 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
OTFS Signaling for SCMA With Coordinated Multi-Point Vehicle Communications
Feb 17, 2023
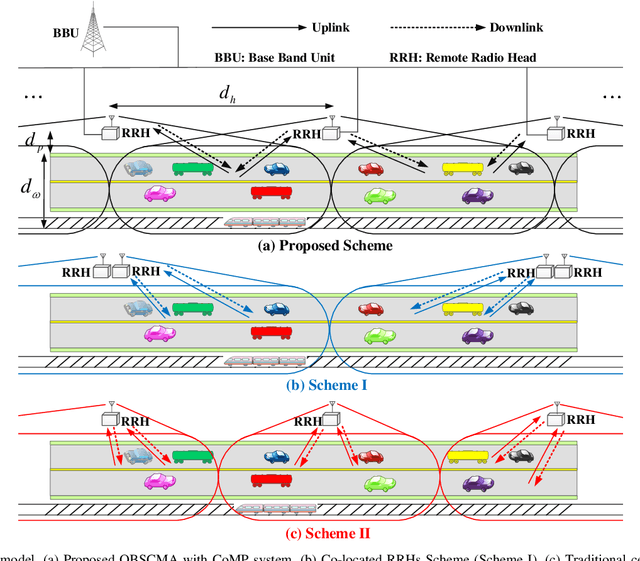
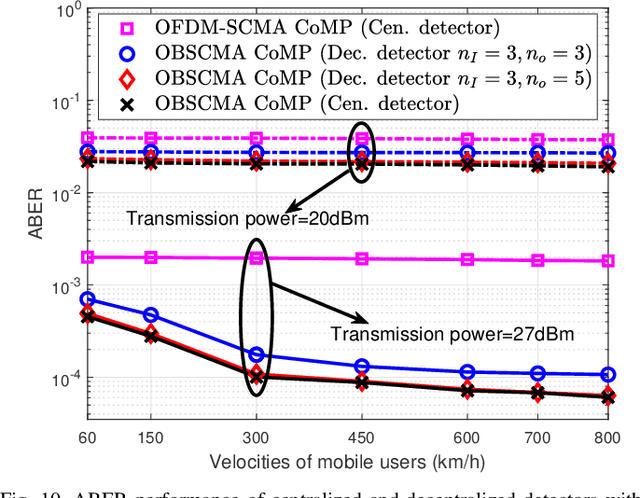
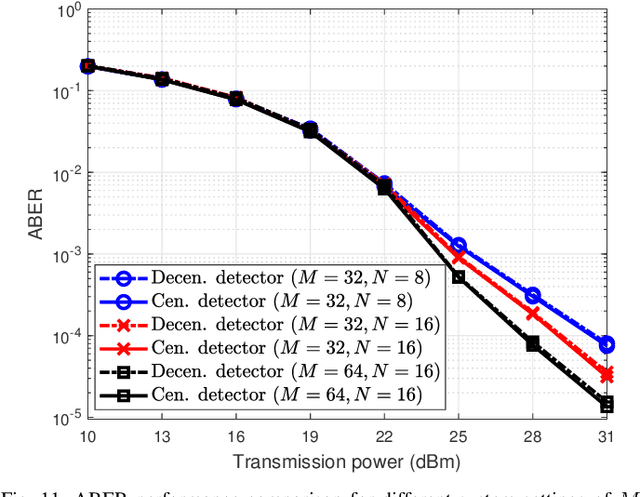

This paper investigates an uplink coordinated multi-point (CoMP) coverage scenario, in which multiple mobile users are grouped for sparse code multiple access (SCMA), and served by the remote radio head (RRH) in front of them and the RRH behind them simultaneously. We apply orthogonal time frequency space (OTFS) modulation for each user to exploit the degrees of freedom arising from both the delay and Doppler domains. As the signals received by the RRHs in front of and behind the users experience respectively positive and negative Doppler frequency shifts, our proposed OTFS-based SCMA (OBSCMA) with CoMP system can effectively harvest extra Doppler and spatial diversity for better performance. Based on maximum likelihood (ML) detector, we analyze the single-user average bit error rate (ABER) bound as the benchmark of the ABER performance for our proposed OBSCMA with CoMP system. We also develop a customized Gaussian approximation with expectation propagation (GAEP) algorithm for multi-user detection and propose efficient algorithm structures for centralized and decentralized detectors. Our proposed OBSCMA with CoMP system leads to stronger performance than the existing solutions. The proposed centralized and decentralized detectors exhibit effective reception and robustness under channel state information uncertainty.
