 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetection of Animal Movement from Weather Radar using Self-Supervised Learning
Aug 08, 2024



Detecting flying animals (e.g., birds, bats, and insects) using weather radar helps gain insights into animal movement and migration patterns, aids in management efforts (such as biosecurity) and enhances our understanding of the ecosystem.The conventional approach to detecting animals in weather radar involves thresholding: defining and applying thresholds for the radar variables, based on expert opinion. More recently, Deep Learning approaches have been shown to provide improved performance in detection. However, obtaining sufficient labelled weather radar data for flying animals to build learning-based models is time-consuming and labor-intensive. To address the challenge of data labelling, we propose a self-supervised learning method for detecting animal movement. In our proposed method, we pre-train our model on a large dataset with noisy labels produced by a threshold approach. The key advantage is that the pre-trained dataset size is limited only by the number of radar images available. We then fine-tune the model on a small human-labelled dataset. Our experiments on Australian weather radar data for waterbird segmentation show that the proposed method outperforms the current state-of-the art approach by 43.53% in the dice co-efficient statistic.
PINN-Ray: A Physics-Informed Neural Network to Model Soft Robotic Fin Ray Fingers
Jul 11, 2024



Modelling complex deformation for soft robotics provides a guideline to understand their behaviour, leading to safe interaction with the environment. However, building a surrogate model with high accuracy and fast inference speed can be challenging for soft robotics due to the nonlinearity from complex geometry, large deformation, material nonlinearity etc. The reality gap from surrogate models also prevents their further deployment in the soft robotics domain. In this study, we proposed a physics-informed Neural Networks (PINNs) named PINN-Ray to model complex deformation for a Fin Ray soft robotic gripper, which embeds the minimum potential energy principle from elastic mechanics and additional high-fidelity experimental data into the loss function of neural network for training. This method is significant in terms of its generalisation to complex geometry and robust to data scarcity as compared to other data-driven neural networks. Furthermore, it has been extensively evaluated to model the deformation of the Fin Ray finger under external actuation. PINN-Ray demonstrates improved accuracy as compared with Finite element modelling (FEM) after applying the data assimilation scheme to treat the sim-to-real gap. Additionally, we introduced our automated framework to design, fabricate soft robotic fingers, and characterise their deformation by visual tracking, which provides a guideline for the fast prototype of soft robotics.
A Neural Emulator for Uncertainty Estimation of Fire Propagation
May 15, 2023



Wildfire propagation is a highly stochastic process where small changes in environmental conditions (such as wind speed and direction) can lead to large changes in observed behaviour. A traditional approach to quantify uncertainty in fire-front progression is to generate probability maps via ensembles of simulations. However, use of ensembles is typically computationally expensive, which can limit the scope of uncertainty analysis. To address this, we explore the use of a spatio-temporal neural-based modelling approach to directly estimate the likelihood of fire propagation given uncertainty in input parameters. The uncertainty is represented by deliberately perturbing the input weather forecast during model training. The computational load is concentrated in the model training process, which allows larger probability spaces to be explored during deployment. Empirical evaluations indicate that the proposed model achieves comparable fire boundaries to those produced by the traditional SPARK simulation platform, with an overall Jaccard index (similarity score) of 67.4% on a set of 35 simulated fires. When compared to a related neural model (emulator) which was employed to generate probability maps via ensembles of emulated fires, the proposed approach produces competitive Jaccard similarity scores while being approximately an order of magnitude faster.
Fruit Picker Activity Recognition with Wearable Sensors and Machine Learning
Apr 20, 2023



In this paper we present a novel application of detecting fruit picker activities based on time series data generated from wearable sensors. During harvesting, fruit pickers pick fruit into wearable bags and empty these bags into harvesting bins located in the orchard. Once full, these bins are quickly transported to a cooled pack house to improve the shelf life of picked fruits. For farmers and managers, the knowledge of when a picker bag is emptied is important for managing harvesting bins more effectively to minimise the time the picked fruit is left out in the heat (resulting in reduced shelf life). We propose a means to detect these bag-emptying events using human activity recognition with wearable sensors and machine learning methods. We develop a semi-supervised approach to labelling the data. A feature-based machine learning ensemble model and a deep recurrent convolutional neural network are developed and tested on a real-world dataset. When compared, the neural network achieves 86% detection accuracy.
