 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
LLM-Enhanced User-Item Interactions: Leveraging Edge Information for Optimized Recommendations
Feb 14, 2024
The extraordinary performance of large language models has not only reshaped the research landscape in the field of NLP but has also demonstrated its exceptional applicative potential in various domains. However, the potential of these models in mining relationships from graph data remains under-explored. Graph neural networks, as a popular research area in recent years, have numerous studies on relationship mining. Yet, current cutting-edge research in graph neural networks has not been effectively integrated with large language models, leading to limited efficiency and capability in graph relationship mining tasks. A primary challenge is the inability of LLMs to deeply exploit the edge information in graphs, which is critical for understanding complex node relationships. This gap limits the potential of LLMs to extract meaningful insights from graph structures, limiting their applicability in more complex graph-based analysis. We focus on how to utilize existing LLMs for mining and understanding relationships in graph data, applying these techniques to recommendation tasks. We propose an innovative framework that combines the strong contextual representation capabilities of LLMs with the relationship extraction and analysis functions of GNNs for mining relationships in graph data. Specifically, we design a new prompt construction framework that integrates relational information of graph data into natural language expressions, aiding LLMs in more intuitively grasping the connectivity information within graph data. Additionally, we introduce graph relationship understanding and analysis functions into LLMs to enhance their focus on connectivity information in graph data. Our evaluation on real-world datasets demonstrates the framework's ability to understand connectivity information in graph data.
Parameterized quantum comb and simpler circuits for reversing unknown qubit-unitary operations
Mar 06, 2024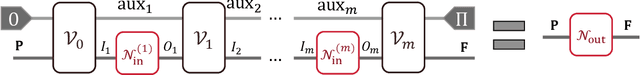
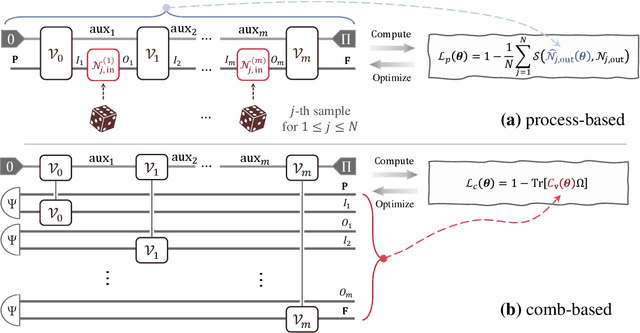
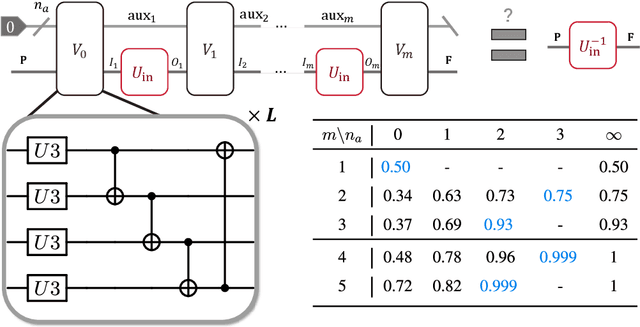
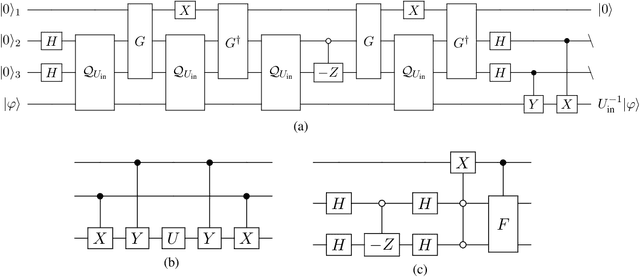
Quantum comb is an essential tool for characterizing complex quantum protocols in quantum information processing. In this work, we introduce PQComb, a framework leveraging parameterized quantum circuits to explore the capabilities of quantum combs for general quantum process transformation tasks and beyond. By optimizing PQComb for time-reversal simulations of unknown unitary evolutions, we develop a simpler protocol for unknown qubit unitary inversion that reduces the ancilla qubit overhead from 6 to 3 compared to the existing method in [Yoshida, Soeda, Murao, PRL 131, 120602, 2023]. This demonstrates the utility of quantum comb structures and showcases PQComb's potential for solving complex quantum tasks. Our results pave the way for broader PQComb applications in quantum computing and quantum information, emphasizing its versatility for tackling diverse problems in quantum machine learning.