More Data Types More Problems: A Temporal Analysis of Complexity, Stability, and Sensitivity in Privacy Policies
Feb 17, 2023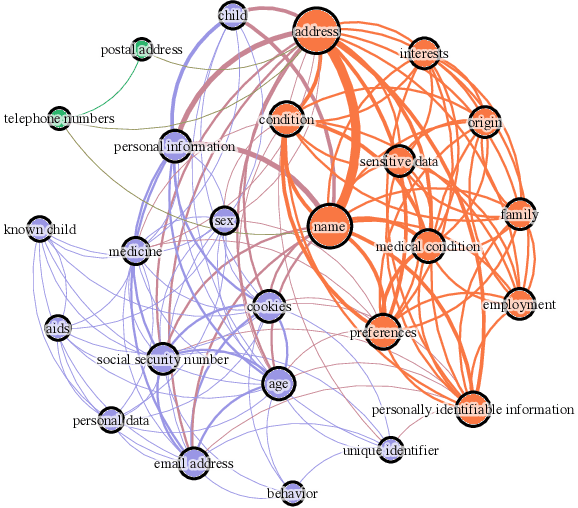
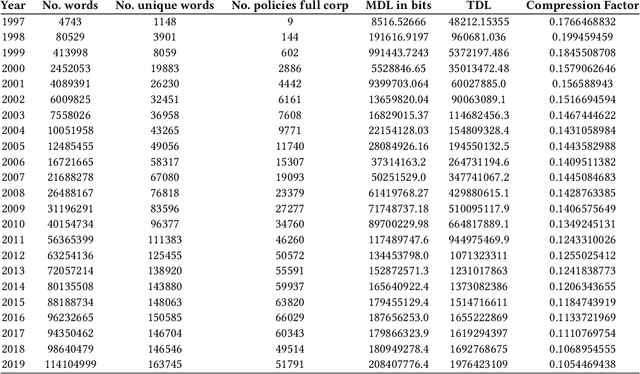

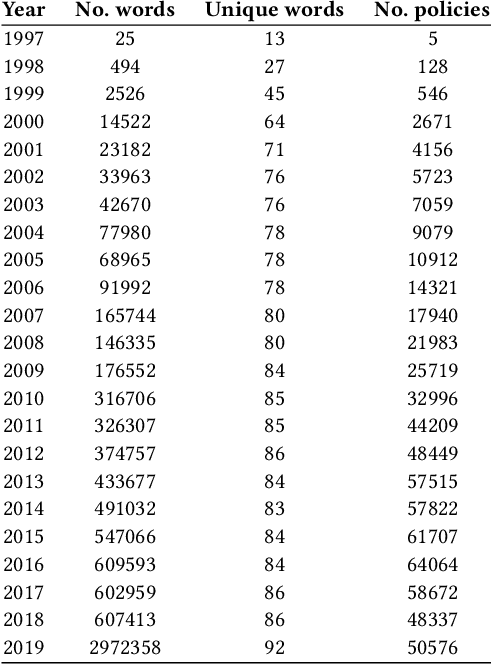
Collecting personally identifiable information (PII) on data subjects has become big business. Data brokers and data processors are part of a multi-billion-dollar industry that profits from collecting, buying, and selling consumer data. Yet there is little transparency in the data collection industry which makes it difficult to understand what types of data are being collected, used, and sold, and thus the risk to individual data subjects. In this study, we examine a large textual dataset of privacy policies from 1997-2019 in order to investigate the data collection activities of data brokers and data processors. We also develop an original lexicon of PII-related terms representing PII data types curated from legislative texts. This mesoscale analysis looks at privacy policies overtime on the word, topic, and network levels to understand the stability, complexity, and sensitivity of privacy policies over time. We find that (1) privacy legislation correlates with changes in stability and turbulence of PII data types in privacy policies; (2) the complexity of privacy policies decreases over time and becomes more regularized; (3) sensitivity rises over time and shows spikes that are correlated with events when new privacy legislation is introduced.
