 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
PointCA: Evaluating the Robustness of 3D Point Cloud Completion Models Against Adversarial Examples
Dec 01, 2022
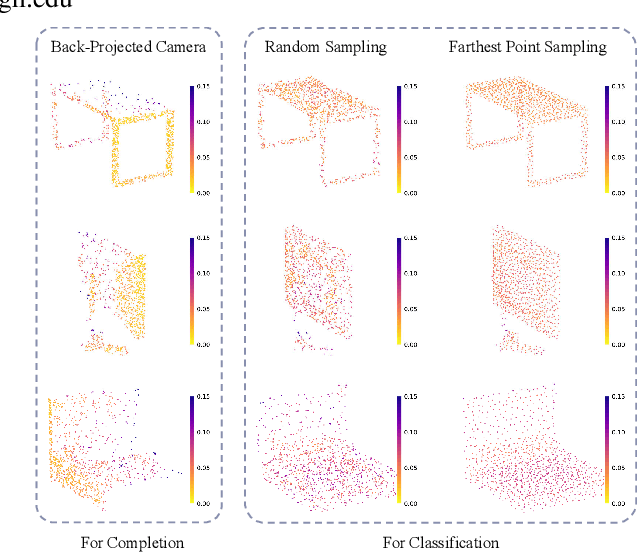
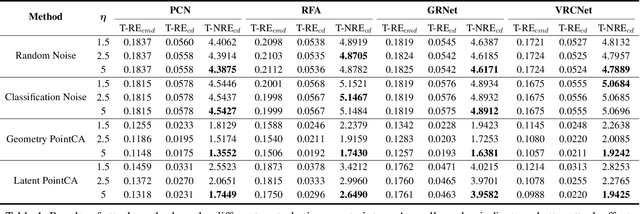


Point cloud completion, as the upstream procedure of 3D recognition and segmentation, has become an essential part of many tasks such as navigation and scene understanding. While various point cloud completion models have demonstrated their powerful capabilities, their robustness against adversarial attacks, which have been proven to be fatally malicious towards deep neural networks, remains unknown. In addition, existing attack approaches towards point cloud classifiers cannot be applied to the completion models due to different output forms and attack purposes. In order to evaluate the robustness of the completion models, we propose PointCA, the first adversarial attack against 3D point cloud completion models. PointCA can generate adversarial point clouds that maintain high similarity with the original ones, while being completed as another object with totally different semantic information. Specifically, we minimize the representation discrepancy between the adversarial example and the target point set to jointly explore the adversarial point clouds in the geometry space and the feature space. Furthermore, to launch a stealthier attack, we innovatively employ the neighbourhood density information to tailor the perturbation constraint, leading to geometry-aware and distribution-adaptive modifications for each point. Extensive experiments against different premier point cloud completion networks show that PointCA can cause a performance degradation from 77.9% to 16.7%, with the structure chamfer distance kept below 0.01. We conclude that existing completion models are severely vulnerable to adversarial examples, and state-of-the-art defenses for point cloud classification will be partially invalid when applied to incomplete and uneven point cloud data.
Uniform Passive Fault-Tolerant Control of a Quadcopter with One, Two, or Three Rotor Failure
Nov 23, 2022
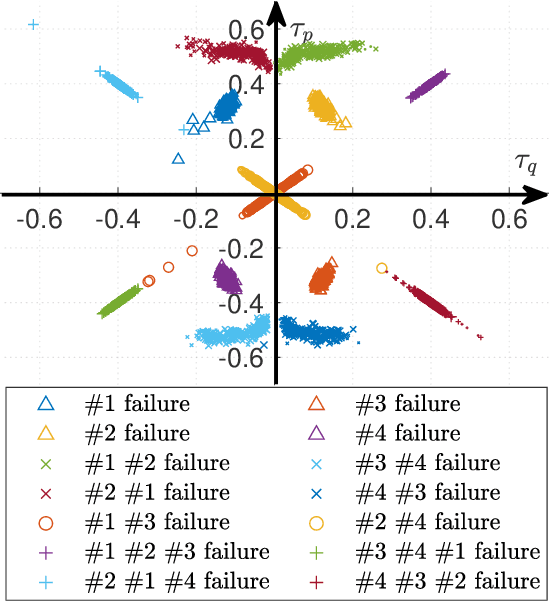
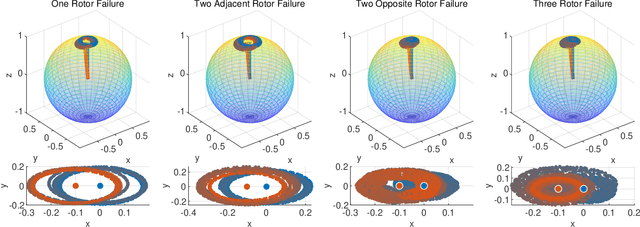
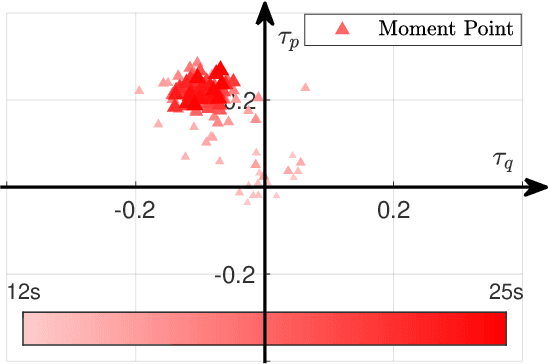
