 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Target Defense against Sequentially Arriving Intruders
Dec 13, 2022
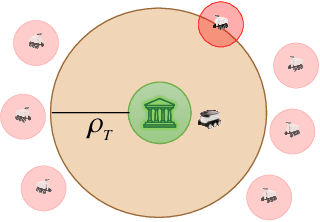
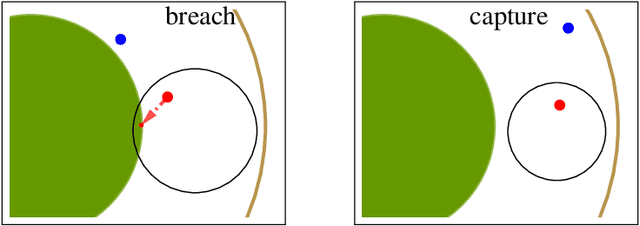
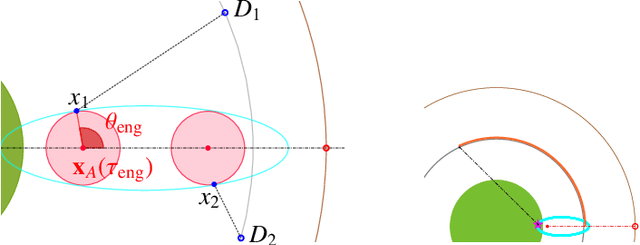
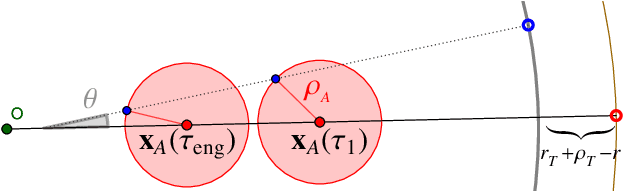
We consider a variant of the target defense problem where a single defender is tasked to capture a sequence of incoming intruders. The intruders' objective is to breach the target boundary without being captured by the defender. As soon as the current intruder breaches the target or gets captured by the defender, the next intruder appears at a random location on a fixed circle surrounding the target. Therefore, the defender's final location at the end of the current game becomes its initial location for the next game. Thus, the players pick strategies that are advantageous for the current as well as for the future games. Depending on the information available to the players, each game is divided into two phases: partial information and full information phase. Under some assumptions on the sensing and speed capabilities, we analyze the agents' strategies in both phases. We derive equilibrium strategies for both the players to optimize the capture percentage using the notions of engagement surface and capture circle. We quantify the percentage of capture for both finite and infinite sequences of incoming intruders.
Learning Disentangled Representations for Counterfactual Regression via Mutual Information Minimization
Jun 02, 2022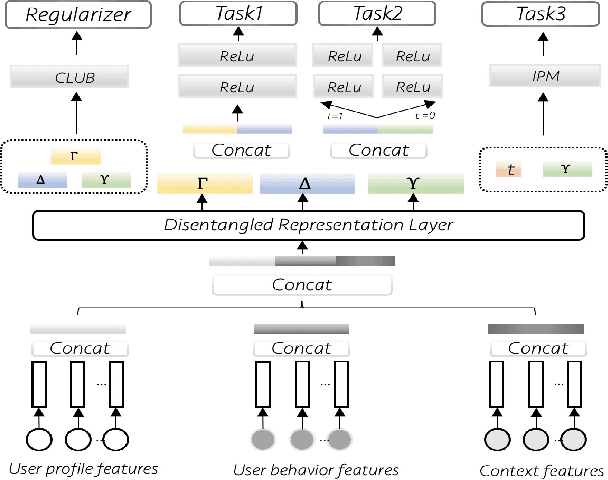
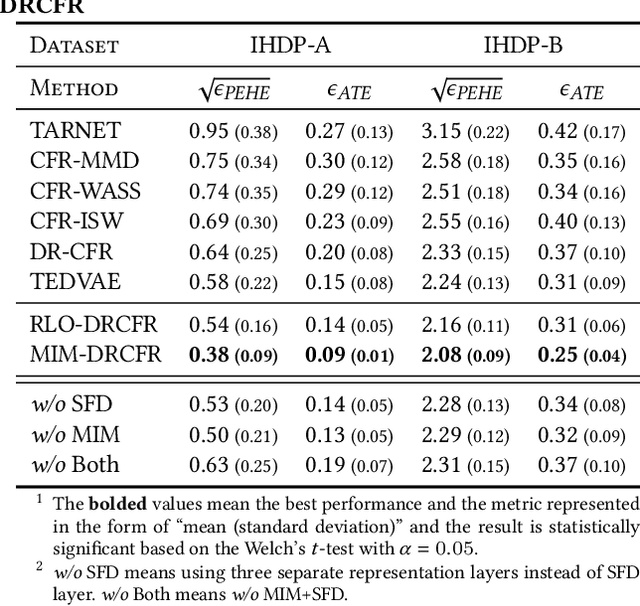
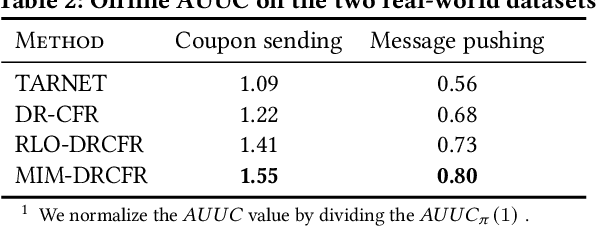
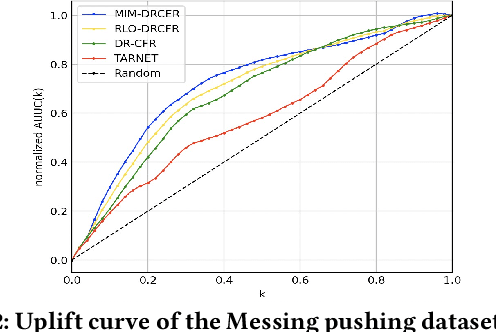
