 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Towards Interpreting Vulnerability of Multi-Instance Learning via Customized and Universal Adversarial Perturbations
Nov 30, 2022
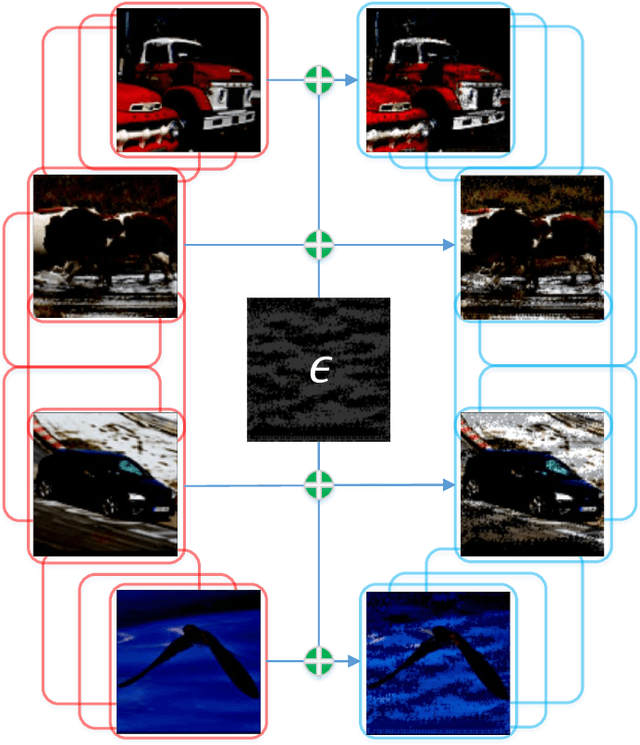
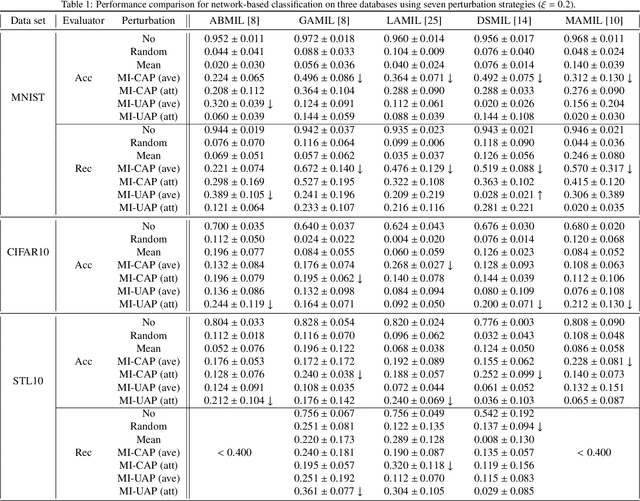
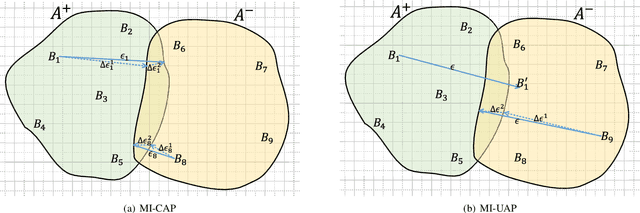
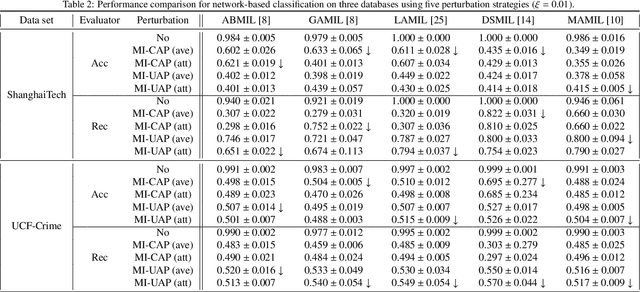
Multi-instance learning (MIL) is a great paradigm for dealing with complex data and has achieved impressive achievements in a number of fields, including image classification, video anomaly detection, and far more. Each data sample is referred to as a bag containing several unlabeled instances, and the supervised information is only provided at the bag-level. The safety of MIL learners is concerning, though, as we can greatly fool them by introducing a few adversarial perturbations. This can be fatal in some cases, such as when users are unable to access desired images and criminals are attempting to trick surveillance cameras. In this paper, we design two adversarial perturbations to interpret the vulnerability of MIL methods. The first method can efficiently generate the bag-specific perturbation (called customized) with the aim of outsiding it from its original classification region. The second method builds on the first one by investigating the image-agnostic perturbation (called universal) that aims to affect all bags in a given data set and obtains some generalizability. We conduct various experiments to verify the performance of these two perturbations, and the results show that both of them can effectively fool MIL learners. We additionally propose a simple strategy to lessen the effects of adversarial perturbations. Source codes are available at https://github.com/InkiInki/MI-UAP.
