 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Adaptive and Scalable Compression of Multispectral Images using VVC
Jan 10, 2023

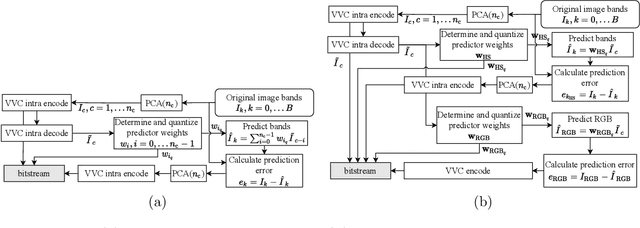
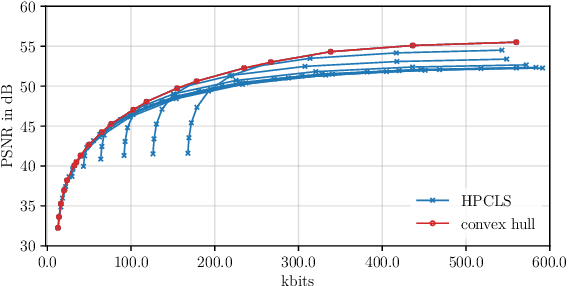
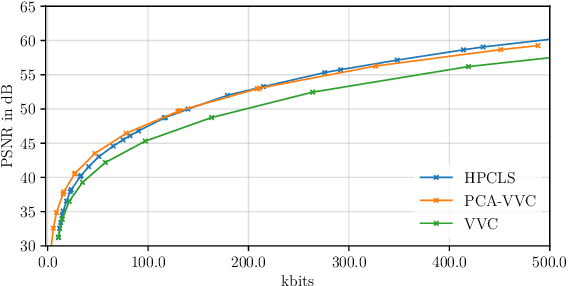
The VVC codec is applied to the task of multispectral image (MSI) compression using adaptive and scalable coding structures. In a 'plain' VVC approach, concepts from picture-to-picture temporal prediction are employed for decorrelation along the MSI's spectral dimension. The popular principle component analysis (PCA) for spectral decorrelation is further evaluated in combination with VVC intra-coding for spatial decorrelation. This approach is referred to as PCA-VVC. A novel adaptive MSI compression algorithm, named HPCLS, is introduced, that uses PCA and inter-prediction for spectral and VVC intra-coding for spatial decorrelation. Further, a novel adaptive scalable approach is proposed, that provides a separately decodable spectrally scaled preview of the MSI in the compressed file. Information contained in the preview is exploited in order to reduce the overall file size. All schemes are evaluated on images from the ARAD HS data set containing outdoor scenes with a high variety in brightness and color. We found that 'Plain' VVC is outperformed by both PCA-VVC and HPCLS. HPCLS shows advantageous rate-distortion (RD) behavior compared to PCA-VVC for reconstruction quality above 51dB PSNR. The performance of the scalable approach is compared to the combination of an independent RGB preview and one of HPCLS or PCA-VVC. The scalable approach shows significant benefit especially at higher preview qualities.
Channel-aware Decoupling Network for Multi-turn Dialogue Comprehension
Jan 10, 2023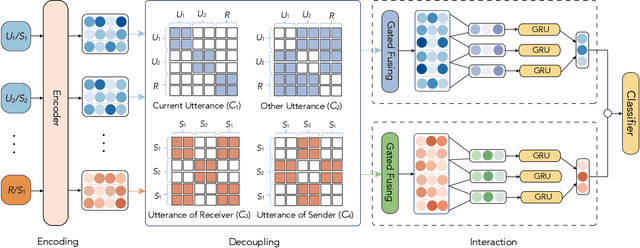
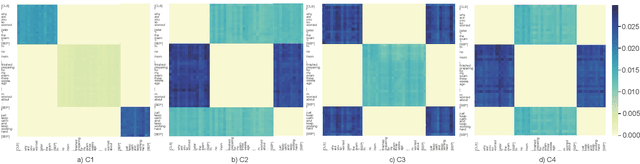
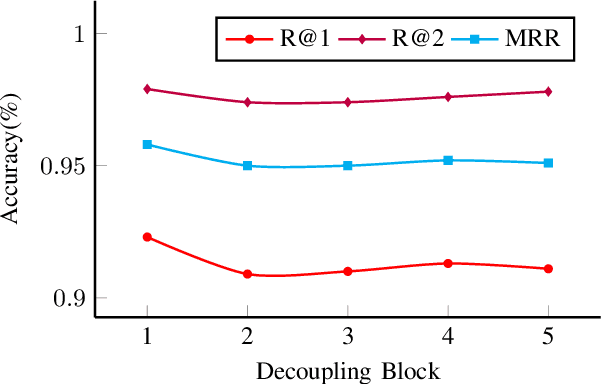
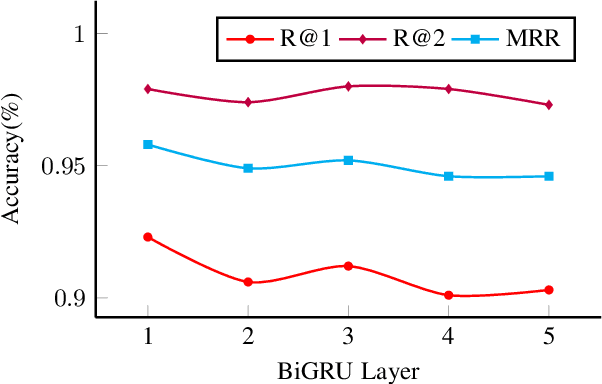
Training machines to understand natural language and interact with humans is one of the major goals of artificial intelligence. Recent years have witnessed an evolution from matching networks to pre-trained language models (PrLMs). In contrast to the plain-text modeling as the focus of the PrLMs, dialogue texts involve multiple speakers and reflect special characteristics such as topic transitions and structure dependencies between distant