Learning individual-level treatment effect is a fundamental problem in causal inference and has received increasing attention in many areas, especially in the user growth area which concerns many internet companies. Recently, disentangled representation learning methods that decompose covariates into three latent factors, including instrumental, confounding and adjustment factors, have witnessed great success in treatment effect estimation. However, it remains an open problem how to learn the underlying disentangled factors precisely. Specifically, previous methods fail to obtain independent disentangled factors, which is a necessary condition for identifying treatment effect. In this paper, we propose Disentangled Representations for Counterfactual Regression via Mutual Information Minimization (MIM-DRCFR), which uses a multi-task learning framework to share information when learning the latent factors and incorporates MI minimization learning criteria to ensure the independence of these factors. Extensive experiments including public benchmarks and real-world industrial user growth datasets demonstrate that our method performs much better than state-of-the-art methods.
Deep Diversity-Enhanced Feature Representation of Hyperspectral Images
Jan 15, 2023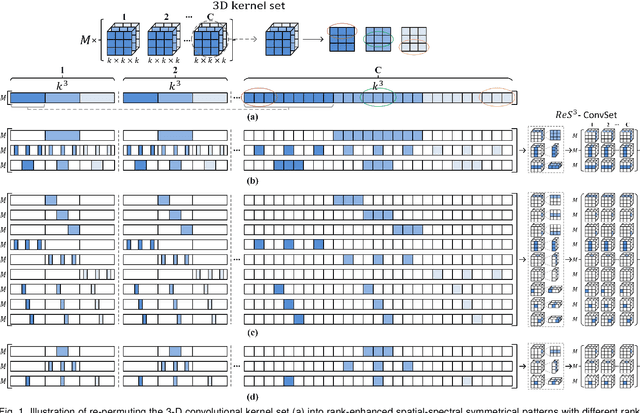
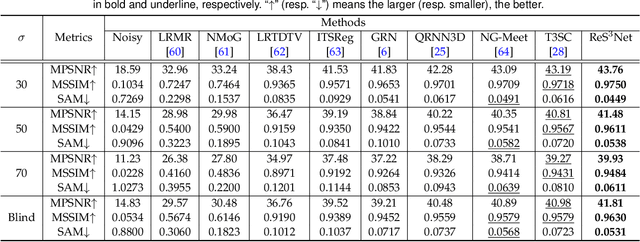
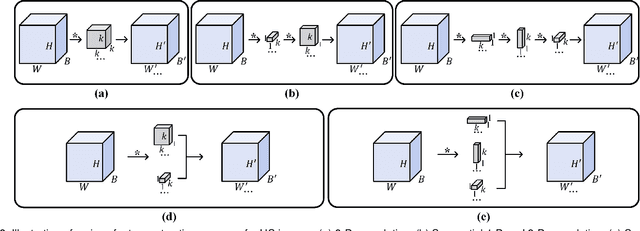
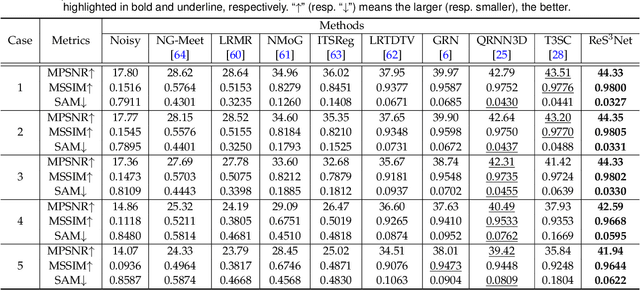
In this paper, we study the problem of embedding the high-dimensional spatio-spectral information of hyperspectral (HS) images efficiently and effectively, oriented by feature diversity. To be specific, based on the theoretical formulation that feature diversity is correlated with the rank of the unfolded kernel matrix, we rectify 3D convolution by modifying its topology to boost the rank upper-bound, yielding a rank-enhanced spatial-spectral symmetrical convolution set (ReS$^3$-ConvSet), which is able to not only learn diverse and powerful feature representations but also save network parameters. In addition, we also propose a novel diversity-aware