 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Pose-disentangled Contrastive Learning for Self-supervised Facial Representation
Nov 24, 2022
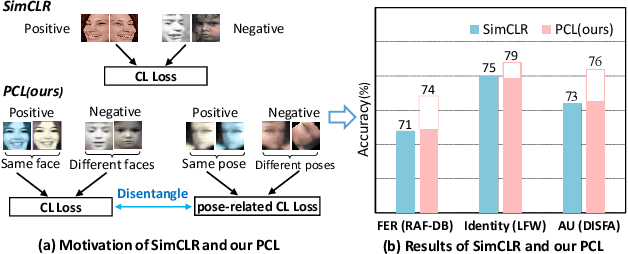
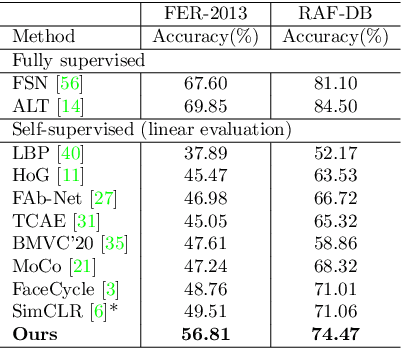
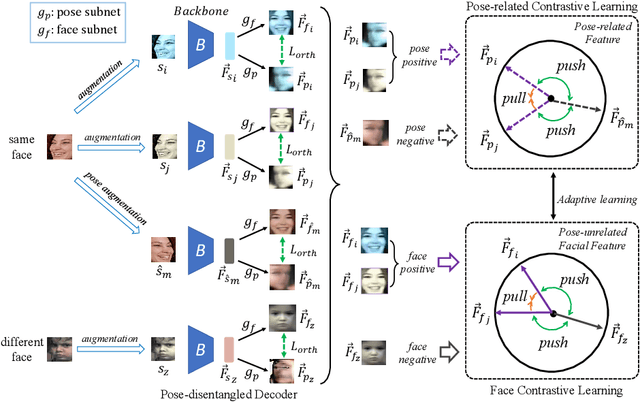
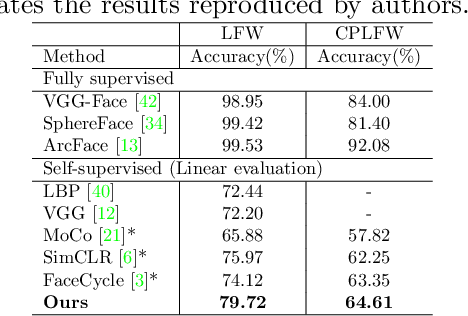
Self-supervised facial representation has recently attracted increasing attention due to its ability to perform face understanding without relying on large-scale annotated datasets heavily. However, analytically, current contrastive-based self-supervised learning still performs unsatisfactorily for learning facial representation. More specifically, existing contrastive learning (CL) tends to learn pose-invariant features that cannot depict the pose details of faces, compromising the learning performance. To conquer the above limitation of CL, we propose a novel Pose-disentangled Contrastive Learning (PCL) method for general self-supervised facial representation. Our PCL first devises a pose-disentangled decoder (PDD) with a delicately designed orthogonalizing regulation, which disentangles the pose-related features from the face-aware features; therefore, pose-related and other pose-unrelated facial information could be performed in individual subnetworks and do not affect each other's training. Furthermore, we introduce a pose-related contrastive learning scheme that learns pose-related information based on data augmentation of the same image, which would deliver more effective face-aware representation for various downstream tasks. We conducted a comprehensive linear evaluation on three challenging downstream facial understanding tasks, i.e., facial expression recognition, face recognition, and AU detection. Experimental results demonstrate that our method outperforms cutting-edge contrastive and other self-supervised learning methods with a great margin.