utterances. However, the related PrLM models commonly represent dialogues sequentially by processing the pairwise dialogue history as a whole. Thus the hierarchical information on either utterance interrelation or speaker roles coupled in such representations is not well addressed. In this work, we propose compositional learning for holistic interaction across the utterances beyond the sequential contextualization from PrLMs, in order to capture the utterance-aware and speaker-aware representations entailed in a dialogue history. We decouple the contextualized word representations by masking mechanisms in Transformer-based PrLM, making each word only focus on the words in current utterance, other utterances, and two speaker roles (i.e., utterances of sender and utterances of the receiver), respectively. In addition, we employ domain-adaptive training strategies to help the model adapt to the dialogue domains. Experimental results show that our method substantially boosts the strong PrLM baselines in four public benchmark datasets, achieving new state-of-the-art performance over previous methods.
Computer Vision for Transit Travel Time Prediction: An End-to-End Framework Using Roadside Urban Imagery
Dec 13, 2022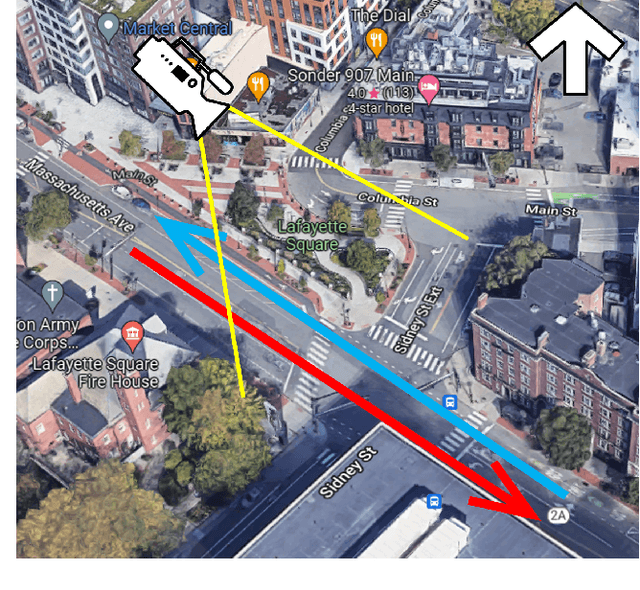


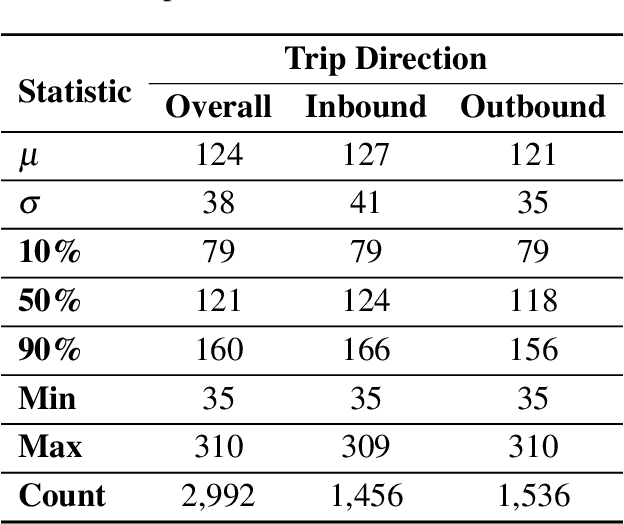
Accurate travel time estimation is paramount for providing transit users with reliable schedules and dependable real-time information. This paper is the first to utilize roadside urban imagery for direct transit travel time prediction. We propose and evaluate an end-to-end framework integrating traditional transit data sources with a roadside camera for automated roadside image data acquisition, labeling, and model training to predict transit travel times across a segment of interest. First, we show how the GTFS real-time data can be utilized as an efficient activation mechanism for a roadside camera unit monitoring a segment of interest. Second, AVL data is utilized to generate ground truth labels for the acquired images based on the observed transit travel time percentiles across the camera-monitored segment during the time of image acquisition. Finally, the generated labeled image dataset is used to train and thoroughly evaluate a Vision Transformer (ViT) model to predict a discrete transit travel time range (band). The results illustrate that the ViT model