regularization (DA-Reg) term, which acts directly on the feature maps to maximize the independence among elements. To demonstrate the superiority of the proposed ReS$^3$-ConvSet and DA-Reg, we apply them to various HS image processing and analysis tasks, including denoising, spatial super-resolution, and classification. Extensive experiments demonstrate that the proposed approaches outperform state-of-the-art methods to a significant extent both quantitatively and qualitatively. The code is publicly available at \url{https://github.com/jinnh/ReSSS-ConvSet}.
A data science and machine learning approach to continuous analysis of Shakespeare's plays
Jan 15, 2023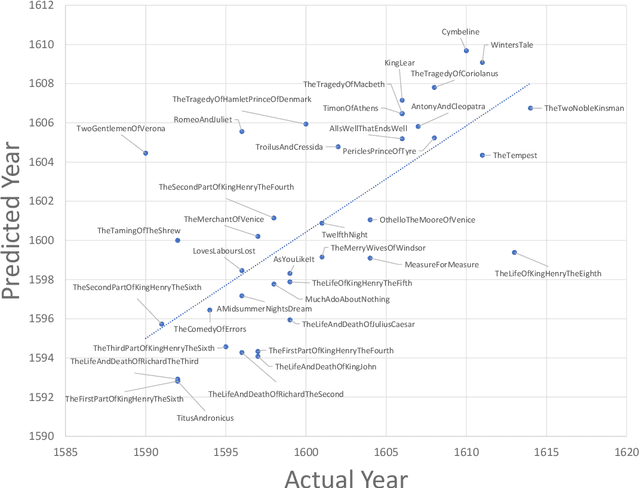
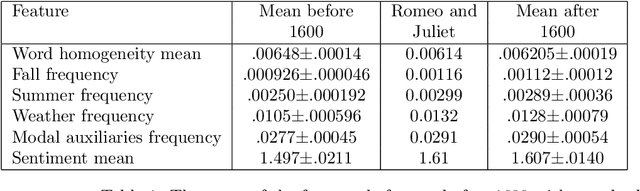
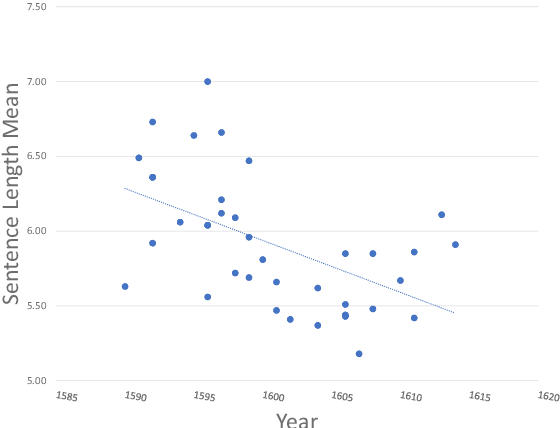
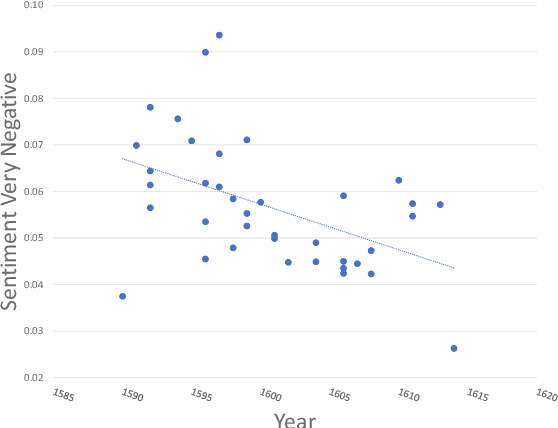
The availability of quantitative methods that can analyze text has provided new ways of examining literature in a manner that was not available in the pre-information era. Here we apply comprehensive machine learning analysis to the work of William Shakespeare. The analysis shows clear change in style of writing over time, with the most significant changes in the sentence length, frequency of adjectives and adverbs, and the sentiments expressed in the text. Applying machine learning to make a stylometric prediction of the year of the play shows a Pearson correlation of 0.71 between the actual and predicted year, indicating that Shakespeare's writing style as reflected by the quantitative measurements changed over time. Additionally, it shows that the stylometrics of some of the plays is more similar to plays written either before or after the year they were written. For instance, Romeo and Juliet is dated 1596, but is more similar in stylometrics to plays written by Shakespeare after 1600. The source code for the analysis is available for free download.