A Quantitative Exploration of Natural Language Processing Applications for Electricity Demand Analysis
Jan 18, 2023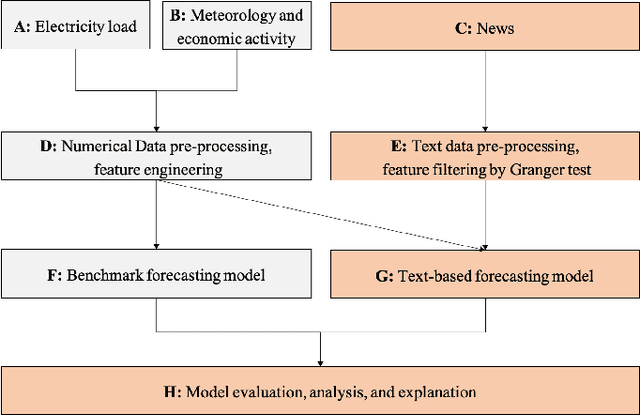
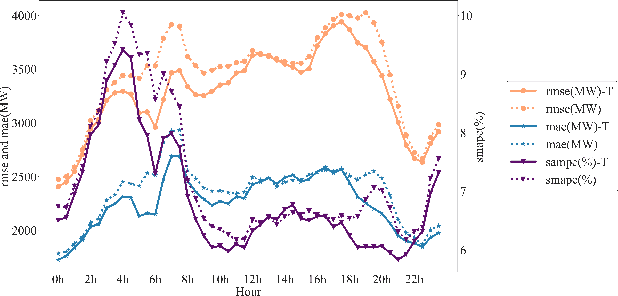
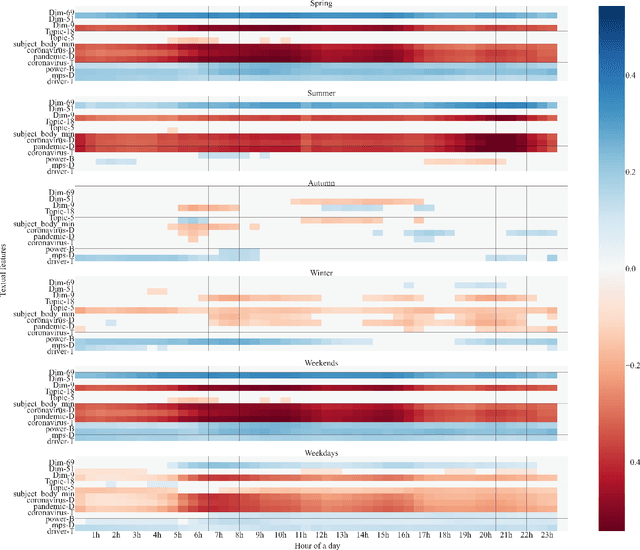
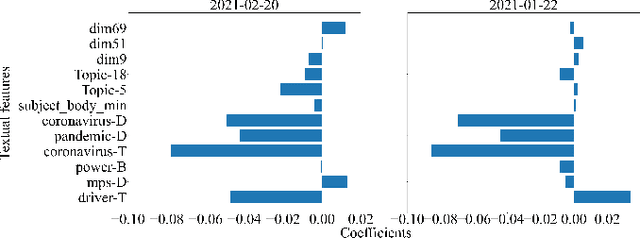
The relationship between electricity demand and weather has been established for a long time and is one of the cornerstones in load prediction for operation and planning, along with behavioral and social aspects such as calendars or significant events. This paper explores how and why the social information contained in the news can be used better to understand aggregate population behaviour in terms of energy demand. The work is done through experiments analysing the impact of predicting features extracted from national news on day-ahead electric demand prediction. The results are compared to a benchmark model trained exclusively on the calendar and meteorological information. Experimental results showed that the best-performing model reduced the official standard errors around 4%, 11%, and 10% in terms of RMSE, MAE, and SMAPE. The best-performing methods are: word frequency identified COVID-19-related keywords; topic distribution that identified news on the pandemic and internal politics; global word embeddings that identified news about international conflicts. This study brings a new perspective to traditional electricity demand analysis and confirms the feasibility of improving its predictions with unstructured information contained in texts, with potential consequences in sociology and economics.