Information Theory with Kernel Methods
Feb 17, 2022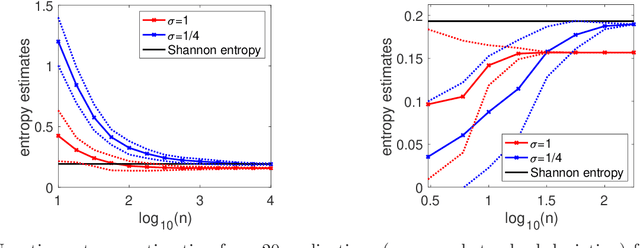
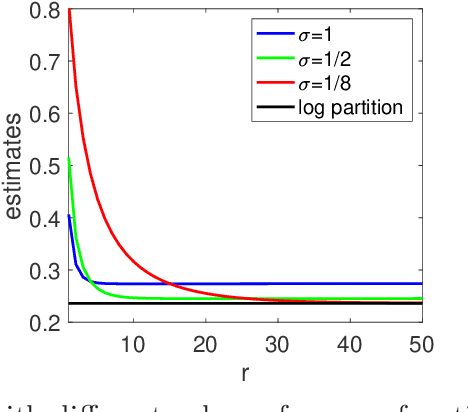
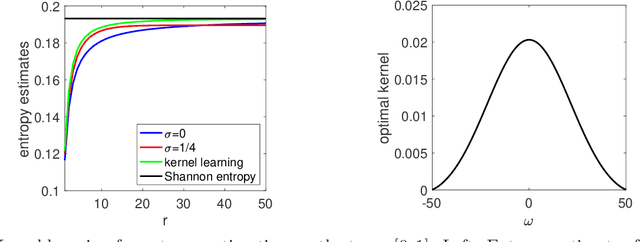
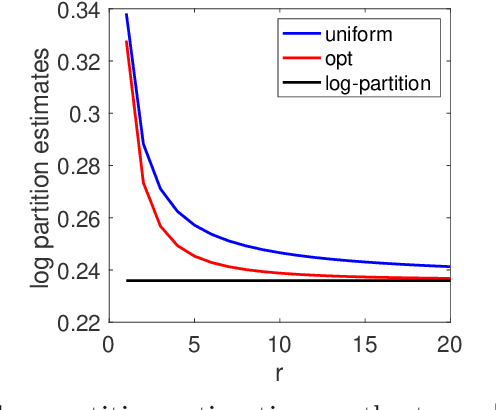
We consider the analysis of probability distributions through their associated covariance operators from reproducing kernel Hilbert spaces. We show that the von Neumann entropy and relative entropy of these operators are intimately related to the usual notions of Shannon entropy and relative entropy, and share many of their properties. They come together with efficient estimation algorithms from various oracles on the probability distributions. We also consider product spaces and show that for tensor product kernels, we can define notions of mutual information and joint entropies, which can then characterize independence perfectly, but only partially conditional independence. We finally show how these new notions of relative entropy lead to new upper-bounds on log partition functions, that can be used together with convex optimization within variational inference methods, providing a new family of probabilistic inference methods.
CLIPVG: Text-Guided Image Manipulation Using Differentiable Vector Graphics
Dec 05, 2022
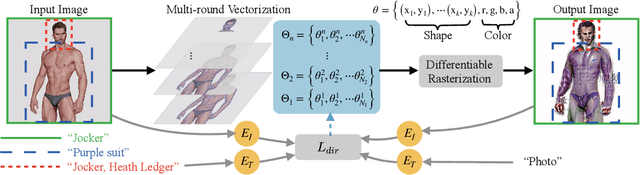

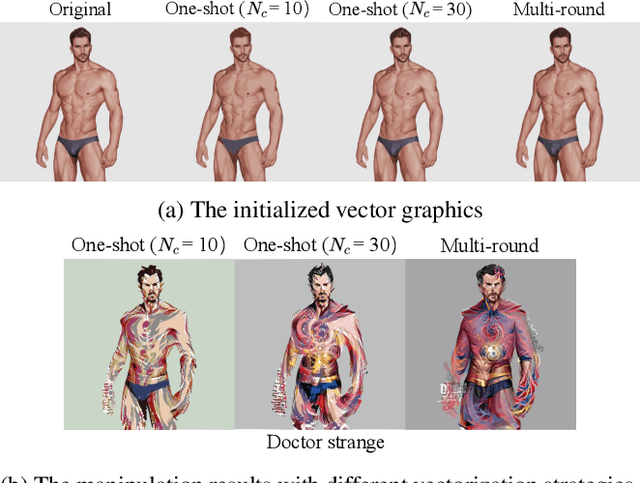
Considerable progress has recently been made in leveraging CLIP (Contrastive Language-Image Pre-Training) models for text-guided image manipulation. However, all existing works rely on additional generative models to ensure the quality of results, because CLIP alone cannot provide enough guidance information for fine-scale pixel-level changes. In this paper, we introduce CLIPVG, a text-guided image manipulation framework using differentiable vector graphics, which is also the first CLIP-based general image manipulation framework that does not require any additional generative models. We demonstrate that CLIPVG can not only achieve state-of-art performance in both semantic correctness and synthesis quality, but also is flexible enough to support various applications far beyond the capability of all existing methods.