Multi Kernel Positional Embedding ConvNeXt for Polyp Segmentation
Jan 17, 2023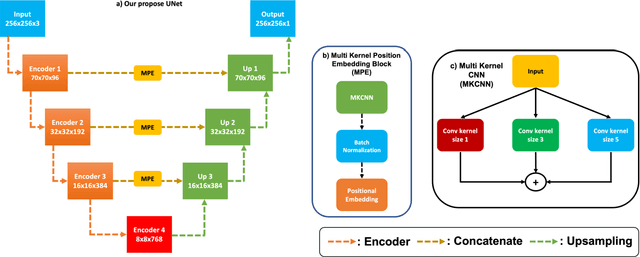
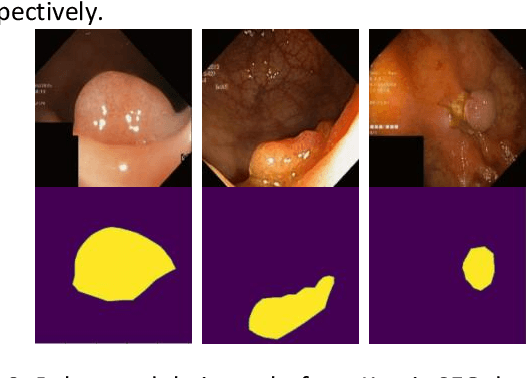
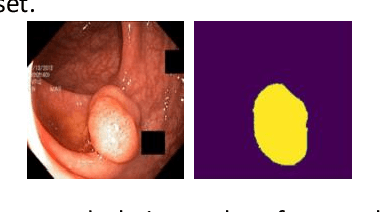
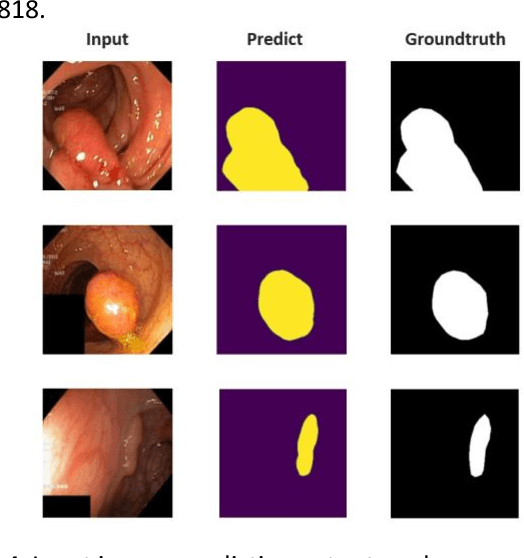
Medical image segmentation is the technique that helps doctor view and has a precise diagnosis, particularly in Colorectal Cancer. Specifically, with the increase in cases, the diagnosis and identification need to be faster and more accurate for many patients; in endoscopic images, the segmentation task has been vital to helping the doctor identify the position of the polyps or the ache in the system correctly. As a result, many efforts have been made to apply deep learning to automate polyp segmentation, mostly to ameliorate the U-shape structure. However, the simple skip connection scheme in UNet leads to deficient context information and the semantic gap between feature maps from the encoder and decoder. To deal with this problem, we propose a novel framework composed of ConvNeXt backbone and Multi Kernel Positional Embedding block. Thanks to the suggested module, our method can attain better accuracy and generalization in the polyps segmentation task. Extensive experiments show that our model achieves the Dice coefficient of 0.8818 and the IOU score of 0.8163 on the Kvasir-SEG dataset. Furthermore, on various datasets, we make competitive achievement results with other previous state-of-the-art methods.