This study proposes a uniform passive fault-tolerant control (FTC) method for a quadcopter that does not rely on fault information subject to one, two adjacent, two opposite, or three rotors failure. The uniform control implies that the passive FTC is able to cover the condition from quadcopter fault-free to rotor failure without controller switching. To achieve the purpose of the passive FTC, the rotors' fault is modeled as a disturbance acting on the virtual control of the quadcopter system. The disturbance estimate is used directly for the passive FTC with rotor failure. To avoid controller switching between normal control and FTC, a dynamic control allocation is used. In addition, the closed-loop stability has been analyzed and a virtual control feedback is adopted to achieve the passive FTC for the quadcopter with two and three rotor failure. To validate the proposed uniform passive FTC method, outdoor experiments are performed for the first time, which have demonstrated that the hovering quadcopter is able to recover from one rotor failure by the proposed controller and continue to fly even if two adjacent, two opposite, or three rotors fail, without any rotor fault information and controller switching.
Discovering Influencers in Opinion Formation over Social Graphs
Nov 23, 2022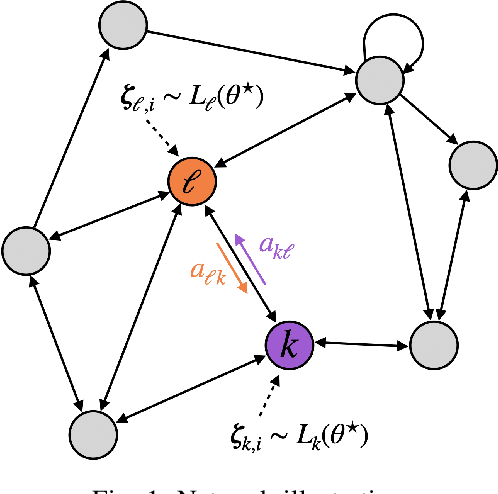
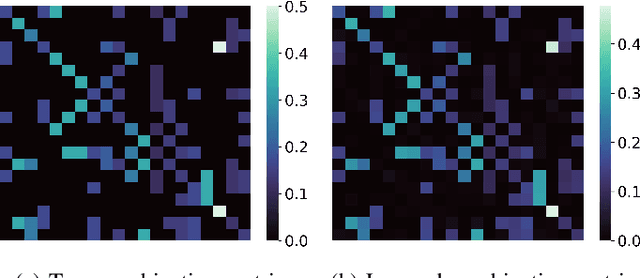
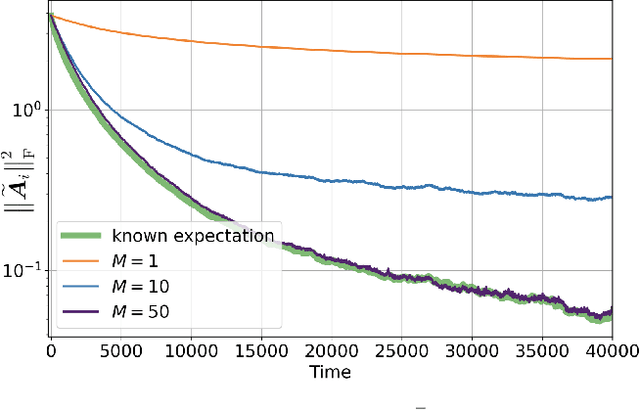
The adaptive social learning paradigm helps model how networked agents are able to form opinions on a state of nature and track its drifts in a changing environment. In this framework, the agents repeatedly update their beliefs based on private observations and exchange the beliefs with their neighbors. In this work, it is shown how the sequence of publicly exchanged beliefs over time allows users to discover rich information about the underlying network topology and about the flow of information over graph. In particular, it is shown that it is possible (i) to identify the influence of each individual agent to the objective of truth learning, (ii) to discover how well informed each agent is, (iii) to quantify the pairwise influences between agents, and (iv) to learn the underlying network topology. The algorithm derived herein is also able to work under non-stationary environments where either the true state of nature or the network topology are allowed to drift over time. We apply the proposed algorithm to different subnetworks of Twitter users, and identify the most influential and central agents merely by using their public tweets (posts).