is able to learn image features and contents that best help it deduce the expected travel time range with an average validation accuracy ranging between 80%-85%. We assess the interpretability of the ViT model's predictions and showcase how this discrete travel time band prediction can subsequently improve continuous transit travel time estimation. The workflow and results presented in this study provide an end-to-end, scalable, automated, and highly efficient approach for integrating traditional transit data sources and roadside imagery to improve the estimation of transit travel duration. This work also demonstrates the value of incorporating real-time information from computer-vision sources, which are becoming increasingly accessible and can have major implications for improving operations and passenger real-time information.
Mutual Guidance and Residual Integration for Image Enhancement
Nov 25, 2022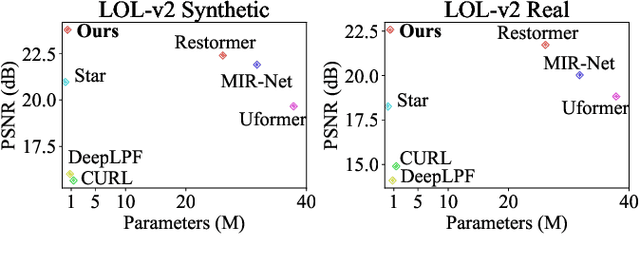
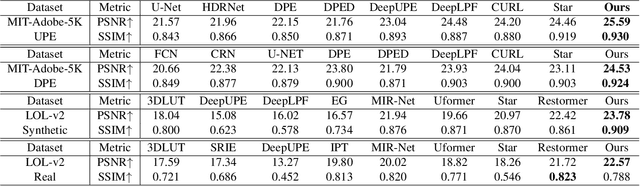

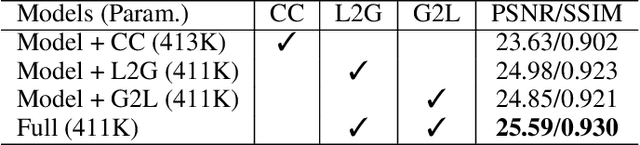
Previous studies show the necessity of global and local adjustment for image enhancement. However, existing convolutional neural networks (CNNs) and transformer-based models face great challenges in balancing the computational efficiency and effectiveness of global-local information usage. Especially, existing methods typically adopt the global-to-local fusion mode, ignoring the importance of bidirectional interactions. To address those issues, we propose a novel mutual guidance network (MGN) to perform effective bidirectional global-local information exchange while keeping a compact architecture. In our design, we adopt a two-branch framework where one branch focuses more on modeling global relations while the other is committed to processing local information. Then, we develop an efficient attention-based mutual guidance approach throughout our framework for bidirectional global-local interactions. As a result, both the global and local branches can enjoy the merits of mutual information aggregation. Besides, to further refine the results produced by our MGN, we propose a novel residual integration scheme following the divide-and-conquer philosophy. The extensive experiments demonstrate the effectiveness of our proposed method, which achieves state-of-the-art performance on several public image enhancement benchmarks.