Contrastive Learning and the Emergence of Attributes Associations
Feb 12, 2023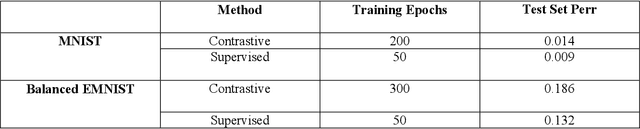
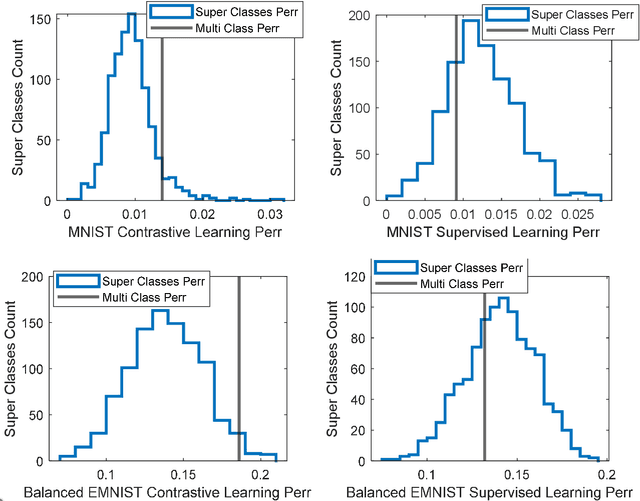
In response to an object presentation, supervised learning schemes generally respond with a parsimonious label. Upon a similar presentation we humans respond again with a label, but are flooded, in addition, by a myriad of associations. A significant portion of these consist of the presented object attributes. Contrastive learning is a semi-supervised learning scheme based on the application of identity preserving transformations on the object input representations. It is conjectured in this work that these same applied transformations preserve, in addition to the identity of the presented object, also the identity of its semantically meaningful attributes. The corollary of this is that the output representations of such a contrastive learning scheme contain valuable information not only for the classification of the presented object, but also for the presence or absence decision of any attribute of interest. Simulation results which demonstrate this idea and the feasibility of this conjecture are presented.
USER: Unsupervised Structural Entropy-based Robust Graph Neural Network
Feb 12, 2023
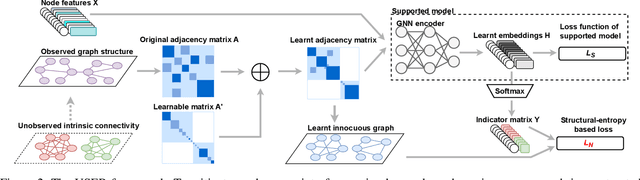
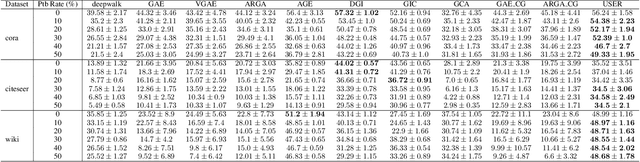
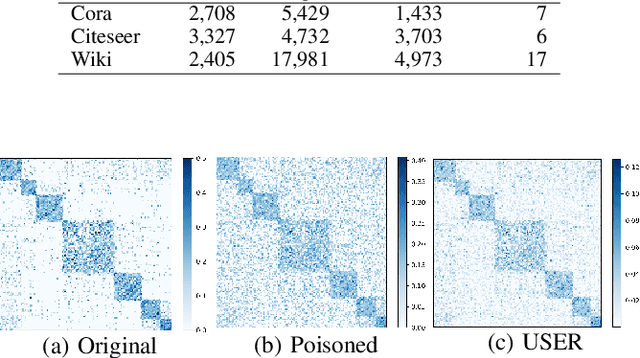
Unsupervised/self-supervised graph neural networks (GNN) are vulnerable to inherent randomness in the input graph data which greatly affects the performance of the model in downstream tasks. In this paper, we alleviate the interference of graph randomness and learn appropriate representations of nodes without label information. To this end, we propose USER, an unsupervised robust version of graph neural networks that is based on structural entropy. We analyze the property of intrinsic connectivity and define intrinsic connectivity graph. We also identify the rank of the adjacency matrix as a crucial factor in revealing a graph that provides the same embeddings as the intrinsic connectivity graph. We then introduce structural entropy in the objective function to capture such a graph. Extensive experiments conducted on clustering and link prediction tasks under random-noises and meta-attack over three datasets show USER outperforms benchmarks and is robust to heavier randomness.