An operational framework to automatically evaluate the quality of weather observations from third-party stations
Dec 05, 2022
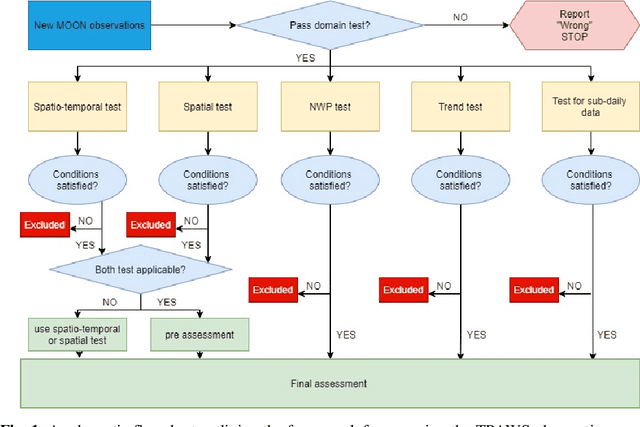

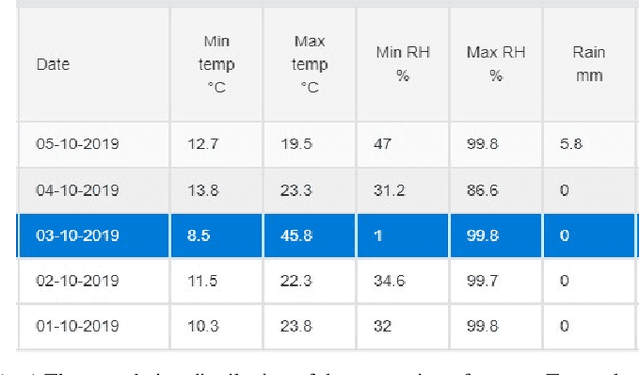
With increasing number of crowdsourced private automatic weather stations (called TPAWS) established to fill the gap of official network and obtain local weather information for various purposes, the data quality is a major concern in promoting their usage. Proper quality control and assessment are necessary to reach mutual agreement on the TPAWS observations. To derive near real-time assessment for operational system, we propose a simple, scalable and interpretable framework based on AI/Stats/ML models. The framework constructs separate models for individual data from official sources and then provides the final assessment by fusing the individual models. The performance of our proposed framework is evaluated by synthetic data and demonstrated by applying it to a re-al TPAWS network.
Fourier Disentangled Multimodal Prior Knowledge Fusion for Red Nucleus Segmentation in Brain MRI
Nov 02, 2022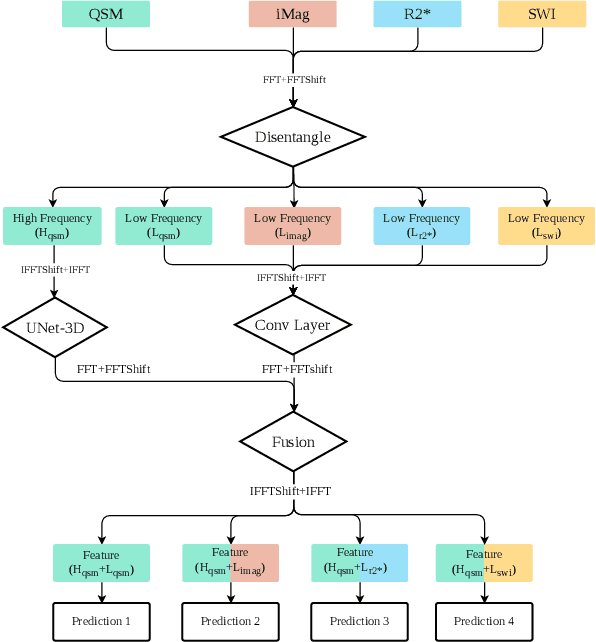
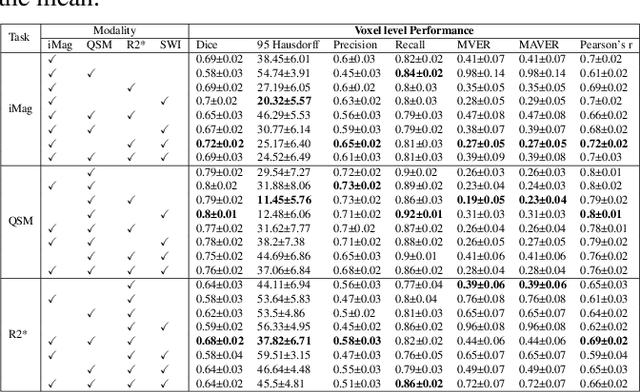

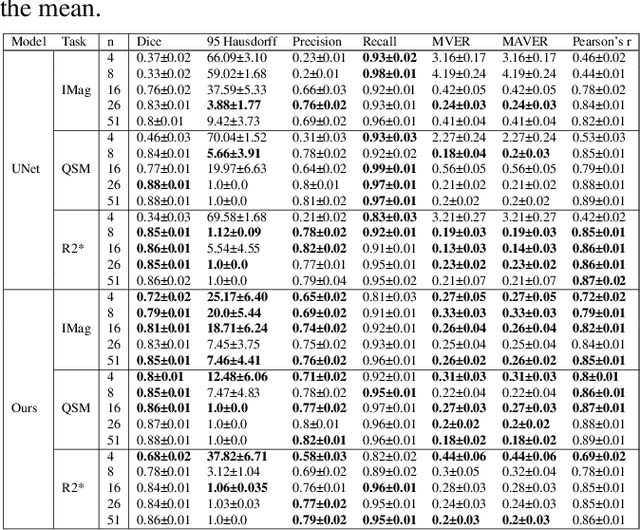
Early and accurate diagnosis of parkinsonian syndromes is critical to provide appropriate care to patients and for inclusion in therapeutic trials. The red nucleus is a structure of the midbrain that plays an important role in these disorders. It can be visualized using iron-sensitive magnetic resonance imaging (MRI) sequences. Different iron-sensitive contrasts can be produced with MRI. Combining such multimodal data has the potential to improve segmentation of the red nucleus. Current multimodal segmentation algorithms are computationally consuming, cannot deal with missing modalities and need annotations for all modalities. In this paper, we propose a new model that integrates prior knowledge from different contrasts for red nucleus segmentation. The method consists of three main stages. First, it disentangles the image into