Training Methods of Multi-label Prediction Classifiers for Hyperspectral Remote Sensing Images
Jan 17, 2023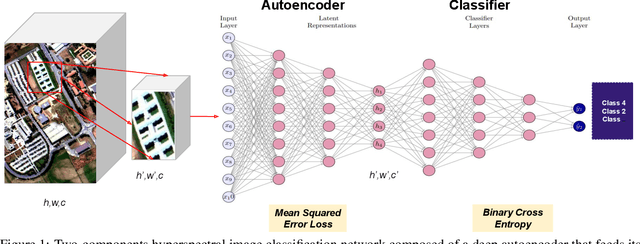


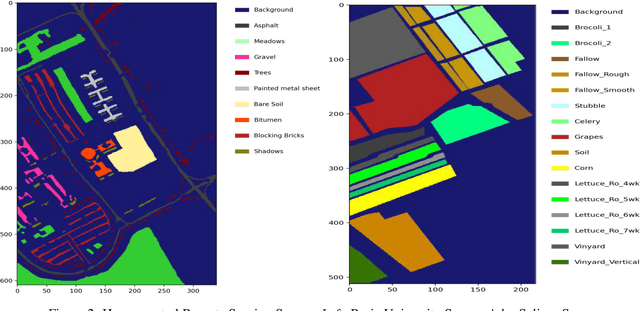
With their combined spectral depth and geometric resolution, hyperspectral remote sensing images embed a wealth of complex, non-linear information that challenges traditional computer vision techniques. Yet, deep learning methods known for their representation learning capabilities prove more suitable for handling such complexities. Unlike applications that focus on single-label, pixel-level classification methods for hyperspectral remote sensing images, we propose a multi-label, patch-level classification method based on a two-component deep-learning network. We use patches of reduced spatial dimension and a complete spectral depth extracted from the remote sensing images. Additionally, we investigate three training schemes for our network: Iterative, Joint, and Cascade. Experiments suggest that the Joint scheme is the best-performing scheme; however, its application requires an expensive search for the best weight combination of the loss constituents. The Iterative scheme enables the sharing of features between the two parts of the network at the early stages of training. It performs better on complex data with multi-labels. Further experiments showed that methods designed with different architectures performed well when trained on patches extracted and labeled according to our sampling method.
Learning a Formality-Aware Japanese Sentence Representation
Jan 17, 2023
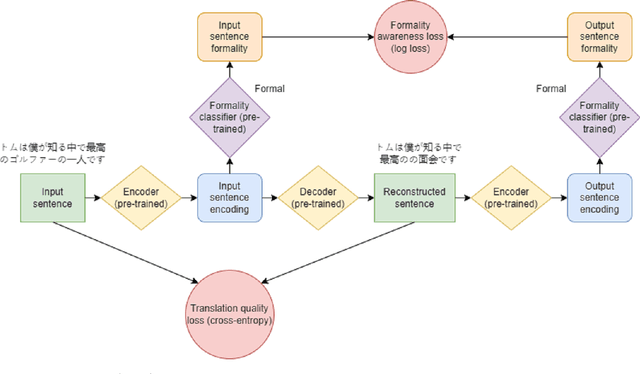


While the way intermediate representations are generated in encoder-decoder sequence-to-sequence models typically allow them to preserve the semantics of the input sentence, input features such as formality might be left out. On the other hand, downstream tasks such as translation would benefit from working with a sentence representation that preserves formality in addition to semantics, so as to generate sentences with the appropriate level of social formality -- the difference between speaking to a friend versus speaking with a supervisor. We propose a sequence-to-sequence method for learning a formality-aware representation for Japanese sentences, where sentence generation is conditioned on both the original representation of the input sentence, and a side constraint which guides the sentence representation towards preserving formality information. Additionally, we propose augmenting the sentence representation with a learned representation of formality which facilitates the extraction of formality in downstream tasks. We address the lack of formality-annotated parallel data by adapting previous works on procedural formality classification of Japanese sentences. Experimental results suggest that our techniques not only helps the decoder recover the formality of the input sentence, but also slightly improves the preservation of input sentence semantics.