Proficiency assessment of L2 spoken English using wav2vec 2.0
Oct 24, 2022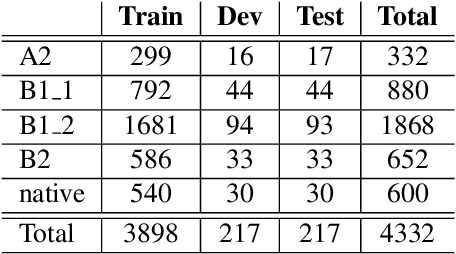
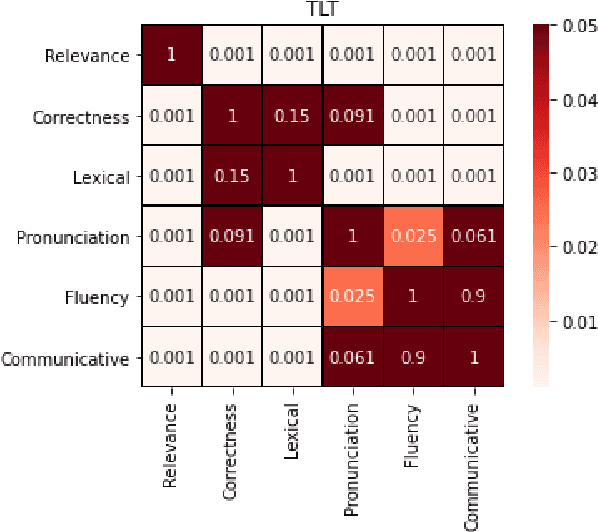
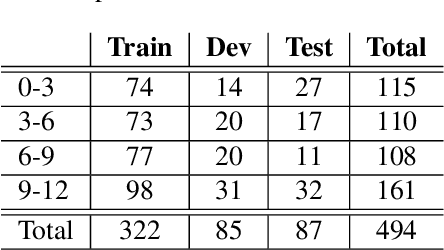
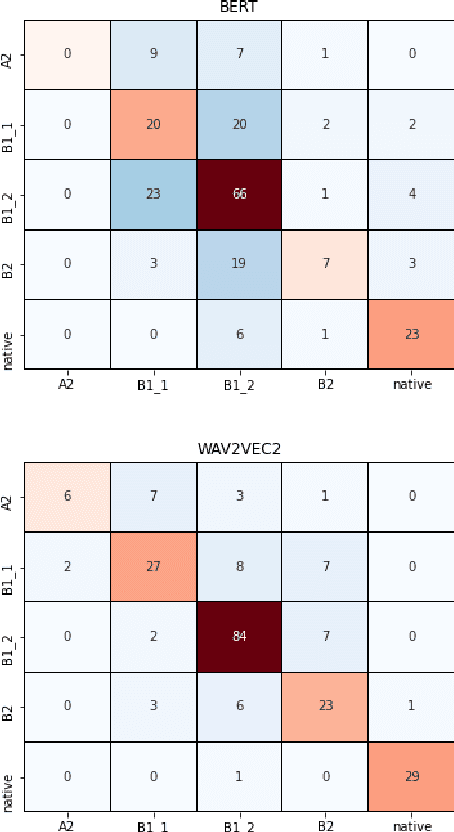
The increasing demand for learning English as a second language has led to a growing interest in methods for automatically assessing spoken language proficiency. Most approaches use hand-crafted features, but their efficacy relies on their particular underlying assumptions and they risk discarding potentially salient information about proficiency. Other approaches rely on transcriptions produced by ASR systems which may not provide a faithful rendition of a learner's utterance in specific scenarios (e.g., non-native children's spontaneous speech). Furthermore, transcriptions do not yield any information about relevant aspects such as intonation, rhythm or prosody. In this paper, we investigate the use of wav2vec 2.0 for assessing overall and individual aspects of proficiency on two small datasets, one of which is publicly available. We find that this approach significantly outperforms the BERT-based baseline system trained on ASR and manual transcriptions used for comparison.
