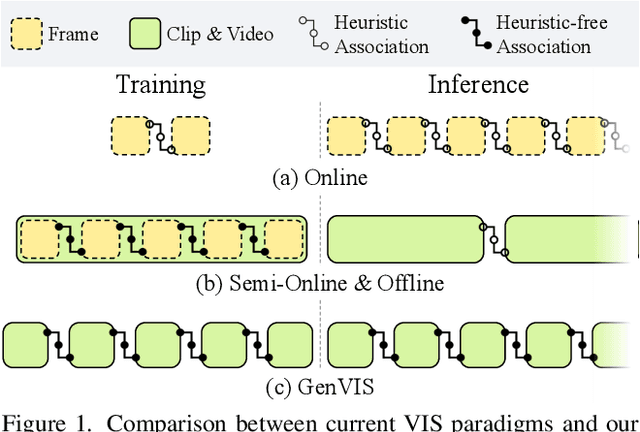
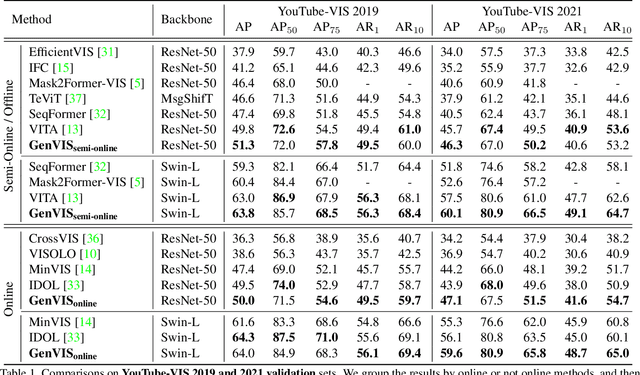
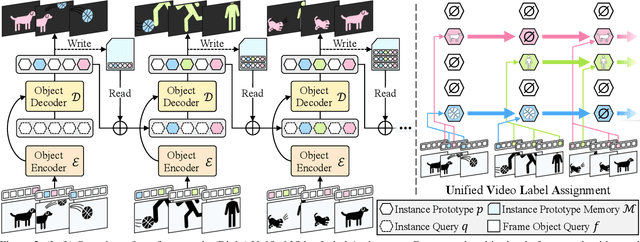
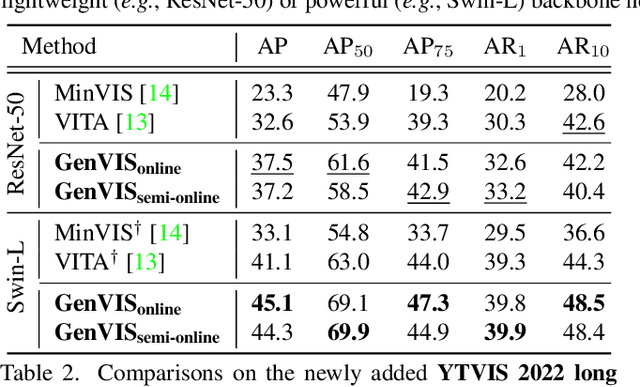
Recently, handling long videos of complex and occluded sequences has emerged as a new challenge in the video instance segmentation (VIS) community. However, existing methods show limitations in addressing the challenge. We argue that the biggest bottleneck in current approaches is the discrepancy between the training and the inference. To effectively bridge the gap, we propose a \textbf{Gen}eralized framework for \textbf{VIS}, namely \textbf{GenVIS}, that achieves the state-of-the-art performance on challenging benchmarks without designing complicated architectures or extra post-processing. The key contribution of GenVIS is the learning strategy. Specifically, we propose a query-based training pipeline for sequential learning, using a novel target label assignment strategy. To further fill the remaining gaps, we introduce a memory that effectively acquires information from previous states. Thanks to the new perspective, which focuses on building relationships between separate frames or clips, GenVIS can be flexibly executed in both online and semi-online manner. We evaluate our methods on popular VIS benchmarks, YouTube-VIS 2019/2021/2022 and Occluded VIS (OVIS), achieving state-of-the-art results. Notably, we greatly outperform the state-of-the-art on the long VIS benchmark (OVIS), improving 5.6 AP with ResNet-50 backbone. Code will be available at https://github.com/miranheo/GenVIS.