high-level information representing the brain structure, and low-frequency information representing the contrast. The high-frequency information is then fed into a network to learn anatomical features, while the list of multimodal low-frequency information is processed by another module. Finally, feature fusion is performed to complete the segmentation task. The proposed method was used with several iron-sensitive contrasts (iMag, QSM, R2*, SWI). Experiments demonstrate that our proposed model substantially outperforms a baseline UNet model when the training set size is very small.
Shining light on data: Geometric data analysis through quantum dynamics
Dec 13, 2022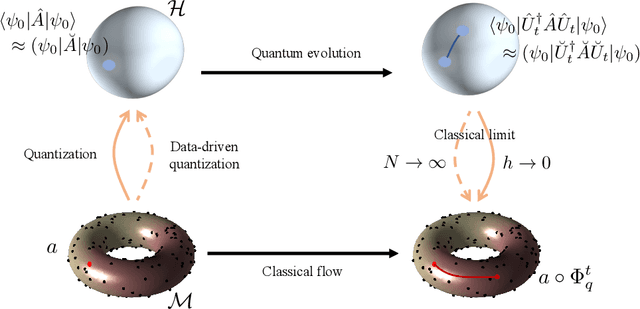
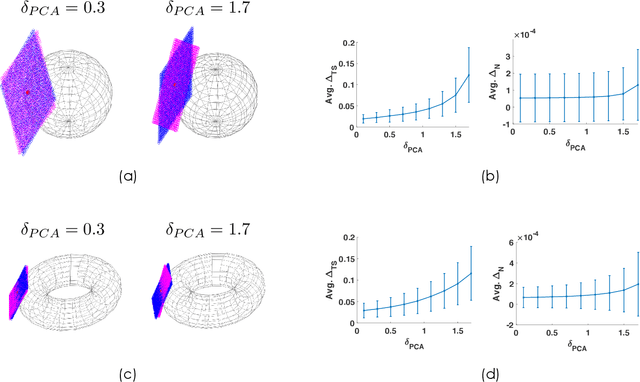
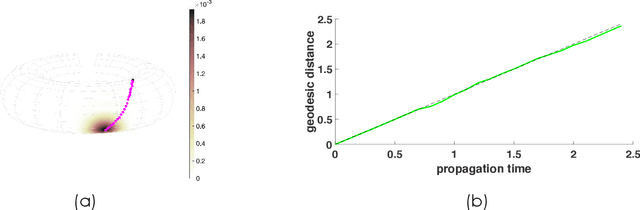
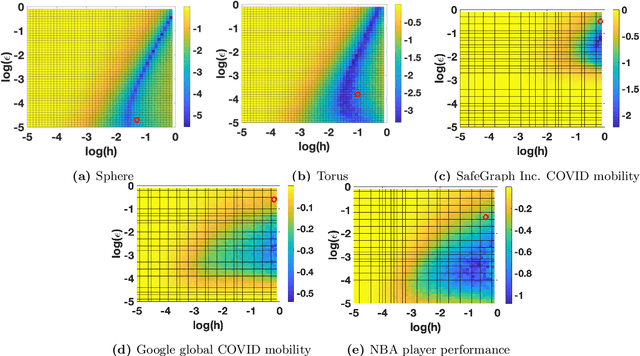
Experimental sciences have come to depend heavily on our ability to organize and interpret high-dimensional datasets. Natural laws, conservation principles, and inter-dependencies among observed variables yield geometric structure, with fewer degrees of freedom, on the dataset. We introduce the frameworks of semiclassical and microlocal analysis to data analysis and develop a novel, yet natural uncertainty principle for extracting fine-scale features of this geometric structure in data, crucially dependent on data-driven approximations to quantum mechanical processes underlying geometric optics. This leads to the first tractable algorithm for approximation of wave dynamics and geodesics on data manifolds with rigorous probabilistic convergence rates under the manifold hypothesis. We demonstrate our algorithm on real-world datasets, including an analysis of population mobility information during the COVID-19 pandemic to achieve four-fold improvement in dimensionality reduction over existing state-of-the-art and reveal anomalous behavior exhibited by less than 1.2% of the entire dataset. Our work initiates the study of data-driven quantum dynamics for analyzing datasets, and we outline several future directions for research.