Incentive-Aware Recommender Systems in Two-Sided Markets
Nov 23, 2022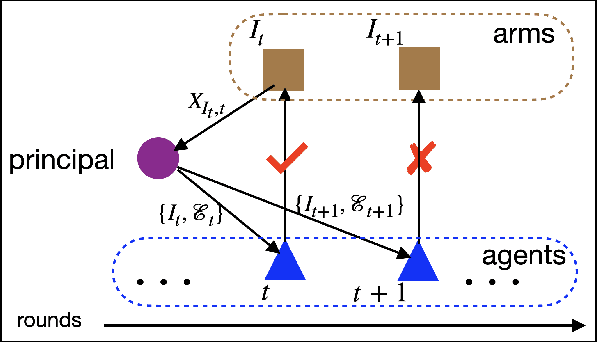
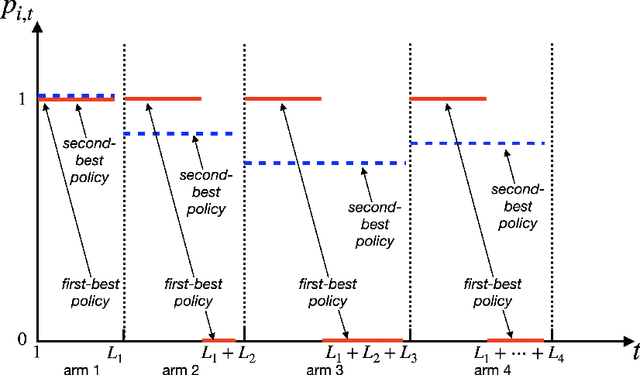
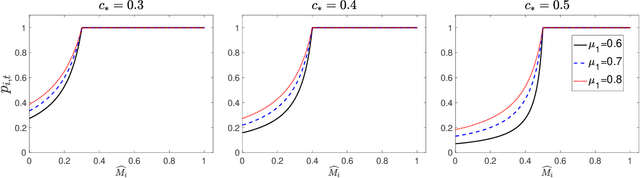
Online platforms in the Internet Economy commonly incorporate recommender systems that recommend arms (e.g., products) to agents (e.g., users). In such platforms, a myopic agent has a natural incentive to exploit, by choosing the best product given the current information rather than to explore various alternatives to collect information that will be used for other agents. We propose a novel recommender system that respects agents' incentives and enjoys asymptotically optimal performances expressed by the regret in repeated games. We model such an incentive-aware recommender system as a multi-agent bandit problem in a two-sided market which is equipped with an incentive constraint induced by agents' opportunity costs. If the opportunity costs are known to the principal, we show that there exists an incentive-compatible recommendation policy, which pools recommendations across a genuinely good arm and an unknown arm via a randomized and adaptive approach. On the other hand, if the opportunity costs are unknown to the principal, we propose a policy that randomly pools recommendations across all arms and uses each arm's cumulative loss as feedback for exploration. We show that both policies also satisfy an ex-post fairness criterion, which protects agents from over-exploitation.
