 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
PCCC: The Pairwise-Confidence-Constraints-Clustering Algorithm
Dec 29, 2022
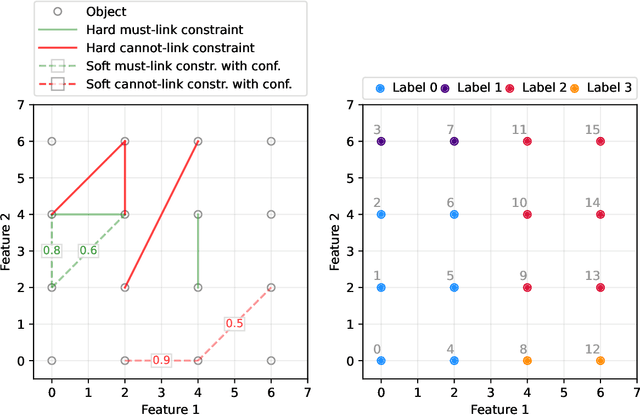
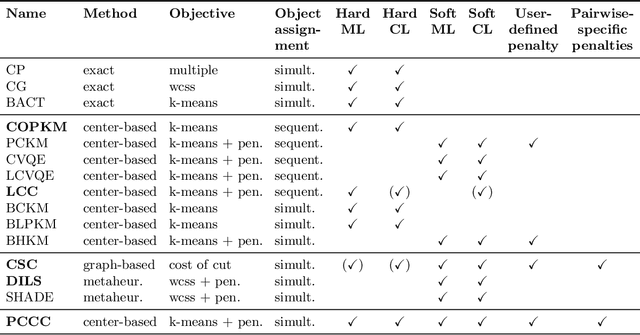
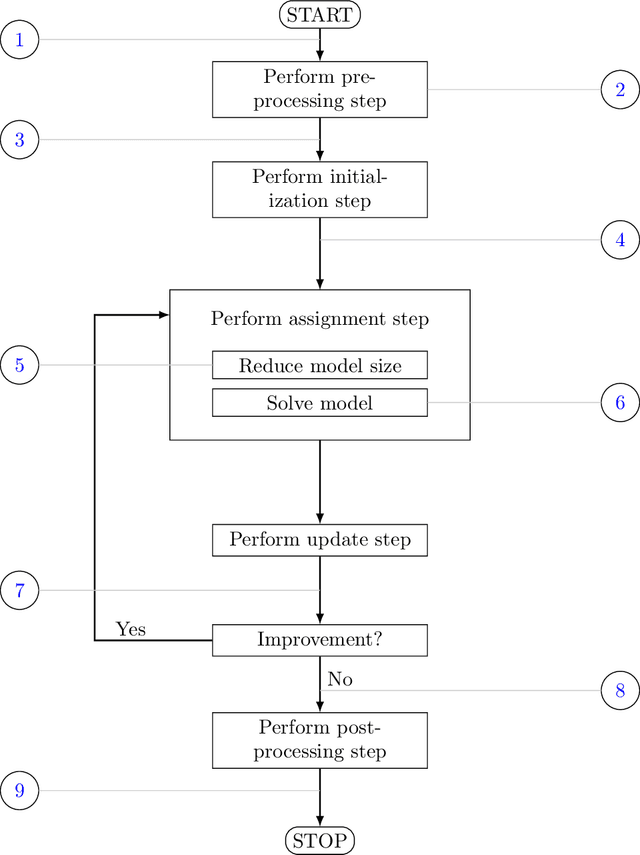
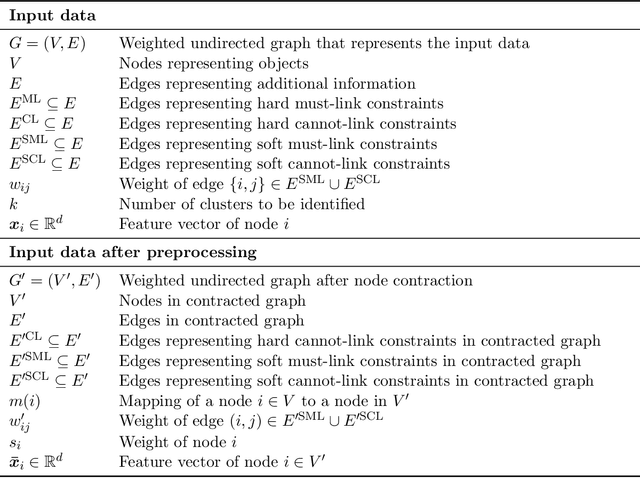
We consider a semi-supervised $k$-clustering problem where information is available on whether pairs of objects are in the same or in different clusters. This information is either available with certainty or with a limited level of confidence. We introduce the PCCC algorithm, which iteratively assigns objects to clusters while accounting for the information provided on the pairs of objects. Our algorithm can include relationships as hard constraints that are guaranteed to be satisfied or as soft constraints that can be violated subject to a penalty. This flexibility distinguishes our algorithm from the state-of-the-art in which all pairwise constraints are either considered hard, or all are considered soft. Unlike existing algorithms, our algorithm scales to large-scale instances with up to 60,000 objects, 100 clusters, and millions of cannot-link constraints (which are the most challenging constraints to incorporate). We compare the PCCC algorithm with state-of-the-art approaches in an extensive computational study. Even though the PCCC algorithm is more general than the state-of-the-art approaches in its applicability, it outperforms the state-of-the-art approaches on instances with all hard constraints or all soft constraints both in terms of running time and various metrics of solution quality. The source code of the PCCC algorithm is publicly available on GitHub.