Foldsformer: Learning Sequential Multi-Step Cloth Manipulation With Space-Time Attention
Jan 08, 2023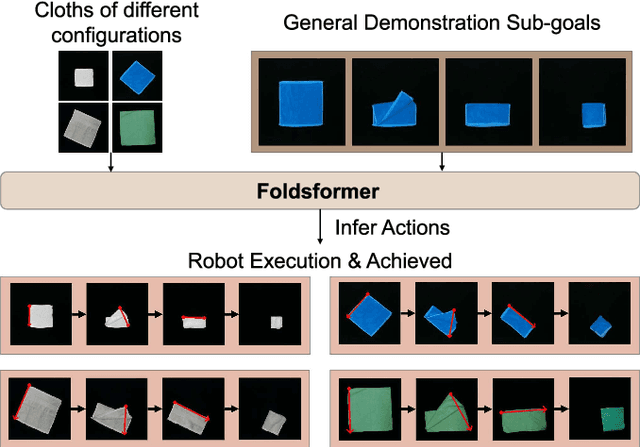
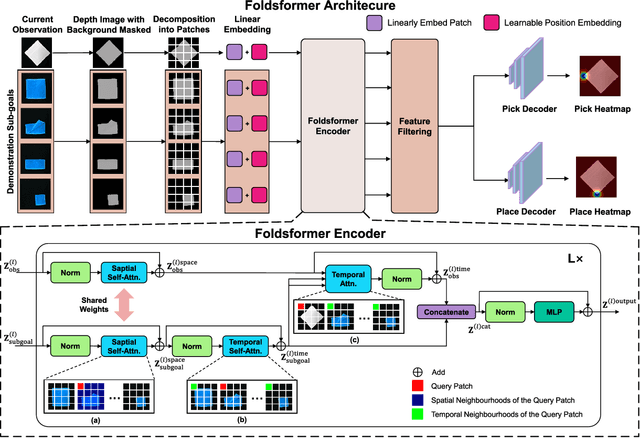
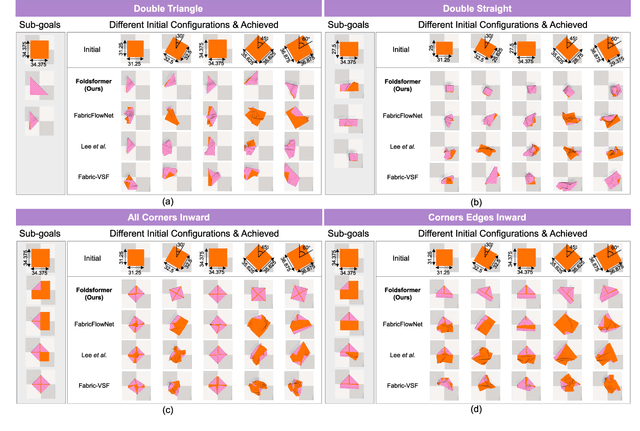
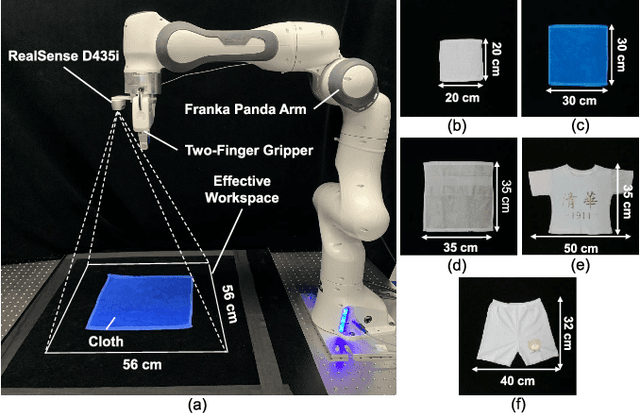
Sequential multi-step cloth manipulation is a challenging problem in robotic manipulation, requiring a robot to perceive the cloth state and plan a sequence of chained actions leading to the desired state. Most previous works address this problem in a goal-conditioned way, and goal observation must be given for each specific task and cloth configuration, which is not practical and efficient. Thus, we present a novel multi-step cloth manipulation planning framework named Foldformer. Foldformer can complete similar tasks with only a general demonstration and utilize a space-time attention mechanism to capture the instruction information behind this demonstration. We experimentally evaluate Foldsformer on four representative sequential multi-step manipulation tasks and show that Foldsformer significantly outperforms state-of-the-art approaches in simulation. Foldformer can complete multi-step cloth manipulation tasks even when configurations of the cloth (e.g., size and pose) vary from configurations in the general demonstrations. Furthermore, our approach can be transferred from simulation to the real world without additional training or domain randomization. Despite training on rectangular clothes, we also show that our approach can generalize to unseen cloth shapes (T-shirts and shorts). Videos and source code are available at: https://sites.google.com/view/foldsformer.