Feature-augmented Machine Reading Comprehension with Auxiliary Tasks
Nov 17, 2022

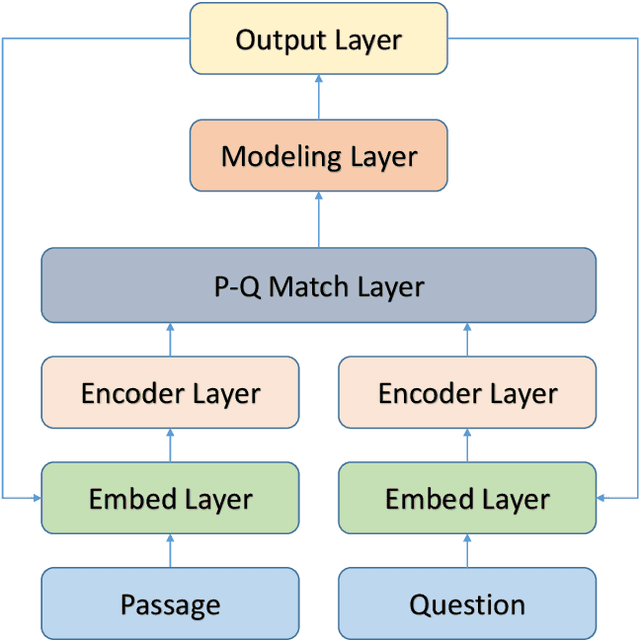
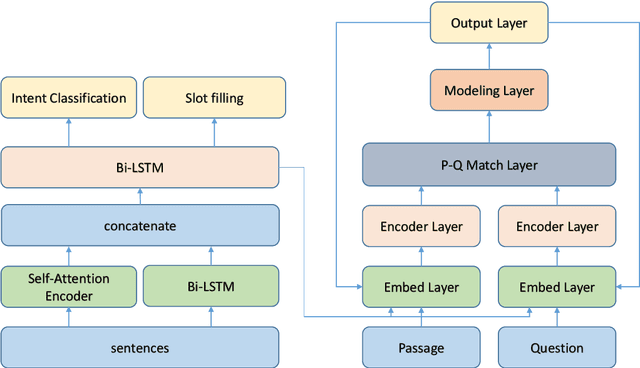
While most successful approaches for machine reading comprehension rely on single training objective, it is assumed that the encoder layer can learn great representation through the loss function we define in the predict layer, which is cross entropy in most of time, in the case that we first use neural networks to encode the question and paragraph, then directly fuse the encoding result of them. However, due to the distantly loss backpropagating in reading comprehension, the encoder layer cannot learn effectively and be directly supervised. Thus, the encoder layer can not learn the representation well at any time. Base on this, we propose to inject multi granularity information to the encoding layer. Experiments demonstrate the effect of adding multi granularity information to the encoding layer can boost the performance of machine reading comprehension system. Finally, empirical study shows that our approach can be applied to many existing MRC models.
Reconfigurable Intelligent Surfaces: The New Frontier of Next G Security
Dec 09, 2022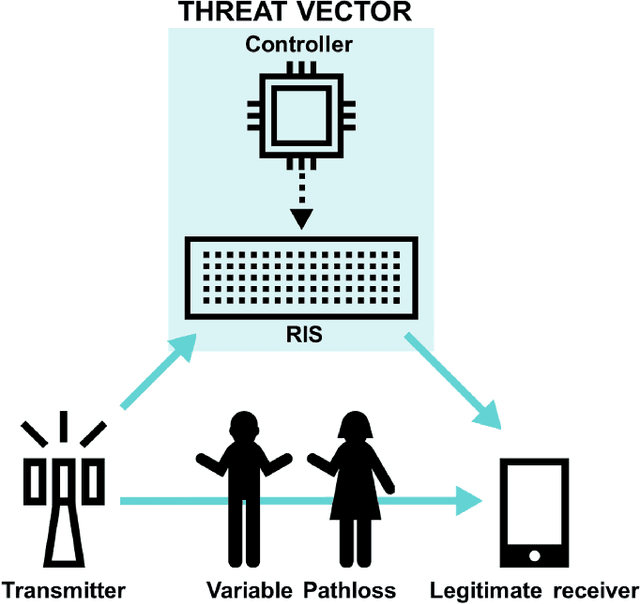
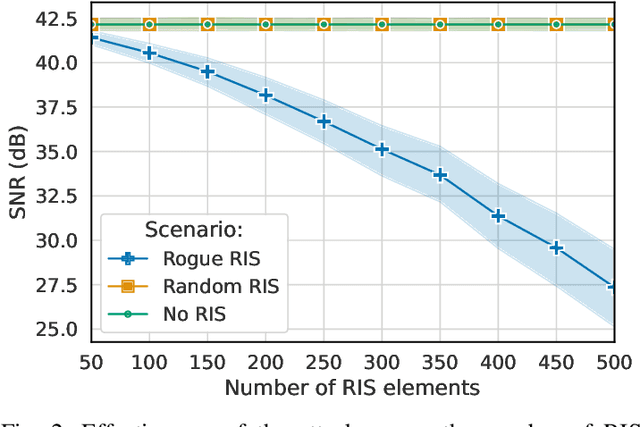
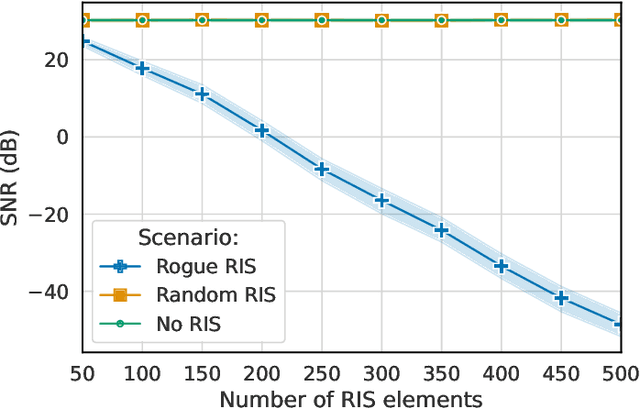
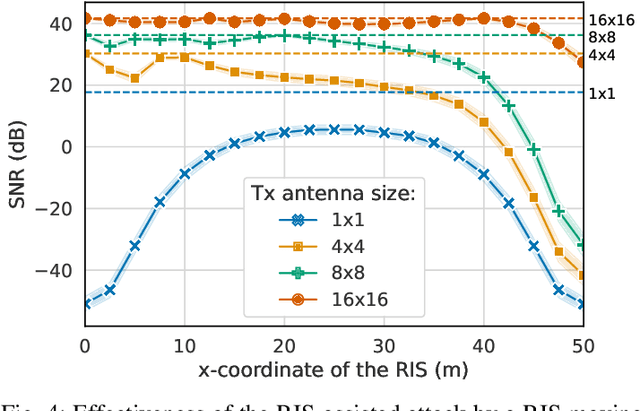
RIS is one of the significant technological advancements that will mark next-generation wireless. RIS technology also opens up the possibility of new security threats, since the reflection of impinging signals can be used for malicious purposes. This article introduces the basic concept for a RIS-assisted attack that re-uses the legitimate signal towards a malicious objective. Specific attacks are identified from this base scenario, and the RIS-assisted signal cancellation attack is selected for evaluation