Word-Graph2vec: An efficient word embedding approach on word co-occurrence graph using random walk sampling
Jan 17, 2023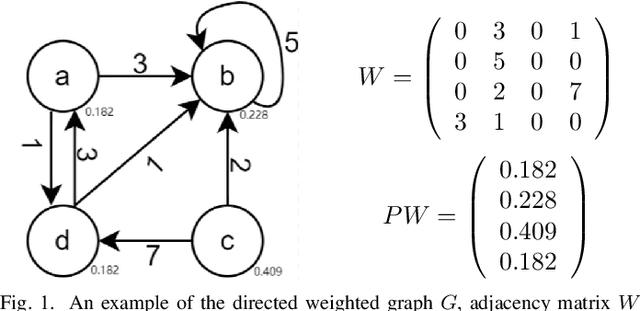
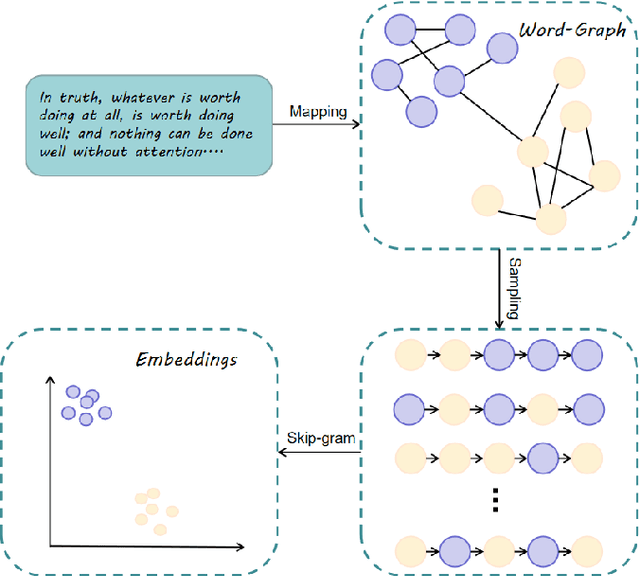
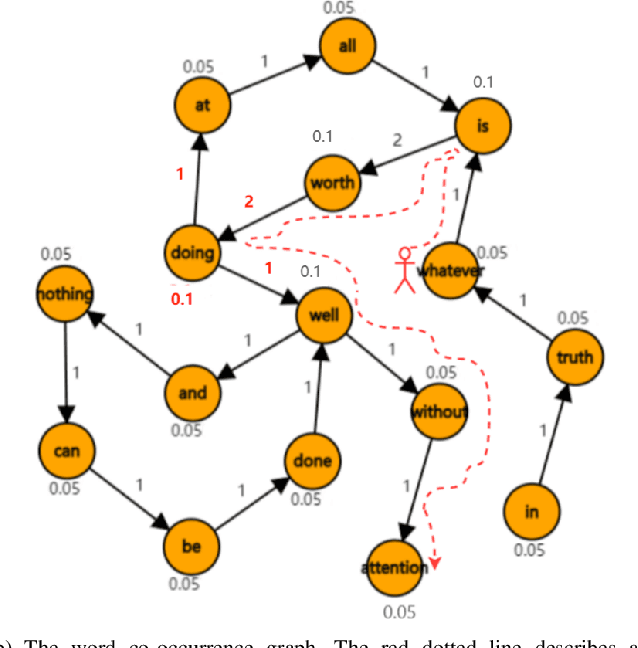
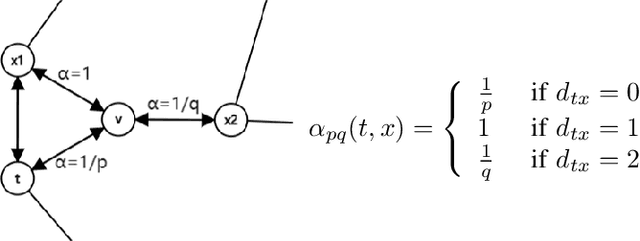
Word embedding has become ubiquitous and is widely used in various text mining and natural language processing (NLP) tasks, such as information retrieval, semantic analysis, and machine translation, among many others. Unfortunately, it is prohibitively expensive to train the word embedding in a relatively large corpus. We propose a graph-based word embedding algorithm, called Word-Graph2vec, which converts the large corpus into a word co-occurrence graph, then takes the word sequence samples from this graph by randomly traveling and trains the word embedding on this sampling corpus in the end. We posit that because of the stable vocabulary, relative idioms, and fixed expressions in English, the size and density of the word co-occurrence graph change slightly with the increase in the training corpus. So that Word-Graph2vec has stable runtime on the large scale data set, and its performance advantage becomes more and more obvious with the growth of the training corpus. Extensive experiments conducted on real-world datasets show that the proposed algorithm outperforms traditional Skip-Gram by four-five times in terms of efficiency, while the error generated by the random walk sampling is small.
