 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLMRec: Empowering Small Language Models for Sequential Recommendation
May 28, 2024



The sequential Recommendation (SR) task involves predicting the next item a user is likely to interact with, given their past interactions. The SR models examine the sequence of a user's actions to discern more complex behavioral patterns and temporal dynamics. Recent research demonstrates the great impact of LLMs on sequential recommendation systems, either viewing sequential recommendation as language modeling or serving as the backbone for user representation. Although these methods deliver outstanding performance, there is scant evidence of the necessity of a large language model and how large the language model is needed, especially in the sequential recommendation scene. Meanwhile, due to the huge size of LLMs, it is inefficient and impractical to apply a LLM-based model in real-world platforms that often need to process billions of traffic logs daily. In this paper, we explore the influence of LLMs' depth by conducting extensive experiments on large-scale industry datasets. Surprisingly, we discover that most intermediate layers of LLMs are redundant. Motivated by this insight, we empower small language models for SR, namely SLMRec, which adopt a simple yet effective knowledge distillation method. Moreover, SLMRec is orthogonal to other post-training efficiency techniques, such as quantization and pruning, so that they can be leveraged in combination. Comprehensive experimental results illustrate that the proposed SLMRec model attains the best performance using only 13% of the parameters found in LLM-based recommendation models, while simultaneously achieving up to 6.6x and 8.0x speedups in training and inference time costs, respectively.
Fine-Grained Dynamic Framework for Bias-Variance Joint Optimization on Data Missing Not at Random
May 24, 2024



In most practical applications such as recommendation systems, display advertising, and so forth, the collected data often contains missing values and those missing values are generally missing-not-at-random, which deteriorates the prediction performance of models. Some existing estimators and regularizers attempt to achieve unbiased estimation to improve the predictive performance. However, variances and generalization bound of these methods are generally unbounded when the propensity scores tend to zero, compromising their stability and robustness. In this paper, we first theoretically reveal that limitations of regularization techniques. Besides, we further illustrate that, for more general estimators, unbiasedness will inevitably lead to unbounded variance. These general laws inspire us that the estimator designs is not merely about eliminating bias, reducing variance, or simply achieve a bias-variance trade-off. Instead, it involves a quantitative joint optimization of bias and variance. Then, we develop a systematic fine-grained dynamic learning framework to jointly optimize bias and variance, which adaptively selects an appropriate estimator for each user-item pair according to the predefined objective function. With this operation, the generalization bounds and variances of models are reduced and bounded with theoretical guarantees. Extensive experiments are conducted to verify the theoretical results and the effectiveness of the proposed dynamic learning framework.
Towards Open-world Cross-Domain Sequential Recommendation: A Model-Agnostic Contrastive Denoising Approach
Nov 23, 2023



Cross-domain sequential recommendation (CDSR) aims to address the data sparsity problems that exist in traditional sequential recommendation (SR) systems. The existing approaches aim to design a specific cross-domain unit that can transfer and propagate information across multiple domains by relying on overlapping users with abundant behaviors. However, in real-world recommender systems, CDSR scenarios usually consist of a majority of long-tailed users with sparse behaviors and cold-start users who only exist in one domain. This leads to a drop in the performance of existing CDSR methods in the real-world industry platform. Therefore, improving the consistency and effectiveness of models in open-world CDSR scenarios is crucial for constructing CDSR models (\textit{1st} CH). Recently, some SR approaches have utilized auxiliary behaviors to complement the information for long-tailed users. However, these multi-behavior SR methods cannot deliver promising performance in CDSR, as they overlook the semantic gap between target and auxiliary behaviors, as well as user interest deviation across domains (\textit{2nd} CH).
Adaptive Pattern Extraction Multi-Task Learning for Multi-Step Conversion Estimations
Jan 23, 2023