as an attack that inherently exploits RIS capabilities. The key takeaway from the evaluation is that an effective attack requires accurate channel information, a RIS deployed in a favorable location (from the point of view of the attacker), and it disproportionately affects legitimate links that already suffer from reduced path loss. These observations motivate specific security solutions and recommendations for future work.
Discriminability-Transferability Trade-Off: An Information-Theoretic Perspective
Mar 08, 2022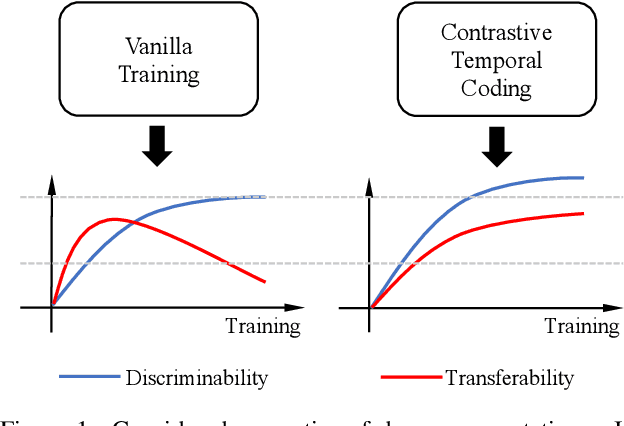

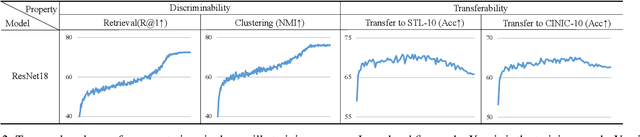

This work simultaneously considers the discriminability and transferability properties of deep representations in the typical supervised learning task, i.e., image classification. By a comprehensive temporal analysis, we observe a trade-off between these two properties. The discriminability keeps increasing with the training progressing while the transferability intensely diminishes in the later training period. From the perspective of information-bottleneck theory, we reveal that the incompatibility between discriminability and transferability is attributed to the over-compression of input information. More importantly, we investigate why and how the InfoNCE loss can alleviate the over-compression, and further present a learning framework, named contrastive temporal coding~(CTC), to counteract the over-compression and alleviate the incompatibility. Extensive experiments validate that CTC successfully mitigates the incompatibility, yielding discriminative and transferable representations. Noticeable improvements are achieved on the image classification task and challenging transfer learning tasks. We hope that this work will raise the significance of the transferability property in the conventional supervised learning setting. Code will be publicly available.