FaaF: Facts as a Function for the evaluation of RAG systems
Mar 06, 2024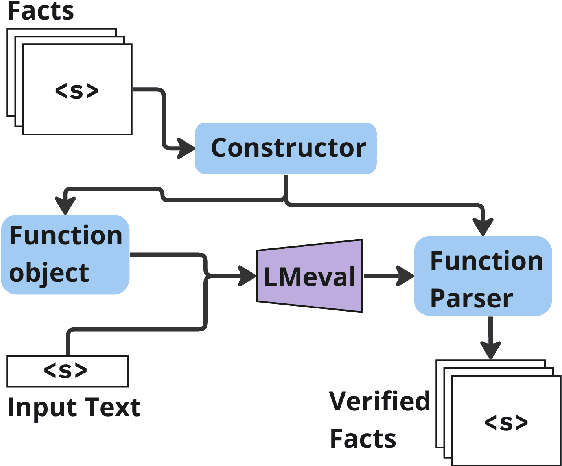

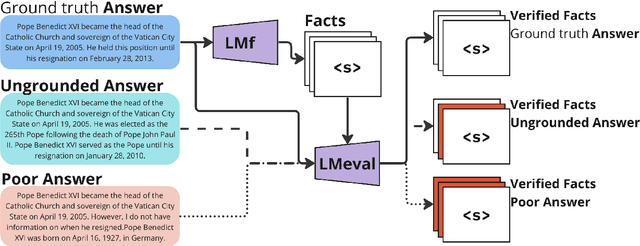
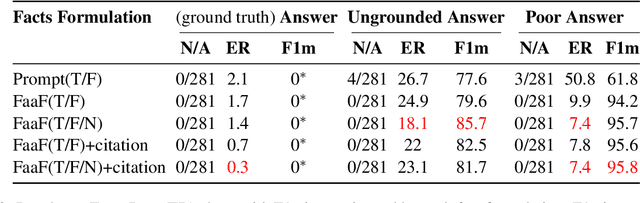
Factual recall from a reference source is crucial for evaluating the performance of Retrieval Augmented Generation (RAG) systems, as it directly probes into the quality of both retrieval and generation. However, it still remains a challenge to perform this evaluation reliably and efficiently. Recent work has focused on fact verification via prompting language model (LM) evaluators, however we demonstrate that these methods are unreliable in the presence of incomplete or inaccurate information. We introduce Facts as a Function (FaaF), a new approach to fact verification that utilizes the function calling abilities of LMs and a framework for RAG factual recall evaluation. FaaF substantially improves the ability of LMs to identify unsupported facts in text with incomplete information whilst improving efficiency and lowering cost by several times, compared to prompt-based approaches.