SUMBot: Summarizing Context in Open-Domain Dialogue Systems
Oct 12, 2022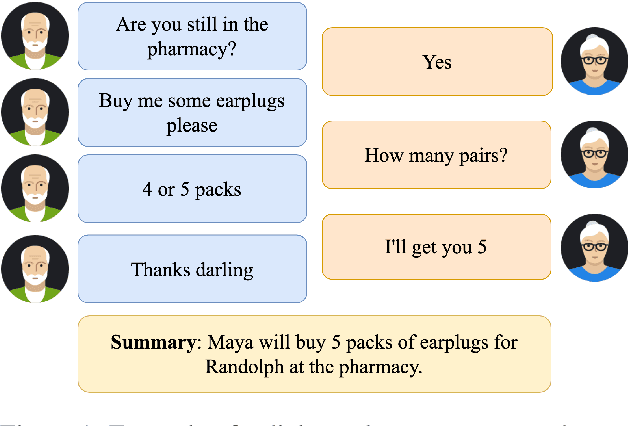
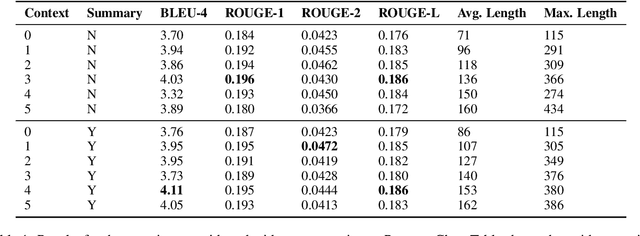
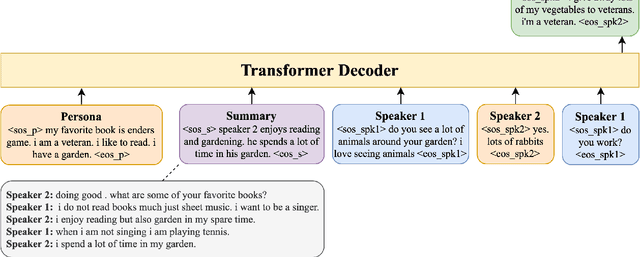
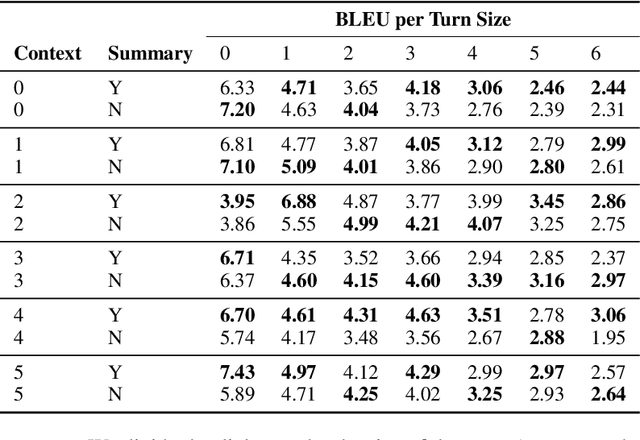
In this paper, we investigate the problem of including relevant information as context in open-domain dialogue systems. Most models struggle to identify and incorporate important knowledge from dialogues and simply use the entire turns as context, which increases the size of the input fed to the model with unnecessary information. Additionally, due to the input size limitation of a few hundred tokens of large pre-trained models, regions of the history are not included and informative parts from the dialogue may be omitted. In order to surpass this problem, we introduce a simple method that substitutes part of the context with a summary instead of the whole history, which increases the ability of models to keep track of all the previous relevant information. We show that the inclusion of a summary may improve the answer generation task and discuss some examples to further understand the system's weaknesses.
Continuous Emotion Recognition using Visual-audio-linguistic information: A Technical Report for ABAW3
Mar 30, 2022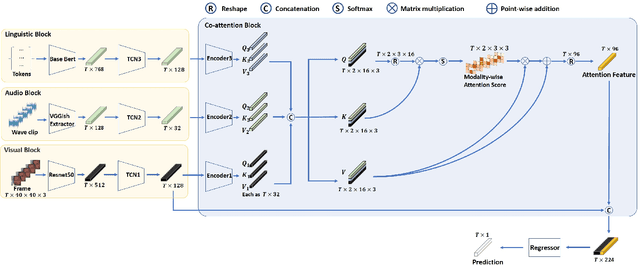
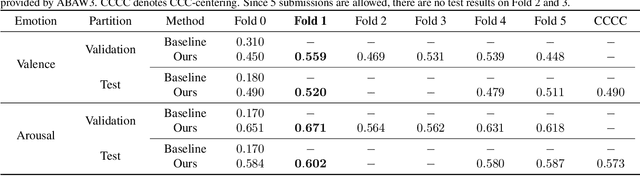
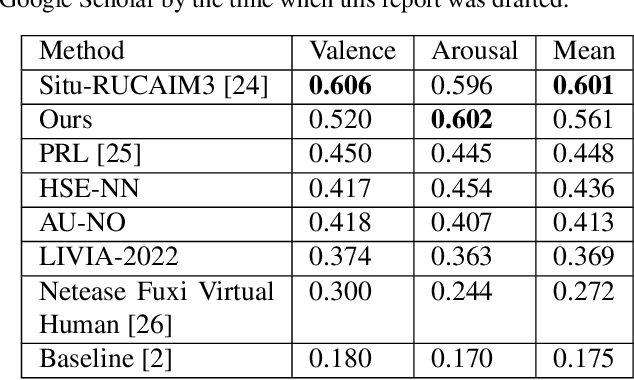
We propose a cross-modal co-attention model for continuous emotion recognition using visual-audio-linguistic information. The model consists of four blocks. The visual, audio, and linguistic blocks are used to learn the spatial-temporal features of the multi-modal input. A co-attention block is designed to fuse the learned features with the multi-head co-attention mechanism. The visual encoding from the visual block is concatenated with the attention feature to emphasize the visual information. To make full use of the data and alleviate over-fitting, cross-validation is carried out on the training and validation set. The concordance correlation coefficient (CCC) centering is used to merge the results from each fold. The achieved CCC on the test set is $0.520$ for valence and $0.602$ for arousal, which significantly outperforms the baseline method with the corresponding CCC of 0.180 and 0.170 for valence and arousal, respectively. The code is available at https://github.com/sucv/ABAW3.