Theoretical Understanding of the Information Flow on Continual Learning Performance
Apr 26, 2022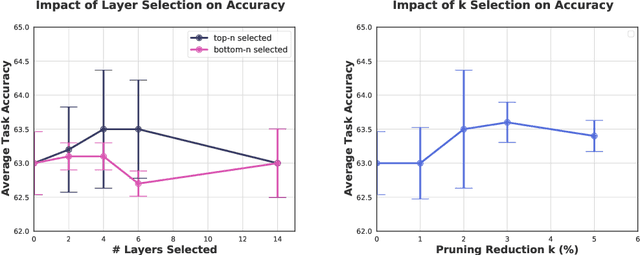
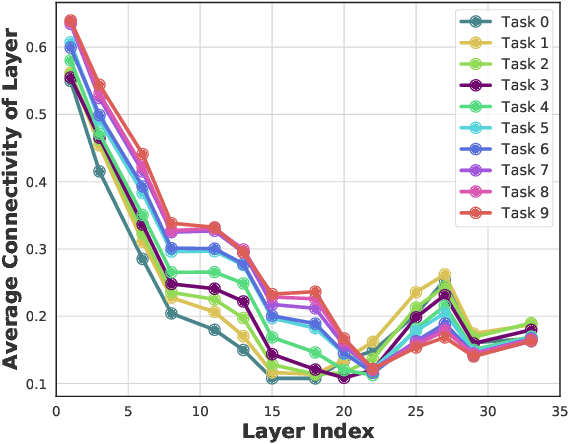
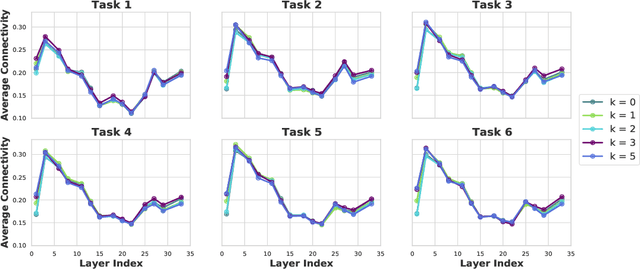
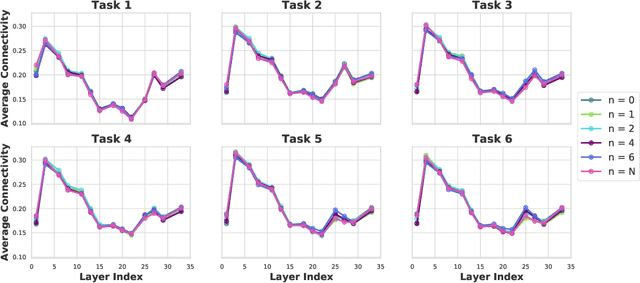
Continual learning (CL) is a setting in which an agent has to learn from an incoming stream of data sequentially. CL performance evaluates the model's ability to continually learn and solve new problems with incremental available information over time while retaining previous knowledge. Despite the numerous previous solutions to bypass the catastrophic forgetting (CF) of previously seen tasks during the learning process, most of them still suffer significant forgetting, expensive memory cost, or lack of theoretical understanding of neural networks' conduct while learning new tasks. While the issue that CL performance degrades under different training regimes has been extensively studied empirically, insufficient attention has been paid from a theoretical angle. In this paper, we establish a probabilistic framework to analyze information flow through layers in networks for task sequences and its impact on learning performance. Our objective is to optimize the information preservation between layers while learning new tasks to manage task-specific knowledge passing throughout the layers while maintaining model performance on previous tasks. In particular, we study CL performance's relationship with information flow in the network to answer the question "How can knowledge of information flow between layers be used to alleviate CF?". Our analysis provides novel insights of information adaptation within the layers during the incremental task learning process. Through our experiments, we provide empirical evidence and practically highlight the performance improvement across multiple tasks.