PrimeComposer: Faster Progressively Combined Diffusion for Image Composition with Attention Steering
Mar 08, 2024
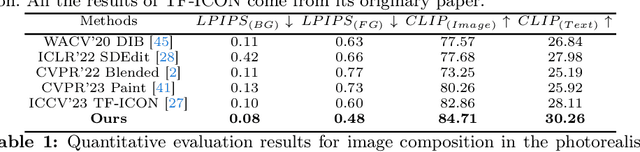

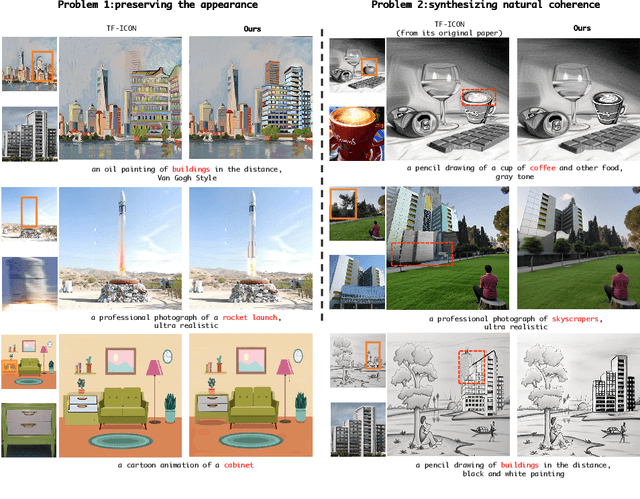
Image composition involves seamlessly integrating given objects into a specific visual context. The current training-free methods rely on composing attention weights from several samplers to guide the generator. However, since these weights are derived from disparate contexts, their combination leads to coherence confusion in synthesis and loss of appearance information. These issues worsen with their excessive focus on background generation, even when unnecessary in this task. This not only slows down inference but also compromises foreground generation quality. Moreover, these methods introduce unwanted artifacts in the transition area. In this paper, we formulate image composition as a subject-based local editing task, solely focusing on foreground generation. At each step, the edited foreground is combined with the noisy background to maintain scene consistency. To address the remaining issues, we propose PrimeComposer, a faster training-free diffuser that composites the images by well-designed attention steering across different noise levels. This steering is predominantly achieved by our Correlation Diffuser, utilizing its self-attention layers at each step. Within these layers, the synthesized subject interacts with both the referenced object and background, capturing intricate details and coherent relationships. This prior information is encoded into the attention weights, which are then integrated into the self-attention layers of the generator to guide the synthesis process. Besides, we introduce a Region-constrained Cross-Attention to confine the impact of specific subject-related words to desired regions, addressing the unwanted artifacts shown in the prior method thereby further improving the coherence in the transition area. Our method exhibits the fastest inference efficiency and extensive experiments demonstrate our superiority both qualitatively and quantitatively.
PromptMM: Multi-Modal Knowledge Distillation for Recommendation with Prompt-Tuning
Mar 10, 2024Multimedia online platforms (e.g., Amazon, TikTok) have greatly benefited from the incorporation of multimedia (e.g., visual, textual, and acoustic) content into their personal recommender systems. These modalities provide intuitive semantics that facilitate modality-aware user preference modeling. However, two key challenges in multi-modal recommenders remain unresolved: i) The introduction of multi-modal encoders with a large number of additional parameters causes overfitting, given high-dimensional multi-modal features provided by extractors (e.g., ViT, BERT). ii) Side information inevitably introduces inaccuracies and redundancies, which skew the modality-interaction dependency from reflecting true user preference. To tackle these problems, we propose to simplify and empower recommenders through Multi-modal Knowledge Distillation (PromptMM) with the prompt-tuning that enables adaptive quality distillation. Specifically, PromptMM conducts model compression through distilling u-i edge relationship and multi-modal node content from cumbersome teachers to relieve students from the additional feature reduction parameters. To bridge the semantic gap between multi-modal context and collaborative signals for empowering the overfitting teacher, soft prompt-tuning is introduced to perform student task-adaptive. Additionally, to adjust the impact of inaccuracies in multimedia data, a disentangled multi-modal list-wise distillation is developed with modality-aware re-weighting mechanism. Experiments on real-world data demonstrate PromptMM's superiority over existing techniques. Ablation tests confirm the effectiveness of key components. Additional tests show the efficiency and effectiveness.