An operational framework to automatically evaluate the quality of weather observations from third-party stations
Dec 05, 2022



With increasing number of crowdsourced private automatic weather stations (called TPAWS) established to fill the gap of official network and obtain local weather information for various purposes, the data quality is a major concern in promoting their usage. Proper quality control and assessment are necessary to reach mutual agreement on the TPAWS observations. To derive near real-time assessment for operational system, we propose a simple, scalable and interpretable framework based on AI/Stats/ML models. The framework constructs separate models for individual data from official sources and then provides the final assessment by fusing the individual models. The performance of our proposed framework is evaluated by synthetic data and demonstrated by applying it to a re-al TPAWS network.
Bayesian Physics Informed Neural Networks for Data Assimilation and Spatio-Temporal Modelling of Wildfires
Dec 02, 2022We apply Physics Informed Neural Networks (PINNs) to the problem of wildfire fire-front modelling. The PINN is an approach that integrates a differential equation into the optimisation loss function of a neural network to guide the neural network to learn the physics of a problem. We apply the PINN to the level-set equation, which is a Hamilton-Jacobi partial differential equation that models a fire-front with the zero-level set. This results in a PINN that simulates a fire-front as it propagates through a spatio-temporal domain. We demonstrate the agility of the PINN to learn physical properties of a fire under extreme changes in external conditions (such as wind) and show that this approach encourages continuity of the PINN's solution across time. Furthermore, we demonstrate how data assimilation and uncertainty quantification can be incorporated into the PINN in the wildfire context. This is significant contribution to wildfire modelling as the level-set method -- which is a standard solver to the level-set equation -- does not naturally provide this capability.
Bayesian Neural Network Inference via Implicit Models and the Posterior Predictive Distribution
Sep 06, 2022

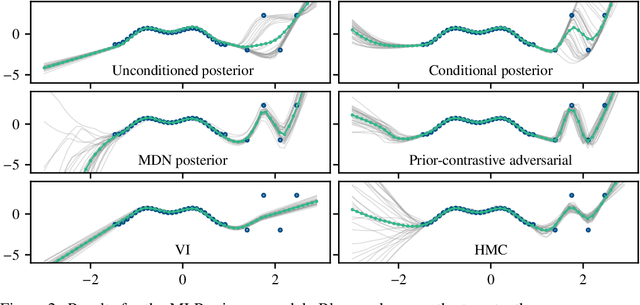

We propose a novel approach to perform approximate Bayesian inference in complex models such as Bayesian neural networks. The approach is more scalable to large data than Markov Chain Monte Carlo, it embraces more expressive models than Variational Inference, and it does not rely on adversarial training (or density ratio estimation). We adopt the recent approach of constructing two models: (1) a primary model, tasked with performing regression or classification; and (2) a secondary, expressive (e.g. implicit) model that defines an approximate posterior distribution over the parameters of the primary model. However, we optimise the parameters of the posterior model via gradient descent according to a Monte Carlo estimate of the posterior predictive distribution -- which is our only approximation (other than the posterior model). Only a likelihood needs to be specified, which can take various forms such as loss functions and synthetic likelihoods, thus providing a form of a likelihood-free approach. Furthermore, we formulate the approach such that the posterior samples can either be independent of, or conditionally dependent upon the inputs to the primary model. The latter approach is shown to be capable of increasing the apparent complexity of the primary model. We see this being useful in applications such as surrogate and physics-based models. To promote how the Bayesian paradigm offers more than just uncertainty quantification, we demonstrate: uncertainty quantification, multi-modality, as well as an application with a recent deep forecasting neural network architecture.
