 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models Understanding: an Inherent Ambiguity Barrier
May 01, 2025A lively ongoing debate is taking place, since the extraordinary emergence of Large Language Models (LLMs) with regards to their capability to understand the world and capture the meaning of the dialogues in which they are involved. Arguments and counter-arguments have been proposed based upon thought experiments, anecdotal conversations between LLMs and humans, statistical linguistic analysis, philosophical considerations, and more. In this brief paper we present a counter-argument based upon a thought experiment and semi-formal considerations leading to an inherent ambiguity barrier which prevents LLMs from having any understanding of what their amazingly fluent dialogues mean.
Contrastive Learning and Abstract Concepts: The Case of Natural Numbers
Aug 05, 2024Contrastive Learning (CL) has been successfully applied to classification and other downstream tasks related to concrete concepts, such as objects contained in the ImageNet dataset. No attempts seem to have been made so far in applying this promising scheme to more abstract entities. A prominent example of these could be the concept of (discrete) Quantity. CL can be frequently interpreted as a self-supervised scheme guided by some profound and ubiquitous conservation principle (e.g. conservation of identity in object classification tasks). In this introductory work we apply a suitable conservation principle to the semi-abstract concept of natural numbers by which discrete quantities can be estimated or predicted. We experimentally show, by means of a toy problem, that contrastive learning can be trained to count at a glance with high accuracy both at human as well as at super-human ranges.. We compare this with the results of a trained-to-count at a glance supervised learning (SL) neural network scheme of similar architecture. We show that both schemes exhibit similar good performance on baseline experiments, where the distributions of the training and testing stages are equal. Importantly, we demonstrate that in some generalization scenarios, where training and testing distributions differ, CL boasts more robust and much better error performance.
Contrastive Learning and the Emergence of Attributes Associations
Mar 01, 2023In response to an object presentation, supervised learning schemes generally respond with a parsimonious label. Upon a similar presentation we humans respond again with a label, but are flooded, in addition, by a myriad of associations. A significant portion of these consist of the presented object attributes. Contrastive learning is a semi-supervised learning scheme based on the application of identity preserving transformations on the object input representations. It is conjectured in this work that these same applied transformations preserve, in addition to the identity of the presented object, also the identity of its semantically meaningful attributes. The corollary of this is that the output representations of such a contrastive learning scheme contain valuable information not only for the classification of the presented object, but also for the presence or absence decision of any attribute of interest. Simulation results which demonstrate this idea and the feasibility of this conjecture are presented.
A Simple Generative Network
Jul 07, 2021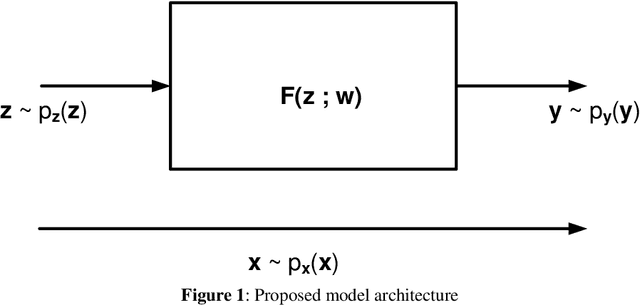
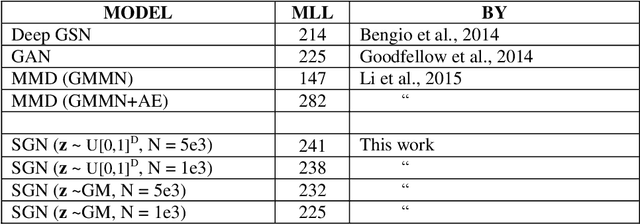

Generative neural networks are able to mimic intricate probability distributions such as those of handwritten text, natural images, etc. Since their inception several models were proposed. The most successful of these were based on adversarial (GAN), auto-encoding (VAE) and maximum mean discrepancy (MMD) relatively complex architectures and schemes. Surprisingly, a very simple architecture (a single feed-forward neural network) in conjunction with an obvious optimization goal (Kullback_Leibler divergence) was apparently overlooked. This paper demonstrates that such a model (denoted SGN for its simplicity) is able to generate samples visually and quantitatively competitive as compared with the fore-mentioned state of the art methods.
Unsupervisedly Learned Representations: Should the Quest be Over?