Deterministic-Random Tradeoff of Integrated Sensing and Communications in Gaussian Channels: A Rate-Distortion Perspective
Jan 04, 2023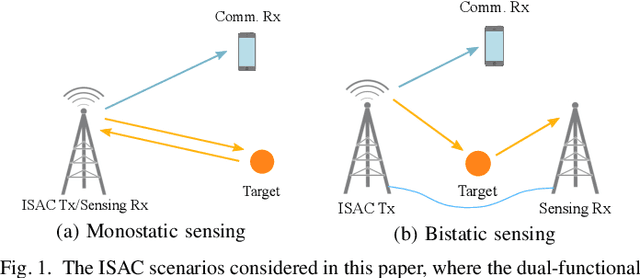
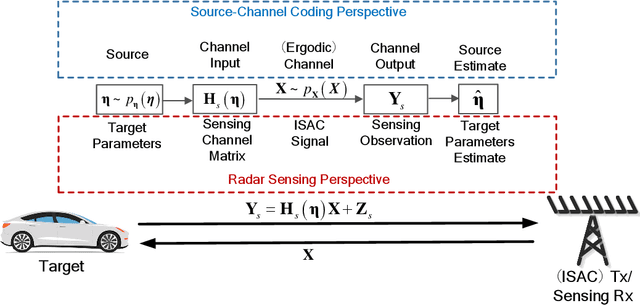
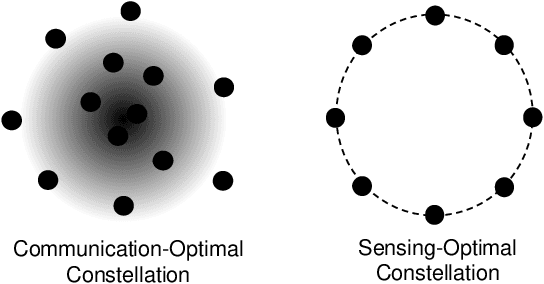
Integrated sensing and communications (ISAC) is recognized as a key enabling technology for future wireless networks. To shed light on the fundamental performance limits of ISAC systems, this paper studies the deterministic-random tradeoff between sensing and communications (S&C) from a rate-distortion perspective under vector Gaussian channels. We model the ISAC signal as a random matrix that carries information, whose realization is perfectly known to the sensing receiver, but is unknown to the communication receiver. We characterize the sensing mutual information conditioned on the random ISAC signal, and show that it provides a universal lower bound for distortion metrics of sensing. Furthermore, we prove that the distortion lower bound is minimized if the sample covariance matrix of the ISAC signal is deterministic. We then offer our understanding of the main results by interpreting wireless sensing as non-cooperative source-channel coding, and reveal the deterministic-random tradeoff of S&C for ISAC systems. Finally, we provide sufficient conditions for the achievability of the distortion bound by analyzing a specific example of target response matrix estimation.