Efficient Graph Neural Network Inference at Large Scale
Nov 05, 2022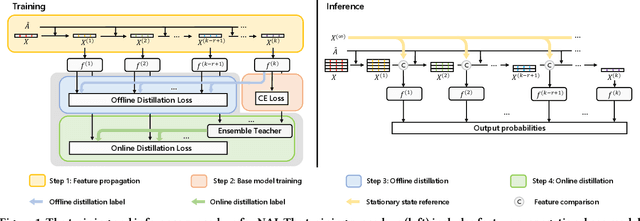
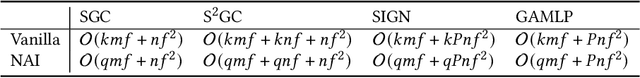
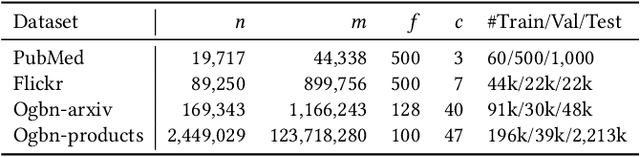
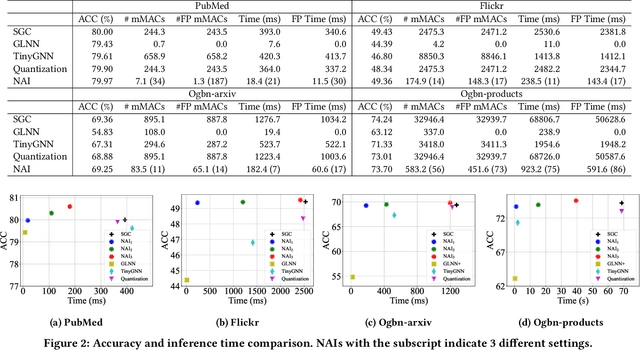
Graph neural networks (GNNs) have demonstrated excellent performance in a wide range of applications. However, the enormous size of large-scale graphs hinders their applications under real-time inference scenarios. Although existing scalable GNNs leverage linear propagation to preprocess the features and accelerate the training and inference procedure, these methods still suffer from scalability issues when making inferences on unseen nodes, as the feature preprocessing requires the graph is known and fixed. To speed up the inference in the inductive setting, we propose a novel adaptive propagation order approach that generates the personalized propagation order for each node based on its topological information. This could successfully avoid the redundant computation of feature propagation. Moreover, the trade-off between accuracy and inference latency can be flexibly controlled by simple hyper-parameters to match different latency constraints of application scenarios. To compensate for the potential inference accuracy loss, we further propose Inception Distillation to exploit the multi scale reception information and improve the inference performance. Extensive experiments are conducted on four public datasets with different scales and characteristics, and the experimental results show that our proposed inference acceleration framework outperforms the SOTA graph inference acceleration baselines in terms of both accuracy and efficiency. In particular, the advantage of our proposed method is more significant on larger-scale datasets, and our framework achieves $75\times$ inference speedup on the largest Ogbn-products dataset.