TransCC: Transformer-based Multiple Illuminant Color Constancy Using Multitask Learning
Nov 16, 2022
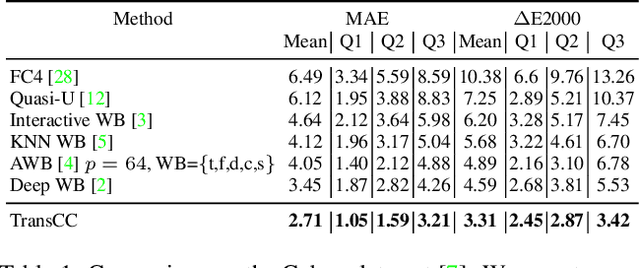
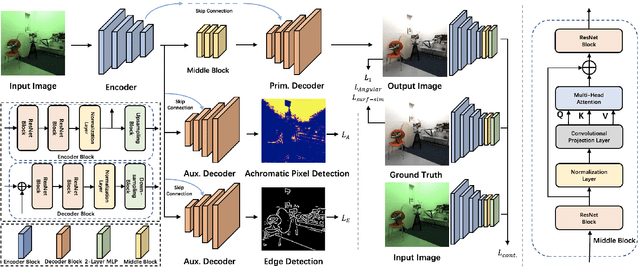
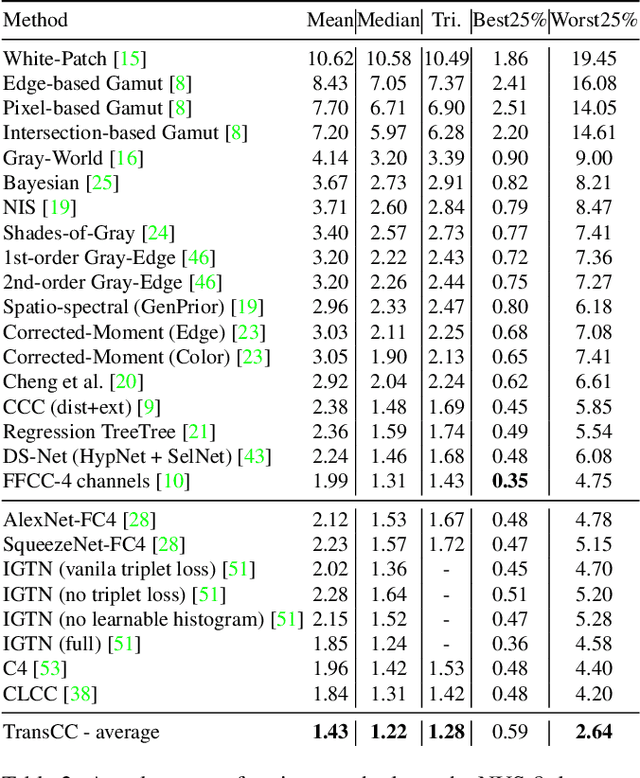
Multi-illuminant color constancy is a challenging problem with only a few existing methods. For example, one prior work used a small set of predefined white balance settings and spatially blended among them, limiting the solution to predefined illuminations. Another method proposed a generative adversarial network and an angular loss, yet the performance is suboptimal due to the lack of regularization for multi-illumination colors. This paper introduces a transformer-based multi-task learning method to estimate single and multiple light colors from a single input image. To help our deep learning model have better cues of the light colors, achromatic-pixel detection, and edge detection are used as auxiliary tasks in our multi-task learning setting. By exploiting extracted content features from the input image as tokens, illuminant color correlations between pixels are learned by leveraging contextual information in our transformer. Our transformer approach is further assisted via a contrastive loss defined between the input, output, and ground truth. We demonstrate that our proposed model achieves 40.7% improvement compared to a state-of-the-art multi-illuminant color constancy method on a multi-illuminant dataset (LSMI). Moreover, our model maintains a robust performance on the single illuminant dataset (NUS-8) and provides 22.3% improvement on the state-of-the-art single color constancy method.