* 8 pages, 6 figures, published to IEEE Robotics & Automation Letters (RA-L)
Multi-scale multi-modal micro-expression recognition algorithm based on transformer
Jan 08, 2023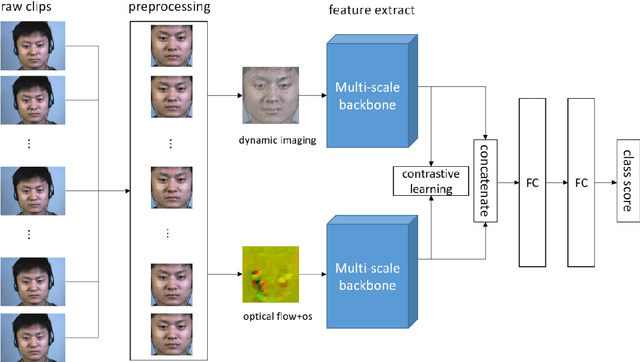

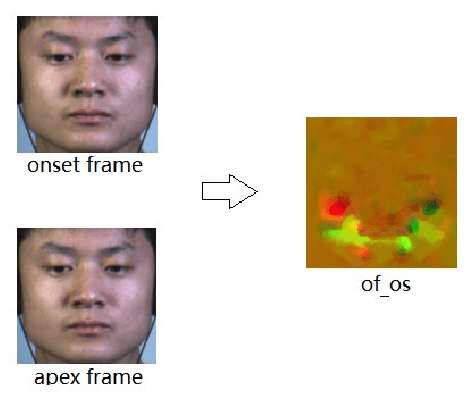
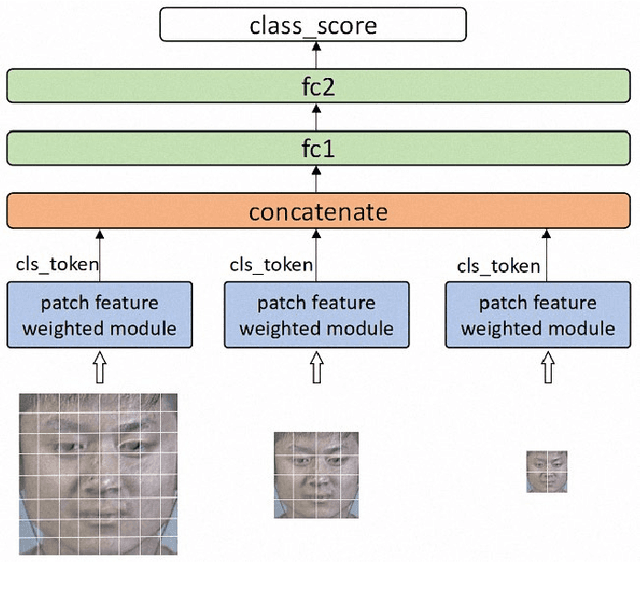
A micro-expression is a spontaneous unconscious facial muscle movement that can reveal the true emotions people attempt to hide. Although manual methods have made good progress and deep learning is gaining prominence. Due to the short duration of micro-expression occurrence and different scales of expressing in facial regions, existing algorithms cannot extract multi-modal multi-scale facial region features while taking into account contextual information to learn underlying features. Therefore, in order to solve the above problems, a multi-modal multi-scale algorithm based on transformer network is proposed in this paper, aiming to fully learn local multi-grained features of micro-expressions through two modal features of micro-expressions - motion features and texture features. To obtain local area features of the face at different scales, we learned patch features at different scales for both modalities, and then fused multi-layer multi-headed attention weights to obtain effective features by weighting the patch features, and combined cross-modal contrastive learning for model optimization. We conducted comprehensive experiments on three spontaneous datasets, and the results show the accuracy of the proposed algorithm in single measurement SMIC database is up to 78.73% and the F1 value on CASMEII of the combined database is up to 0.9071, which is at the leading level.