A Spatio-Temporal Neural Network Forecasting Approach for Emulation of Firefront Models
Jun 22, 2022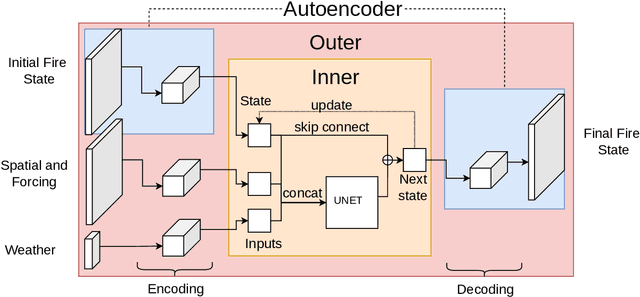
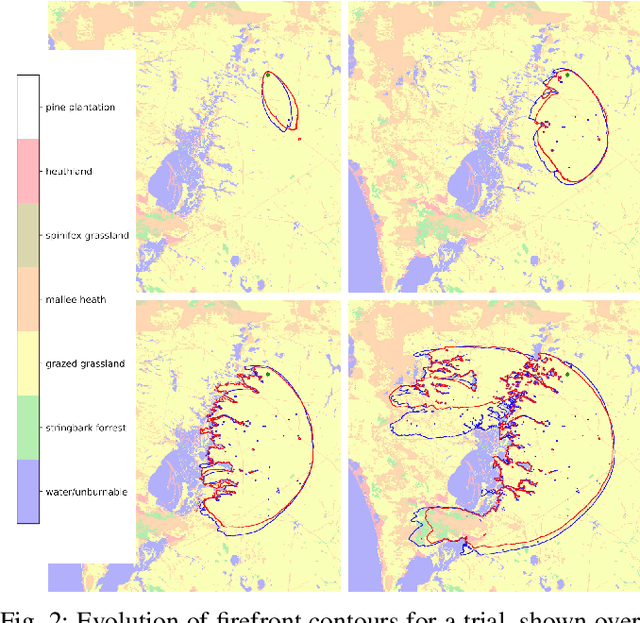
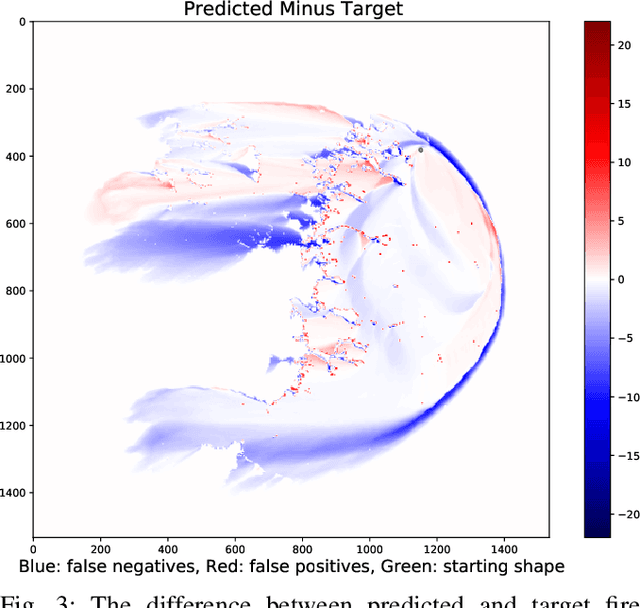
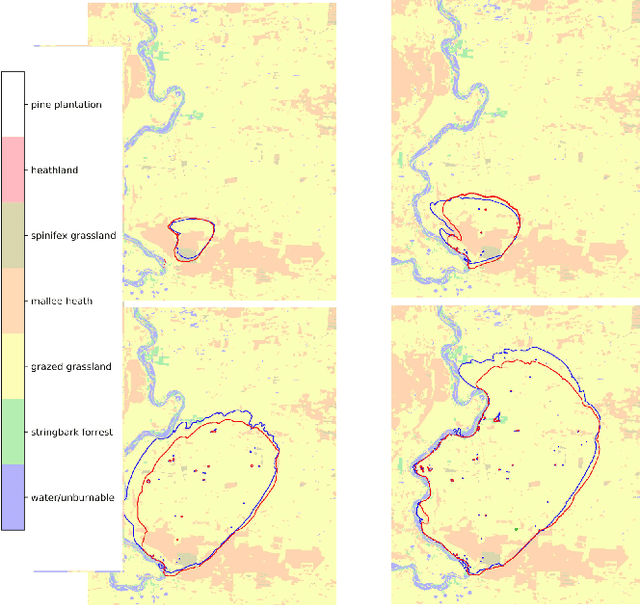
Computational simulations of wildfire spread typically employ empirical rate-of-spread calculations under various conditions (such as terrain, fuel type, weather). Small perturbations in conditions can often lead to significant changes in fire spread (such as speed and direction), necessitating a computationally expensive large set of simulations to quantify uncertainty. Model emulation seeks alternative representations of physical models using machine learning, aiming to provide more efficient and/or simplified surrogate models. We propose a dedicated spatio-temporal neural network based framework for model emulation, able to capture the complex behaviour of fire spread models. The proposed approach can approximate forecasts at fine spatial and temporal resolutions that are often challenging for neural network based approaches. Furthermore, the proposed approach is robust even with small training sets, due to novel data augmentation methods. Empirical experiments show good agreement between simulated and emulated firefronts, with an average Jaccard score of 0.76.