Learning Ambiguity from Crowd Sequential Annotations
Jan 04, 2023
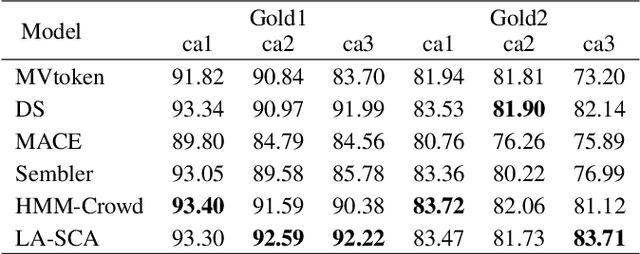
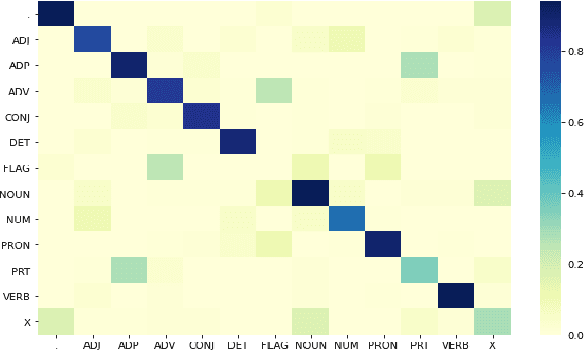
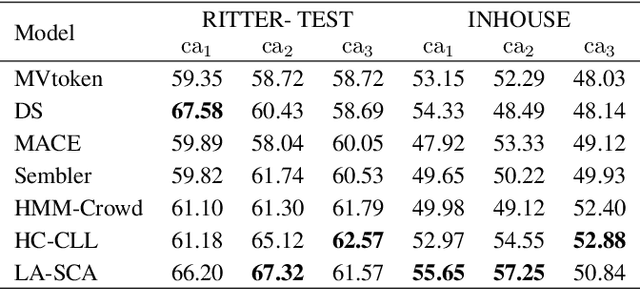
Most crowdsourcing learning methods treat disagreement between annotators as noisy labelings while inter-disagreement among experts is often a good indicator for the ambiguity and uncertainty that is inherent in natural language. In this paper, we propose a framework called Learning Ambiguity from Crowd Sequential Annotations (LA-SCA) to explore the inter-disagreement between reliable annotators and effectively preserve confusing label information. First, a hierarchical Bayesian model is developed to infer ground-truth from crowds and group the annotators with similar reliability together. By modeling the relationship between the size of group the annotator involved in, the annotator's reliability and element's unambiguity in each sequence, inter-disagreement between reliable annotators on ambiguous elements is computed to obtain label confusing information that is incorporated to cost-sensitive sequence labeling. Experimental results on POS tagging and NER tasks show that our proposed framework achieves competitive performance in inferring ground-truth from crowds and predicting unknown sequences, and interpreting hierarchical clustering results helps discover labeling patterns of annotators with similar reliability.
Knowledge Enhancement for Multi-Behavior Contrastive Recommendation
Jan 13, 2023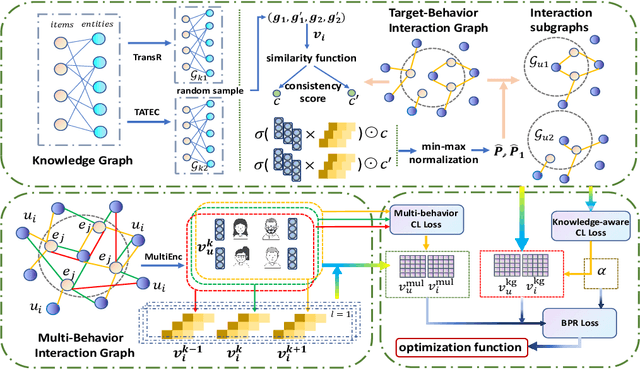


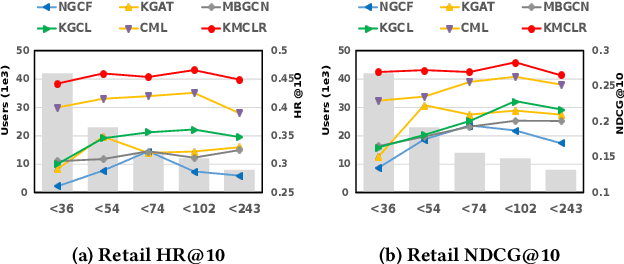
A well-designed recommender system can accurately capture the attributes of users and items, reflecting the unique preferences of individuals. Traditional recommendation techniques usually focus on modeling the singular type of behaviors between users and items. However, in many practical recommendation scenarios (e.g., social media, e-commerce), there exist multi-typed interactive behaviors in user-item relationships, such as click, tag-as-favorite, and purchase in online shopping platforms. Thus, how to make full use of multi-behavior information for recommendation is of great importance to the existing system, which presents challenges in two aspects that need to be explored: (1) Utilizing users' personalized preferences to capture multi-behavioral dependencies; (2) Dealing with the insufficient recommendation caused by sparse supervision signal for target behavior. In this work, we propose a Knowledge Enhancement Multi-Behavior Contrastive Learning Recommendation (KMCLR) framework, including two Contrastive Learning tasks and three functional modules to tackle the above challenges, respectively. In particular, we design the multi-behavior learning module to extract users' personalized behavior information for user-embedding enhancement, and utilize knowledge graph in the knowledge enhancement module to derive more robust knowledge-aware representations for items. In addition, in the optimization stage, we model the coarse-grained commonalities and the fine-grained differences between multi-behavior of users to further improve the recommendation effect. Extensive experiments and ablation tests on the three real-world datasets indicate our KMCLR outperforms various state-of-the-art recommendation methods and verify the effectiveness of our method.