Visual Analytics for Early Detection of Retinal Diseases
Dec 13, 2022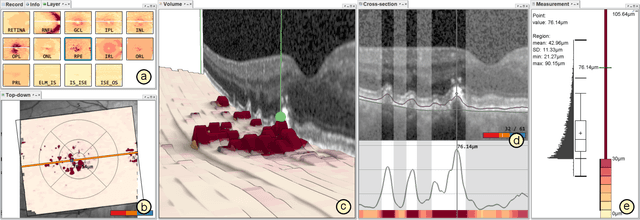
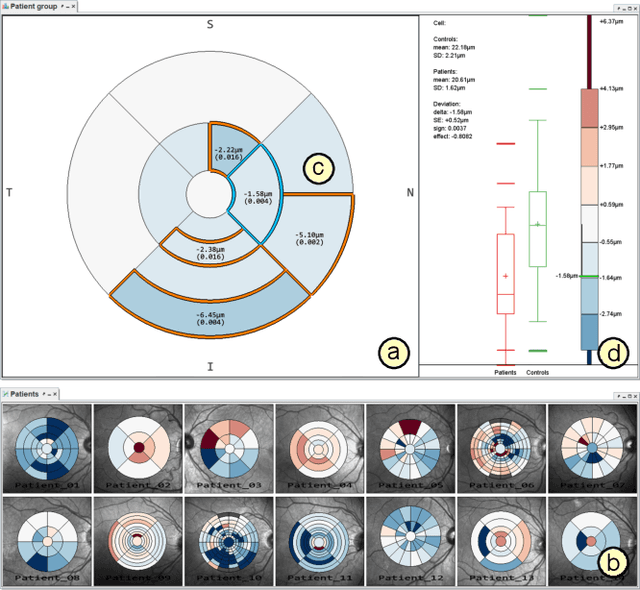
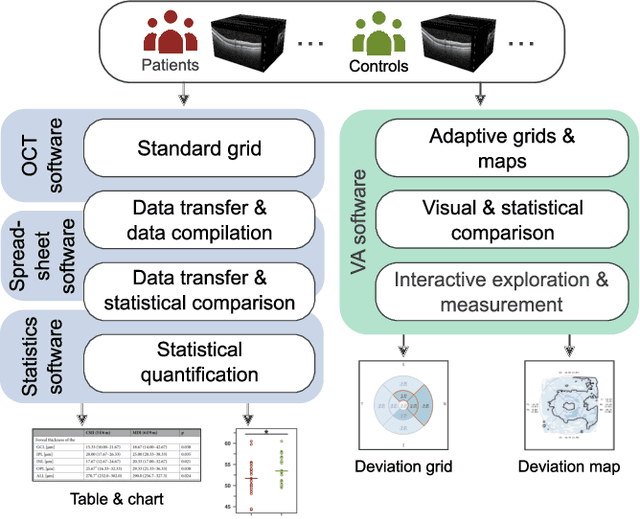
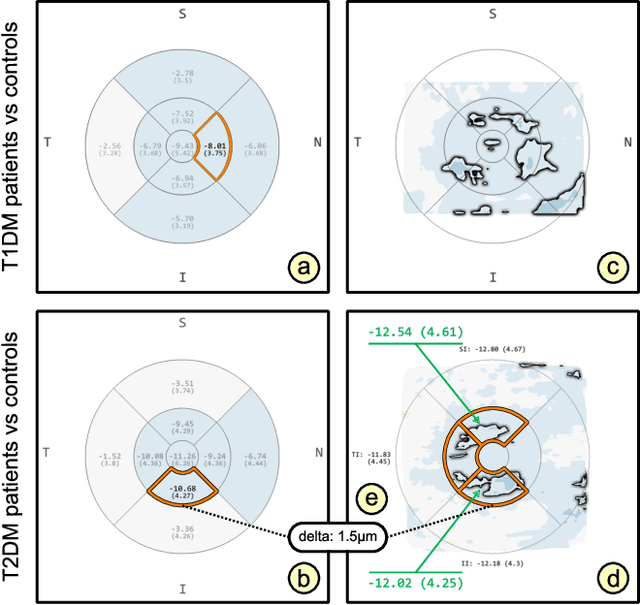
Advances in optical coherence tomography (OCT) have enabled noninvasive imaging of substructures of the human retina with high spatial resolution. OCT examinations are now a standard procedure in clinics and an integral part of ophthalmic research. The interpretation of the OCT helps ophthalmologists understand the impact of various retinal and systemic diseases on the structure of the retina in a way not previously possible. In the early stages of retinal diseases, however, the identification and analysis of small and localized substructural changes in the retina remains a challenge. We present an overview of novel visual analytics approaches for the interactive exploration of early retinal changes in single and multiple patients, the comparison of the changes with normative data, and automated quantification and measurement of diagnosis-relevant information. We developed these approaches in close collaboration with ophthalmology researchers and industry experts from a leading OCT device manufacturer. As a result, they not only significantly reduced the time and effort required for OCT data analysis, especially in the context of cross-sectional studies, but have also led to several new discoveries published in biomedical journals.