A Bayesian Robust Regression Method for Corrupted Data Reconstruction
Jan 08, 2023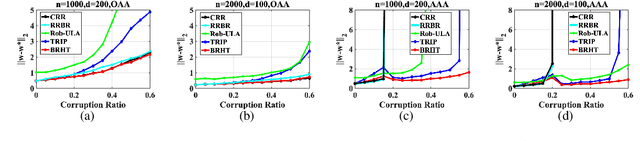
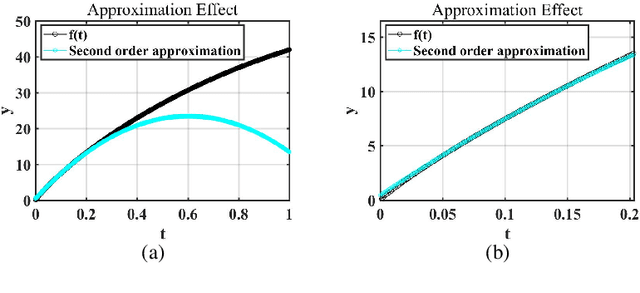
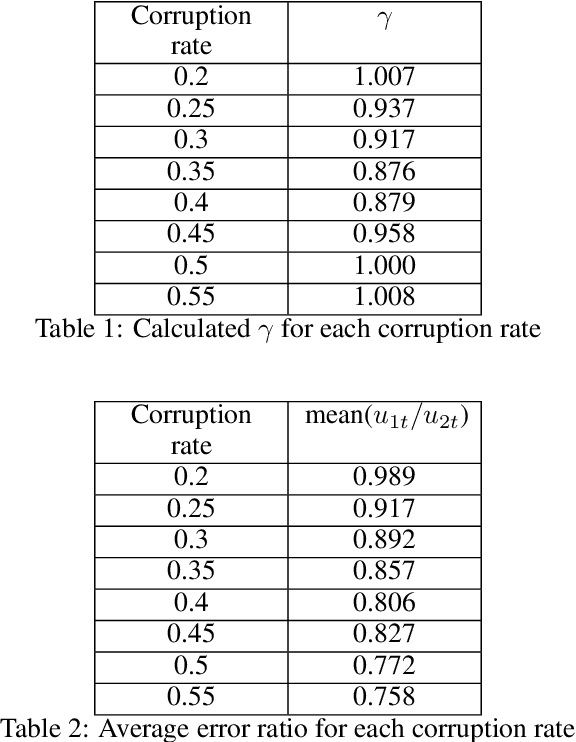

Because of the widespread existence of noise and data corruption, recovering the true regression parameters with a certain proportion of corrupted response variables is an essential task. Methods to overcome this problem often involve robust least-squares regression, but few methods perform well when confronted with severe adaptive adversarial attacks. In many applications, prior knowledge is often available from historical data or engineering experience, and by incorporating prior information into a robust regression method, we develop an effective robust regression method that can resist adaptive adversarial attacks. First, we propose the novel TRIP (hard Thresholding approach to Robust regression with sImple Prior) algorithm, which improves the breakdown point when facing adaptive adversarial attacks. Then, to improve the robustness and reduce the estimation error caused by the inclusion of priors, we use the idea of Bayesian reweighting to construct the more robust BRHT (robust Bayesian Reweighting regression via Hard Thresholding) algorithm. We prove the theoretical convergence of the proposed algorithms under mild conditions, and extensive experiments show that under different types of dataset attacks, our algorithms outperform other benchmark ones. Finally, we apply our methods to a data-recovery problem in a real-world application involving a space solar array, demonstrating their good applicability.