Sum-of-Squares Relaxations for Information Theory and Variational Inference
Jun 27, 2022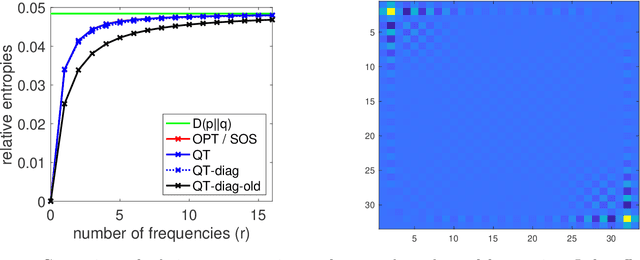
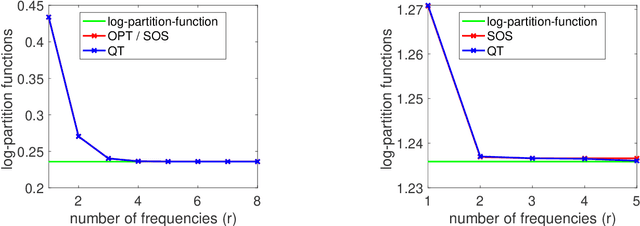
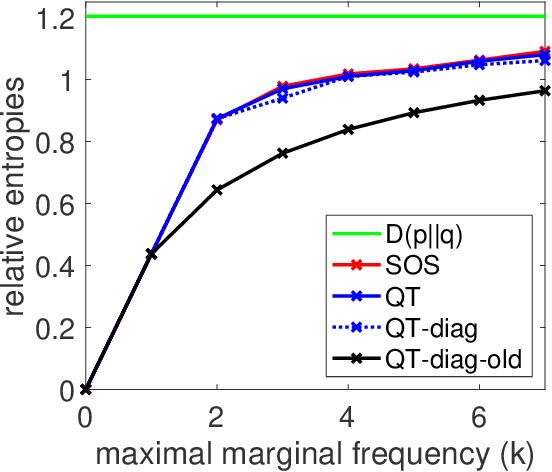
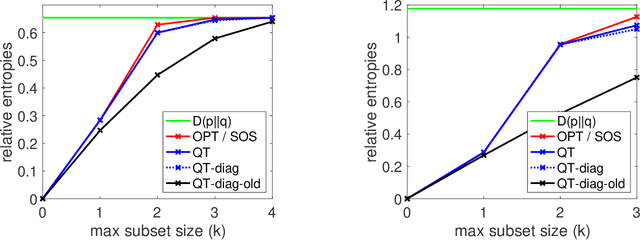
We consider extensions of the Shannon relative entropy, referred to as f-divergences. Three classical related computational problems are typically associated with these divergences: (a) estimation from moments, (b) computing normalizing integrals, and (c) variational inference in probabilistic models. These problems are related to one another through convex duality, and for all them, there are many applications throughout data science, and we aim for computationally tractable approximation algorithms that preserve properties of the original problem such as potential convexity or monotonicity. In order to achieve this, we derive a sequence of convex relaxations for computing these divergences from non-centered covariance matrices associated with a given feature vector: starting from the typically non-tractable optimal lower-bound, we consider an additional relaxation based on ''sums-of-squares'', which is is now computable in polynomial time as a semidefinite program, as well as further computationally more efficient relaxations based on spectral information divergences from quantum information theory. For all of the tasks above, beyond proposing new relaxations, we derive tractable algorithms based on augmented Lagrangians and first-order methods, and we present illustrations on multivariate trigonometric polynomials and functions on the Boolean hypercube.