A Robust Data-Driven Fault Diagnosis scheme based on Recursive Dempster-Shafer Combination Rule *
Dec 13, 2022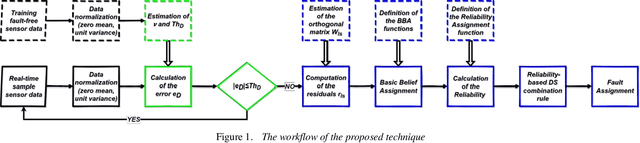
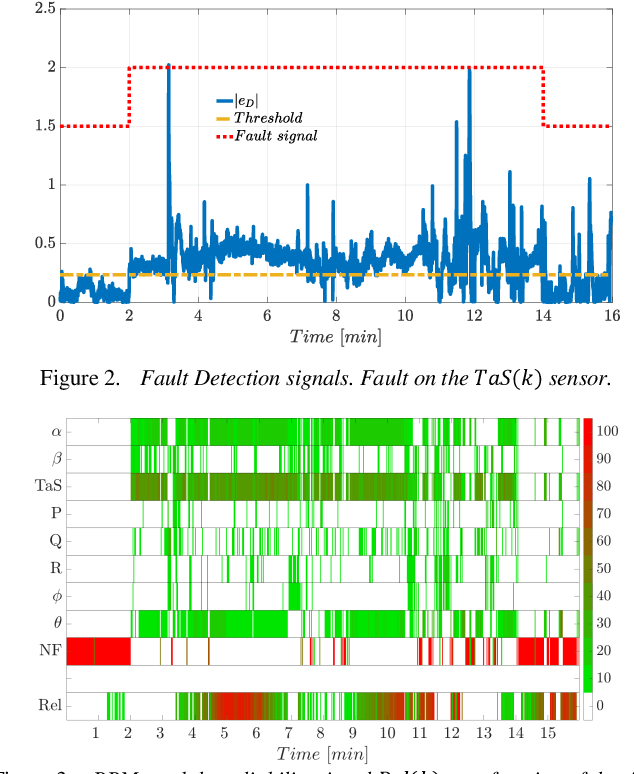
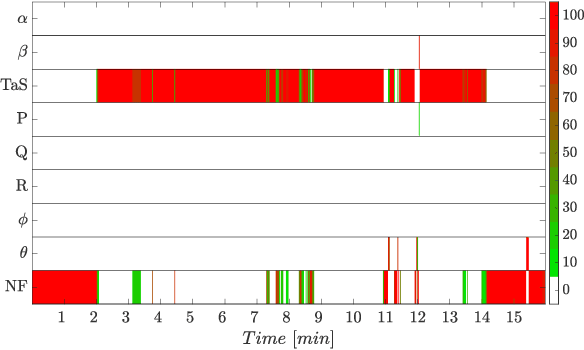
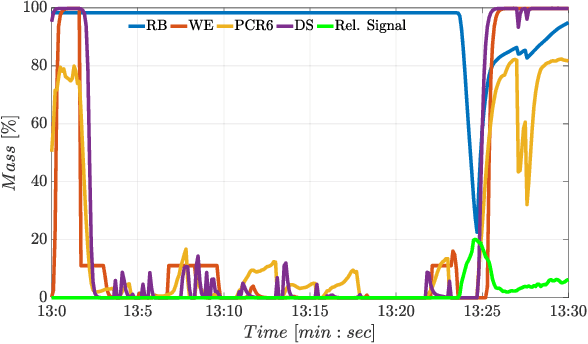
In-flight sensor fault diagnosis and recursive combination of residual signals via the Dempster-Shafer (DS) theory have been considered in this study. In particular, a novel evidence-based combination rule of residual errors as a function of a reliability measure derived from streaming data is proposed for the purpose of online robust sensors fault diagnosis. The proposed information fusion mechanism is divided into three steps. In the first step, the classic DS probability mass combination rule is applied; then, the difference between the previous posterior mass and the current prior mass associated with fault events is computed. Finally, the increment of the posterior mass of a fault event is weighted as a function of a reliability coefficient that depends on the norm of control activity. A Sensor Fault Isolation scheme based on the proposed combination rule has been worked out and compared with well-known state-of-the-art recursive combination rules. A quantitative analysis has been performed exploiting multi-flight data of a P92 Tecnam aircraft. The proposed approach showed to be effective, particularly in reducing the false alarms rate.