PAANet:Visual Perception based Four-stage Framework for Salient Object Detection using High-order Contrast Operator
Nov 16, 2022
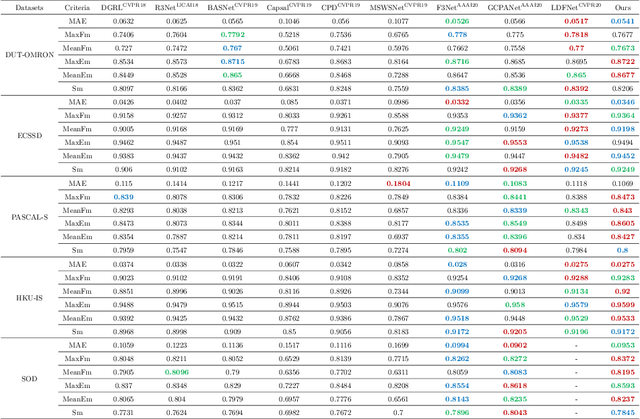
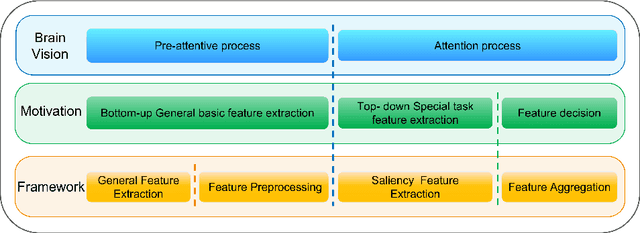
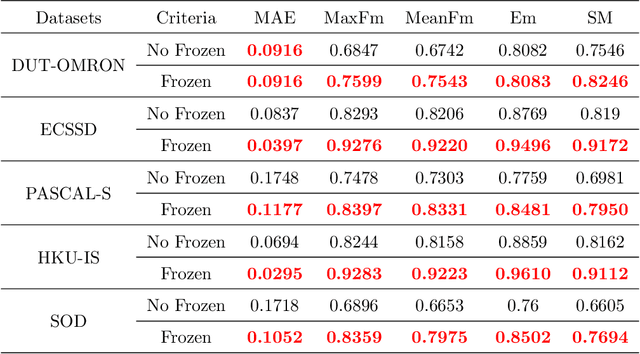
It is believed that human vision system (HVS) consists of pre-attentive process and attention process when performing salient object detection (SOD). Based on this fact, we propose a four-stage framework for SOD, in which the first two stages match the \textbf{P}re-\textbf{A}ttentive process consisting of general feature extraction (GFE) and feature preprocessing (FP), and the last two stages are corresponding to \textbf{A}ttention process containing saliency feature extraction (SFE) and the feature aggregation (FA), namely \textbf{PAANet}. According to the pre-attentive process, the GFE stage applies the fully-trained backbone and needs no further finetuning for different datasets. This modification can greatly increase the training speed. The FP stage plays the role of finetuning but works more efficiently because of its simpler structure and fewer parameters. Moreover, in SFE stage we design for saliency feature extraction a novel contrast operator, which works more semantically in contrast with the traditional convolution operator when extracting the interactive information between the foreground and its surroundings. Interestingly, this contrast operator can be cascaded to form a deeper structure and extract higher-order saliency more effective for complex scene. Comparative experiments with the state-of-the-art methods on 5 datasets demonstrate the effectiveness of our framework.
Streaming Joint Speech Recognition and Disfluency Detection
Nov 16, 2022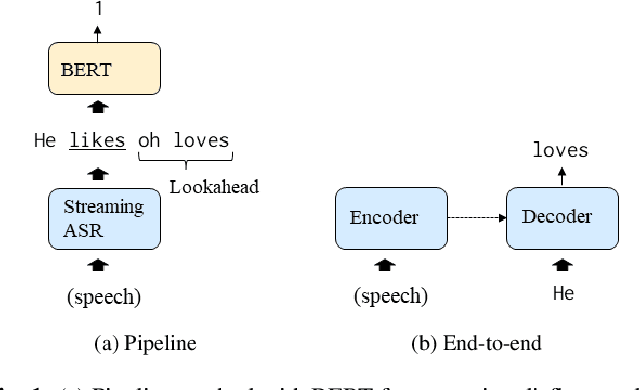

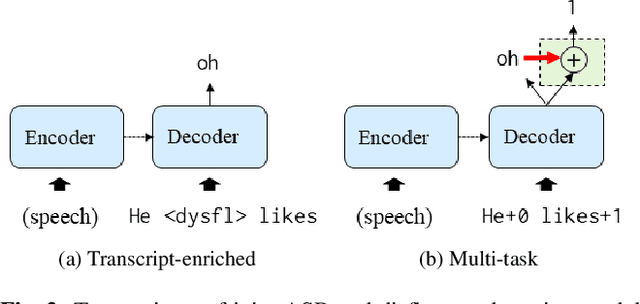

Disfluency detection has mainly been solved in a pipeline approach, as post-processing of speech recognition. In this study, we propose Transformer-based encoder-decoder models that jointly solve speech recognition and disfluency detection, which work in a streaming manner. Compared to pipeline approaches, the joint models can leverage acoustic information that makes disfluency detection robust to recognition errors and provide non-verbal clues. Moreover, joint modeling results in low-latency and lightweight inference. We investigate two joint model variants for streaming disfluency detection: a transcript-enriched model and a multi-task model. The transcript-enriched model is trained on text with special tags indicating the starting and ending points of the disfluent part. However, it has problems with latency and standard language model adaptation, which arise from the additional disfluency tags. We propose a multi-task model to solve such problems, which has two output layers at the Transformer decoder; one for speech recognition and the other for disfluency detection. It is modeled to be conditioned on the currently recognized token with an additional token-dependency mechanism. We show that the proposed joint models outperformed a BERT-based pipeline approach in both accuracy and latency, on both the Switchboard and the corpus of spontaneous Japanese.