A Neuromorphic Dataset for Object Segmentation in Indoor Cluttered Environment
Feb 13, 2023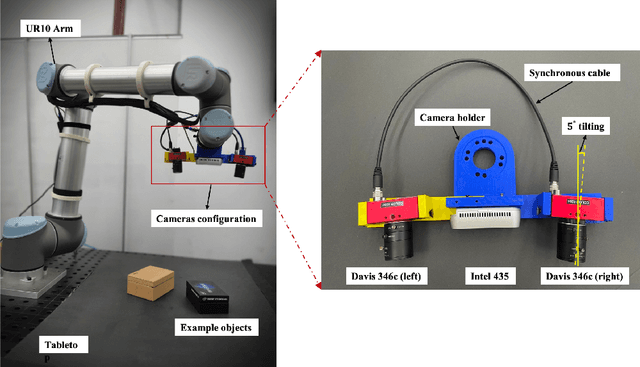
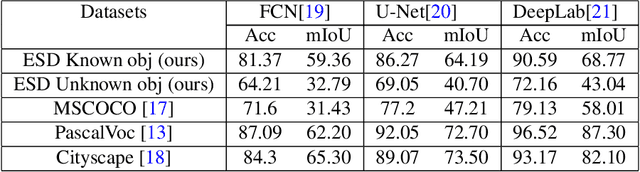
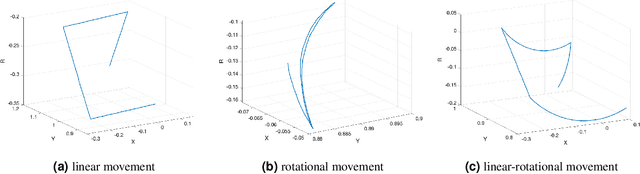

Taking advantage of an event-based camera, the issues of motion blur, low dynamic range and low time sampling of standard cameras can all be addressed. However, there is a lack of event-based datasets dedicated to the benchmarking of segmentation algorithms, especially those that provide depth information which is critical for segmentation in occluded scenes. This paper proposes a new Event-based Segmentation Dataset (ESD), a high-quality 3D spatial and temporal dataset for object segmentation in an indoor cluttered environment. Our proposed dataset ESD comprises 145 sequences with 14,166 RGB frames that are manually annotated with instance masks. Overall 21.88 million and 20.80 million events from two event-based cameras in a stereo-graphic configuration are collected, respectively. To the best of our knowledge, this densely annotated and 3D spatial-temporal event-based segmentation benchmark of tabletop objects is the first of its kind. By releasing ESD, we expect to provide the community with a challenging segmentation benchmark with high quality.