Non-Intrusive Load Monitoring with Missing Data Imputation Based on Tensor Decomposition
Mar 09, 2024
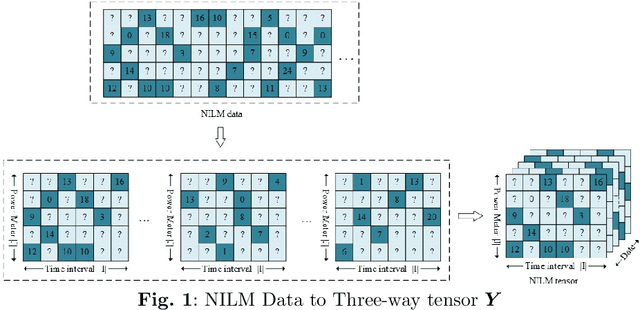
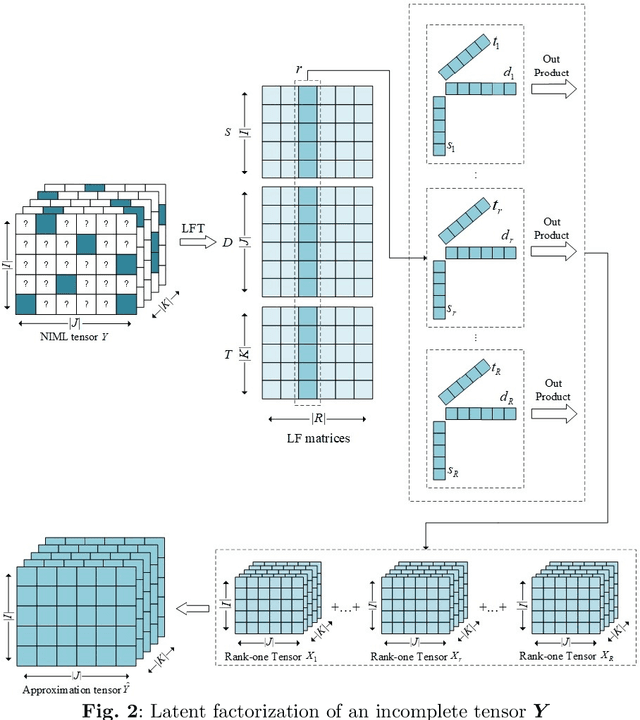
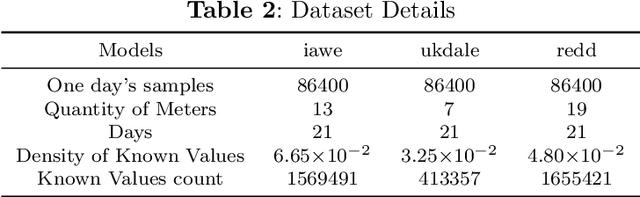
With the widespread adoption of Non-Intrusive Load Monitoring (NILM) in building energy management, ensuring the high quality of NILM data has become imperative. However, practical applications of NILM face challenges associated with data loss, significantly impacting accuracy and reliability in energy management. This paper addresses the issue of NILM data loss by introducing an innovative tensor completion(TC) model- Proportional-Integral-Derivative (PID)-incorporated Non-negative Latent Factorization of Tensors (PNLFT) with twofold ideas: 1) To tackle the issue of slow convergence in Latent Factorization of Tensors (LFT) using Stochastic Gradient Descent (SGD), a Proportional-Integral-Derivative controller is introduced during the learning process. The PID controller utilizes historical and current information to control learning residuals. 2) Considering the characteristics of NILM data, non-negative update rules are proposed in the model's learning scheme. Experimental results on three datasets demonstrate that, compared to state-of-the-art models, the proposed model exhibits noteworthy enhancements in both convergence speed and accuracy.
Deep Contrastive Multi-view Clustering under Semantic Feature Guidance
Mar 09, 2024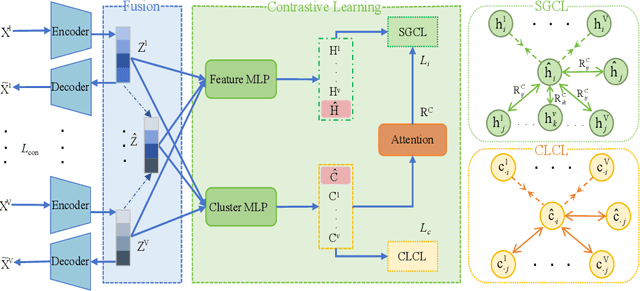
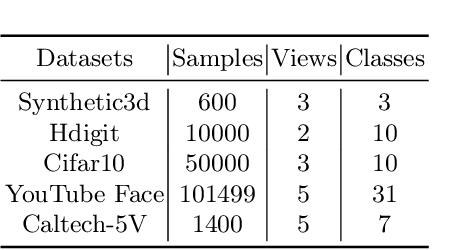
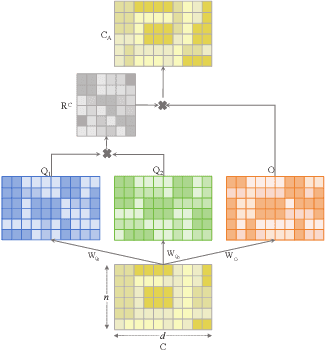
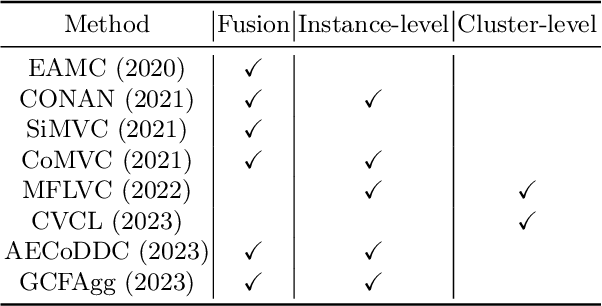
Contrastive learning has achieved promising performance in the field of multi-view clustering recently. However, the positive and negative sample construction mechanisms ignoring semantic consistency lead to false negative pairs, limiting the performance of existing algorithms from further improvement. To solve this problem, we propose a multi-view clustering framework named Deep Contrastive Multi-view Clustering under Semantic feature guidance (DCMCS) to alleviate the influence of false negative pairs. Specifically, view-specific features are firstly extracted from raw features and fused to