Dwelling Type Classification for Disaster Risk Assessment Using Satellite Imagery
Nov 16, 2022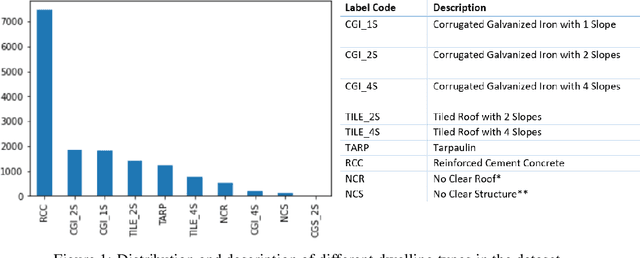
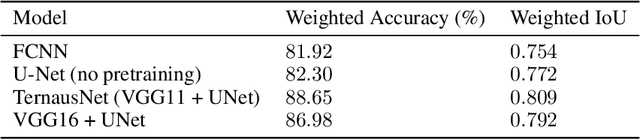
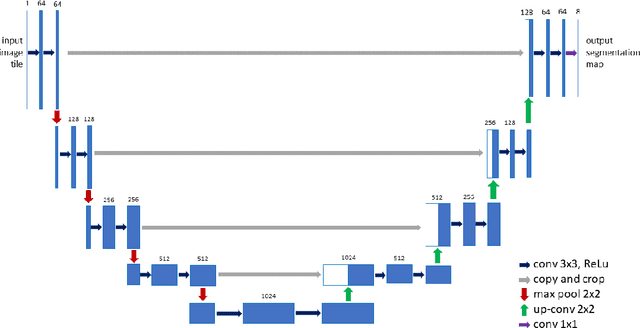
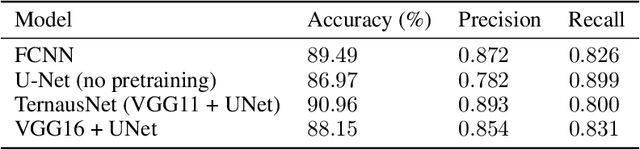
Vulnerability and risk assessment of neighborhoods is essential for effective disaster preparedness. Existing traditional systems, due to dependency on time-consuming and cost-intensive field surveying, do not provide a scalable way to decipher warnings and assess the precise extent of the risk at a hyper-local level. In this work, machine learning was used to automate the process of identifying dwellings and their type to build a potentially more effective disaster vulnerability assessment system. First, satellite imageries of low-income settlements and vulnerable areas in India were used to identify 7 different dwelling types. Specifically, we formulated the dwelling type classification as a semantic segmentation task and trained a U-net based neural network model, namely TernausNet, with the data we collected. Then a risk score assessment model was employed, using the determined dwelling type along with an inundation model of the regions. The entire pipeline was deployed to multiple locations prior to natural hazards in India in 2020. Post hoc ground-truth data from those regions was collected to validate the efficacy of this model which showed promising performance. This work can aid disaster response organizations and communities at risk by providing household-level risk information that can inform preemptive actions.