Energy-Efficient Task Offloading for Semantic-Aware Networks
Jan 20, 2023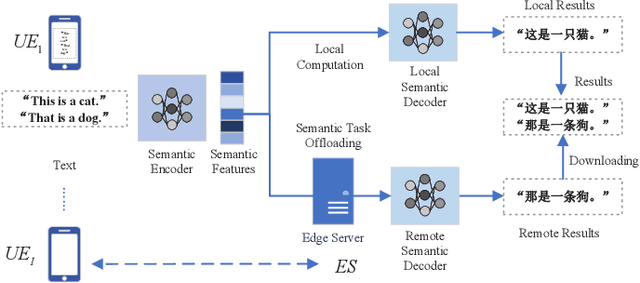
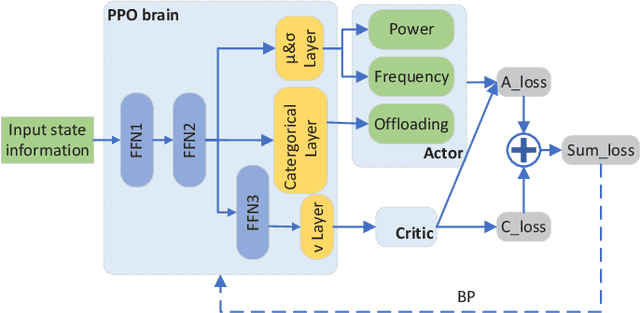
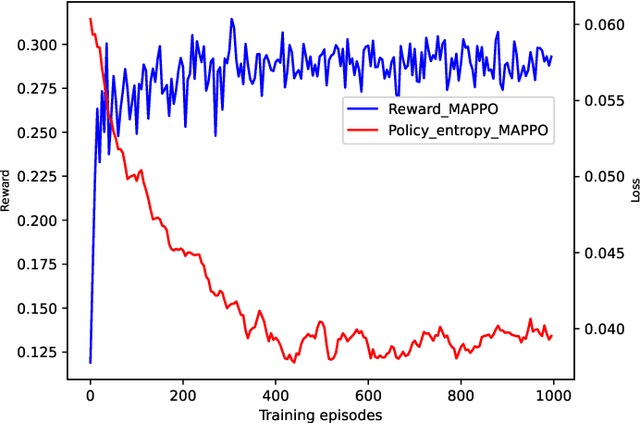
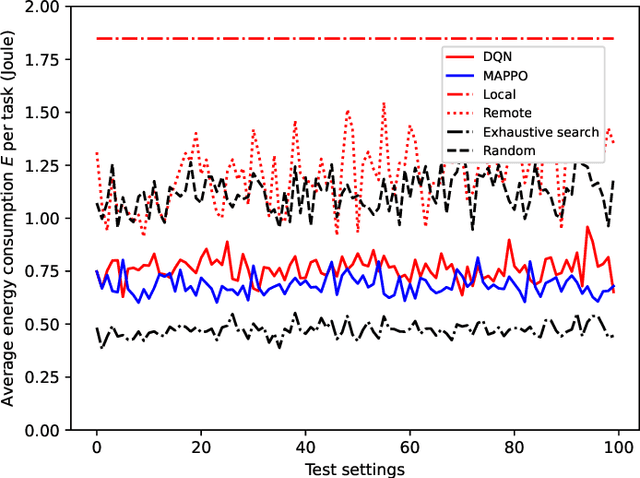
The limited computation capacity of user equipments restricts the local implementation of computation-intense applications. Edge computing, especially the edge intelligence system enables local users to offload the computation tasks to the edge servers for reducing the computational energy consumption of user equipments and fast task execution. However, the limited bandwidth of upstream channels may increase the task transmission latency and affect the computation offloading performance. To overcome the challenge of the limited resource of wireless communications, we adopt a semantic-aware task offloading system, where the semantic information of tasks are extracted and offloaded to the edge servers. Furthermore, a proximal policy optimization based multi-agent reinforcement learning algorithm (MAPPO) is proposed to coordinate the resource of wireless communications and the computation, so that the resource management can be performed distributedly and the computational complexity of the online algorithm can be reduced.