obtain fusion view features according to view importance. To mitigate the interference of view-private information, specific view and fusion view semantic features are learned by cluster-level contrastive learning and concatenated to measure the semantic similarity of instances. By minimizing instance-level contrastive loss weighted by semantic similarity, DCMCS adaptively weakens contrastive leaning between false negative pairs. Experimental results on several public datasets demonstrate the proposed framework outperforms the state-of-the-art methods.
Triple-CFN: Restructuring Conceptual Spaces for Enhancing Abstract Reasoning process
Mar 09, 2024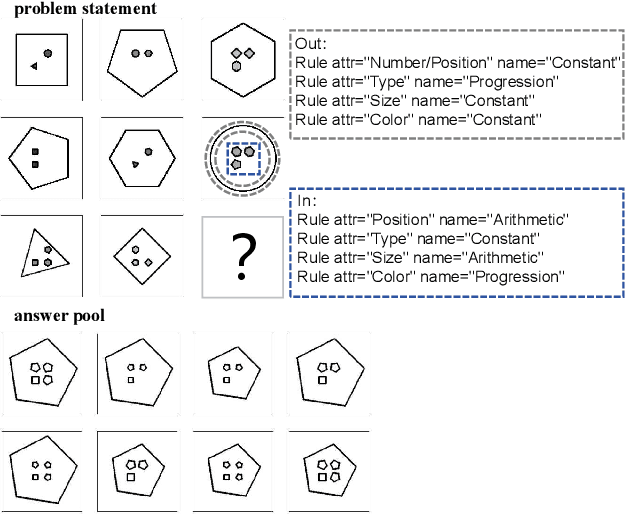
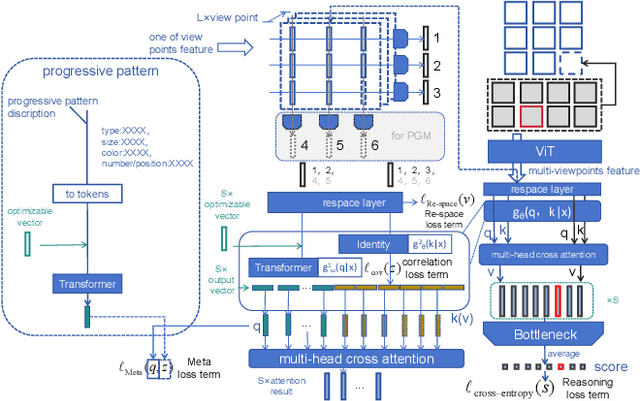
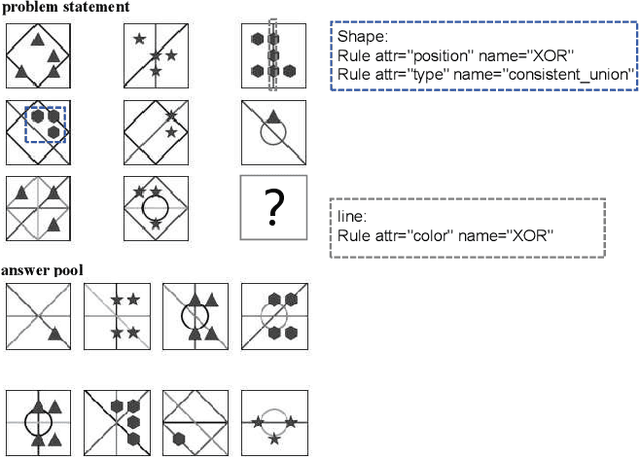

Abstract reasoning problems pose significant challenges to artificial intelligence algorithms, demanding cognitive capabilities beyond those required for perception tasks. This study introduces the Triple-CFN approach to tackle the Bongard-Logo problem, achieving notable reasoning accuracy by implicitly reorganizing the concept space of conflicting instances. Additionally, the Triple-CFN paradigm proves effective for the RPM problem with necessary modifications, yielding competitive results. To further enhance performance on the RPM issue, we develop the Meta Triple-CFN network, which explicitly structures the problem space while maintaining interpretability on progressive patterns. The success of Meta Triple-CFN is attributed to its paradigm of modeling the conceptual space, equivalent to normalizing reasoning information. Based on this ideology, we introduce the Re-space layer, enhancing the performance of both Meta Triple-CFN and Triple-CFN. This paper aims to contribute to advancements in machine intelligence by exploring innovative network designs for addressing abstract reasoning problems, paving the way for further breakthroughs in this domain.
Foundational propositions of hesitant fuzzy soft $β$-covering approximation spaces
Mar 08, 2024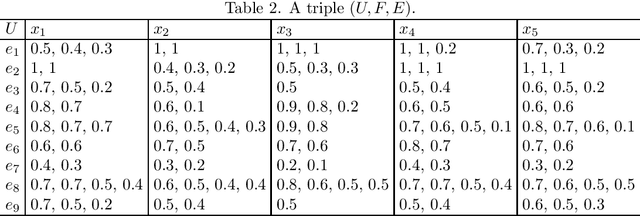