Deep Graph-Level Orthogonal Hypersphere Compression for Anomaly Detection
Feb 13, 2023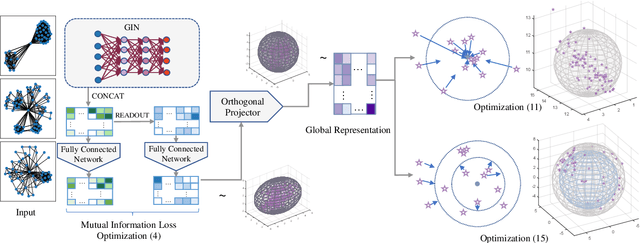
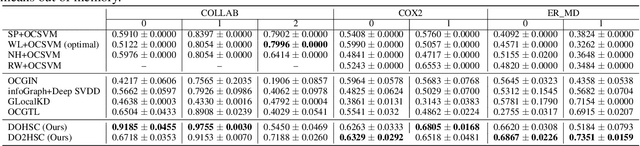
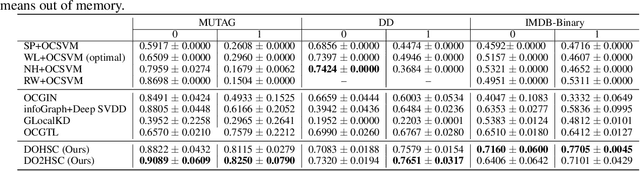
Graph-level anomaly detection aims to identify anomalous graphs from a collection of graphs in an unsupervised manner. A common assumption of anomaly detection is that a reasonable decision boundary has a hypersphere shape, but may appear some non-conforming phenomena in high dimensions. Towards this end, we firstly propose a novel deep graph-level anomaly detection model, which learns the graph representation with maximum mutual information between substructure and global structure features while exploring a hypersphere anomaly decision boundary. The idea is to ensure the training data distribution consistent with the decision hypersphere via an orthogonal projection layer. Moreover, we further perform the bi-hypersphere compression to emphasize the discrimination of anomalous graphs from normal graphs. Note that our method is not confined to graph data and is applicable to anomaly detection of other data such as images. The numerical and visualization results on benchmark datasets demonstrate the effectiveness and superiority of our methods in comparison to many baselines and state-of-the-arts.
Restoring the saturation response of a PMT using pulse-shape and artificial-neural-networks
Feb 13, 2023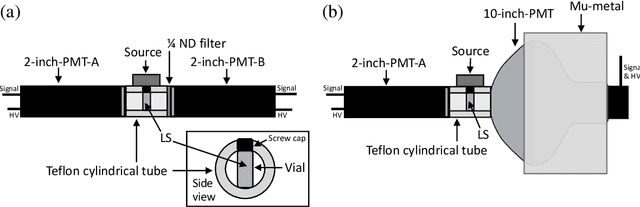
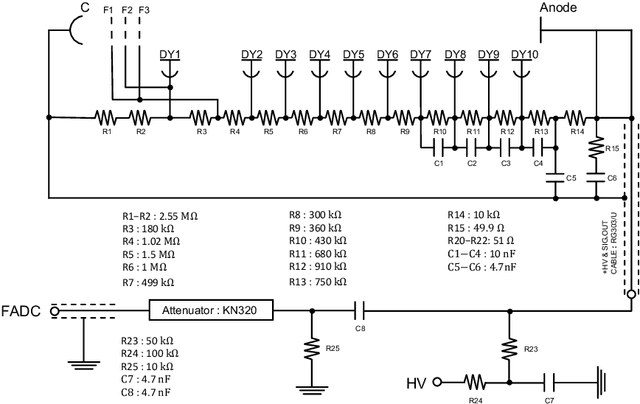
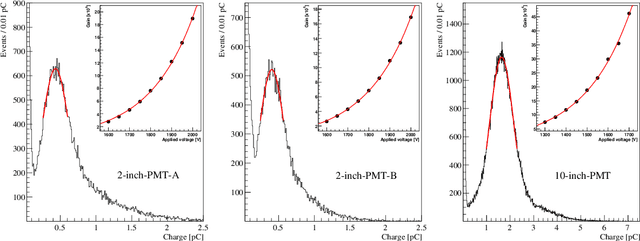
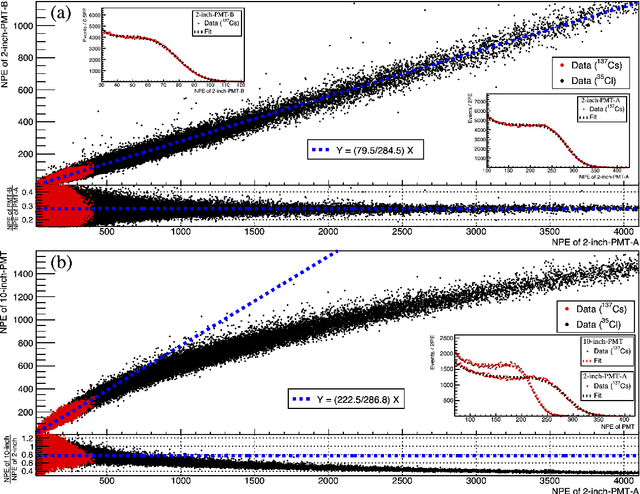
The linear response of a photomultiplier tube (PMT) is a required property for photon counting and reconstruction of the neutrino energy. The linearity valid region and the saturation response of PMT were investigated using a linear-alkyl-benzene (LAB)-based liquid scintillator. A correlation was observed between the two different saturation responses, with pulse-shape distortion and pulse-area decrease. The observed pulse-shape provides useful information for the estimation of the linearity region relative to the pulse-area. This correlation-based diagnosis allows an ${in}$-${situ}$ estimation of the linearity range, which was previously challenging. The measured correlation between the two saturation responses was employed to train an artificial-neural-network (ANN) to predict the decrease in pulse-area from the observed pulse-shape. The ANN-predicted pulse-area decrease enables the prediction of the ideal number of photoelectrons irrelevant to the saturation behavior. This pulse-shape-based machine learning technique offers a novel method for restoring the saturation response of PMTs.