FMCW Radar Sensing for Indoor Drones Using Learned Representations
Jan 06, 2023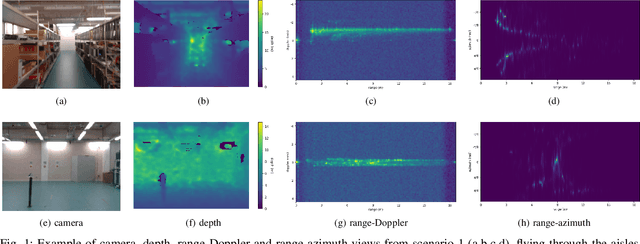

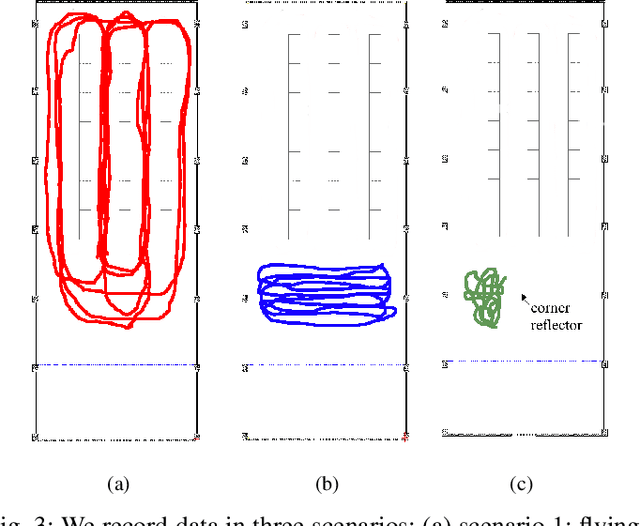
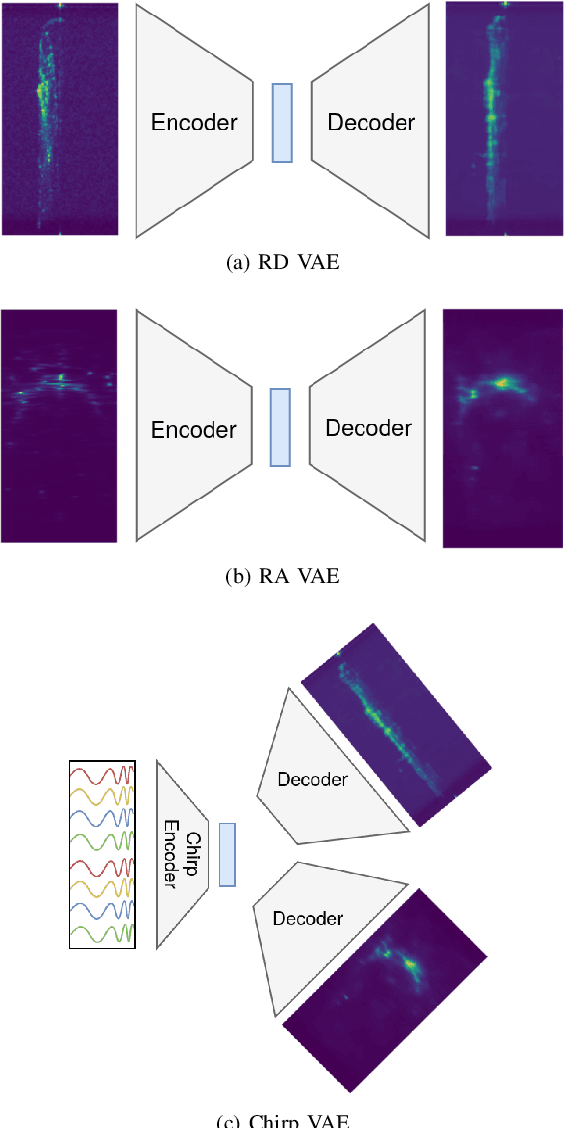
Frequency-modulated continuous-wave (FMCW) radar is a promising sensor technology for indoor drones as it provides range, angular as well as Doppler-velocity information about obstacles in the environment. Recently, deep learning approaches have been proposed for processing FMCW data, outperforming traditional detection techniques on range-Doppler or range-azimuth maps. However, these techniques come at a cost; for each novel task a deep neural network architecture has to be trained on high-dimensional input data, stressing both data bandwidth and processing budget. In this paper, we investigate unsupervised learning techniques that generate low-dimensional representations from FMCW radar data, and evaluate to what extent these representations can be reused for multiple downstream tasks. To this end, we introduce a novel dataset of raw radar ADC data recorded from a radar mounted on a flying drone platform in an indoor environment, together with ground truth detection targets. We show with real radar data that, utilizing our learned representations, we match the performance of conventional radar processing techniques and that our model can be trained on different input modalities such as raw ADC samples of only two consecutively transmitted chirps.