Design of Reconfigurable Intelligent Surface-Aided Cross-Media Communications
Nov 05, 2022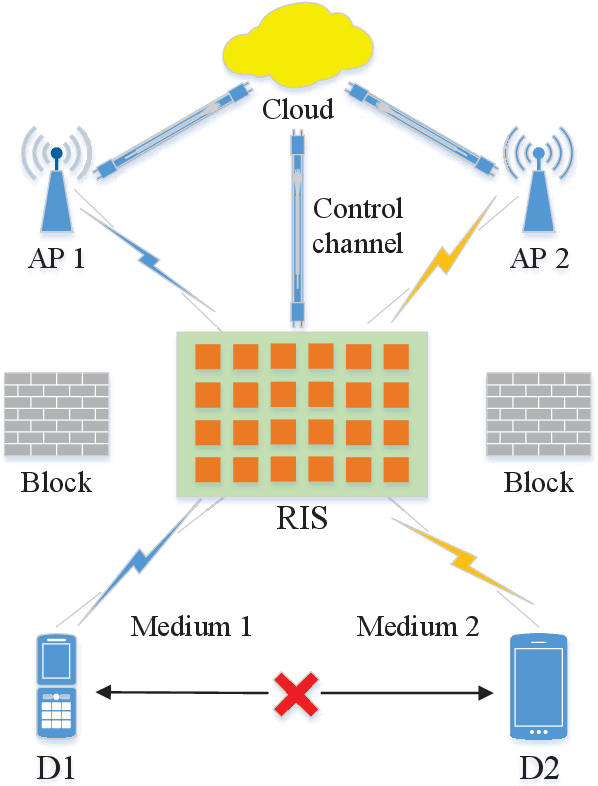
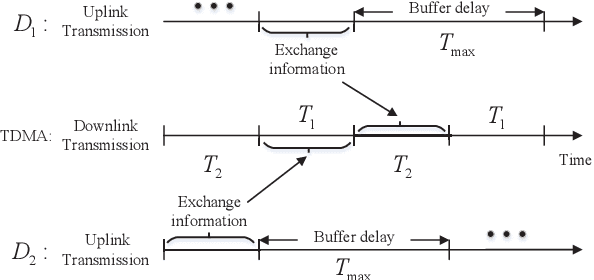
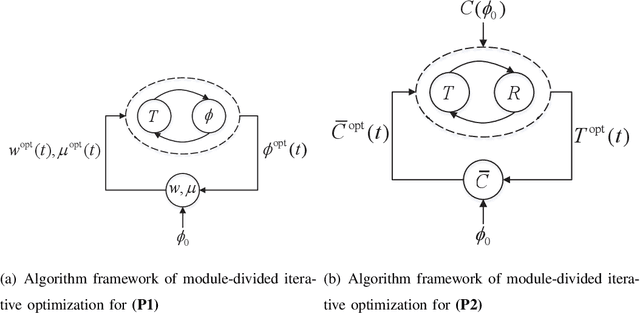
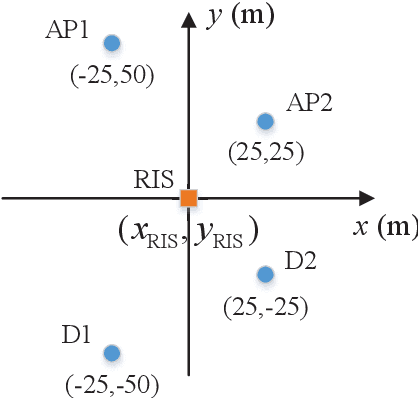
A novel reconfigurable intelligent surface (RIS)-aided hybrid reflection/transmitter design is proposed for achieving information exchange in cross-media communications. In pursuit of the balance between energy efficiency and low-cost implementations, the cloud-management transmission protocol is adopted in the integrated multi-media system. Specifically, the messages of devices using heterogeneous propagation media, are firstly transmitted to the medium-matched AP, with the aid of the RIS-based dual-hop transmission. After the operation of intermediate frequency conversion, the access point (AP) uploads the received signals to the cloud for further demodulating and decoding process. Based on time division multiple access (TDMA), the cloud is able to distinguish the downlink data transmitted to different devices and transforms them into the input of the RIS controller via the dedicated control channel. Thereby, the RIS can passively reflect the incident carrier back into the original receiver with the exchanged information during the preallocated slots, following the idea of an index modulation-based transmitter. Moreover, the iterative optimization algorithm is utilized for optimizing the RIS phase, transmit rate and time allocation jointly in the delay-constrained cross-media communication model. Our simulation results demonstrate that the proposed RIS-based scheme can improve the end-to-end throughput than that of the AP-based transmission, the equal time allocation, the random and the discrete phase adjustment benchmarks.