Offline-to-Online Knowledge Distillation for Video Instance Segmentation
Feb 15, 2023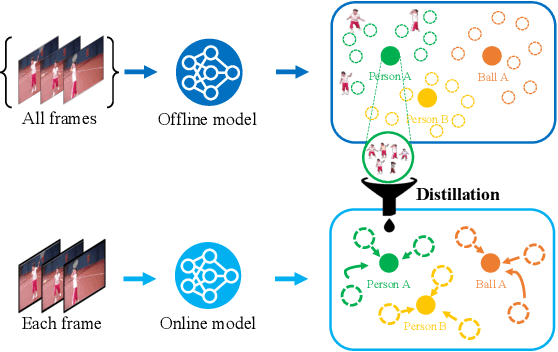
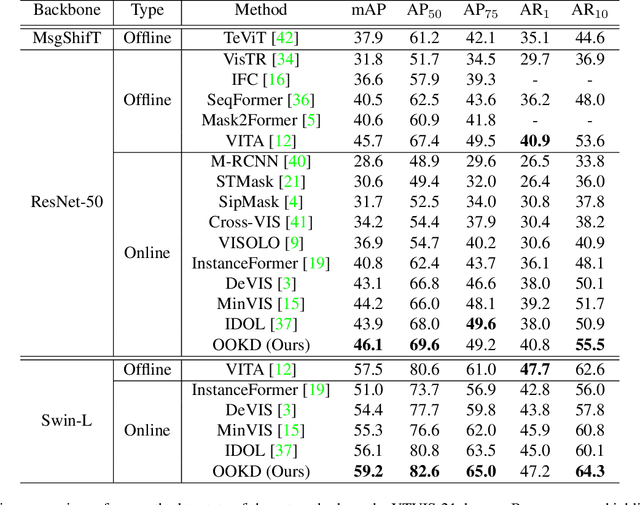

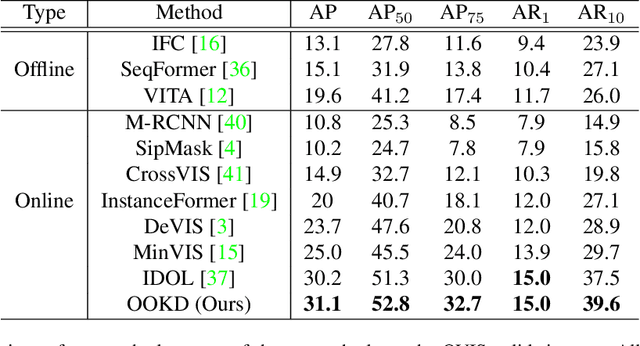
In this paper, we present offline-to-online knowledge distillation (OOKD) for video instance segmentation (VIS), which transfers a wealth of video knowledge from an offline model to an online model for consistent prediction. Unlike previous methods that having adopting either an online or offline model, our single online model takes advantage of both models by distilling offline knowledge. To transfer knowledge correctly, we propose query filtering and association (QFA), which filters irrelevant queries to exact instances. Our KD with QFA increases the robustness of feature matching by encoding object-centric features from a single frame supplemented by long-range global information. We also propose a simple data augmentation scheme for knowledge distillation in the VIS task that fairly transfers the knowledge of all classes into the online model. Extensive experiments show that our method significantly improves the performance in video instance segmentation, especially for challenging datasets including long, dynamic sequences. Our method also achieves state-of-the-art performance on YTVIS-21, YTVIS-22, and OVIS datasets, with mAP scores of 46.1%, 43.6%, and 31.1%, respectively.