Deep Learning for Prawn Farming: Forecasting and Anomaly Detection
May 12, 2022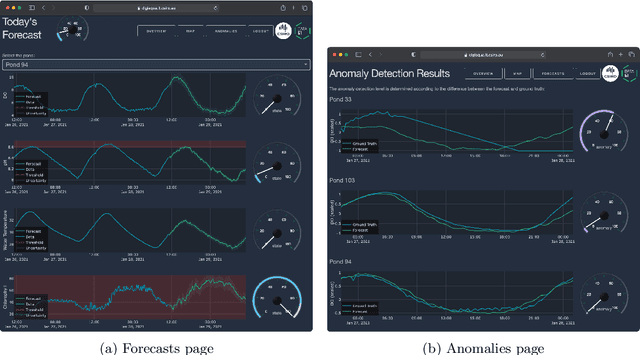

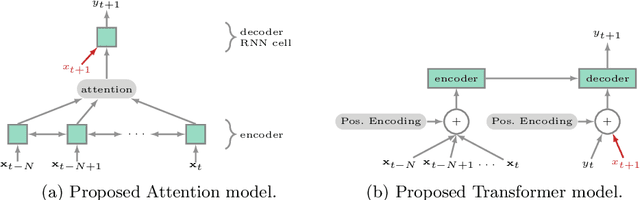
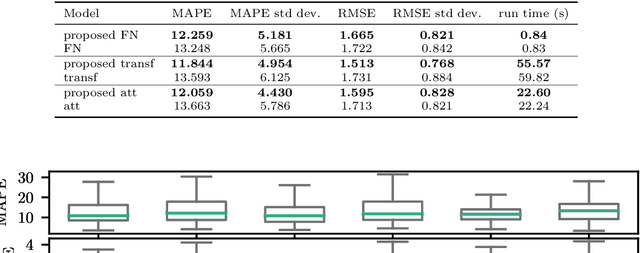
We present a decision support system for managing water quality in prawn ponds. The system uses various sources of data and deep learning models in a novel way to provide 24-hour forecasting and anomaly detection of water quality parameters. It provides prawn farmers with tools to proactively avoid a poor growing environment, thereby optimising growth and reducing the risk of losing stock. This is a major shift for farmers who are forced to manage ponds by reactively correcting poor water quality conditions. To our knowledge, we are the first to apply Transformer as an anomaly detection model, and the first to apply anomaly detection in general to this aquaculture problem. Our technical contributions include adapting ForecastNet for multivariate data and adapting Transformer and the Attention model to incorporate weather forecast data into their decoders. We attain an average mean absolute percentage error of 12% for dissolved oxygen forecasts and we demonstrate two anomaly detection case studies. The system is successfully running in its second year of deployment on a commercial prawn farm.