Vision-based navigation and obstacle avoidance via deep reinforcement learning
Nov 09, 2022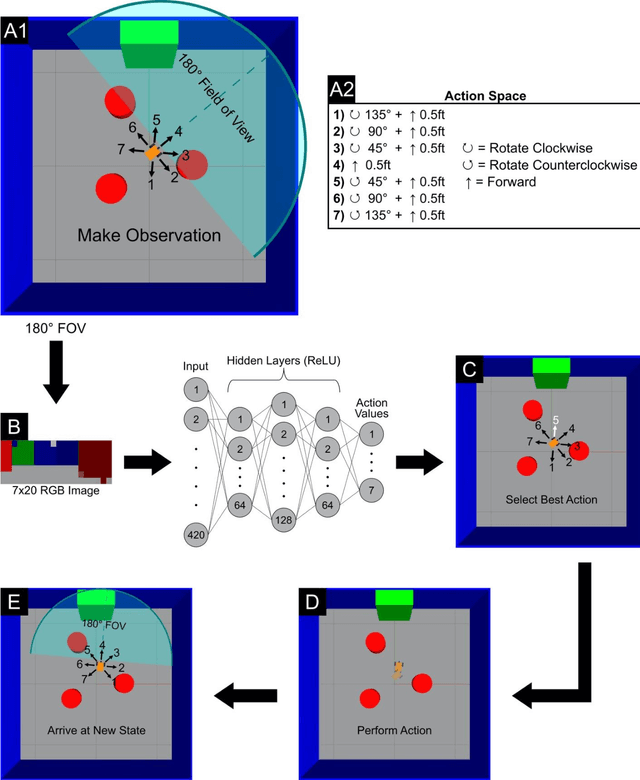

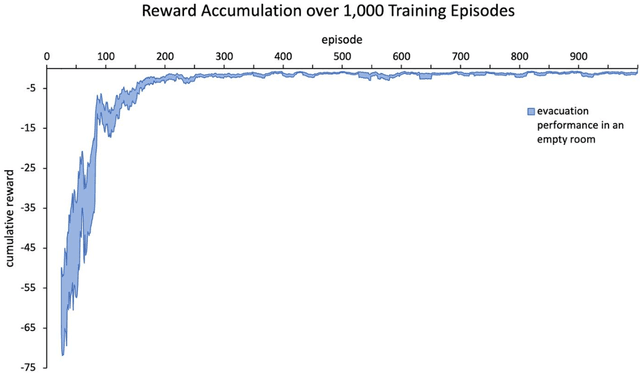
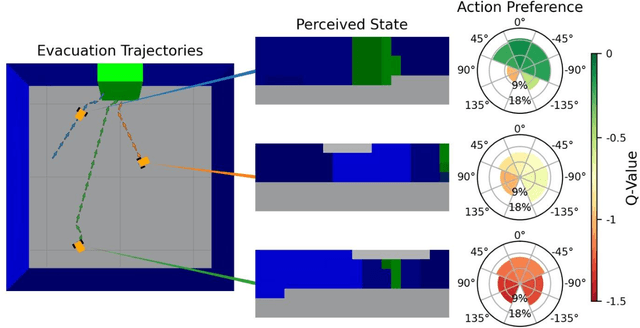
Development of navigation algorithms is essential for the successful deployment of robots in rapidly changing hazardous environments for which prior knowledge of configuration is often limited or unavailable. Use of traditional path-planning algorithms, which are based on localization and require detailed obstacle maps with goal locations, is not possible. In this regard, vision-based algorithms hold great promise, as visual information can be readily acquired by a robot's onboard sensors and provides a much richer source of information from which deep neural networks can extract complex patterns. Deep reinforcement learning has been used to achieve vision-based robot navigation. However, the efficacy of these algorithms in environments with dynamic obstacles and high variation in the configuration space has not been thoroughly investigated. In this paper, we employ a deep Dyna-Q learning algorithm for room evacuation and obstacle avoidance in partially observable environments based on low-resolution raw image data from an onboard camera. We explore the performance of a robotic agent in environments containing no obstacles, convex obstacles, and concave obstacles, both static and dynamic. Obstacles and the exit are initialized in random positions at the start of each episode of reinforcement learning. Overall, we show that our algorithm and training approach can generalize learning for collision-free evacuation of environments with complex obstacle configurations. It is evident that the agent can navigate to a goal location while avoiding multiple static and dynamic obstacles, and can escape from a concave obstacle while searching for and navigating to the exit.