Reduce Information Loss in Transformers for Pluralistic Image Inpainting
May 15, 2022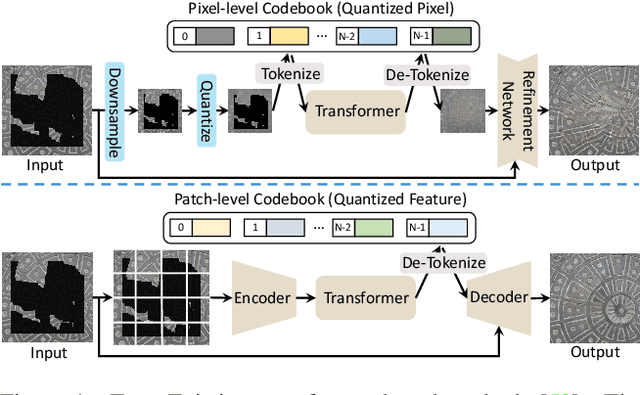
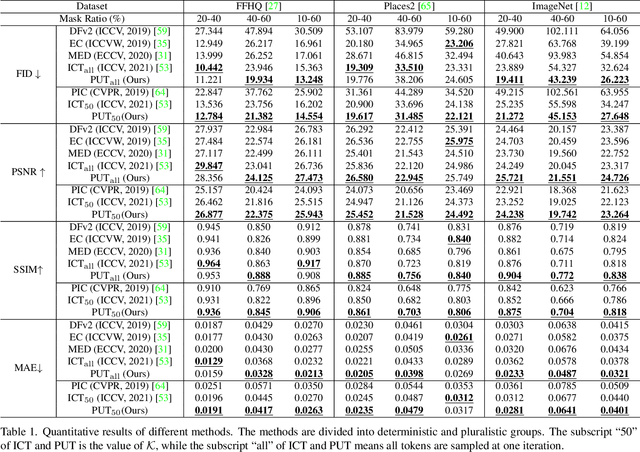
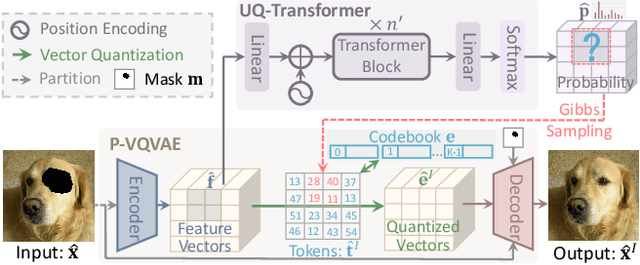

Transformers have achieved great success in pluralistic image inpainting recently. However, we find existing transformer based solutions regard each pixel as a token, thus suffer from information loss issue from two aspects: 1) They downsample the input image into much lower resolutions for efficiency consideration, incurring information loss and extra misalignment for the boundaries of masked regions. 2) They quantize $256^3$ RGB pixels to a small number (such as 512) of quantized pixels. The indices of quantized pixels are used as tokens for the inputs and prediction targets of transformer. Although an extra CNN network is used to upsample and refine the low-resolution results, it is difficult to retrieve the lost information back.To keep input information as much as possible, we propose a new transformer based framework "PUT". Specifically, to avoid input downsampling while maintaining the computation efficiency, we design a patch-based auto-encoder P-VQVAE, where the encoder converts the masked image into non-overlapped patch tokens and the decoder recovers the masked regions from inpainted tokens while keeping the unmasked regions unchanged. To eliminate the information loss caused by quantization, an Un-Quantized Transformer (UQ-Transformer) is applied, which directly takes the features from P-VQVAE encoder as input without quantization and regards the quantized tokens only as prediction targets. Extensive experiments show that PUT greatly outperforms state-of-the-art methods on image fidelity, especially for large masked regions and complex large-scale datasets. Code is available at https://github.com/liuqk3/PUT