Dynamic Feature Pruning and Consolidation for Occluded Person Re-Identification
Nov 27, 2022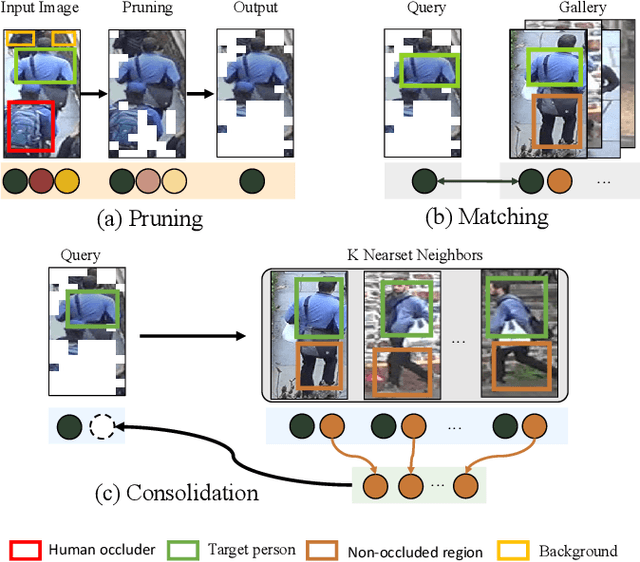
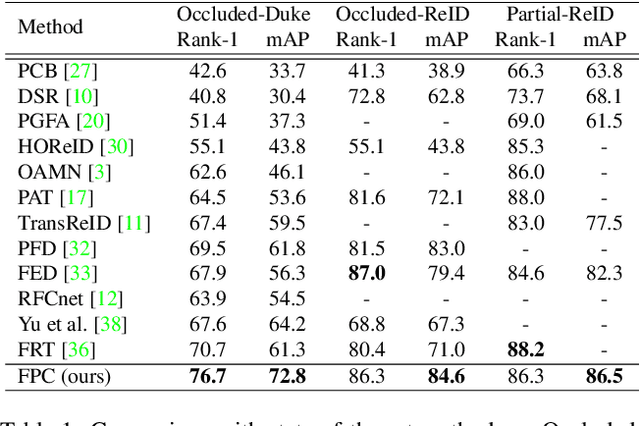
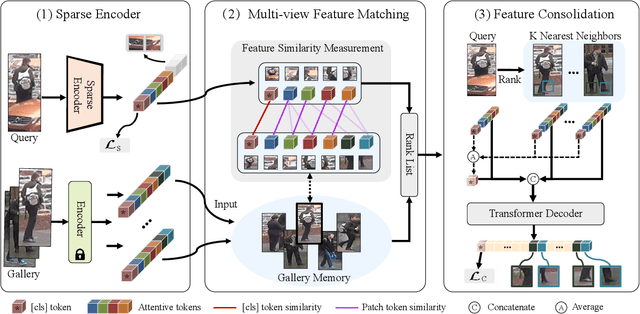
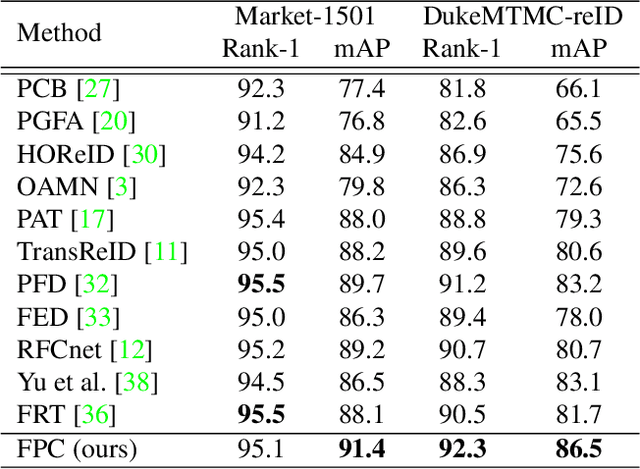
Occluded person re-identification (ReID) is a challenging problem due to contamination from occluders, and existing approaches address the issue with prior knowledge cues, eg human body key points, semantic segmentations and etc, which easily fails in the presents of heavy occlusion and other humans as occluders. In this paper, we propose a feature pruning and consolidation (FPC) framework to circumvent explicit human structure parse, which mainly consists of a sparse encoder, a global and local feature ranking module, and a feature consolidation decoder. Specifically, the sparse encoder drops less important image tokens (mostly related to background noise and occluders) solely according to correlation within the class token attention instead of relying on prior human shape information. Subsequently, the ranking stage relies on the preserved tokens produced by the sparse encoder to identify k-nearest neighbors from a pre-trained gallery memory by measuring the image and patch-level combined similarity. Finally, we use the feature consolidation module to compensate pruned features using identified neighbors for recovering essential information while disregarding disturbance from noise and occlusion. Experimental results demonstrate the effectiveness of our proposed framework on occluded, partial and holistic Re-ID datasets. In particular, our method outperforms state-of-the-art results by at least 8.6% mAP and 6.0% Rank-1 accuracy on the challenging Occluded-Duke dataset.