Domain Adaptation for Dense Retrieval through Self-Supervision by Pseudo-Relevance Labeling
Dec 13, 2022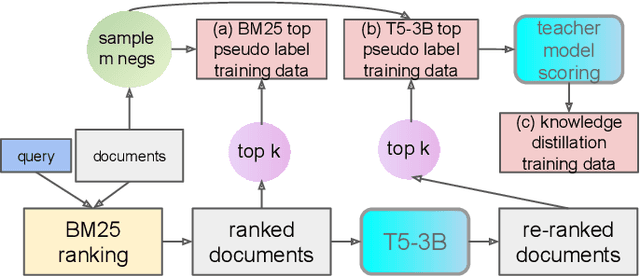
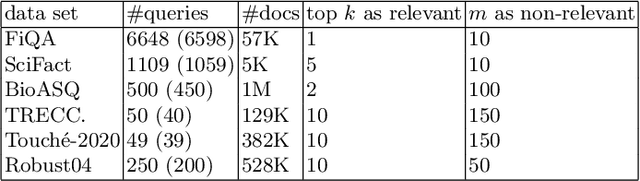
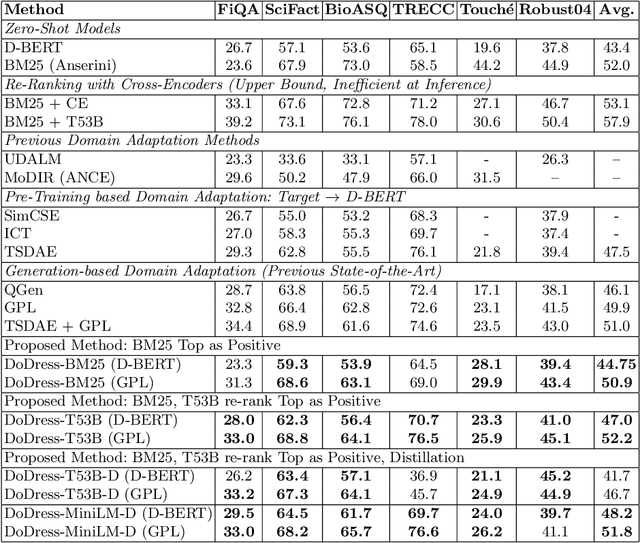
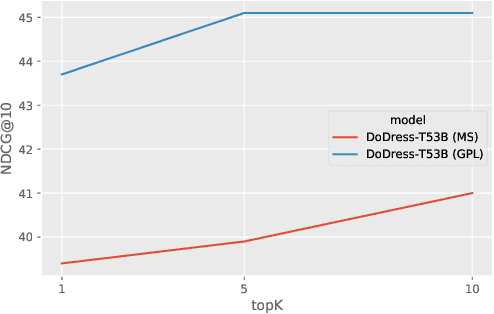
Although neural information retrieval has witnessed great improvements, recent works showed that the generalization ability of dense retrieval models on target domains with different distributions is limited, which contrasts with the results obtained with interaction-based models. To address this issue, researchers have resorted to adversarial learning and query generation approaches; both approaches nevertheless resulted in limited improvements. In this paper, we propose to use a self-supervision approach in which pseudo-relevance labels are automatically generated on the target domain. To do so, we first use the standard BM25 model on the target domain to obtain a first ranking of documents, and then use the interaction-based model T53B to re-rank top documents. We further combine this approach with knowledge distillation relying on an interaction-based teacher model trained on the source domain. Our experiments reveal that pseudo-relevance labeling using T53B and the MiniLM teacher performs on average better than other approaches and helps improve the state-of-the-art query generation approach GPL when it is fine-tuned on the pseudo-relevance labeled data.