Probabilistic Neural Data Fusion for Learning from an Arbitrary Number of Multi-fidelity Data Sets
Jan 30, 2023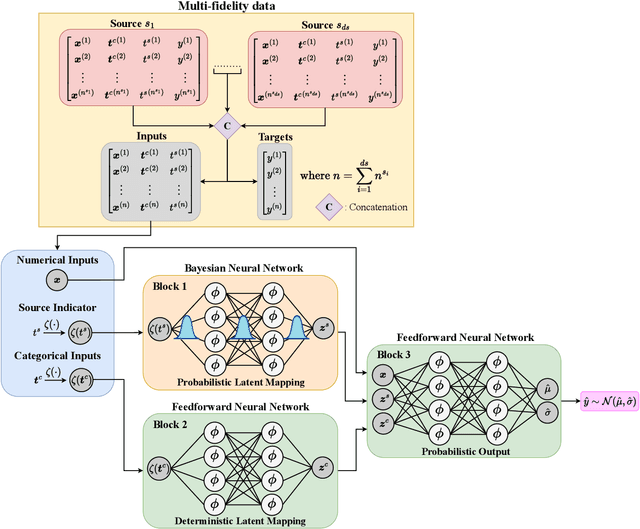
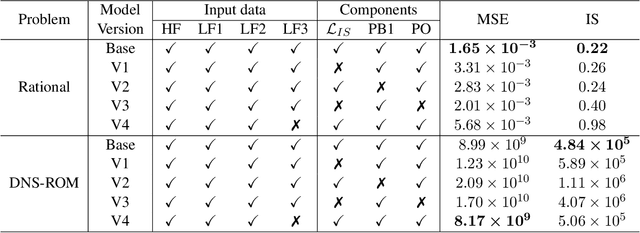
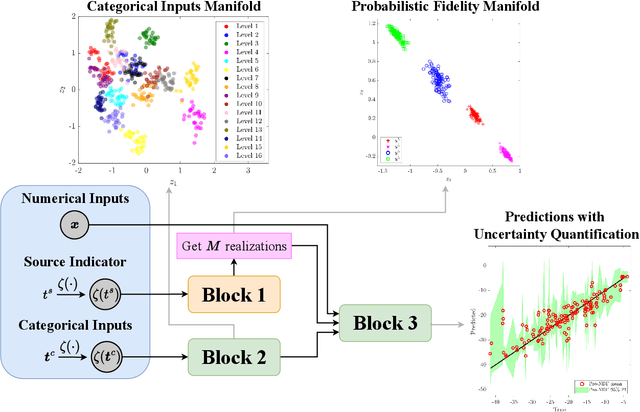
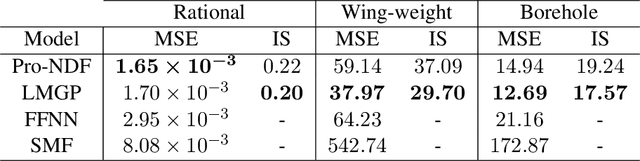
In many applications in engineering and sciences analysts have simultaneous access to multiple data sources. In such cases, the overall cost of acquiring information can be reduced via data fusion or multi-fidelity (MF) modeling where one leverages inexpensive low-fidelity (LF) sources to reduce the reliance on expensive high-fidelity (HF) data. In this paper, we employ neural networks (NNs) for data fusion in scenarios where data is very scarce and obtained from an arbitrary number of sources with varying levels of fidelity and cost. We introduce a unique NN architecture that converts MF modeling into a nonlinear manifold learning problem. Our NN architecture inversely learns non-trivial (e.g., non-additive and non-hierarchical) biases of the LF sources in an interpretable and visualizable manifold where each data source is encoded via a low-dimensional distribution. This probabilistic manifold quantifies model form uncertainties such that LF sources with small bias are encoded close to the HF source. Additionally, we endow the output of our NN with a parametric distribution not only to quantify aleatoric uncertainties, but also to reformulate the network's loss function based on strictly proper scoring rules which improve robustness and accuracy on unseen HF data. Through a set of analytic and engineering examples, we demonstrate that our approach provides a high predictive power while quantifying various sources uncertainties.