Transformers for End-to-End InfoSec Tasks: A Feasibility Study
Dec 05, 2022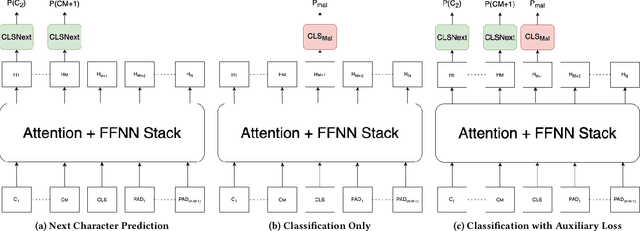
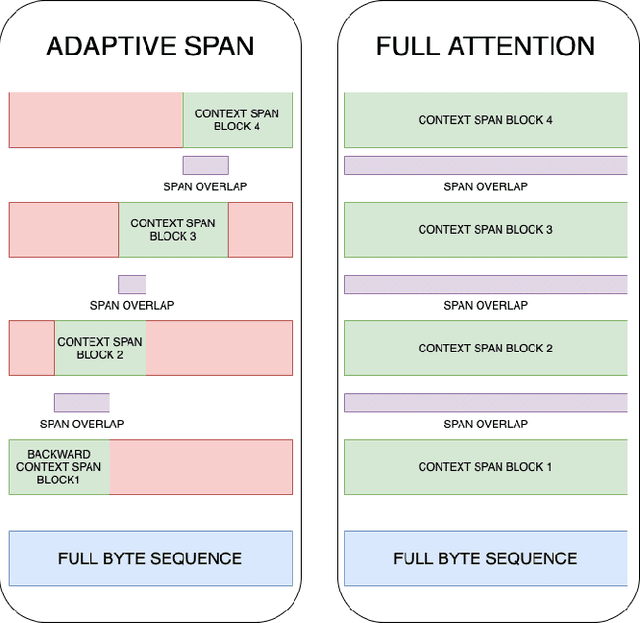
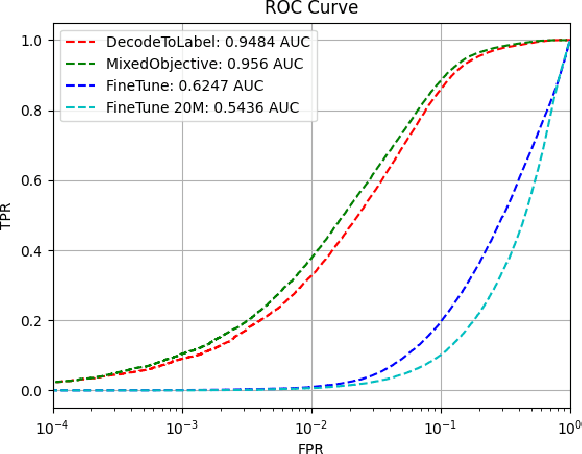
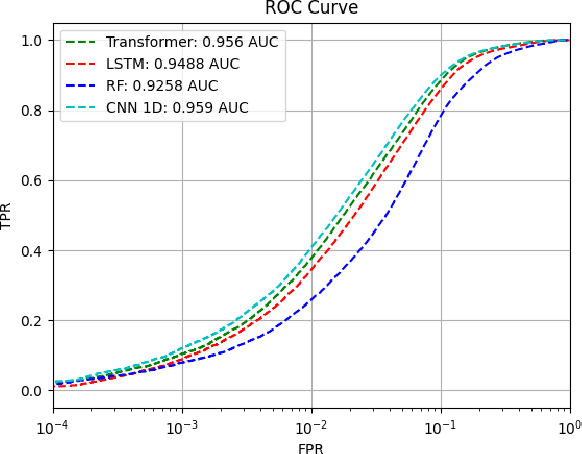
In this paper, we assess the viability of transformer models in end-to-end InfoSec settings, in which no intermediate feature representations or processing steps occur outside the model. We implement transformer models for two distinct InfoSec data formats - specifically URLs and PE files - in a novel end-to-end approach, and explore a variety of architectural designs, training regimes, and experimental settings to determine the ingredients necessary for performant detection models. We show that in contrast to conventional transformers trained on more standard NLP-related tasks, our URL transformer model requires a different training approach to reach high performance levels. Specifically, we show that 1) pre-training on a massive corpus of unlabeled URL data for an auto-regressive task does not readily transfer to binary classification of malicious or benign URLs, but 2) that using an auxiliary auto-regressive loss improves performance when training from scratch. We introduce a method for mixed objective optimization, which dynamically balances contributions from both loss terms so that neither one of them dominates. We show that this method yields quantitative evaluation metrics comparable to that of several top-performing benchmark classifiers. Unlike URLs, binary executables contain longer and more distributed sequences of information-rich bytes. To accommodate such lengthy byte sequences, we introduce additional context length into the transformer by providing its self-attention layers with an adaptive span similar to Sukhbaatar et al. We demonstrate that this approach performs comparably to well-established malware detection models on benchmark PE file datasets, but also point out the need for further exploration into model improvements in scalability and compute efficiency.