Goal-guided Transformer-enabled Reinforcement Learning for Efficient Autonomous Navigation
Jan 01, 2023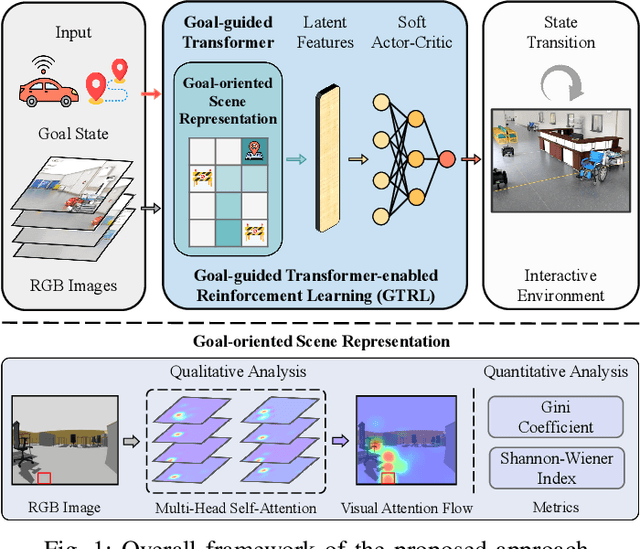
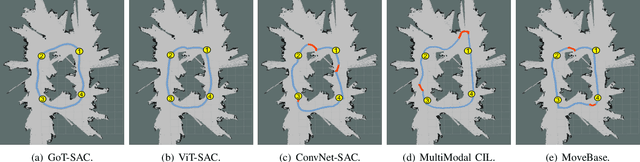
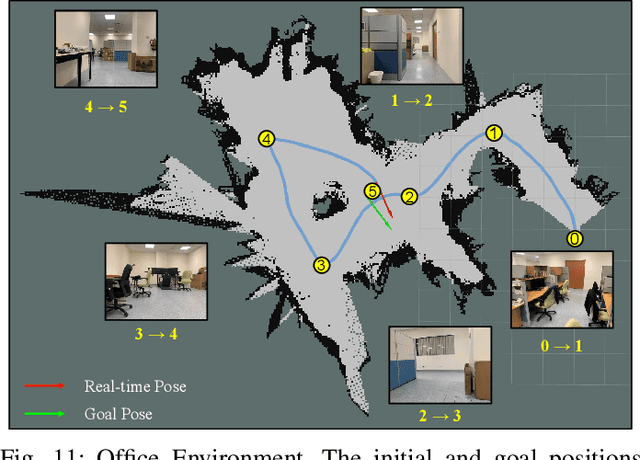
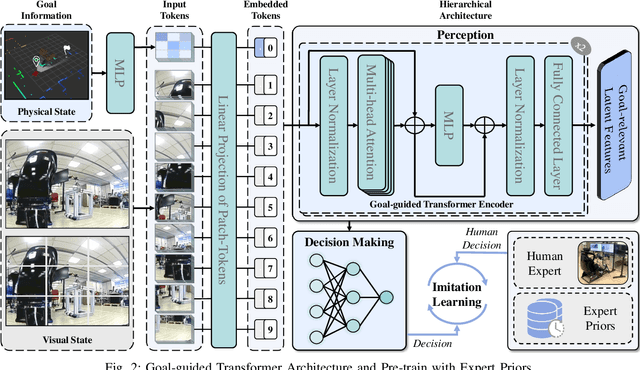
Despite some successful applications of goal-driven navigation, existing deep reinforcement learning-based approaches notoriously suffers from poor data efficiency issue. One of the reasons is that the goal information is decoupled from the perception module and directly introduced as a condition of decision-making, resulting in the goal-irrelevant features of the scene representation playing an adversary role during the learning process. In light of this, we present a novel Goal-guided Transformer-enabled reinforcement learning (GTRL) approach by considering the physical goal states as an input of the scene encoder for guiding the scene representation to couple with the goal information and realizing efficient autonomous navigation. More specifically, we propose a novel variant of the Vision Transformer as the backbone of the perception system, namely Goal-guided Transformer (GoT), and pre-train it with expert priors to boost the data efficiency. Subsequently, a reinforcement learning algorithm is instantiated for the decision-making system, taking the goal-oriented scene representation from the GoT as the input and generating decision commands. As a result, our approach motivates the scene representation to concentrate mainly on goal-relevant features, which substantially enhances the data efficiency of the DRL learning process, leading to superior navigation performance. Both simulation and real-world experimental results manifest the superiority of our approach in terms of data efficiency, performance, robustness, and sim-to-real generalization, compared with other state-of-art baselines. Demonstration videos are available at \colorb{https://youtu.be/93LGlGvaN0c.