Soft set theory serves as a mathematical framework for handling uncertain information, and hesitant fuzzy sets find extensive application in scenarios involving uncertainty and hesitation. Hesitant fuzzy sets exhibit diverse membership degrees, giving rise to various forms of inclusion relationships among them. This article introduces the notions of hesitant fuzzy soft $\beta$-coverings and hesitant fuzzy soft $\beta$-neighborhoods, which are formulated based on distinct forms of inclusion relationships among hesitancy fuzzy sets. Subsequently, several associated properties are investigated. Additionally, specific variations of hesitant fuzzy soft $\beta$-coverings are introduced by incorporating hesitant fuzzy rough sets, followed by an exploration of properties pertaining to hesitant fuzzy soft $\beta$-covering approximation spaces.
Deep Structural Knowledge Exploitation and Synergy for Estimating Node Importance Value on Heterogeneous Information Networks
Feb 19, 2024Node importance estimation problem has been studied conventionally with homogeneous network topology analysis. To deal with network heterogeneity, a few recent methods employ graph neural models to automatically learn diverse sources of information. However, the major concern revolves around that their full adaptive learning process may lead to insufficient information exploration, thereby formulating the problem as the isolated node value prediction with underperformance and less interpretability. In this work, we propose a novel learning framework: SKES. Different from previous automatic learning designs, SKES exploits heterogeneous structural knowledge to enrich the informativeness of node representations. Based on a sufficiently uninformative reference, SKES estimates the importance value for any input node, by quantifying its disparity against the reference. This establishes an interpretable node importance computation paradigm. Furthermore, SKES dives deep into the understanding that "nodes with similar characteristics are prone to have similar importance values" whilst guaranteeing that such informativeness disparity between any different nodes is orderly reflected by the embedding distance of their associated latent features. Extensive experiments on three widely-evaluated benchmarks demonstrate the performance superiority of SKES over several recent competing methods.