* Post-print of a manuscript accepted to ACM Asia-CCS Workshop on Robust Malware Analysis (WoRMA) 2022. 11 Pages total. arXiv admin note: substantial text overlap with arXiv:2011.03040
Hardness-guided domain adaptation to recognise biomedical named entities under low-resource scenarios
Nov 11, 2022
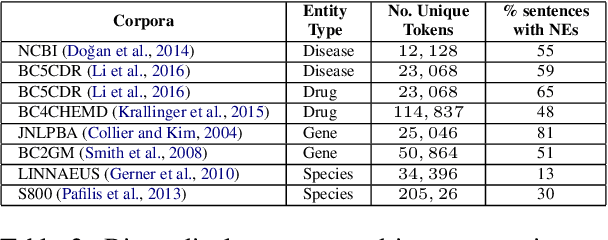
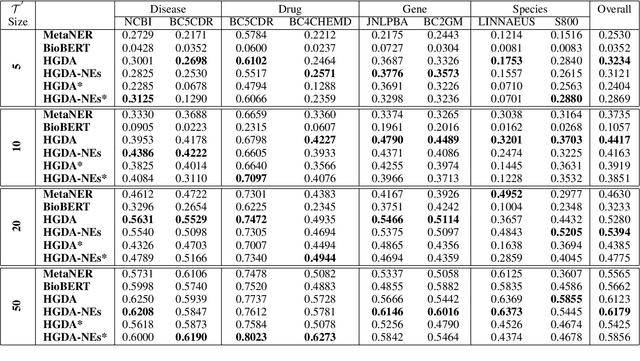
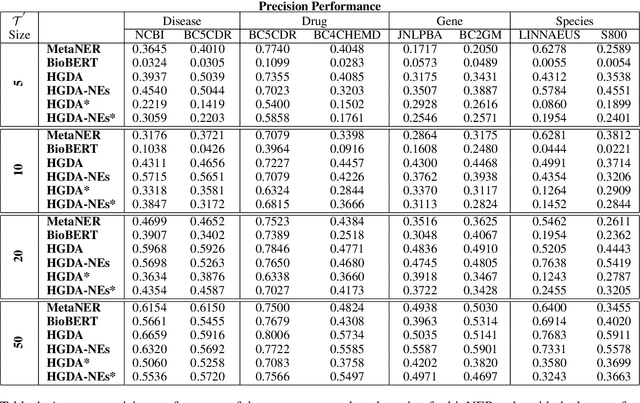
Domain adaptation is an effective solution to data scarcity in low-resource scenarios. However, when applied to token-level tasks such as bioNER, domain adaptation methods often suffer from the challenging linguistic characteristics that clinical narratives possess, which leads to unsatisfactory performance. In this paper, we present a simple yet effective hardness-guided domain adaptation (HGDA) framework for bioNER tasks that can effectively leverage the domain hardness information to improve the adaptability of the learnt model in low-resource scenarios. Experimental results on biomedical datasets show that our model can achieve significant performance improvement over the recently published state-of-the-art (SOTA) MetaNER model
Hand Avatar: Free-Pose Hand Animation and Rendering from Monocular Video
Nov 23, 2022
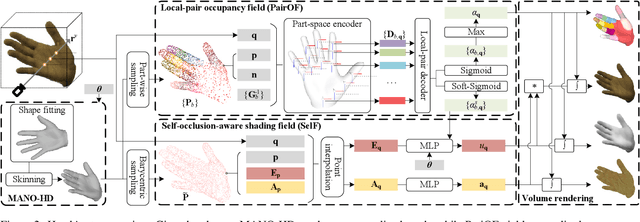
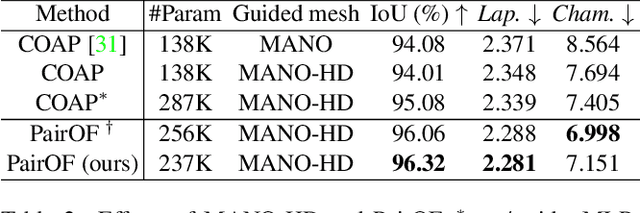
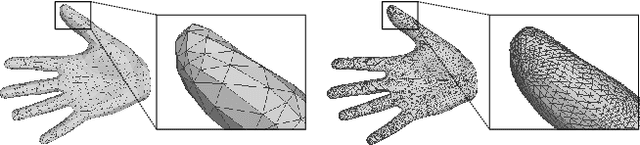
We present HandAvatar, a novel representation for hand animation and rendering, which can generate smoothly compositional geometry and self-occlusion-aware texture. Specifically, we first develop a MANO-HD model as a high-resolution mesh topology to fit personalized hand shapes. Sequentially, we decompose hand geometry into per-bone rigid parts, and then re-compose paired geometry encodings to derive an across-part consistent occupancy field. As for texture modeling, we propose a self-occlusion-aware shading field (SelF). In SelF, drivable anchors are paved on the MANO-HD surface to record albedo information under a wide variety of hand poses. Moreover, directed soft occupancy is designed to describe the ray-to-surface relation, which is leveraged to generate an illumination field for the disentanglement of pose-independent albedo and pose-dependent illumination. Trained from monocular video data, our HandAvatar can perform free-pose hand animation and rendering while at the same time achieving superior appearance fidelity. We also demonstrate that HandAvatar provides a route for hand appearance editing. Project website: https://seanchenxy.github.io/HandAvatarWeb.