High-Resolution Boundary Detection for Medical Image Segmentation with Piece-Wise Two-Sample T-Test Augmented Loss
Nov 04, 2022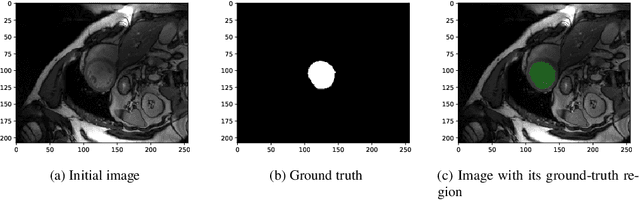
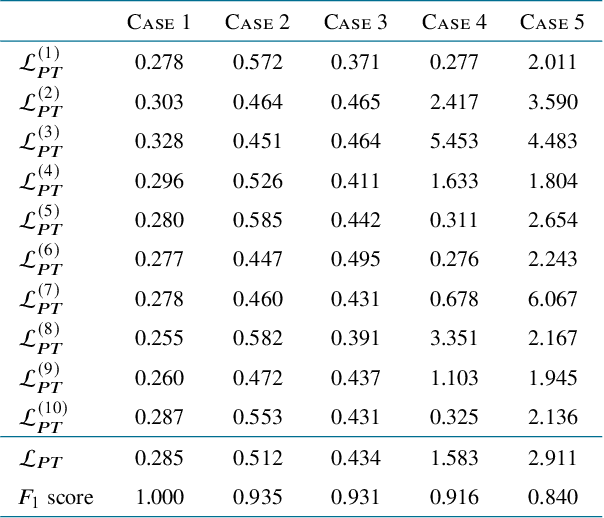
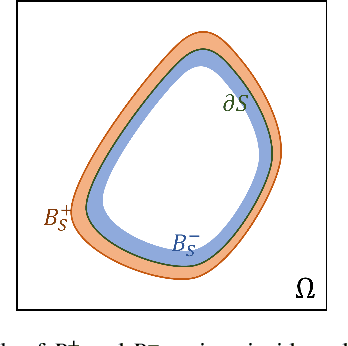
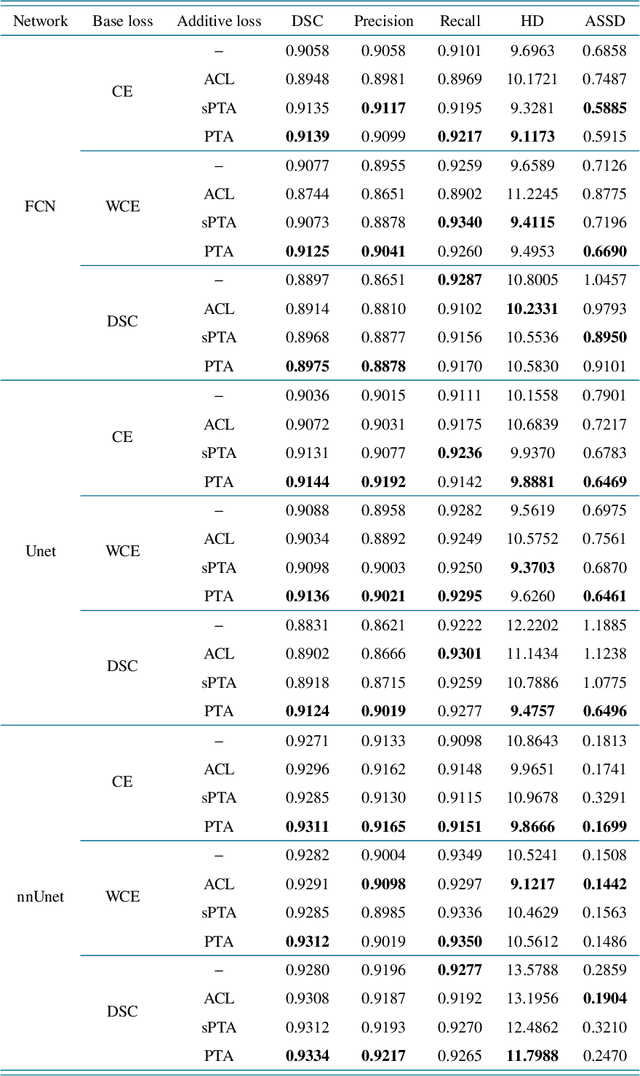
Deep learning methods have contributed substantially to the rapid advancement of medical image segmentation, the quality of which relies on the suitable design of loss functions. Popular loss functions, including the cross-entropy and dice losses, often fall short of boundary detection, thereby limiting high-resolution downstream applications such as automated diagnoses and procedures. We developed a novel loss function that is tailored to reflect the boundary information to enhance the boundary detection. As the contrast between segmentation and background regions along the classification boundary naturally induces heterogeneity over the pixels, we propose the piece-wise two-sample t-test augmented (PTA) loss that is infused with the statistical test for such heterogeneity. We demonstrate the improved boundary detection power of the PTA loss compared to benchmark losses without a t-test component.