Jan 21, 2020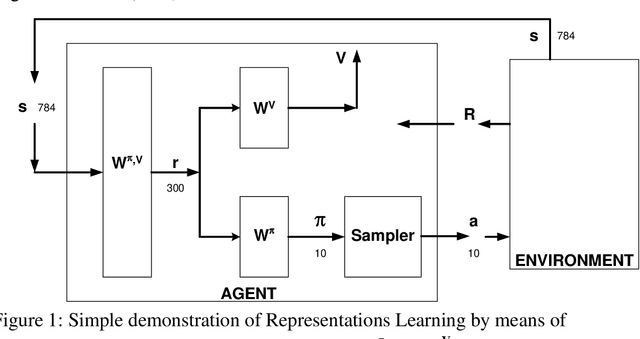
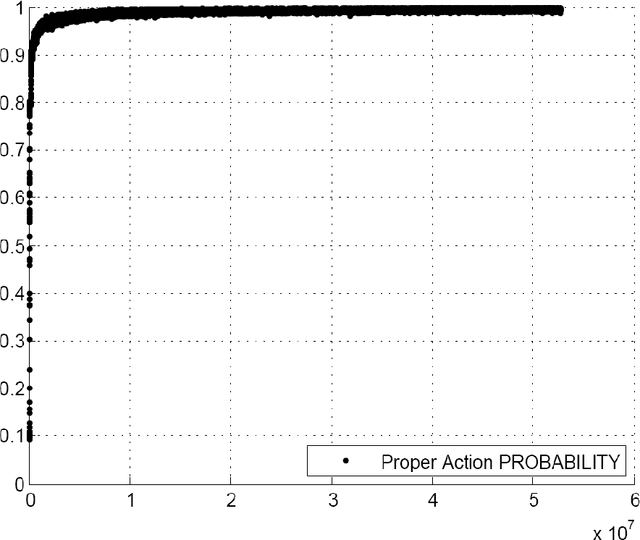
There exists a Classification accuracy gap of about 20% between our best methods of generating Unsupervisedly Learned Representations and the accuracy rates achieved by (naturally Unsupervisedly Learning) humans. We are at our fourth decade at least in search of this class of paradigms. It thus may well be that we are looking in the wrong direction. We present in this paper a possible solution to this puzzle. We demonstrate that Reinforcement Learning schemes can learn representations, which may be used for Pattern Recognition tasks such as Classification, achieving practically the same accuracy as that of humans. Our main modest contribution lies in the observations that: a. when applied to a real world environment (e.g. nature itself) Reinforcement Learning does not require labels, and thus may be considered a natural candidate for the long sought, accuracy competitive Unsupervised Learning method, and b. in contrast, when Reinforcement Learning is applied in a simulated or symbolic processing environment (e.g. a computer program) it does inherently require labels and should thus be generally classified, with some exceptions, as Supervised Learning. The corollary of these observations is that further search for Unsupervised Learning competitive paradigms which may be trained in simulated environments like many of those found in research and applications may be futile.
An Unsupervised Learning Classifier with Competitive Error Performance
Jul 04, 2018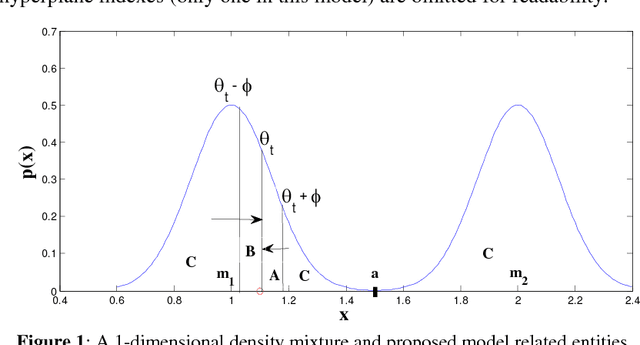
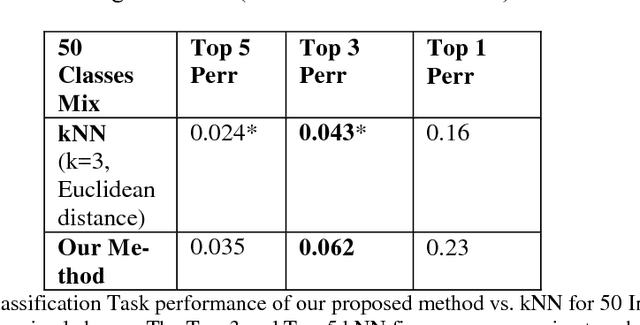
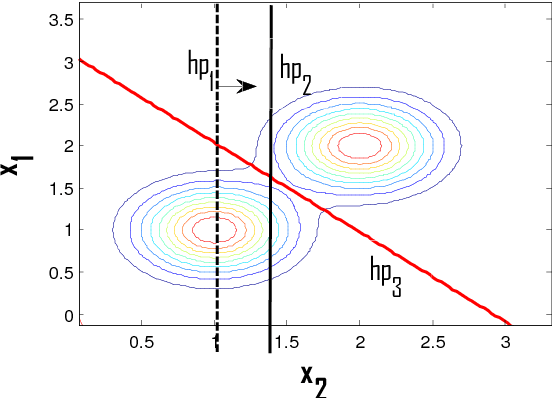
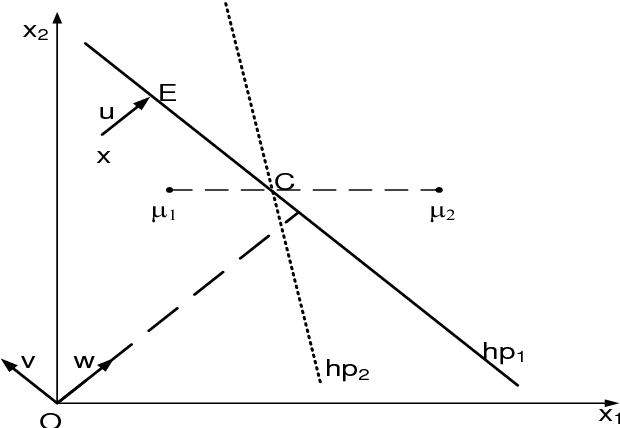
An unsupervised learning classification model is described. It achieves classification error probability competitive with that of popular supervised learning classifiers such as SVM or kNN. The model is based on the incremental execution of small step shift and rotation operations upon selected discriminative hyperplanes at the arrival of input samples. When applied, in conjunction with a selected feature extractor, to a subset of the ImageNet dataset benchmark, it yields 6.2 % Top 3 probability of error; this exceeds by merely about 2 % the result achieved by (supervised) k-Nearest Neighbor, both using same feature extractor. This result may also be contrasted with popular unsupervised learning schemes such as k-Means which is shown to be practically useless on same dataset.