An Emulation Framework for Fire Front Spread
Mar 23, 2022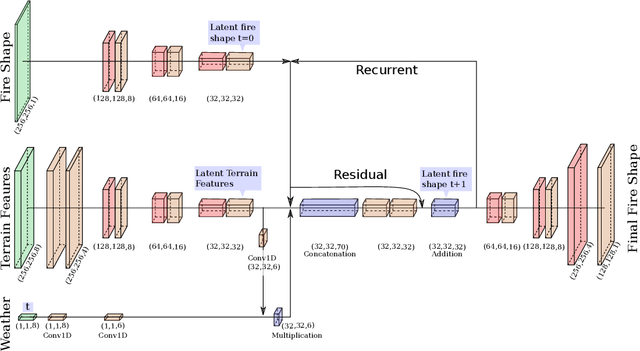
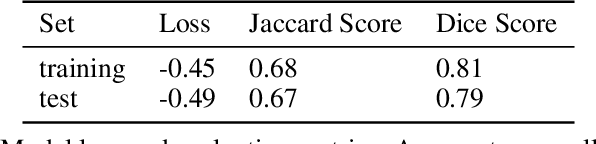
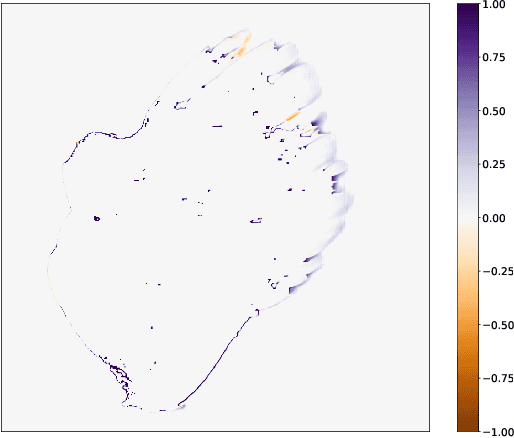
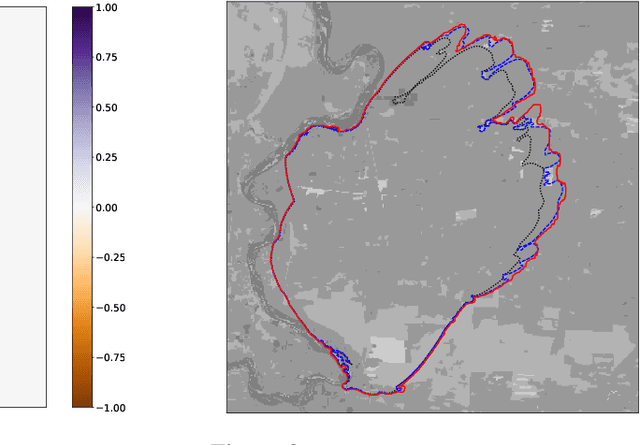
Forecasting bushfire spread is an important element in fire prevention and response efforts. Empirical observations of bushfire spread can be used to estimate fire response under certain conditions. These observations form rate-of-spread models, which can be used to generate simulations. We use machine learning to drive the emulation approach for bushfires and show that emulation has the capacity to closely reproduce simulated fire-front data. We present a preliminary emulator approach with the capacity for fast emulation of complex simulations. Large numbers of predictions can then be generated as part of ensemble estimation techniques, which provide more robust and reliable forecasts of stochastic systems.