Task Aware Feature Extraction Framework for Sequential Dependence Multi-Task Learning
Jan 06, 2023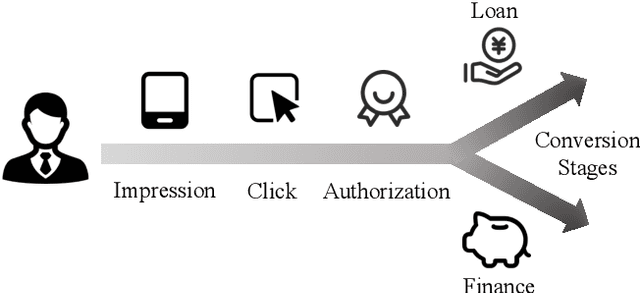

Multi-task learning (MTL) has been successfully implemented in many real-world applications, which aims to simultaneously solve multiple tasks with a single model. The general idea of multi-task learning is designing kinds of global parameter sharing mechanism and task-specific feature extractor to improve the performance of all tasks. However, sequential dependence between tasks are rarely studied but frequently encountered in e-commence online recommendation, e.g. impression, click and conversion on displayed product. There is few theoretical work on this problem and biased optimization object adopted in most MTL methods deteriorates online performance. Besides, challenge still remains in balancing the trade-off between various tasks and effectively learn common and specific representation. In this paper, we first analyze sequential dependence MTL from rigorous mathematical perspective and design a dependence task learning loss to provide an unbiased optimizing object. And we propose a Task Aware Feature Extraction (TAFE) framework for sequential dependence MTL, which enables to selectively reconstruct implicit shared representations from a sample-wise view and extract explicit task-specific information in an more efficient way. Extensive experiments on offline datasets and online A/B implementation demonstrate the effectiveness of our proposed TAFE.
Three-stage binarization of color document images based on discrete wavelet transform and generative adversarial networks
Dec 17, 2022
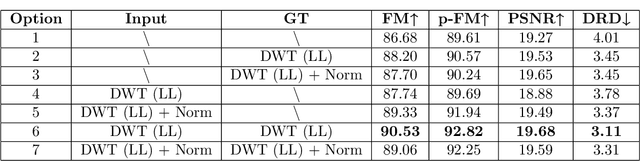
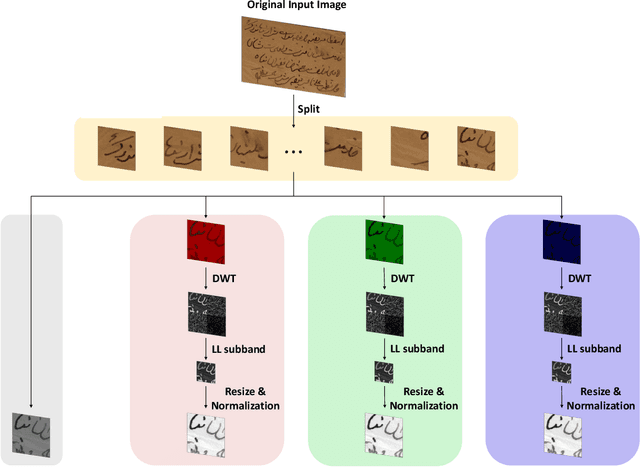
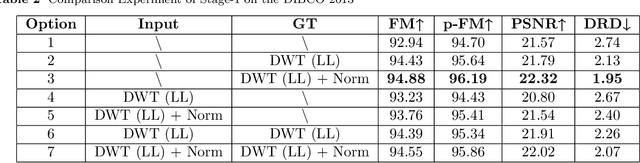
The efficient segmentation of foreground text information from the background in degraded color document images is a hot research topic. Due to the imperfect preservation of ancient documents over a long period of time, various types of degradation, including staining, yellowing, and ink seepage, have seriously affected the results of image binarization. In this paper, a three-stage method is proposed for image enhancement and binarization of degraded color document images by using discrete wavelet transform (DWT) and generative adversarial network (GAN). In Stage-1, we use DWT and retain the LL subband images to achieve the image enhancement. In Stage-2, the original input image is split into four (Red, Green, Blue and Gray) single-channel images, each of which trains the independent adversarial networks. The trained adversarial network models are used to extract the color foreground information from the images. In Stage-3, in order to combine global and local features, the output image from Stage-2 and the original input image are used to train the independent adversarial networks for document binarization. The experimental results demonstrate that our proposed method outperforms many classical and state-of-the-art (SOTA) methods on the Document Image Binarization Contest (DIBCO) dataset. We release our implementation code at https://github.com/abcpp12383/ThreeStageBinarization.