SST: Real-time End-to-end Monocular 3D Reconstruction via Sparse Spatial-Temporal Guidance
Dec 13, 2022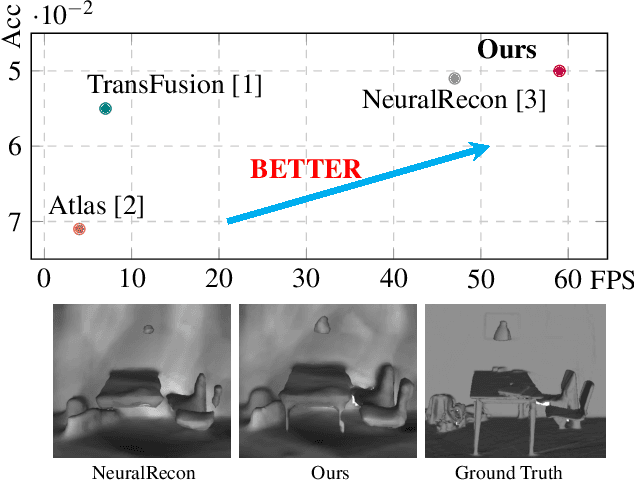
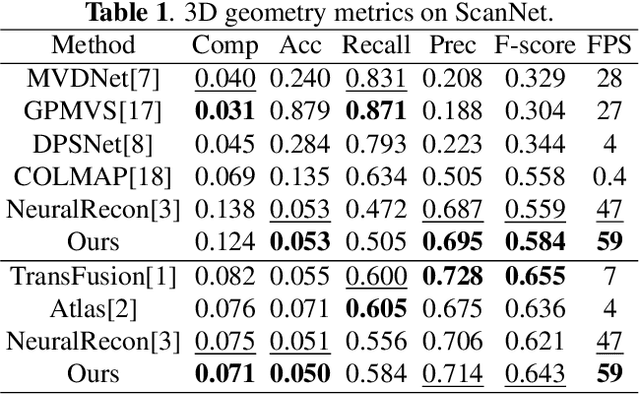
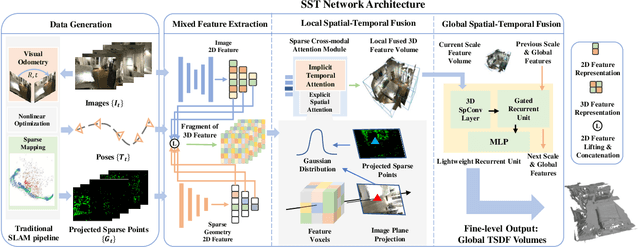
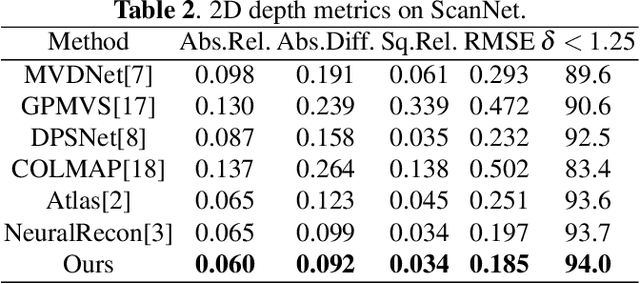
Real-time monocular 3D reconstruction is a challenging problem that remains unsolved. Although recent end-to-end methods have demonstrated promising results, tiny structures and geometric boundaries are hardly captured due to their insufficient supervision neglecting spatial details and oversimplified feature fusion ignoring temporal cues. To address the problems, we propose an end-to-end 3D reconstruction network SST, which utilizes Sparse estimated points from visual SLAM system as additional Spatial guidance and fuses Temporal features via a novel cross-modal attention mechanism, achieving more detailed reconstruction results. We propose a Local Spatial-Temporal Fusion module to exploit more informative spatial-temporal cues from multi-view color information and sparse priors, as well a Global Spatial-Temporal Fusion module to refine the local TSDF volumes with the world-frame model from coarse to fine. Extensive experiments on ScanNet and 7-Scenes demonstrate that SST outperforms all state-of-the-art competitors, whilst keeping a high inference speed at 59 FPS, enabling real-world applications with real-time requirements.