Traffic Flow Prediction via Variational Bayesian Inference-based Encoder-Decoder Framework
Dec 14, 2022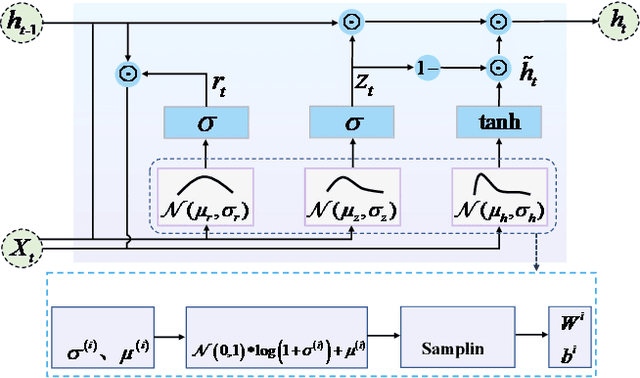
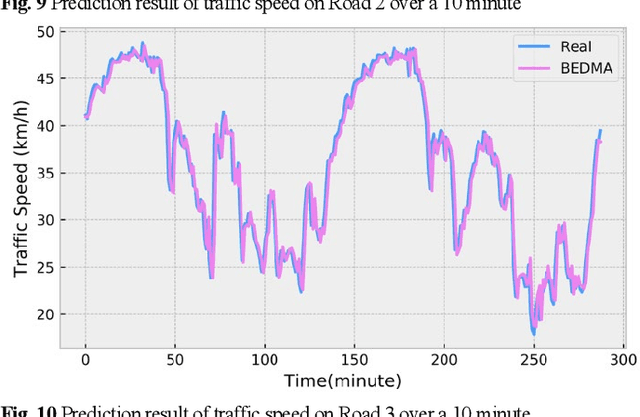
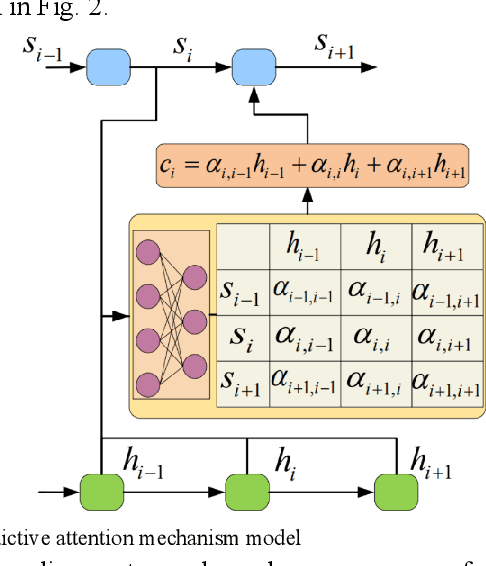
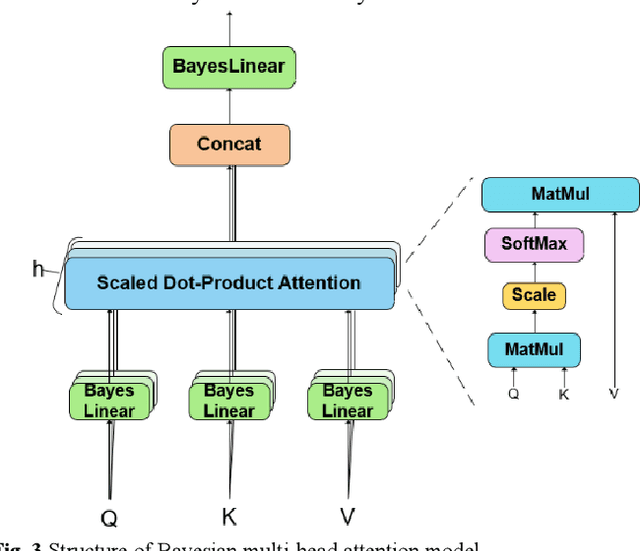
Accurate traffic flow prediction, a hotspot for intelligent transportation research, is the prerequisite for mastering traffic and making travel plans. The speed of traffic flow can be affected by roads condition, weather, holidays, etc. Furthermore, the sensors to catch the information about traffic flow will be interfered with by environmental factors such as illumination, collection time, occlusion, etc. Therefore, the traffic flow in the practical transportation system is complicated, uncertain, and challenging to predict accurately. This paper proposes a deep encoder-decoder prediction framework based on variational Bayesian inference. A Bayesian neural network is constructed by combining variational inference with gated recurrent units (GRU) and used as the deep neural network unit of the encoder-decoder framework to mine the intrinsic dynamics of traffic flow. Then, the variational inference is introduced into the multi-head attention mechanism to avoid noise-induced deterioration of prediction accuracy. The proposed model achieves superior prediction performance on the Guangzhou urban traffic flow dataset over the benchmarks, particularly when the long-term prediction.