Multi-task learning (MTL) has been successfully used in many real-world applications, which aims to simultaneously solve multiple tasks with a single model. The general idea of multi-task learning is designing kinds of global parameter sharing mechanism and task-specific feature extractor to improve the performance of all tasks. However, challenge still remains in balancing the trade-off of various tasks since model performance is sensitive to the relationships between them. Less correlated or even conflict tasks will deteriorate the performance by introducing unhelpful or negative information. Therefore, it is important to efficiently exploit and learn fine-grained feature representation corresponding to each task. In this paper, we propose an Adaptive Pattern Extraction Multi-task (APEM) framework, which is adaptive and flexible for large-scale industrial application. APEM is able to fully utilize the feature information by learning the interactions between the input feature fields and extracted corresponding tasks-specific information. We first introduce a DeepAuto Group Transformer module to automatically and efficiently enhance the feature expressivity with a modified set attention mechanism and a Squeeze-and-Excitation operation. Second, explicit Pattern Selector is introduced to further enable selectively feature representation learning by adaptive task-indicator vectors. Empirical evaluations show that APEM outperforms the state-of-the-art MTL methods on public and real-world financial services datasets. More importantly, we explore the online performance of APEM in a real industrial-level recommendation scenario.
An Adaptive Oversampling Learning Method for Class-Imbalanced Fault Diagnostics and Prognostics
Nov 19, 2018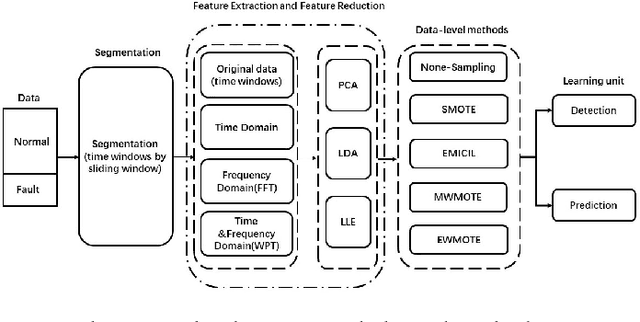
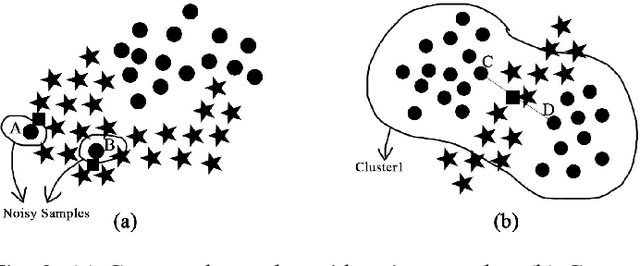
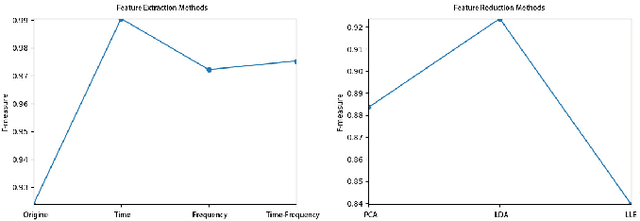
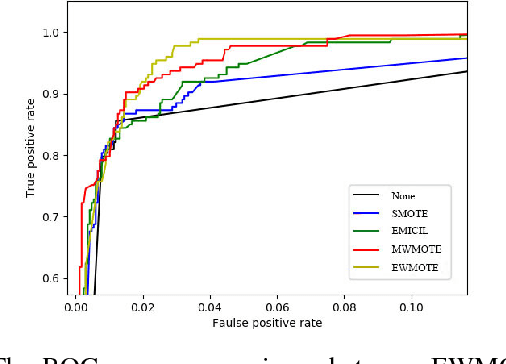
Data-driven fault diagnostics and prognostics suffers from class-imbalance problem in industrial systems and it raises challenges to common machine learning algorithms as it becomes difficult to learn the features of the minority class samples. Synthetic oversampling methods are commonly used to tackle these problems by generating the minority class samples to balance the distributions between majority and minority classes. However, many of oversampling methods are inappropriate that they cannot generate effective and useful minority class samples according to different distributions of data, which further complicate the process of learning samples. Thus, this paper proposes a novel adaptive oversampling technique: EM-based Weighted Minority Oversampling TEchnique (EWMOTE) for industrial fault diagnostics and prognostics. The methods comprises a weighted minority sampling strategy to identify hard-to-learn informative minority fault samples and Expectation Maximization (EM) based imputation algorithm to generate fault samples. To validate the performance of the proposed methods, experiments are conducted in two real datasets. The results show that the method could achieve better performance on not only binary class, but multi-class imbalance learning task in different imbalance ratios than other oversampling-based baseline models.