Similarity, Compression and Local Steps: Three Pillars of Efficient Communications for Distributed Variational Inequalities
Feb 15, 2023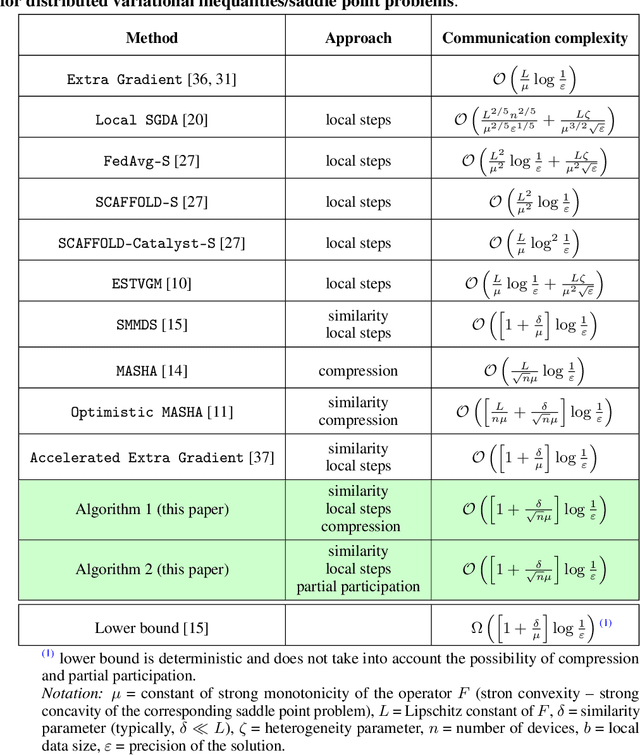
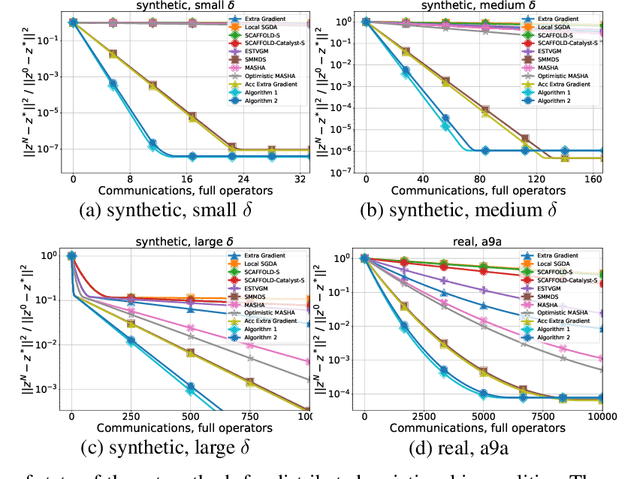
Variational inequalities are a broad and flexible class of problems that includes minimization, saddle point, fixed point problems as special cases. Therefore, variational inequalities are used in a variety of applications ranging from equilibrium search to adversarial learning. Today's realities with the increasing size of data and models demand parallel and distributed computing for real-world machine learning problems, most of which can be represented as variational inequalities. Meanwhile, most distributed approaches has a significant bottleneck - the cost of communications. The three main techniques to reduce both the total number of communication rounds and the cost of one such round are the use of similarity of local functions, compression of transmitted information and local updates. In this paper, we combine all these approaches. Such a triple synergy did not exist before for variational inequalities and saddle problems, nor even for minimization problems. The methods presented in this paper have the best theoretical guarantees of communication complexity and are significantly ahead of other methods for distributed variational inequalities. The theoretical results are confirmed by adversarial learning experiments on synthetic and real datasets.