Fully complex-valued deep learning model for visual perception
Dec 14, 2022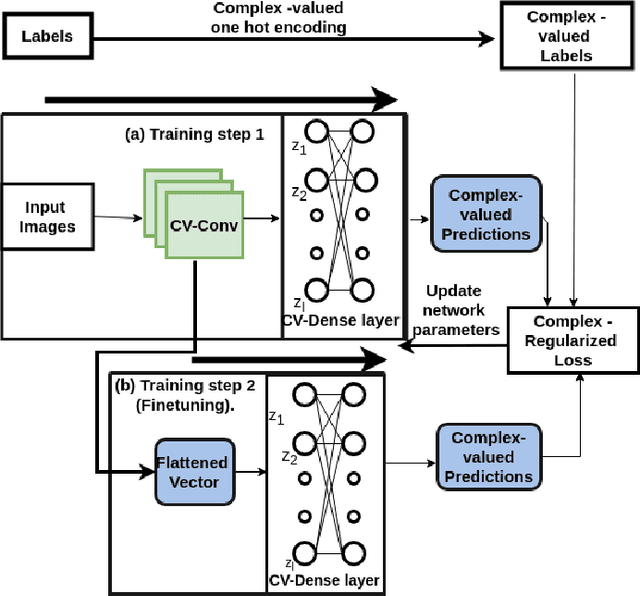
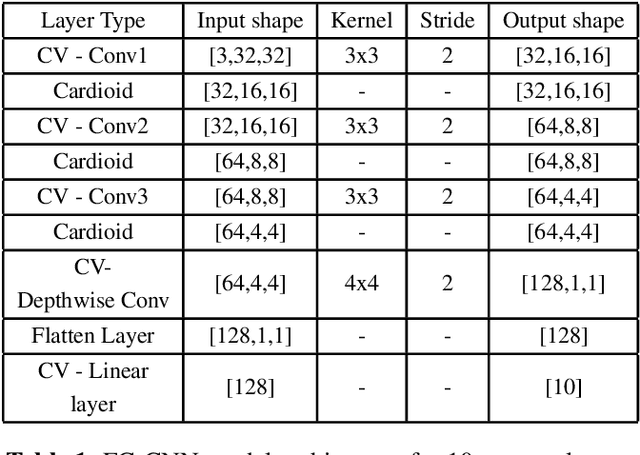
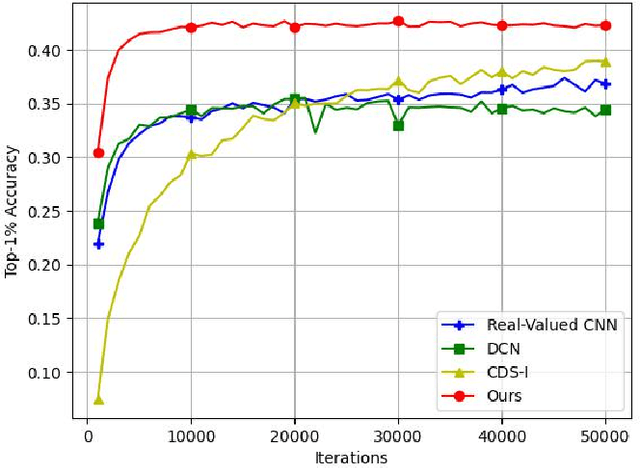
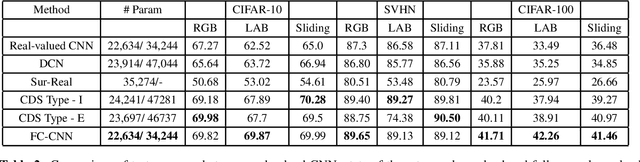
Deep learning models operating in the complex domain are used due to their rich representation capacity. However, most of these models are either restricted to the first quadrant of the complex plane or project the complex-valued data into the real domain, causing a loss of information. This paper proposes that operating entirely in the complex domain increases the overall performance of complex-valued models. A novel, fully complex-valued learning scheme is proposed to train a Fully Complex-valued Convolutional Neural Network (FC-CNN) using a newly proposed complex-valued loss function and training strategy. Benchmarked on CIFAR-10, SVHN, and CIFAR-100, FC-CNN has a 4-10% gain compared to its real-valued counterpart, maintaining the model complexity. With fewer parameters, it achieves comparable performance to state-of-the-art complex-valued models on CIFAR-10 and SVHN. For the CIFAR-100 dataset, it achieves state-of-the-art performance with 25% fewer parameters. FC-CNN shows better training efficiency and much faster convergence than all the other models.