BSSAD: Towards A Novel Bayesian State-Space Approach for Anomaly Detection in Multivariate Time Series
Jan 30, 2023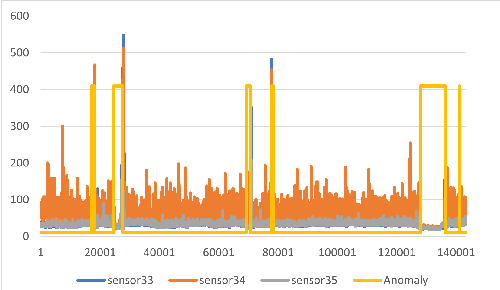
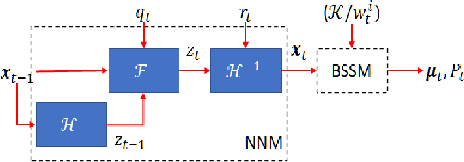
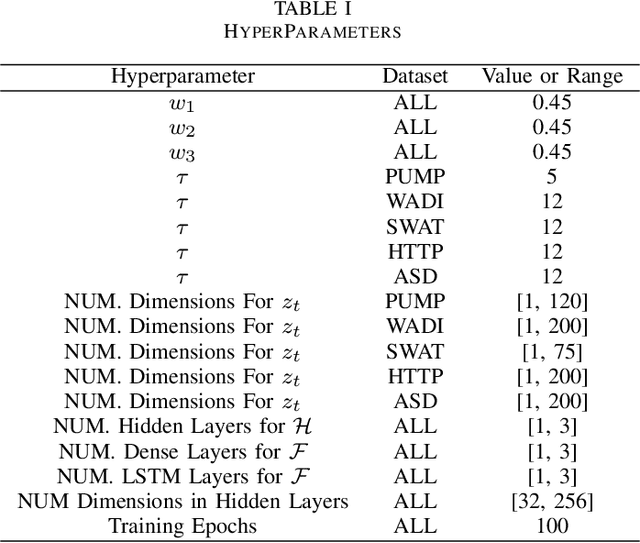
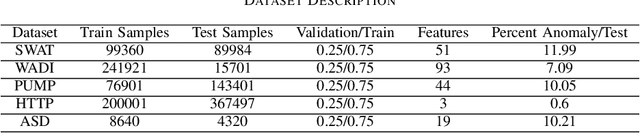
Detecting anomalies in multivariate time series(MTS) data plays an important role in many domains. The abnormal values could indicate events, medical abnormalities,cyber-attacks, or faulty devices which if left undetected could lead to significant loss of resources, capital, or human lives. In this paper, we propose a novel and innovative approach to anomaly detection called Bayesian State-Space Anomaly Detection(BSSAD). The BSSAD consists of two modules: the neural network module and the Bayesian state-space module. The design of our approach combines the strength of Bayesian state-space algorithms in predicting the next state and the effectiveness of recurrent neural networks and autoencoders in understanding the relationship between the data to achieve high accuracy in detecting anomalies. The modular design of our approach allows flexibility in implementation with the option of changing the parameters of the Bayesian state-space models or swap-ping neural network algorithms to achieve different levels of performance. In particular, we focus on using Bayesian state-space models of particle filters and ensemble Kalman filters. We conducted extensive experiments on five different datasets. The experimental results show the superior performance of our model over baselines, achieving an F1-score greater than 0.95. In addition, we also propose using a metric called MatthewCorrelation Coefficient (MCC) to obtain more comprehensive information about the accuracy of anomaly detection.
The Optimal Choice of Hypothesis Is the Weakest, Not the Shortest
Jan 30, 2023

If $A$ and $B$ are sets such that $A \subset B$, generalisation may be understood as the inference from $A$ of a hypothesis sufficient to construct $B$. One might infer any number of hypotheses from $A$, yet only some of those may generalise to $B$. How can one know which are likely to generalise? One strategy is to choose the shortest, equating the ability to compress information with the ability to generalise (a proxy for intelligence). We examine this in the context of a mathematical formalism of enactive cognition. We show that compression is neither necessary nor sufficient to maximise performance (measured in terms of the probability of a hypothesis generalising). We formulate a proxy unrelated to length or simplicity, called weakness. We show that if tasks are uniformly distributed, then there is no choice of proxy that performs at least as well as weakness maximisation in all tasks while performing strictly better in at least one. In other words, weakness is the pareto optimal choice of proxy. In experiments comparing maximum weakness and minimum description length in the context of binary arithmetic, the former generalised at between $1.1$ and $5$ times the rate of the latter. We argue this demonstrates that weakness is a far better proxy, and explains why Deepmind's Apperception Engine is able to generalise effectively.